
1. Wprowadzenie
W tym samouczku utworzymy model TensorFlow.js do rozpoznawania odręcznych cyfr z użyciem splotowej sieci neuronowej. Najpierw wytrenujemy klasyfikator, na tysiącach odręcznych odręcznych cyfr i ich etykiet. Następnie ocenimy dokładność klasyfikatora za pomocą danych testowych, których model nigdy nie widział.
To zadanie jest uznawane za zadanie klasyfikacji, ponieważ trenujemy model do przypisywania kategorii (cyfry widocznej na obrazie) do obrazu wejściowego. Wytrenujemy model, pokazując mu wiele przykładów danych wejściowych wraz z prawidłowymi danymi wyjściowymi. Jest to tzw. uczenie nadzorowane.
Co utworzysz
Utworzysz stronę internetową, która używa TensorFlow.js do trenowania modelu w przeglądarce. Czarno-biały obraz o określonym rozmiarze określa, która cyfra jest na nim widoczna. Wymagane czynności:
- Wczytaj dane.
- Zdefiniuj architekturę modelu.
- Wytrenuj model i monitoruj jego wydajność podczas trenowania.
- Oceń wytrenowany model, wykonując prognozy.
Czego się nauczysz
- Składnia TensorFlow.js do tworzenia modeli splotowych za pomocą interfejsu TensorFlow.js Warstwy API.
- Formułowanie zadań klasyfikacji w TensorFlow.js
- Jak monitorować trenowanie w przeglądarce za pomocą biblioteki tfjs-vis.
Czego potrzebujesz
- Najnowsza wersja Chrome lub inna nowoczesna przeglądarka obsługująca moduły ES6.
- Edytor tekstu działający lokalnie na komputerze lub w internecie za pomocą programu takiego jak Codepen lub Glitch.
- znajomość języków HTML, CSS, JavaScript i Narzędzi deweloperskich w Chrome (lub narzędzi deweloperskich preferowanych przez Ciebie w przeglądarce).
- Ogólne pojęcie teorety na temat sieci neuronowych. Jeśli potrzebujesz wprowadzenia lub przypomnienia, możesz obejrzeć ten film 3blue1brown lub film o Deep Learning in JavaScript autorstwa Ashiego Krishnana.
Musisz też znać treść naszego pierwszego samouczka.
2. Konfiguracja
Utwórz stronę HTML i dołącz JavaScript
 Skopiuj poniższy kod do pliku HTML o nazwie
Skopiuj poniższy kod do pliku HTML o nazwie
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Utwórz pliki JavaScript dla danych i kodu
- W tym samym folderze co plik HTML powyżej utwórz plik o nazwie data.js i skopiuj do niego zawartość z tego linku.
- W tym samym folderze co krok 1 utwórz plik o nazwie script.js i umieść w nim poniższy kod.
console.log('Hello TensorFlow');
Wypróbuj
Po utworzeniu plików HTML i JavaScript możesz je przetestować. Otwórz plik index.html w przeglądarce i otwórz konsolę devtools.
Jeśli wszystko działa, powinny być utworzone 2 zmienne globalne. tf jest odniesieniem do biblioteki TensorFlow.js, tfvis to odwołanie do biblioteki tfjs-vis.
Powinien wyświetlić się komunikat Hello TensorFlow,. Jeśli tak, możesz przejść do następnego kroku.
3. Wczytywanie danych
Z tego samouczka dowiesz się, jak wytrenować model tak, aby nauczył się rozpoznawać cyfry na obrazach takich jak te poniżej. Te obrazy to obrazy w skali szarości o wymiarach 28 x 28 pikseli, pochodzące ze zbioru danych o nazwie MNIST.
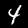

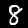
Udostępniliśmy kod, który umożliwia wczytywanie tych obrazów ze specjalnego pliku ze spacjami (ok. 10 MB), który dla Ciebie utworzyliśmy. Dzięki temu możemy skupić się na części trenowania.
Zapoznaj się z plikiem data.js, aby dowiedzieć się, jak są wczytywane dane. Gdy już skończysz korzystać z tego samouczka, możesz utworzyć własną metodę wczytywania danych.
Podany kod zawiera klasę MnistData z 2 metodami publicznymi:
nextTrainBatch(batchSize): zwraca losową grupę obrazów i ich etykiet ze zbioru treningowego.nextTestBatch(batchSize): zwraca grupę obrazów i ich etykiet ze zbioru testowego.
Klasa MnistData wykonuje też ważne kroki tasowania i normalizowania danych.
Dostępnych jest 65 tys. obrazów. Do wytrenowania modelu użyjemy do 55 tys. obrazów, co pozwoli zaoszczędzić 10 000 obrazów, które będziemy mogli wykorzystać do przetestowania wydajności modelu po zakończeniu pracy. Wszystko to zrobimy w przeglądarce.
Wczytaj dane i sprawdźmy, czy zostały prawidłowo wczytane.
Dodaj poniższy kod do pliku script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Odśwież stronę – po kilku sekundach powinien wyświetlić się panel z szeregiem obrazów.

4. Przedstaw nasze zadanie
Nasze dane wejściowe wyglądają tak.
Naszym celem jest wytrenowanie modelu, który będzie używać 1 obrazu i nauczy się przewidywać wynik dla każdej z 10 możliwych klas, do których może należeć obraz (cyfry 0–9).
Każdy obraz ma 28 pikseli szerokości i 28 pikseli wysokości. Ma 1 kanał kolorów, ponieważ jest obrazem w skali szarości. Kształt każdego obrazu jest więc taki: [28, 28, 1].
Pamiętaj, że robimy mapowanie w formacie 1-10, a także kształt każdego przykładu danych wejściowych, ponieważ jest to ważne w przypadku następnej sekcji.
5. Zdefiniuj architekturę modelu
W tej sekcji napiszemy kod opisujący architekturę modelu. Architektura modelu to wyrafinowany sposób określenia „które funkcje będzie uruchamiać model podczas wykonywania” lub „jakiego algorytmu będzie używać nasz model do obliczania odpowiedzi”.
W uczeniu maszynowym definiujemy architekturę (czyli algorytm), a proces trenowania „przyjmuje” parametry tego algorytmu.
Dodaj poniższą funkcję do
script.js plik do definiowania architektury modelu
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Przyjrzyjmy się temu nieco bardziej szczegółowo.
Sploty
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Korzystamy tu z modelu sekwencyjnego.
Korzystamy z warstwy conv2d, a nie z warstwy gęstej. Nie możemy wdawać się w szczegóły działania splotów, ale oto kilka zasobów, które wyjaśniają podstawę działania:
Przeanalizujmy każdy argument w obiekcie konfiguracji conv2d:
inputShapeKształt danych, które trafią do pierwszej warstwy modelu. W tym przypadku nasze przykłady z MNIST to czarno-białe obrazy o wymiarach 28 x 28 pikseli. Format kanoniczny danych obrazów to[row, column, depth], więc tutaj chcemy skonfigurować kształt[28, 28, 1]. 28 wierszy i kolumn dla liczby pikseli w każdym wymiarze oraz głębia 1, ponieważ nasze obrazy mają tylko 1 kanał kolorów. Pamiętaj, że w kształcie danych wejściowych nie określamy wielkości wsadu. Warstwy są zaprojektowane w sposób niezależny od rozmiaru wsadu, dzięki czemu podczas wnioskowania można przekazać tensor o dowolnym rozmiarze wsadu.kernelSizeRozmiar przesuwanych splotowych okien filtrów, które mają być stosowane do danych wejściowych. Ustawiliśmy tutaj wartośćkernelSizeo wartości5, która określa kwadrat o wymiarach splotowych 5 x 5.filtersLiczba okien filtrów o rozmiarzekernelSize, które mają zostać zastosowane do danych wejściowych. Zastosujemy do danych 8 filtrów.strides„Rozmiar kroku”, przesuwanego okna – czyli o ile pikseli zostanie przesunięty filtr za każdym razem, gdy przesunie się po obrazie. Określamy tutaj kroki 1, co oznacza, że filtr będzie przesuwał się po obrazie w krokach co 1 piksel.activationFunkcja aktywacji, która ma być stosowana do danych po zakończeniu splotu. W tym przypadku stosujemy funkcję Rectified Linear Unit (ReLU), która jest bardzo powszechną funkcją aktywacyjną w modelach ML.kernelInitializerMetoda używana do losowego inicjowania wag modelu, co jest bardzo ważne z punktu widzenia dynamiki trenowania. Nie będziemy tu omawiać szczegółów inicjowania, ale zwykle dobrym opcją inicjowania jestVarianceScaling(używany w tym miejscu).
Ujednolicenie reprezentacji danych
model.add(tf.layers.flatten());
Obrazy to dane o dużych wymiarach, a operacje splotowe zwykle zwiększają rozmiar danych, które trafiają do nich. Przed przekazaniem ich do końcowej warstwy klasyfikacji musimy podzielić dane w jedną długą tablicę. Gęste warstwy (które wykorzystujemy jako ostatnia warstwa) zajmują tylko tensor1d, więc ten krok jest typowy w wielu zadaniach klasyfikacji.
Oblicz ostateczny rozkład prawdopodobieństwa
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Do obliczenia rozkładu prawdopodobieństwa na 10 możliwych klasach użyjemy gęstej warstwy z aktywacją softmax. Przewidywaną cyfrą będzie klasa z najwyższym wynikiem.
Wybierz funkcję optymalizatora i utraty
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Kompilujemy model określający optymalizator, funkcję straty oraz wskaźniki, które chcemy śledzić.
W przeciwieństwie do pierwszego samouczka tutaj używamy categoricalCrossentropy jako funkcji utraty. Jak sama nazwa wskazuje, jest ona używana, gdy dane wyjściowe naszego modelu są rozkładem prawdopodobieństwa. Funkcja categoricalCrossentropy mierzy błąd między rozkładem prawdopodobieństwa wygenerowanym przez ostatnią warstwę naszego modelu a rozkładem prawdopodobieństwa określonym przez prawdziwą etykietę.
Jeśli na przykład nasza cyfra faktycznie oznacza liczbę 7, mogą pojawić się następujące wyniki:
Indeks | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Etykieta „Prawda” | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Prognoza | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
Kategoryczna entropia krzyżowa wygeneruje jedną liczbę wskazującą, jak podobny jest wektor prognostyczny do wektora prawdziwego etykiety.
Reprezentacja danych używana w przypadku etykiet to kodowanie jedno- gorące i często występują problemy z klasyfikacją. Z każdą klasą jest powiązane prawdopodobieństwo związane z każdym przykładem. Gdy wiemy, jakie powinno być prawdopodobieństwo, możemy ustawić je na 1, a pozostałe na 0. Więcej informacji o kodowaniu One-got znajdziesz na tej stronie.
Innym wskaźnikiem, który będziemy monitorować, jest accuracy. W przypadku problemu z klasyfikacją jest to odsetek poprawnych prognoz spośród wszystkich prognoz.
6. Wytrenuj model
Skopiuj poniższą funkcję do pliku Script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Następnie dodaj następujący kod do
run funkcja.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Odśwież stronę. Po kilku sekundach zobaczysz wykresy obrazujące postęp trenowania.
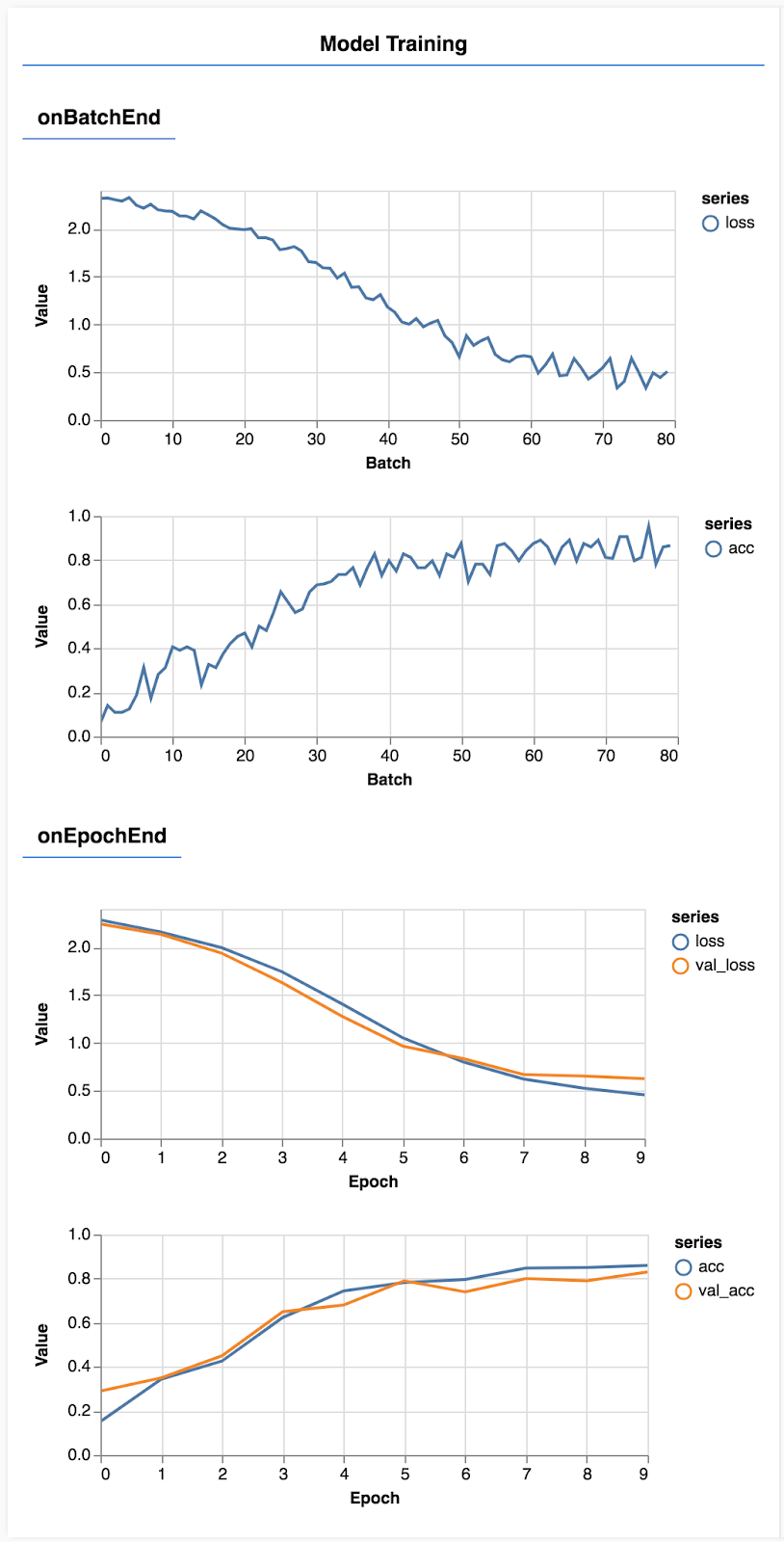
Przyjrzyjmy się temu nieco bardziej szczegółowo.
Monitorowanie danych
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
W tym miejscu określamy, które dane chcemy monitorować. Będziemy monitorować utratę i dokładność zbioru treningowego, a także utratę i dokładność zbioru do walidacji (odpowiednio wartość val_loss i val_acc). Więcej informacji o zestawie do weryfikacji piszemy poniżej.
Przygotowywanie danych jako tensorów
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Przygotowujemy 2 zbiory danych: zbiór treningowy, na którym będziemy trenować model, oraz zbiór do walidacji, na którym pod koniec każdej epoki będziemy testować model. Jednak dane w zbiorze do walidacji nigdy nie są wyświetlane modelowi podczas trenowania.
Udostępniona klasa danych ułatwia pobieranie tensorów z danych obrazu. Nadal jednak zmieniamy kształt tensorów, aby miały kształt [num_examples, image_width, image_height, channels], zanim przekażemy je do modelu. Każdy zbiór danych ma zarówno dane wejściowe (X), jak i etykiety (Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Nazywamy model.fit, aby rozpocząć pętlę trenowania. Przekazujemy również właściwość ValidData, która wskazuje, których danych model powinien użyć do przetestowania po każdej epoce (ale nie używać ich do trenowania).
Jeśli radzimy sobie dobrze w przypadku danych treningowych, ale nie w przypadku danych walidacyjnych, oznacza to, że prawdopodobnie model dopasowuje się zbytnio do danych treningowych i nie uogólni dobrze, aby wprowadzić go wcześniej.
7. Ocena modelu
Dokładność walidacji to dobre oszacowanie, jak nasz model poradzi sobie z danymi, których wcześniej nie widział (o ile dane te w jakiś sposób przypominają zbiór do weryfikacji). Chcemy jednak uzyskać bardziej szczegółowy podział wyników z poszczególnych klas.
W pliku tfjs-vis jest kilka metod, które mogą Ci w tym pomóc.
Dodaj następujący kod na końcu pliku script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Do czego służy ten kod?
- Przewiduje.
- Oblicza wskaźniki dokładności.
- Wyświetla dane
Przyjrzyjmy się bliżej każdemu etapowi.
Podpowiedzi
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Najpierw musimy zrobić kilka przewidywań. Zrobimy tu 500 zdjęć i przewidujemy, która cyfra się na nich znajduje (możesz później zwiększyć tę liczbę, aby przetestować na większym zbiorze zdjęć).
W szczególności funkcja argmax daje nam indeks najwyższej klasy prawdopodobieństwa. Pamiętaj, że model zwraca prawdopodobieństwo dla każdej klasy. Tutaj określamy największe prawdopodobieństwo i przypisujemy użycie go jako prognozy.
Możemy też przewidywać wyniki na wszystkich 500 przykładach naraz. TensorFlow.js zapewnia taką moc wektoryzacji.
Pokaż dokładność według zajęć
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Mając zestaw prognoz i etykiet, możemy obliczyć dokładność każdej z klas.
Pokaż tablicę pomyłek
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Tablica pomyłek jest podobna do dokładności dla poszczególnych klas, ale dzieli je na podgrupy, aby pokazać wzorce błędów klasyfikacji. Pozwala sprawdzić, czy model nie myli się w przypadku konkretnych par klas.
Wyświetlanie oceny
Dodaj ten kod na końcu funkcji uruchamiania, aby wyświetlić ocenę.
await showAccuracy(model, data);
await showConfusion(model, data);
Zobaczysz ekran podobny do tego.
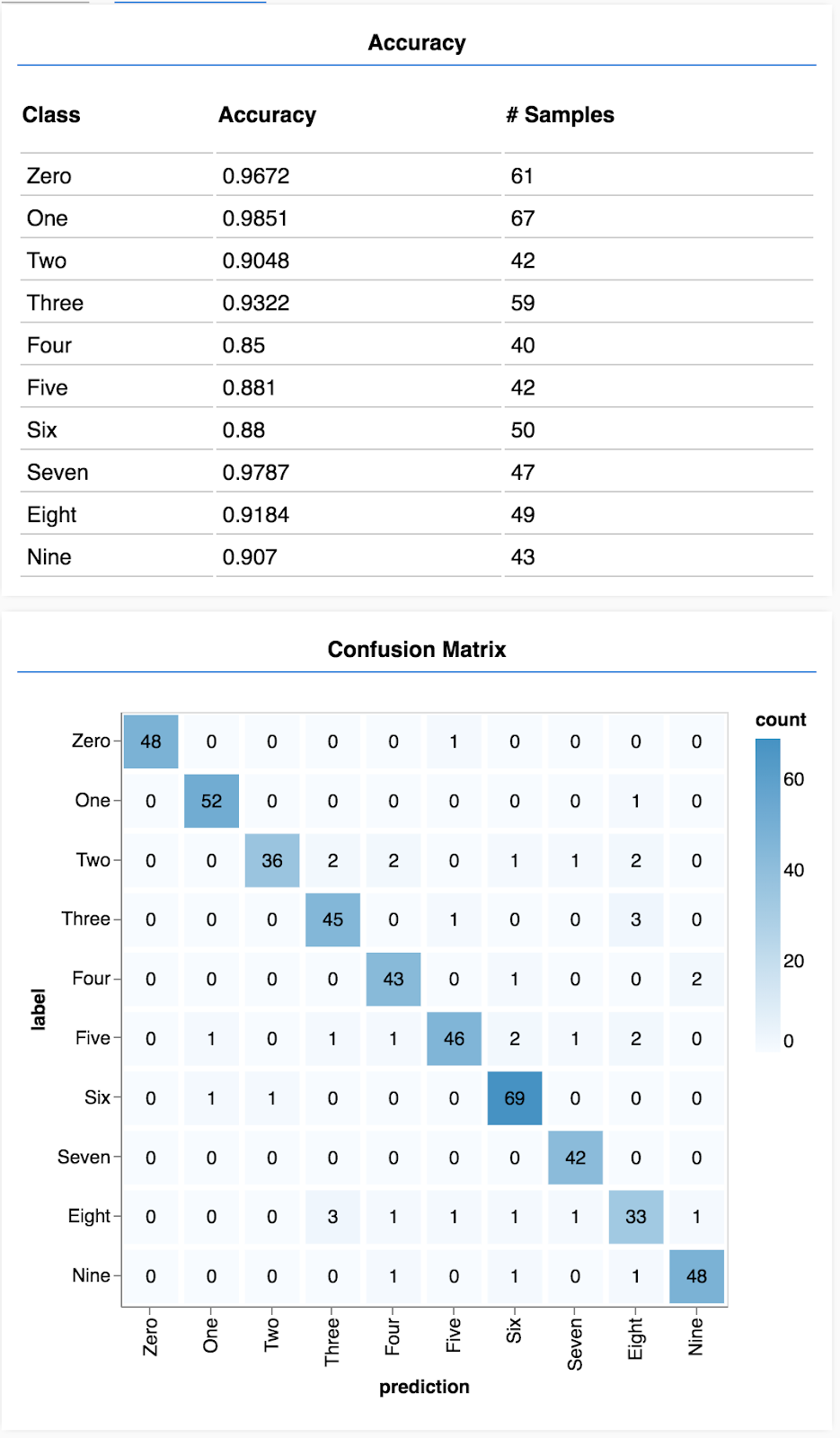
Gratulacje! Właśnie udało Ci się wytrenować splotową sieć neuronowa.
8. Główne wnioski
Prognozowanie kategorii dla danych wejściowych jest nazywane zadaniem klasyfikacji.
Zadania klasyfikacji wymagają odpowiedniej reprezentacji danych dla etykiet
- Etykiety często są przedstawiane przy użyciu jednego kodowania kategorii.
Przygotuj dane:
- Warto zachować niektóre dane, których model nie zobaczy podczas trenowania, aby wykorzystać je do oceny modelu. Jest to tzw. zestaw do weryfikacji.
Utwórz i uruchom model:
- Wykazano, że modele splotowe dobrze radzą sobie z zadaniami związanymi z obrazem.
- W problemach klasyfikacji używa się zwykle kategorycznej entropii krzyżowej funkcji straty.
- Monitoruj trenowanie, aby zobaczyć, czy strata spada, a dokładność rośnie.
Ocenianie modelu
- Po wytrenowaniu modelu wybierz sposób oceny jego skuteczności w przypadku początkowego problemu, który chcesz rozwiązać.
- Macierze pomyłek i dokładności według klasy mogą zapewnić dokładniejsze zestawienie wydajności modelu niż tylko ogólna dokładność.