
1. מבוא
במדריך הזה נבנה מודל TensorFlow.js כדי לזהות ספרות בכתב יד באמצעות רשת עצבית מתקפלת. קודם כל, נאמן את המסווג באמצעות "מראה" על אלפי תמונות בכתב יד והתוויות שלהן. לאחר מכן נבדוק את דיוק המסווג באמצעות נתוני בדיקה שהמודל מעולם לא ראה.
המשימה הזו נחשבת כמשימת סיווג כי אנחנו מאמנים את המודל להקצות לתמונה (הספרה שמופיעה בתמונה) קטגוריה. כדי לאמן את המודל, נציג לו הרבה דוגמאות של קלט יחד עם הפלט הנכון. היא נקראת למידה מונחית.
מה תפַתחו
אתם תיצרו דף אינטרנט שמשתמש ב-TensorFlow.js לאימון מודל בדפדפן. אם מדובר בתמונה בשחור-לבן בגודל מסוים, המערכת תסווג איזו ספרה מופיעה בתמונה. השלבים הנדרשים הם:
- טוענים את הנתונים.
- להגדיר את הארכיטקטורה של המודל.
- לאמן את המודל ולעקוב אחרי הביצועים שלו במהלך האימון.
- תוכלו להעריך את המודל שעבר אימון על ידי יצירת תחזיות.
מה תלמדו
- בתחביר TensorFlow.js ליצירת מודלים קונבולוציה באמצעות TensorFlow.js Layers API.
- ניסוח משימות סיווג ב-TensorFlow.js
- איך לעקוב אחר אימון בדפדפן באמצעות ספריית tfjs-vis.
מה צריך להכין
- גרסה עדכנית של Chrome או דפדפן מודרני אחר שתומך במודולים של ES6.
- כלי לעריכת טקסט, שפועל באופן מקומי במחשב שלכם או באינטרנט באמצעות משהו כמו Codepen או Glitch.
- ידע ב-HTML, ב-CSS, ב-JavaScript וב-כלי הפיתוח ל-Chrome (או בכלי הפיתוח המועדפים עליכם בדפדפנים).
- הבנה רעיונית של רשתות נוירונים. אם אתם צריכים מבוא או רענון, תוכלו לצפות בסרטון הזה ב-3blue1brown או בסרטון הזה בנושא למידה עמוקה (Deep Learning) ב-JavaScript של אשי קרישנן.
בנוסף, אתם אמורים להיות מרוצים מהחומר שבמדריך ההדרכה הראשון שלנו.
2. להגדרה
יצירת דף HTML והכללת ה-JavaScript
 צריך להעתיק את הקוד הבא לקובץ HTML בשם
צריך להעתיק את הקוד הבא לקובץ HTML בשם
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
יוצרים את קובצי ה-JavaScript של הנתונים והקוד
- באותה תיקייה שבה נמצא קובץ ה-HTML שלמעלה, יוצרים קובץ בשם data.js ומעתיקים את התוכן מהקישור הזה לתוך הקובץ.
- באותה תיקייה שבה נמצא שלב 1, יוצרים קובץ בשם script.js ומציבים בו את הקוד הבא.
console.log('Hello TensorFlow');
רוצים לנסות?
עכשיו, אחרי שיצרתם את קובצי ה-HTML וה-JavaScript, כדאי לנסות אותם. פותחים את הקובץ index.html בדפדפן ופותחים את מסוף כלי הפיתוח.
אם הכול עובד כמו שצריך, אמורים להיווצר שני משתנים גלובליים. tf הוא הפניה לספריית TensorFlow.js, tfvis הוא הפניה לספריית tfjs-vis.
אמורה להופיע ההודעה Hello TensorFlow, אם כן, אתם מוכנים לעבור לשלב הבא.
3. טעינת הנתונים
במדריך הזה תאמנו מודל ללמוד לזהות ספרות בתמונות כמו אלה שמופיעות בהמשך. התמונות האלה הן תמונות בגווני אפור בגודל 28x28 פיקסלים ממערך נתונים שנקרא MNIST.

כדי שנוכל להתמקד בחלק האימון, סיפקנו קוד לטעינת התמונות האלה מקובץ sprite מיוחד (כ-10MB) שיצרנו.
אתם יכולים לעיין בקובץ data.js כדי להבין איך הנתונים נטענים. לחלופין, כשתסיימו לקרוא את המדריך, תוכלו ליצור גישה משלכם לטעינת הנתונים.
הקוד שסופק מכיל מחלקה MnistData שיש לה שתי שיטות ציבוריות:
nextTrainBatch(batchSize): מחזירה קבוצה אקראית של תמונות והתוויות שלהן מקבוצת האימון.nextTestBatch(batchSize): החזרת קבוצה של תמונות והתוויות שלהן מקבוצת הבדיקה
המחלקה MnistData מבצעת גם את השלבים החשובים של השמעה אקראית ונירמול של הנתונים.
ישנן 65,000 תמונות בסך הכול. נשתמש בעד 55,000 תמונות כדי לאמן את המודל, ונשמור 10,000 תמונות שבהן נוכל להשתמש כדי לבדוק את ביצועי המודל. ואנחנו נעשה את כל זה בדפדפן!
בואו טוענים את הנתונים ונבדוק שהם נטענים בצורה נכונה.
צריך להוסיף את הקוד הבא לקובץ script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
מרעננים את הדף ולאחר כמה שניות אמורה להופיע חלונית עם מספר תמונות בצד ימין.

4. מגדירים את המשימה שלנו
נתוני הקלט שלנו נראים כך.
המטרה שלנו היא לאמן מודל שיקבל תמונה אחת וללמוד לחזות ציון לכל אחת מ-10 הכיתות האפשריות שהתמונה שייכת אליהן (הספרות 0-9).
לכל תמונה יש רוחב של 28 פיקסלים וגובה של 28 פיקסלים, ויש לה ערוץ צבעים אחד כי היא תמונה בגווני אפור. לכן, הצורה של כל תמונה היא [28, 28, 1].
חשוב לזכור שאנחנו מבצעים מיפוי של אחד עד עשר, וכן את הצורה של כל קלט לדוגמה, כי זה חשוב בקטע הבא.
5. הגדרת ארכיטקטורת המודל
בקטע הזה נכתוב קוד שמתאר את ארכיטקטורת המודל. ארכיטקטורת מודלים היא דרך מפוארת לומר "אילו פונקציות יפעילו את המודל כשהוא יבצע", או באיזה אלגוריתם ישתמש המודל שלנו כדי לחשב את התשובות שלו".
בלמידת מכונה אנחנו מגדירים ארכיטקטורה (או אלגוריתם) ומאפשרים לתהליך האימון ללמוד את הפרמטרים של אותו אלגוריתם.
מוסיפים את הפונקציה הבאה
script.js להגדרת ארכיטקטורת המודל
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
נבחן את הנושא לעומק.
השלכות
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
כאן אנחנו משתמשים במודל רציף.
אנחנו משתמשים בשכבה conv2d במקום בשכבה צפופה. אנחנו לא יכולים להיכנס לכל הפרטים על האופן שבו עובדות התנודות, אבל הנה כמה מקורות מידע שמסבירים את הפעולה הבסיסית:
בואו נפרט כל ארגומנט באובייקט ההגדרה של conv2d:
inputShapeצורת הנתונים שיזרמו לשכבה הראשונה של המודל. במקרה הזה, הדוגמאות שלנו ל-MNIST הן תמונות בשחור-לבן בגודל 28x28 פיקסלים. הפורמט הקנוני לנתוני תמונה הוא[row, column, depth], לכן כאן אנחנו רוצים להגדיר צורה של[28, 28, 1]. 28 שורות ועמודות למספר הפיקסלים בכל מימד, והעומק 1 כי לתמונות יש רק ערוץ צבעים אחד. שימו לב שאנחנו לא מציינים גודל אצווה בצורת הקלט. השכבות מתוכננות כך שלא יהיו אגנוסטיות בגודל האצווה, כך שבמהלך ההסקה תוכלו להעביר את Tensor מכל גודל אצווה.kernelSizeהגודל של חלונות המסננים המתקפלים ההזזה שיש להחיל על נתוני הקלט. כאן אנחנו מגדיריםkernelSizeשל5, שמציין חלון קונבולוציה ריבועי בגודל 5x5.filtersמספר חלונות הסינון בגודלkernelSizeשיש להחיל על נתוני הקלט. כאן נחיל 8 מסננים על הנתונים.strides"גודל השלבים" של חלון ההזזה - כלומר, כמה פיקסלים ישתנה המסנן בכל פעם שהוא ינוע על פני התמונה. כאן מציינים את הצעדים של 1, כך שהמסנן יחליק מעל התמונה בשלבים של פיקסל אחד.activationפונקציית ההפעלה שתחול על הנתונים לאחר השלמת הקונבולוציה. במקרה הזה אנחנו מחילים פונקציה מסוג Rectified Linear Unit (ReLU), שהיא פונקציית הפעלה נפוצה מאוד במודלים של למידת מכונה.kernelInitializerהשיטה שתשמש לאתחול אקראי של משקולות המודל, שחשובה מאוד לאימון של הדינמיקה. לא ניכנס כאן לפרטי האתחול, אבלVarianceScaling(משמש כאן) היא בחירה טובה לאתחול.
כיווץ ייצוג הנתונים שלנו
model.add(tf.layers.flatten());
תמונות הן נתונים בעלי ממדים גבוהים, ופעולות קונבולציה נוטות להגדיל את גודל הנתונים שנכללו בהן. לפני שנעביר אותם לשכבת הסיווג הסופית, עלינו לשטח את הנתונים למערך ארוך אחד. שכבות צפופות (שבהן אנחנו משתמשים כשכבה הסופית) נמשכות רק tensor1d שניות, לכן השלב הזה נפוץ במשימות סיווג רבות.
חישוב ההתפלגות הסופית שלנו
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
נשתמש בשכבה צפופה עם הפעלת softmax כדי לחשב את התפלגויות ההסתברות לפי 10 הסוגים האפשריים. הכיתה עם הציון הגבוה ביותר תהיה הספרה החזויה.
בחירה של פונקציית אופטימיזציה ואובדן
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
אנחנו יוצרים את המודל כדי לציין כלי אופטימיזציה, פונקציית הפסד ומדדים שאנחנו רוצים לעקוב אחריהם.
בניגוד למדריך הראשון, כאן אנחנו משתמשים ב-categoricalCrossentropy כפונקציית הפסד. כפי שמשתמע מהשם, משתמשים בהתפלגות הזאת כאשר הפלט של המודל שלנו הוא התפלגות הסתברות. categoricalCrossentropy מודד את השגיאה בין התפלגות ההסתברות שנוצרה על ידי השכבה האחרונה של המודל שלנו לבין התפלגות ההסתברות לפי התווית האמיתית שלנו.
לדוגמה, אם הספרה שלנו מייצגת באמת 7, ייתכן שיתקבלו התוצאות הבאות
אינדקס | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
תווית אמיתית | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
חיזוי | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
CategoricalCrossentropy תפיק מספר יחיד שמציין כמה וקטור החיזוי דומה לווקטור התווית האמיתי שלנו.
ייצוג הנתונים שבו משתמשים כאן לתוויות נקרא קידוד חד-פעמי והוא נפוץ בבעיות סיווג. לכל כיתה משויכת הסתברות לכל דוגמה. כשאנחנו יודעים בדיוק מה צריך להיות, אנחנו יכולים להגדיר את ההסתברות ל-1 ולשארות 0. מומלץ לעיין בדף הזה לקבלת מידע נוסף על קידוד חם.
המדד השני שנעקוב אחריו הוא accuracy, בשביל בעיית סיווג הוא אחוז החיזויים הנכונים מתוך כל החיזויים.
6. אימון המודל
מעתיקים את הפונקציה הבאה לקובץ script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
אחר כך מוסיפים את הקוד הבא אל
run .
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
צריך לרענן את הדף, ולאחר כמה שניות אמורים להופיע תרשימים שמדווחים על התקדמות האימון.
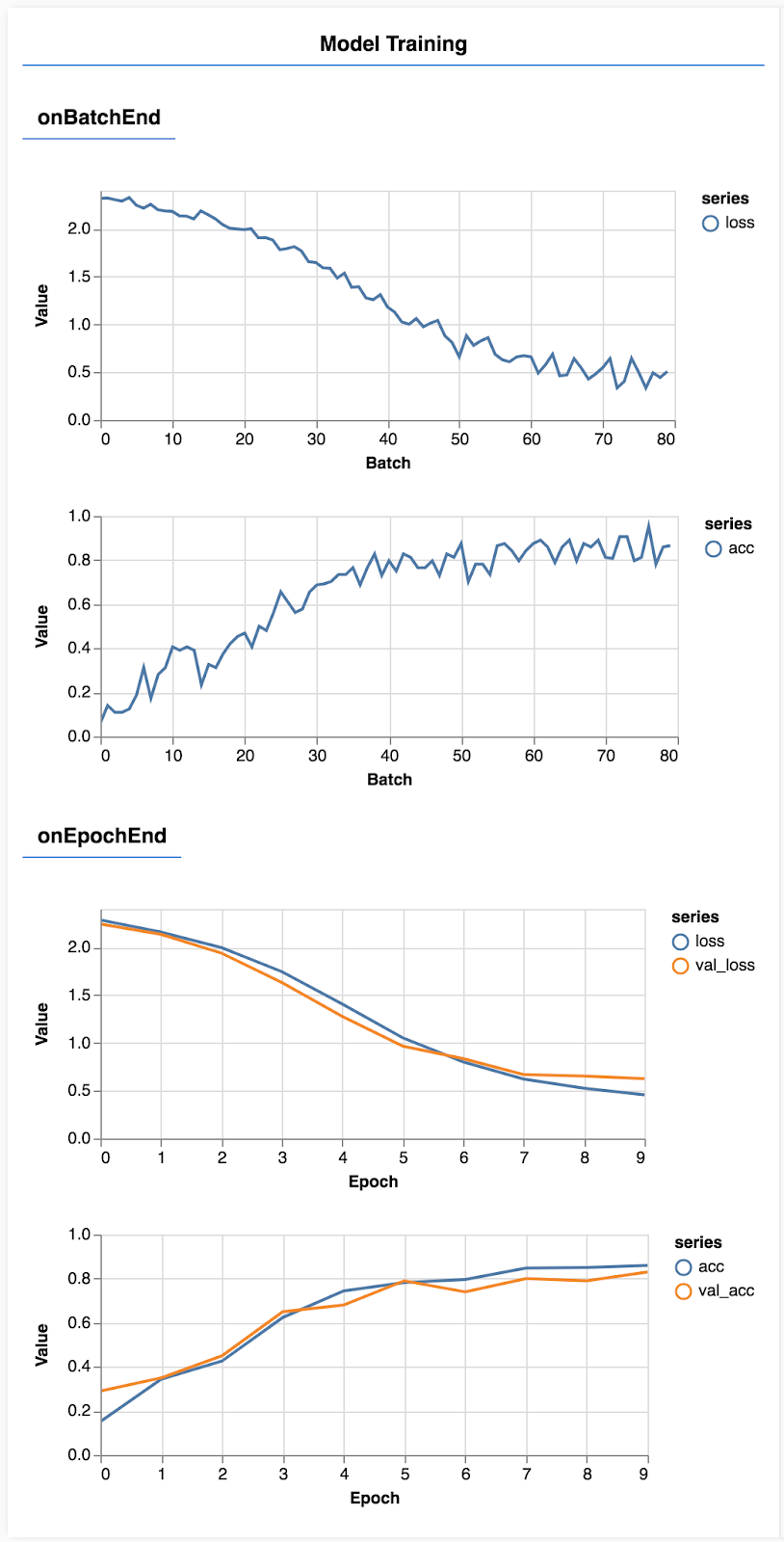
נבחן את הנושא לעומק.
מעקב אחרי המדדים
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
כאן אנו מחליטים אחרי אילו מדדים לעקוב. אנחנו נעקוב אחרי האובדן והדיוק באימון שנקבע, וגם נעקוב אחרי ההפסד והדיוק של קבוצת האימות (val_loss ו-val_acc בהתאמה). בהמשך נפרט מידע נוסף על קבוצת האימות.
הכנת נתונים כרכיבי tensor
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
כאן אנחנו יוצרים שני מערכי נתונים, ערכת אימון שלפיה נאמן את המודל וערכת אימות שבה נבדוק את המודל בסוף כל תקופה של זמן מערכת, אבל הנתונים בקבוצת האימות אף פעם לא מוצגים למודל במהלך האימון.
סיווג הנתונים שסיפקנו מאפשר לקבל בקלות רכיבי tensor מנתוני התמונה. עם זאת, אנחנו עדיין משנים את הפורמט של הגבולות לצורה שהמודל מצפה לה, [num_examples, image_width, image_height, channels], לפני שנוכל להזין אותם למודל. לכל מערך נתונים יש גם קלט (X) וגם תוויות (Ys).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
קוראים למודל model.fit כדי להתחיל את לולאת האימון. אנחנו גם מעבירים מאפיין ValidData כדי לציין באילו נתונים המודל צריך להשתמש כדי לבדוק את עצמו אחרי כל תקופה של זמן מערכת (אבל לא להשתמש בו לאימון).
אם נתוני האימון שלנו טובים אבל לא מתאימים לנתוני האימות שלנו, פירוש הדבר הוא שסביר להניח שהמודל מבצע התאמה לנתוני האימון ולא יכליל בצורה טובה קלט שהם לא היו בעבר.
7. להעריך את המודל שלנו
רמת הדיוק של האימות מספקת הערכה טובה לגבי הביצועים של המודל שלנו ביחס לנתונים שלא ראה בעבר (כל עוד הנתונים דומים לאלו של הניסוי בפועל). עם זאת, יכול להיות שנרצה לקבל פירוט רב יותר של הביצועים בין המחלקות השונות.
יש כמה שיטות ב-tfjs-vis שיוכלו לעזור לכם.
צריך להוסיף את הקוד הבא לתחתית הקובץ script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
למה הקוד הזה עושה?
- יוצר חיזוי.
- מחשב את מדדי הדיוק.
- הצגת המדדים
בואו נבחן כל שלב מקרוב.
ביצוע חיזויים
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
קודם כל צריך לבצע כמה חיזויים. בשלב הזה ניצור 500 תמונות ונ לחזות איזו ספרה נמצאת בהן (תוכלו להגדיל מספר זה מאוחר יותר כדי לבדוק על קבוצה גדולה יותר של תמונות).
חשוב לציין שהפונקציה argmax היא זו שמעניקה לנו את האינדקס של סיווג ההסתברות הגבוהה ביותר. חשוב לזכור שהמודל מפיק הסתברות לכל מחלקה. כאן אנו מוצאים את הסבירות הגבוהה ביותר ומקצים את השימוש בה כחיזוי.
ייתכן גם שתראו שאנחנו יכולים לבצע חיזויים לכל 500 הדוגמאות בבת אחת. זו עוצמת הווקטורים של TensorFlow.js.
הצגת הדיוק של כל כיתה
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
בעזרת קבוצה של חיזויים ותוויות, אנחנו יכולים לחשב את רמת הדיוק של כל מחלקה.
הצגה של מטריצת בלבול
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
מטריצת בלבול דומה לדיוק לפי כיתה, אבל מפצלת אותה עוד יותר כדי להציג דפוסים של סיווג שגוי. כדי לראות אם המודל מתבלבל בין צמדים מסוימים של מחלקות.
הצגת ההערכה
כדי להציג את ההערכה, צריך להוסיף את הקוד הבא לתחתית של פונקציית ההרצה.
await showAccuracy(model, data);
await showConfusion(model, data);
אתם אמורים לראות מסך שנראה כך.
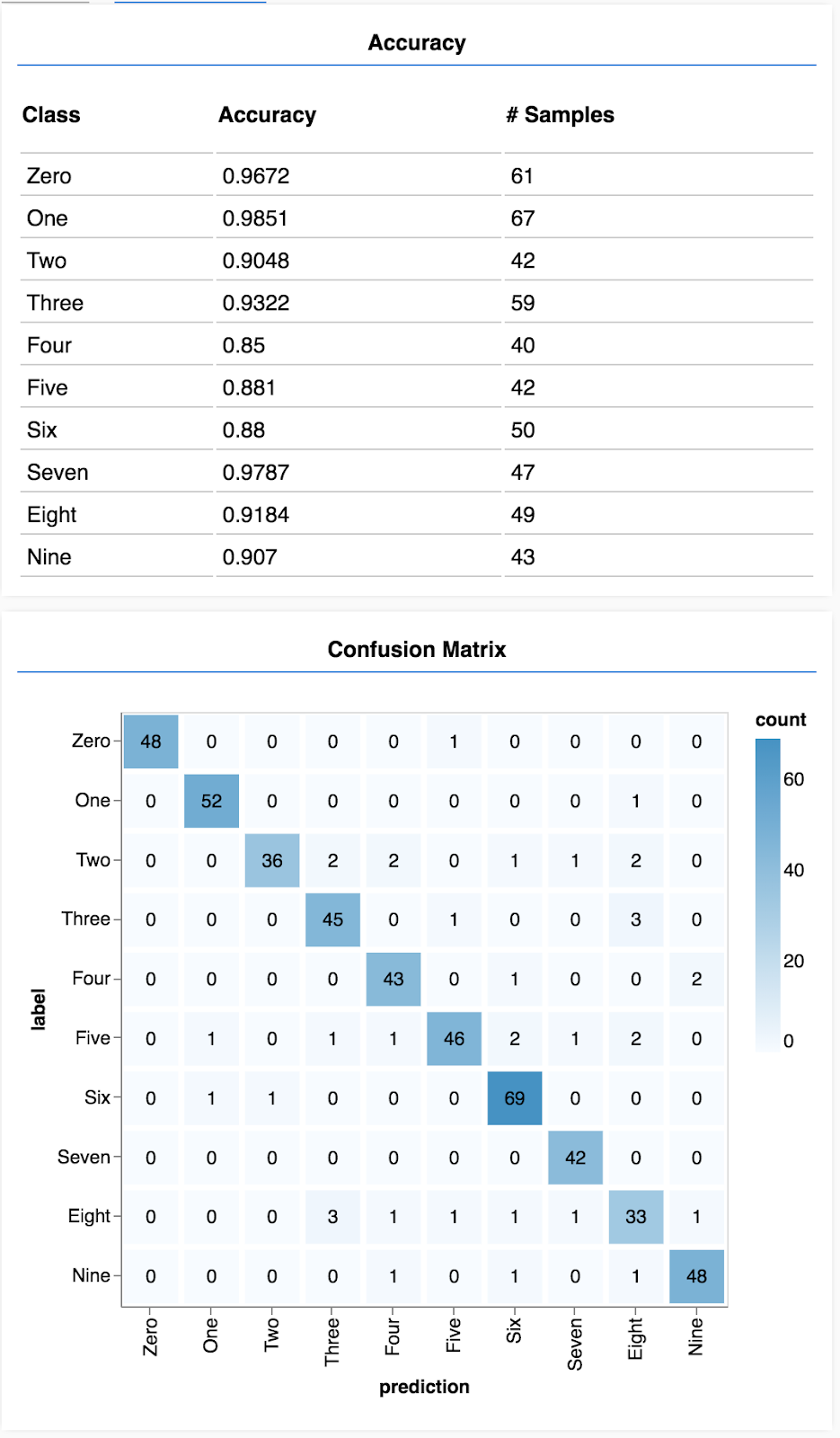
מזל טוב! אימנת עכשיו רשת נוירונים קונבולוציה!
8. המסקנות העיקריות
חיזוי הקטגוריות של נתוני הקלט נקרא 'משימת סיווג'.
למשימות של סיווג נדרש ייצוג נתונים מתאים עבור התוויות.
- ייצוגים נפוצים של תוויות כוללים קידוד חד-פעמי של קטגוריות
מכינים את הנתונים:
- כדאי לשמור בצד נתונים מסוימים שהמודל אף פעם לא רואה במהלך האימון, ולהשתמש בהם כדי להעריך את המודל. ההגדרה הזו נקראת קבוצת האימות.
בונים ומפעילים את המודל:
- הוכח שמודלים מסתובבים מניבים ביצועים טובים במשימות תמונה.
- בעיות סיווג בדרך כלל משתמשות באנטרופיה חובקת-קטגורית עבור פונקציות אובדן הנתונים.
- צריך לעקוב אחרי האימון כדי לראות אם האובדן יורד ואם רמת הדיוק עולה.
הערכת המודל
- אחרי שאומן את המודל, מחליטים איך להעריך את המודל בבעיה הראשונית שרצית לפתור.
- מטריצות ברמת הדיוק והבלבול לפי כיתה יכולות לספק פירוט מדויק יותר של ביצועי המודל מאשר רמת הדיוק הכוללת.