
1. परिचय
इस ट्यूटोरियल में, हम TensorFlow.js मॉडल बनाएंगे, ताकि कॉन्वोलूशनल न्यूरल नेटवर्क की मदद से हाथ से लिखे गए अंकों की पहचान की जा सके. सबसे पहले, हम क्लासिफ़ायर को "लुक" लगाकर ट्रेनिंग देंगे हाथ से लिखे हुए अंकों वाली हज़ारों इमेज और उनके लेबल में. इसके बाद, हम डेटा की कैटगरी तय करने वाले टूल के सटीक होने का आकलन करेंगे. इसके लिए, हम उस टेस्ट डेटा का इस्तेमाल करेंगे जिसे मॉडल ने पहले कभी नहीं देखा है.
इस टास्क को कैटगरी वाला टास्क माना जाता है, क्योंकि हम मॉडल को इनपुट इमेज के लिए कैटगरी (इमेज में दिखने वाला अंक) असाइन करने के लिए ट्रेनिंग दे रहे हैं. हम इस मॉडल को सही आउटपुट के साथ इनपुट के कई उदाहरण दिखाएंगे. इसे सुपरवाइज़्ड लर्निंग कहा जाता है.
आपको क्या बनाना होगा
आपको एक ऐसा वेबपेज बनाना है जो ब्राउज़र में मॉडल को ट्रेनिंग देने के लिए, TensorFlow.js का इस्तेमाल करता है. किसी खास साइज़ की ब्लैक ऐंड व्हाइट इमेज होने पर, यह तय किया जाता है कि इमेज में कौनसा अंक दिख रहा है. इसमें ये चरण शामिल हैं:
- डेटा लोड करें.
- मॉडल की आर्किटेक्चर तय करें.
- मॉडल को ट्रेनिंग दें और ट्रेनिंग के दौरान इसकी परफ़ॉर्मेंस पर नज़र रखें.
- कुछ अनुमान लगाकर, ट्रेन किए गए मॉडल का आकलन करें.
आपको इनके बारे में जानकारी मिलेगी
- TensorFlow.js लेयर्स एपीआई का इस्तेमाल करके, कॉन्वलूशनल मॉडल बनाने के लिए TensorFlow.js सिंटैक्स.
- TensorFlow.js में क्लासिफ़िकेशन टास्क बनाना
- tfjs-vis लाइब्रेरी का इस्तेमाल करके ब्राउज़र में मौजूद ट्रेनिंग पर नज़र रखने का तरीका.
आपको इन चीज़ों की ज़रूरत होगी
- आपके पास Chrome का नया वर्शन या ऐसा दूसरा मॉडर्न ब्राउज़र हो जो ES6 मॉड्यूल के साथ काम करता हो.
- ऐसा टेक्स्ट एडिटर जो कोडपेन या Glitch जैसे टूल के ज़रिए, आपकी मशीन या वेब पर चल रहा हो.
- एचटीएमएल, सीएसएस, JavaScript, और Chrome DevTools (या आपके पसंदीदा ब्राउज़र Devtools) के बारे में जानकारी.
- न्यूरल नेटवर्क के बारे में कॉन्सेप्ट की अच्छी जानकारी. अगर आपको कोई परिचय या रीफ़्रेशर चाहिए, तो 3blue1brown का यह वीडियो या JavaScript में डीप लर्निंग के बारे में आशी कृष्णन का यह वीडियो देखें.
आपको हमारे पहले ट्रेनिंग ट्यूटोरियल में दिए गए कॉन्टेंट के हिसाब से भी अनुभव होना चाहिए.
2. सेट अप करें
एचटीएमएल पेज बनाना और उसमें JavaScript को शामिल करना
 नीचे दिए गए कोड को एक html फ़ाइल में कॉपी करें, जिसे
नीचे दिए गए कोड को एक html फ़ाइल में कॉपी करें, जिसे
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
डेटा और कोड के लिए JavaScript फ़ाइलें बनाना
- ऊपर दी गई एचटीएमएल फ़ाइल वाले फ़ोल्डर में, data.js फ़ाइल बनाएं और इस लिंक से कॉन्टेंट को उस फ़ाइल में कॉपी करें.
- पहले चरण वाले फ़ोल्डर में ही, script.js नाम की फ़ाइल बनाएं और उसमें यह कोड डालें.
console.log('Hello TensorFlow');
इसे आज़माएं
अब जब आपने एचटीएमएल और JavaScript फ़ाइलें बना ली हैं, तो इनकी जांच करें. अपने ब्राउज़र में index.html फ़ाइल खोलें और devtools कंसोल खोलें.
अगर सब कुछ ठीक से काम कर रहा है, तो दो ग्लोबल वैरिएबल बनाए जाने चाहिए. tf, TensorFlow.js लाइब्रेरी का रेफ़रंस है, जबकि tfvis, tfjs-vis लाइब्रेरी का रेफ़रंस है.
आपको Hello TensorFlow, मैसेज दिखेगा. अगर ऐसा है, तो आप अगले चरण पर जाने के लिए तैयार हैं.
3. डेटा लोड करें
इस ट्यूटोरियल में, आपको मॉडल को ट्रेनिंग दी जाएगी कि वह नीचे दी गई इमेज जैसी इमेज में मौजूद अंकों की पहचान करना सीखे. ये इमेज, MNIST नाम के डेटासेट से ली गई 28x28 पिक्सल की ग्रेस्केल इमेज हैं.
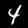

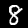
हमने आपके लिए एक खास स्प्राइट फ़ाइल (~10 एमबी) से इन इमेज को लोड करने के लिए कोड दिया है, ताकि हम ट्रेनिंग वाले हिस्से पर फ़ोकस कर सकें.
डेटा लोड करने का तरीका जानने के लिए, data.js फ़ाइल को पढ़ें. इसके अलावा, यह ट्यूटोरियल पूरा करने के बाद, अपने हिसाब से डेटा लोड करने का तरीका तय करें.
दिए गए कोड में एक क्लास MnistData है, जिसमें दो सार्वजनिक तरीके हैं:
nextTrainBatch(batchSize): ट्रेनिंग सेट से इमेज और उनके लेबल का रैंडम बैच दिखाता है.nextTestBatch(batchSize): टेस्ट सेट से इमेज और उनके लेबल का बैच दिखाता है
MnistData क्लास, डेटा को शफ़ल करने और नॉर्मलाइज़ करने के अहम चरणों को भी पूरा करती है.
कुल 65,000 इमेज हैं. हम मॉडल को ट्रेनिंग देने के लिए, 55,000 इमेज का इस्तेमाल करेंगे. इससे 10, 000 इमेज सेव हो जाएंगी,जिनका इस्तेमाल करके हम मॉडल की परफ़ॉर्मेंस की जांच कर सकेंगे. और हम ये सभी काम ब्राउज़र में करने वाले हैं!
चलिए, डेटा लोड करके जांच करते हैं कि यह सही तरीके से लोड हुआ है या नहीं.
यह कोड अपनी script.js फ़ाइल में जोड़ें.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
पेज को रीफ़्रेश करें. इसके बाद, आपको बाईं ओर कई इमेज वाला पैनल दिखेगा.

4. हमारे काम की बनावट तय करें
हमारा इनपुट डेटा कुछ ऐसा दिखता है.
हमारा लक्ष्य एक ऐसे मॉडल को ट्रेनिंग देना है जो एक इमेज लेगा. साथ ही, वह इमेज जो 10 क्लास से जुड़ी हो सकती है, हर क्लास के स्कोर (0-9 के अंक) का अनुमान लगाना सीखें.
हर इमेज की ऊंचाई 28 पिक्सल चौड़ी 28 पिक्सल है. इमेज का एक कलर चैनल है, क्योंकि यह ग्रेस्केल इमेज है. इसलिए, हर इमेज का आकार [28, 28, 1] है.
याद रखें कि हम वन-टू-10 मैपिंग करते हैं, और साथ ही हर इनपुट उदाहरण का आकार भी बनाते हैं, क्योंकि यह अगले सेक्शन के लिए अहम है.
5. मॉडल आर्किटेक्चर तय करें
इस सेक्शन में, हम मॉडल आर्किटेक्चर की जानकारी देने के लिए कोड लिखेंगे. मॉडल आर्किटेक्चर यह कहने का एक शानदार तरीका है कि "मॉडल को एक्ज़ीक्यूट करने के दौरान यह कौनसा फ़ंक्शन चलेगा" या दूसरा विकल्प "हमारा मॉडल अपने जवाबों का हिसाब लगाने के लिए किस एल्गोरिदम का इस्तेमाल करेगा".
मशीन लर्निंग में, हम एक आर्किटेक्चर या एल्गोरिदम तय करते हैं और ट्रेनिंग की प्रोसेस को उस एल्गोरिदम के पैरामीटर जानने देते हैं.
ये फ़ंक्शन अपने में जोड़ें
script.js फ़ाइल का इस्तेमाल करके मॉडल आर्किटेक्चर तय करें
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
चलिए, इस पर थोड़ा और विस्तार से गौर करते हैं.
कॉन्फ़्रेंस
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
यहां हम क्रम में चलने वाले मॉडल का इस्तेमाल कर रहे हैं.
हम सघन परत के बजाय conv2d परत का उपयोग कर रहे हैं. हम बातचीत के काम करने के तरीके की पूरी जानकारी नहीं दे सकते, लेकिन यहां कुछ संसाधन दिए गए हैं जो बुनियादी कार्रवाई के बारे में बताते हैं:
- इमेज कर्नेल के बारे में विज़ुअल की मदद से जानकारी
- विज़ुअल रिकग्निशन के लिए 'कॉन्वलूशनल न्यूरल नेटवर्क'
आइए, conv2d के लिए कॉन्फ़िगरेशन ऑब्जेक्ट में मौजूद हर आर्ग्युमेंट को बांटते हैं:
inputShape. मॉडल की पहली लेयर में जाने वाले डेटा का आकार. इस मामले में, MNIST का उदाहरण 28x28 पिक्सल वाली ब्लैक-ऐंड-व्हाइट इमेज है. इमेज डेटा के लिए कैननिकल फ़ॉर्मैट[row, column, depth]है, इसलिए यहां हम[28, 28, 1]का आकार कॉन्फ़िगर करना चाहते हैं. हर डाइमेंशन में पिक्सल की संख्या के लिए 28 पंक्तियां और कॉलम, और 1 की गहराई, क्योंकि हमारी इमेज में सिर्फ़ एक कलर चैनल होता है. ध्यान दें कि हम इनपुट के आकार में बैच का साइज़ तय नहीं करते. लेयर को बैच साइज़ ऐग्नोस्टिक के तौर पर डिज़ाइन किया गया है, ताकि अनुमान के दौरान किसी भी बैच साइज़ के टेंसर को पास किया जा सके.kernelSize. इनपुट डेटा पर लागू होने वाले स्लाइडिंग कॉन्वलूशनल फ़िल्टर विंडो का साइज़. यहां हम5काkernelSizeसेट करते हैं. इससे पता चलता है कि स्क्वेयर और 5x5 की कॉन्वोलूशनल विंडो क्या है.filters. इनपुट डेटा पर लागू करने के लिए,kernelSizeसाइज़ की फ़िल्टर विंडो की संख्या. यहां, हम डेटा पर 8 फ़िल्टर लागू करेंगे.strides. "चरण का आकार" स्लाइडिंग विंडो की—यानी, हर बार इमेज पर मूव करने पर फ़िल्टर कितने पिक्सल शिफ़्ट करेगा. यहां, हम 1 के स्ट्राइड की जानकारी देते हैं, जिसका मतलब है कि फ़िल्टर, इमेज पर 1 पिक्सल के चरणों में स्लाइड करेगा.activation. कन्वर्ज़न की प्रोसेस पूरी होने के बाद, डेटा पर लागू किया जाने वाला ऐक्टिवेशन फ़ंक्शन. इस मामले में, हम रेक्टिफ़ाइड लीनियर यूनिट (ReLU) फ़ंक्शन लागू कर रहे हैं, जो कि एमएल मॉडल में ऐक्टिवेशन फ़ंक्शन है.kernelInitializer. किसी मॉडल वेट को शुरू करने के लिए इस्तेमाल किया जाने वाला तरीका, जो डाइनैमिक की ट्रेनिंग के लिए बहुत ज़रूरी है. हम यहां, शुरू करने के बारे में नहीं बताएंगे. हालांकि,VarianceScaling(यहां इस्तेमाल किया गया है) को शुरू करने के लिए, एक अच्छा विकल्प माना जाता है.
डेटा दिखाने के तरीके को बेहतर बनाना
model.add(tf.layers.flatten());
इमेज हाई डाइमेंशन वाले डेटा की होती हैं. कॉन्वोल्यूशन की कार्रवाइयों से मिले डेटा का साइज़ बढ़ जाता है. उन्हें अपनी फ़ाइनल क्लासिफ़िकेशन लेयर में पास करने से पहले, हमें डेटा को एक लंबे अरे में फ़्लैट करना होगा. सघन लेयर (जिसका इस्तेमाल हम अपने आखिरी लेयर के रूप में करते हैं) में सिर्फ़ tensor1d सेकंड लगते हैं. इसलिए, कैटगरी तय करने से जुड़े कई टास्क में इस चरण का इस्तेमाल किया जाता है.
हमारे आखिरी प्रॉबबिलिटी डिस्ट्रिब्यूशन का हिसाब लगाएं
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
हम 10 संभावित क्लास में प्रॉबबिलिटी डिस्ट्रिब्यूशन का पता लगाने के लिए, सॉफ़्टमैक्स ऐक्टिवेशन के साथ सघन लेयर का इस्तेमाल करेंगे. सबसे ज़्यादा स्कोर वाली क्लास का अंक अनुमानित होगा.
ऑप्टिमाइज़र और लॉस फ़ंक्शन चुनें
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
हम मॉडल को ऑप्टिमाइज़ करने वाले टूल, लॉस फ़ंक्शन, और उन मेट्रिक के बारे में बताते हैं जिन्हें हम ट्रैक करना चाहते हैं.
हमारे पहले ट्यूटोरियल के उलट, हमने यहां categoricalCrossentropy को लॉस फ़ंक्शन के तौर पर इस्तेमाल किया है. जैसा कि नाम से ही पता चलता है कि इसका इस्तेमाल तब किया जाता है, जब हमारे मॉडल का आउटपुट प्रॉबबिलिटी डिस्ट्रिब्यूशन होता है. categoricalCrossentropy, हमारे मॉडल की आखिरी लेयर से जनरेट हुए प्रॉबबिलिटी डिस्ट्रिब्यूशन और हमारे ट्रू लेबल के दिए गए प्रॉबबिलिटी डिस्ट्रिब्यूशन के बीच की गड़बड़ी को मापता है.
उदाहरण के लिए, अगर हमारा अंक सही मायनों में 7 को दिखाता है, तो हमारे पास ये नतीजे हो सकते हैं
इंडेक्स | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
ट्रू लेबल | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
अनुमान | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
कैटगरीकल क्रॉस एंट्रॉपी से एक संख्या निकलेगी, जो यह बताएगी कि प्रेडिक्शन वेक्टर, हमारे ट्रू लेबल वेक्टर से कितना मिलता-जुलता है.
लेबल के लिए यहां इस्तेमाल किए गए डेटा को वन-हॉट एन्कोडिंग कहा जाता है और आम तौर पर, डेटा की कैटगरी तय करने से जुड़ी समस्याओं में इसका इस्तेमाल किया जाता है. हर उदाहरण के लिए, हर क्लास के साथ प्रॉबबिलिटी जुड़ी होती है. जब हमें पता चल जाता है कि यह क्या होना चाहिए, तो हम उस प्रॉबबिलिटी को 1 और बाकी को 0 पर सेट कर सकते हैं. वन-हॉट एन्कोडिंग के बारे में ज़्यादा जानकारी के लिए, इस पेज पर जाएं.
अन्य मेट्रिक, जिसकी हम निगरानी करेंगे वह accuracy है. क्लासिफ़िकेशन से जुड़ी समस्या के लिए, यह सभी अनुमानों में से सही अनुमानों का प्रतिशत है.
6. मॉडल को ट्रेनिंग दें
इस फ़ंक्शन को अपनी script.js फ़ाइल में कॉपी करें.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
इसके बाद, नीचे दिया गया कोड अपने फ़ोन नंबर में जोड़ें
run फ़ंक्शन.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
पेज को रीफ़्रेश करें. कुछ सेकंड बाद, आपको ट्रेनिंग की प्रोग्रेस की जानकारी देने वाले कुछ ग्राफ़ दिखेंगे.
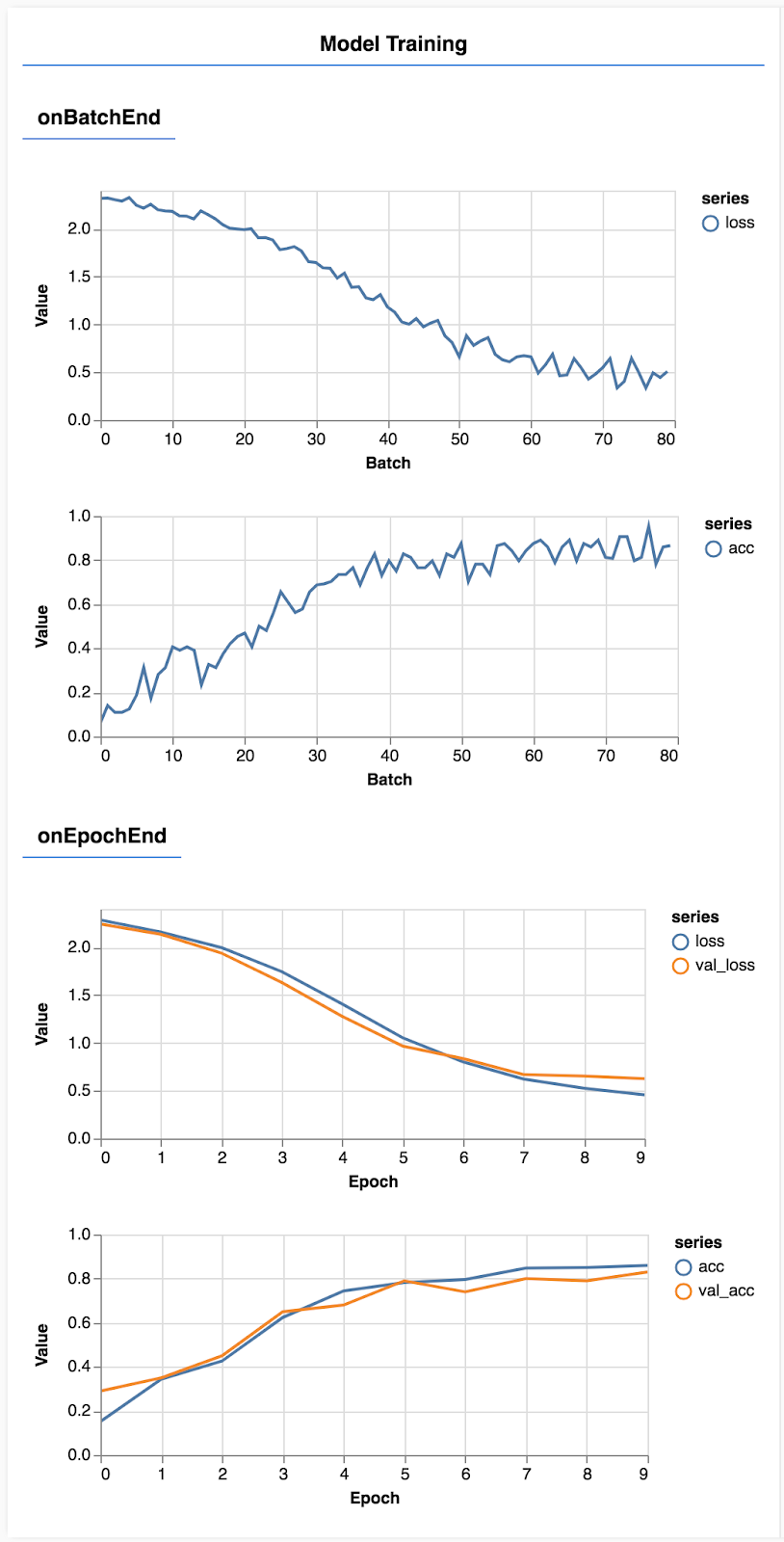
आइए, इस पर थोड़ा और विस्तार से गौर करते हैं.
मेट्रिक को मॉनिटर करना
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
यहां हम तय करते हैं कि हम किन मेट्रिक पर नज़र रखेंगे. हम इस बात पर नज़र रखेंगे कि ट्रेनिंग सेट में मौजूद नुकसान और सटीक होने के साथ-साथ, पुष्टि करने के सेट (वैल_लॉस और val_acc) पर कोई वैल्यू कितनी सटीक है और कितनी सटीक है. नीचे हम पुष्टि करने के सेट के बारे में ज़्यादा जानकारी देंगे.
डेटा को टेंसर के तौर पर तैयार करना
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
यहां हम दो डेटासेट बनाते हैं. एक ट्रेनिंग सेट, जिसके आधार पर हम मॉडल को ट्रेनिंग देंगे और एक पुष्टि सेट, जिस पर हम हर epoch के आखिर में मॉडल की जांच करेंगे. हालांकि, ट्रेनिंग के दौरान मॉडल को पुष्टि करने वाले सेट में मौजूद डेटा कभी नहीं दिखाया जाता.
हमने जो डेटा क्लास दी है उसकी मदद से, इमेज के डेटा से टेंसर आसानी से हासिल किए जा सकते हैं. हालांकि, हम अब भी टेंसर को उसके मॉडल [num_examples,image_width, image_height, channels] के हिसाब से आकार में बदलाव कर रहे हैं. इसके बाद ही हम इन्हें मॉडल में फ़ीड कर पाएंगे. हर डेटासेट के लिए, इनपुट (X) और लेबल (Y) दोनों होते हैं.
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
हम ट्रेनिंग लूप शुरू करने के लिए, Model.fit को कॉल करते हैं. हम एक verificationData प्रॉपर्टी भी पास करते हैं, जो यह बताने के लिए है कि मॉडल को हर epoch के बाद, खुद की जांच करने के लिए किस डेटा का इस्तेमाल करना चाहिए (हालांकि, ट्रेनिंग के लिए इसका इस्तेमाल नहीं करना चाहिए).
अगर हम अपने ट्रेनिंग डेटा का सही तरीके से इस्तेमाल करते हैं, लेकिन पुष्टि करने वाले डेटा के मुताबिक नहीं, तो इसका मतलब है कि मॉडल, ट्रेनिंग डेटा में ज़रूरत से ज़्यादा बदलाव कर सकता है. साथ ही, इसके बारे में पहले से अनुमान नहीं लगा पाएगा.
7. हमारे मॉडल का मूल्यांकन करना
पुष्टि करने की सटीक जानकारी से इस बात का बेहतर अनुमान मिलता है कि हमारा मॉडल, ऐसे डेटा के लिए कितना बेहतर काम करेगा जो पहले नहीं देखा गया था. हालांकि, इसके लिए ज़रूरी है कि वह डेटा, पुष्टि करने के लिए सेट किए गए डेटा से मिलता-जुलता हो. हालांकि, हो सकता है कि हम अलग-अलग क्लास के हिसाब से परफ़ॉर्मेंस के बारे में ज़्यादा जानकारी पाना चाहें.
tfjs-vis में ऐसे कई तरीके हैं जो इस काम में आपकी मदद कर सकते हैं.
अपनी script.js फ़ाइल में सबसे नीचे यह कोड जोड़ें
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
यह कोड क्या कर रहा है?
- सुझाव देता है.
- सटीक मेट्रिक का हिसाब लगाता है.
- मेट्रिक दिखाता है
आइए, अब हर चरण पर गौर करें.
अनुमान लगाना
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
सबसे पहले हमें कुछ अनुमान लगाने होंगे. यहां हम 500 इमेज लेंगे और यह अनुमान लगाएंगे कि उनमें कौनसा अंक है (इमेज के बड़े सेट पर टेस्ट करने के लिए, इस संख्या को बाद में बढ़ाया जा सकता है).
ध्यान दें कि argmax फ़ंक्शन हमें सबसे ज़्यादा प्रॉबबिलिटी क्लास का इंडेक्स देता है. याद रखें कि मॉडल, हर क्लास के लिए प्रॉबबिलिटी देता है. यहां हम सबसे ज़्यादा संभावना का पता लगाते हैं और उसी अनुमान को अनुमान के तौर पर इस्तेमाल करते हैं.
आपने यह भी देखा होगा कि हम एक ही बार में सभी 500 उदाहरणों पर अनुमान लगा सकते हैं. यह TensorFlow.js से मिलने वाली वेक्टराइज़ेशन की ताकत है.
हर क्लास के हिसाब से दिखाएं कि फ़िल्टर कितना सटीक है
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
अनुमानों और लेबल के सेट की मदद से, हम हर क्लास के लिए सटीक होने का पता लगा सकते हैं.
भ्रम की स्थिति का आव्यूह दिखाएं
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
भ्रम की स्थिति वाला मैट्रिक्स, क्लास की सटीक जानकारी की तरह ही होता है. हालांकि, इसमें गलत कैटगरी के पैटर्न दिखाने के लिए इसे तोड़ दिया जाता है. इससे आपको यह देखने में मदद मिलती है कि क्या मॉडल, क्लास के किसी खास जोड़े को लेकर भ्रमित हो रहा है या नहीं.
आकलन दिखाना
आकलन दिखाने के लिए, अपने रन फ़ंक्शन के नीचे इस कोड को जोड़ें.
await showAccuracy(model, data);
await showConfusion(model, data);
आपको ऐसा डिसप्ले दिखेगा जो इस तरह दिखता है.
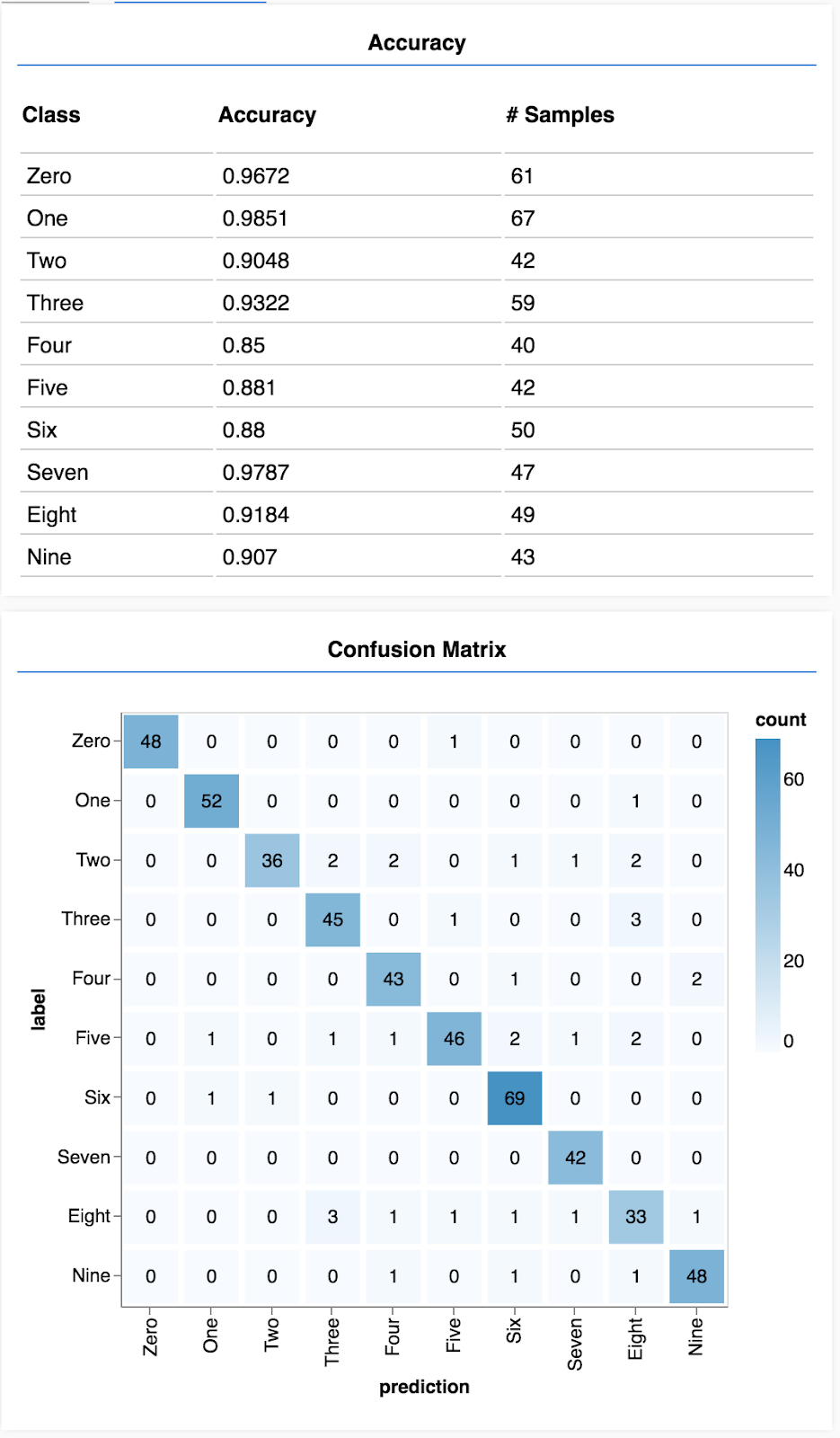
बधाई हो! आपने अभी-अभी कॉन्वोलूशनल न्यूरल नेटवर्क को ट्रेनिंग दी है!
8. सीखने वाली मुख्य बातें
इनपुट डेटा के लिए कैटगरी का अनुमान लगाने को कैटगरी बनाने का टास्क कहा जाता है.
क्लासिफ़िकेशन टास्क में लेबल के लिए, सही डेटा दिखाना ज़रूरी है
- लेबल के सामान्य निरूपण में, कैटगरी की वन-हॉट एन्कोडिंग शामिल है
अपना डेटा तैयार करें:
- कुछ डेटा को अलग रखना फ़ायदेमंद होता है, जो ट्रेनिंग के दौरान मॉडल को कभी नहीं दिखता. इसका इस्तेमाल मॉडल का आकलन करने के लिए किया जा सकता है. इसे पुष्टि सेट कहा जाता है.
अपना मॉडल बनाएं और चलाएं:
- कॉन्वोल्यूशन मॉडल को इमेज से जुड़े टास्क पर अच्छा परफ़ॉर्म करने के लिए दिखाया गया है.
- वर्गीकरण के सवाल में, आम तौर पर अपने लॉस फ़ंक्शन के लिए, कैटगरीकल क्रॉस एंट्रॉपी का इस्तेमाल किया जाता है.
- यह देखने के लिए ट्रेनिंग पर नज़र रखें कि क्या नुकसान कम हो रहा है और सटीक हो रहा है या नहीं.
अपने मॉडल का मूल्यांकन करना
- एक बार आपके मॉडल का मूल्यांकन करने के लिए कोई तरीका तय करें जब यह आपके द्वारा हल की जाने वाली शुरुआती समस्या पर यह देखने के लिए प्रशिक्षित हो जाए.
- हर क्लास के हिसाब से सटीक जानकारी और भ्रम की स्थिति दिखाने वाले मैट्रिक्स से, मॉडल की परफ़ॉर्मेंस के बारे में ज़्यादा सटीक जानकारी मिल सकती है.