
1. Введение
В этом уроке мы создадим модель TensorFlow.js для распознавания рукописных цифр с помощью сверточной нейронной сети. Сначала мы обучим классификатор, заставив его «просмотреть» тысячи рукописных изображений цифр и их меток. Затем мы оценим точность классификатора, используя тестовые данные, которых модель никогда не видела.
Эта задача считается задачей классификации, поскольку мы обучаем модель присваивать категорию (цифру, которая появляется на изображении) входному изображению. Мы будем обучать модель, показывая ей множество примеров входных данных и правильных выходных данных. Это называется контролируемым обучением .
Что вы построите
Вы создадите веб-страницу, которая будет использовать TensorFlow.js для обучения модели в браузере. Учитывая черно-белое изображение определенного размера, он определит, какая цифра появляется на изображении. Необходимые шаги:
- Загрузите данные.
- Определите архитектуру модели.
- Обучайте модель и отслеживайте ее производительность во время обучения.
- Оцените обученную модель, сделав некоторые прогнозы.
Что вы узнаете
- Синтаксис TensorFlow.js для создания сверточных моделей с использованием API слоев TensorFlow.js.
- Формулирование задач классификации в TensorFlow.js
- Как отслеживать обучение в браузере с помощью библиотеки tfjs-vis.
Что вам понадобится
- Последняя версия Chrome или другой современный браузер, поддерживающий модули ES6.
- Текстовый редактор, работающий либо локально на вашем компьютере, либо в Интернете через что-то вроде Codepen или Glitch .
- Знание HTML, CSS, JavaScript и инструментов разработчика Chrome (или инструментов разработчика предпочитаемого вами браузера).
- Концептуальное понимание нейронных сетей высокого уровня. Если вам нужно введение или повышение квалификации, рассмотрите возможность просмотра этого видео от 3blue1brown или этого видео о глубоком обучении в Javascript от Аши Кришнана .
Вы также должны быть знакомы с материалом нашего первого учебного пособия .
2. Настройте
Создайте HTML-страницу и включите JavaScript.
 Скопируйте следующий код в HTML-файл с именем
Скопируйте следующий код в HTML-файл с именем
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Создайте файлы JavaScript для данных и кода.
- В той же папке, что и HTML-файл выше, создайте файл data.js и скопируйте содержимое этой ссылки в этот файл.
- В той же папке, что и на первом этапе, создайте файл с именем script.js и поместите в него следующий код.
console.log('Hello TensorFlow');
Проверьте это
Теперь, когда у вас созданы файлы HTML и JavaScript, протестируйте их. Откройте файл index.html в своем браузере и откройте консоль devtools.
Если все работает, должны быть созданы две глобальные переменные. tf — ссылка на библиотеку TensorFlow.js, tfvis — ссылка на библиотеку tfjs-vis .
Вы должны увидеть сообщение Hello TensorFlow . Если это так, вы готовы перейти к следующему шагу.
3. Загрузите данные
В этом уроке вы научите модель распознавать цифры на изображениях, подобных приведенным ниже. Эти изображения представляют собой изображения в оттенках серого размером 28x28 пикселей из набора данных MNIST .

Мы предоставили код для загрузки этих изображений из специального файла спрайтов (~ 10 МБ), который мы создали для вас, чтобы мы могли сосредоточиться на обучающей части.
Не стесняйтесь изучить файл data.js чтобы понять, как загружаются данные. Или, закончив изучение этого руководства, создайте свой собственный подход к загрузке данных.
Предоставленный код содержит класс MnistData , который имеет два общедоступных метода:
-
nextTrainBatch(batchSize): возвращает случайную партию изображений и их метки из обучающего набора. -
nextTestBatch(batchSize): возвращает пакет изображений и их метки из тестового набора.
Класс MnistData также выполняет важные шаги по перетасовке и нормализации данных.
Всего имеется 65 000 изображений, мы будем использовать до 55 000 изображений для обучения модели, сохранив 10 000 изображений, которые мы сможем использовать для проверки производительности модели, когда закончим. И все это мы собираемся сделать в браузере!
Давайте загрузим данные и проверим, что они загружены правильно.
Добавьте следующий код в файл script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Обновите страницу, и через несколько секунд вы увидите панель слева с несколькими изображениями.

4. Концептуализируем нашу задачу
Наши входные данные выглядят следующим образом.
Наша цель — обучить модель, которая возьмет одно изображение и научится прогнозировать оценку для каждого из 10 возможных классов, к которым может принадлежать изображение (цифры 0–9).
Каждое изображение имеет ширину 28 пикселей и высоту 28 пикселей и имеет 1 цветовой канал, поскольку представляет собой изображение в оттенках серого. Таким образом, форма каждого изображения равна [28, 28, 1] .
Помните, что мы выполняем сопоставление один к десяти, а также форму каждого входного примера, поскольку это важно для следующего раздела.
5. Определите архитектуру модели.
В этом разделе мы напишем код для описания архитектуры модели. Архитектура модели — это причудливый способ сказать , «какие функции будет выполнять модель во время выполнения» или, альтернативно , «какой алгоритм будет использовать наша модель для вычисления ответов» .
В машинном обучении мы определяем архитектуру (или алгоритм) и позволяем процессу обучения изучить параметры этого алгоритма.
Добавьте следующую функцию в свой
файл script.js для определения архитектуры модели.
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Давайте посмотрим на это немного подробнее.
Извилины
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Здесь мы используем последовательную модель.
Мы используем слой conv2d вместо плотного слоя. Мы не можем вдаваться во все детали того, как работают свертки , но вот несколько ресурсов, которые объясняют основную операцию:
Давайте разберем каждый аргумент в объекте конфигурации для conv2d :
-
inputShape. Форма данных, которые будут поступать в первый слой модели. В данном случае наши примеры MNIST представляют собой черно-белые изображения размером 28x28 пикселей. Канонический формат данных изображения —[row, column, depth], поэтому здесь мы хотим настроить форму[28, 28, 1]. 28 строк и столбцов для количества пикселей в каждом измерении и глубины 1, поскольку наши изображения имеют только 1 цветовой канал. Обратите внимание, что мы не указываем размер пакета во входной форме. Слои спроектированы таким образом, чтобы они не зависели от размера пакета, поэтому во время вывода вы можете передать в него тензор любого размера пакета. -
kernelSize. Размер скользящих окон сверточного фильтра, которые будут применены к входным данным. Здесь мы устанавливаемkernelSize, равный5, что определяет квадратное сверточное окно 5x5. -
filters. Количество окон фильтра размеромkernelSize, применяемых к входным данным. Здесь мы применим к данным 8 фильтров. -
strides. «Размер шага» скользящего окна — т. е. на сколько пикселей фильтр будет смещаться каждый раз, когда он перемещается по изображению. Здесь мы указываем шаг равный 1, что означает, что фильтр будет скользить по изображению с шагом в 1 пиксель. -
activation. Функция активации , применяемая к данным после завершения свертки. В этом случае мы применяем функцию выпрямленной линейной единицы (ReLU) , которая является очень распространенной функцией активации в моделях ML. -
kernelInitializer. Метод, используемый для случайной инициализации весов модели, что очень важно для динамики обучения. Мы не будем здесь вдаваться в подробности инициализации, ноVarianceScaling(используемый здесь) обычно является хорошим выбором инициализатора .
Сглаживание нашего представления данных
model.add(tf.layers.flatten());
Изображения представляют собой данные большой размерности, и операции свертки имеют тенденцию увеличивать размер данных, которые в них входят. Прежде чем передать их на наш последний уровень классификации, нам нужно свести данные в один длинный массив. Плотные слои (которые мы используем в качестве последнего слоя) принимают только tensor1d , поэтому этот шаг часто встречается во многих задачах классификации.
Вычислите наше окончательное распределение вероятностей
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Мы будем использовать плотный слой с активацией softmax для расчета распределений вероятностей по 10 возможным классам. Класс с наивысшим баллом будет предсказанной цифрой.
Выберите оптимизатор и функцию потерь
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Мы компилируем модель, указывая оптимизатор , функцию потерь и метрики, которые мы хотим отслеживать.
В отличие от нашего первого урока, здесь мы используем categoricalCrossentropy в качестве функции потерь. Как следует из названия, он используется, когда выходные данные нашей модели представляют собой распределение вероятностей. categoricalCrossentropy измеряет ошибку между распределением вероятностей, сгенерированным последним слоем нашей модели, и распределением вероятностей, заданным нашей истинной меткой.
Например, если наша цифра действительно представляет собой 7, мы можем получить следующие результаты:
Индекс | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Настоящая этикетка | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Прогноз | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
Категориальная перекрестная энтропия даст одно число, указывающее, насколько вектор прогнозирования похож на наш вектор истинной метки.
Представление данных, используемое здесь для меток, называется горячим кодированием и часто встречается в задачах классификации. Каждый класс имеет связанную с ним вероятность для каждого примера. Когда мы точно знаем, каким оно должно быть, мы можем установить эту вероятность на 1, а остальные на 0. Дополнительную информацию о горячем кодировании см. на этой странице .
Другой показатель, который мы будем отслеживать, — это accuracy , которая для задачи классификации представляет собой процент правильных прогнозов от всех прогнозов.
6. Обучите модель
Скопируйте следующую функцию в файл script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Затем добавьте следующий код в свой
функция run .
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Обновите страницу, и через несколько секунд вы увидите несколько графиков, отражающих ход обучения.
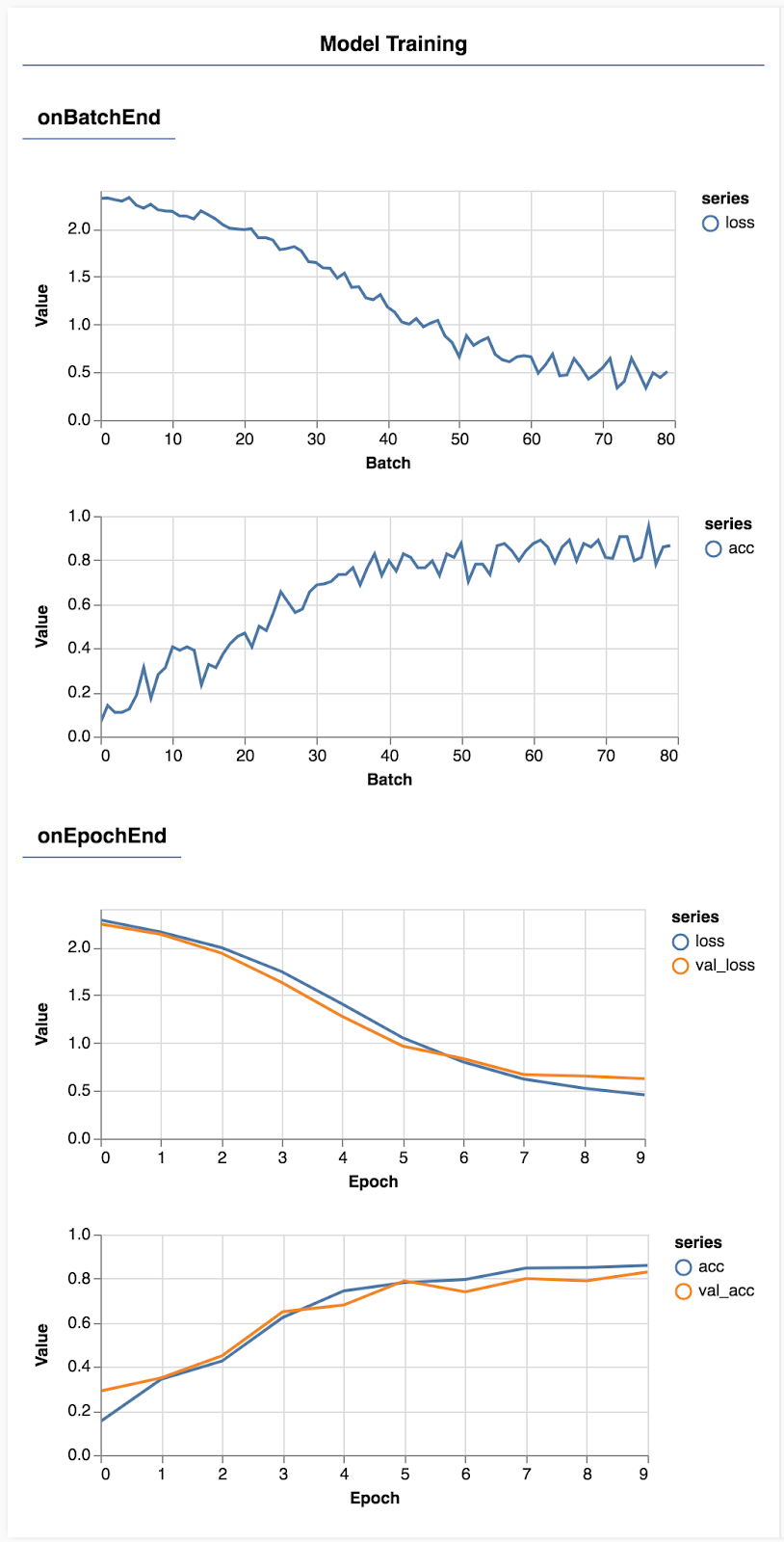
Давайте посмотрим на это немного подробнее.
Мониторинг показателей
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Здесь мы решаем, какие метрики будем отслеживать. Мы будем отслеживать потери и точность в обучающем наборе, а также потери и точность в проверочном наборе (val_loss и val_acc соответственно). Подробнее о наборе проверок мы поговорим ниже.
Подготовьте данные в виде тензоров
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Здесь мы создаем два набора данных: обучающий набор, на котором мы будем обучать модель, и набор проверки, на котором мы будем тестировать модель в конце каждой эпохи, однако данные в наборе проверки никогда не отображаются модели во время обучения. .
Предоставленный нами класс данных позволяет легко получать тензоры из данных изображения. Но мы все равно придаем тензорам форму, ожидаемую моделью, [num_examples, image_width, image_height,channels] прежде, чем мы сможем передать их в модель. Для каждого набора данных у нас есть как входные данные (X), так и метки (Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Мы вызываем model.fit, чтобы начать цикл обучения. Мы также передаем свойство validationData, чтобы указать, какие данные модель должна использовать для тестирования после каждой эпохи (но не для обучения).
Если мы хорошо справляемся с нашими обучающими данными, но не с нашими данными проверки, это означает, что модель, скорее всего, переподгоняется под обучающие данные и не сможет хорошо обобщать входные данные, которых она ранее не видела.
7. Оцените нашу модель
Точность проверки дает хорошую оценку того, насколько хорошо наша модель будет работать с данными, которых она раньше не видела (при условии, что эти данные каким-то образом напоминают набор проверки). Однако нам может потребоваться более подробная разбивка производительности по различным классам.
В tfjs-vis есть несколько методов, которые могут вам в этом помочь.
Добавьте следующий код в конец файла script.js.
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Что делает этот код?
- Делает прогноз.
- Вычисляет показатели точности.
- Показывает метрики
Давайте подробнее рассмотрим каждый шаг.
Делайте прогнозы
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Сначала нам нужно сделать некоторые прогнозы. Здесь мы возьмем 500 изображений и предскажем, какая цифра в них (вы можете увеличить это число позже, чтобы проверить на большем наборе изображений).
Примечательно, что функция argmax дает нам индекс наивысшего класса вероятности. Помните, что модель выводит вероятность для каждого класса. Здесь мы находим наибольшую вероятность и назначаем использовать ее в качестве прогноза.
Вы также можете заметить, что мы можем делать прогнозы для всех 500 примеров одновременно. В этом заключается мощь векторизации, которую обеспечивает TensorFlow.js.
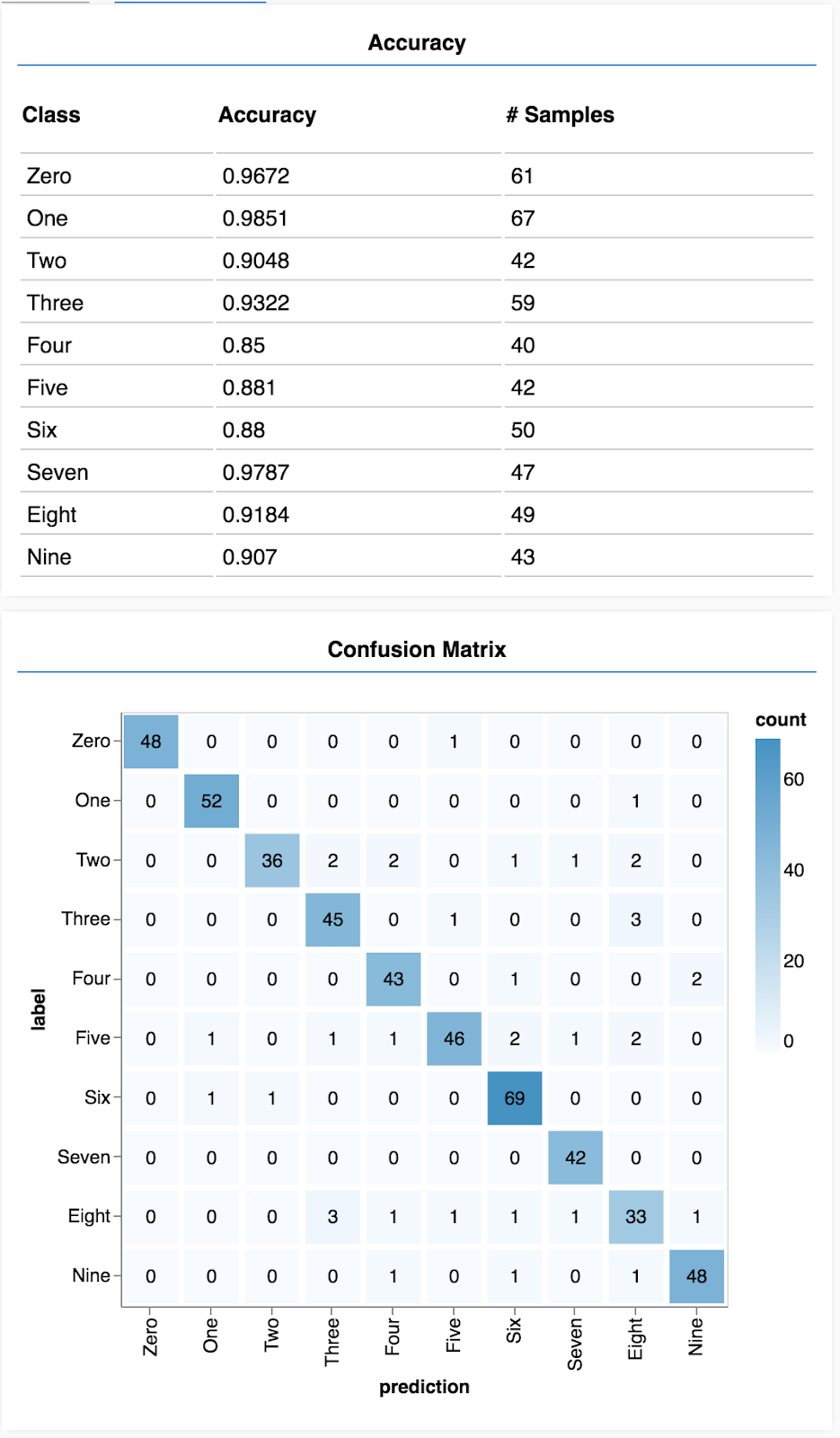
Показать точность по классам
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Имея набор прогнозов и меток, мы можем рассчитать точность для каждого класса.
Показать матрицу путаницы
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Матрица путаницы аналогична точности по классам, но дополнительно разбивает ее на части, чтобы показать закономерности неправильной классификации. Это позволяет вам увидеть, не запуталась ли модель в каких-либо конкретных парах классов.
Отобразить оценку
Добавьте следующий код в конец функции запуска, чтобы отобразить оценку.
await showAccuracy(model, data);
await showConfusion(model, data);
Вы должны увидеть экран, похожий на следующий.
Поздравляем! Вы только что обучили сверточную нейронную сеть!
8. Основные выводы
Прогнозирование категорий входных данных называется задачей классификации.
Задачи классификации требуют соответствующего представления данных для меток.
- Общие представления меток включают горячее кодирование категорий.
Подготовьте данные:
- Полезно сохранить некоторые данные, которые модель никогда не увидит во время обучения, и которые вы можете использовать для оценки модели. Это называется набором проверки.
Создайте и запустите свою модель:
- Было показано, что сверточные модели хорошо справляются с задачами с изображениями.
- В задачах классификации обычно используется категориальная перекрестная энтропия для функций потерь.
- Контролируйте обучение, чтобы увидеть, уменьшаются ли потери и повышается ли точность.
Оцените свою модель
- Решите, каким образом можно оценить вашу модель после ее обучения, чтобы увидеть, насколько хорошо она справляется с исходной проблемой, которую вы хотели решить.
- Матрицы точности по классам и путаницы могут дать более точное представление о производительности модели, чем просто общая точность.