
1. مقدمة
سوف ننشئ في هذا البرنامج التعليمي نموذج TensorFlow.js للتعرف على الأرقام المكتوبة بخط اليد باستخدام شبكة عصبية التفافية. أولًا، سنطبق المصنِّف من خلال جعله يبدو الآلاف من صور الأرقام المكتوبة بخط اليد وتسمياتها. وبعد ذلك، سنقوم بتقييم دقة المُصنِّف باستخدام بيانات الاختبار التي لم يسبق أن شاهدها النموذج.
تُعد هذه المهمة مهمة تصنيف حيث نقوم بتدريب النموذج لتعيين فئة (الرقم الذي يظهر في الصورة) للصورة المدخلة. سنقوم بتدريب النموذج من خلال توضيح العديد من الأمثلة على المدخلات معه إلى جانب المخرجات الصحيحة. ويُشار إلى ذلك باسم التعلّم المُوجّه.
ما الذي ستقوم ببنائه
ستنشئ صفحة ويب تستخدم TensorFlow.js لتدريب نموذج في المتصفح. بناءً على صورة بالأبيض والأسود بحجم معين، سيتم تصنيف الرقم الذي يظهر في الصورة. الخطوات المعنية هي:
- تحميل البيانات.
- تحديد بنية النموذج.
- درِّب النموذج وراقب أدائه أثناء تدريبه.
- يمكنك تقييم النموذج المُدرَّب من خلال إجراء بعض التوقّعات.
المعلومات التي ستطّلع عليها
- بنية TensorFlow.js لإنشاء نماذج التفافية باستخدام واجهة برمجة التطبيقات TensorFlow.js Layers API.
- صياغة مهام التصنيف في TensorFlow.js
- كيفية مراقبة التدريب داخل المتصفح باستخدام مكتبة tfjs-vis.
المتطلبات
- يتوفّر إصدار حديث من Chrome أو متصفّح حديث آخر يتوافق مع وحدات ES6.
- محرّر نصوص يعمل محليًا على جهازك أو على الويب من خلال برامج مثل Codepen أو Glitch
- معرفة HTML وCSS وJavaScript وChrome DevTools (أو أدوات مطوري البرامج للمتصفحات المفضلة لديك).
- فهم مفاهيمي عالي المستوى للشبكات العصبية. إذا كنت بحاجة إلى مقدمة أو تنشيط للذاكرة، يمكنك مشاهدة هذا الفيديو من قناة 3blue1brown أو هذا الفيديو حول التعلم المتعمق بلغة JavaScript من إعداد "آشي كريشنان".
يجب أيضًا أن تعرف المواد الواردة في البرنامج التعليمي الأول.
2. الإعداد
إنشاء صفحة HTML وتضمين JavaScript
 انسخ الرمز التالي إلى ملف html باسم
انسخ الرمز التالي إلى ملف html باسم
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
إنشاء ملفات JavaScript للبيانات والرمز
- في المجلد نفسه الذي يضم ملف HTML أعلاه، أنشئ ملفًا باسم ملف data.js وانسخ المحتوى من هذا الرابط إلى ذلك الملف.
- في المجلد نفسه كخطوة أولى، أنشِئ ملفًا باسم script.js وضَع الرمز التالي فيه.
console.log('Hello TensorFlow');
تجربة الميزة
الآن بعد الانتهاء من إنشاء ملفات HTML وJavaScript، جرِّبها. افتح ملف index.html في المتصفح وافتح وحدة التحكم في أدوات dev.
إذا كان كل شيء يعمل، يجب أن يكون هناك متغيران عموميان. العلامة tf هي مرجع لمكتبة TensorFlow.js، وسمة tfvis هي مرجع إلى مكتبة tfjs-vis.
من المفترض أن تظهر لك رسالة نصها Hello TensorFlow, وفي هذه الحالة، يعني ذلك أنّك جاهز للانتقال إلى الخطوة التالية.
3- تحميل البيانات
في هذا البرنامج التعليمي، ستتدرب على نموذج لتعلم كيفية التعرف على الأرقام في الصور مثل تلك الموجودة أدناه. حجم هذه الصور هو 28×28 بكسل بتدرج الرمادي من مجموعة بيانات تسمى MNIST.

لقد وفّرنا رمزًا لتحميل هذه الصور من ملف رموز متحركة خاص (بحجم 10 ميغابايت تقريبًا) أنشأناه لك لكي نتمكّن من التركيز على الجزء المخصّص للتدريب.
يمكنك دراسة ملف data.js للتعرّف على كيفية تحميل البيانات. أو بمجرد الانتهاء من هذا البرنامج التعليمي، قم بإنشاء نهجك الخاص لتحميل البيانات.
يحتوي الرمز المقدّم على فئة MnistData تستخدِم طريقتَين عامتَين:
nextTrainBatch(batchSize): يعرض هذا الإجراء مجموعة عشوائية من الصور وتصنيفاتها من مجموعة التدريب.nextTestBatch(batchSize): يعرض هذا الإجراء مجموعة من الصور وتصنيفاتها من مجموعة الاختبار.
وتنفِّذ فئة MnistData أيضًا الخطوات المهمة المتعلقة بالترتيب العشوائي وتسوية البيانات.
هناك 65,000 صورة إجمالاً، وسنستخدم ما يصل إلى 55,000 صورة لتدريب النموذج، وسنحفظ 10,000 صورة يمكننا استخدامها لاختبار أداء النموذج عند الانتهاء. وسنعمل على تنفيذ كل ذلك في المتصفح!
لنقم بتحميل البيانات ونختبر ما إذا تم تحميلها بشكل صحيح.
أضِف الرمز التالي إلى ملف script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
أعِد تحميل الصفحة، وبعد بضع ثوانٍ، من المفترض أن تظهر لوحة على اليمين تتضمّن عددًا من الصور.

4. تصور مهمتنا
تبدو بيانات الإدخال لدينا على النحو التالي.
هدفنا هو تدريب نموذج يأخذ صورة واحدة ويتعلّم كيفية توقُّع نتيجة لكل فئة من الفئات العشرة المحتملة التي قد تنتمي إليها الصورة (الأرقام من 0 إلى 9).
يبلغ عرض كل صورة 28 بكسل وارتفاع 28 بكسل ولها قناة ألوان واحدة؛ حيث إنها صورة بتدرج رمادي. وبالتالي، يكون شكل كل صورة [28, 28, 1].
تذكر أننا نقوم بتعيين واحد إلى عشرة، وكذلك شكل كل مثال إدخال، حيث إنه مهم للقسم التالي.
5- تحديد بنية النموذج
سنكتب في هذا القسم تعليمات برمجية لوصف بنية النموذج. تُعدّ بنية النموذج طريقة رائعة للتعبير عن "الوظائف التي سيتم تشغيل النموذج عند تنفيذها"، أو بدلاً من ذلك، "ما الخوارزمية التي سيستخدمها نموذجنا لحساب إجاباته".
في التعلم الآلي نحدد بنية (أو خوارزمية) ونترك لعملية التطبيق إمكانية التعرف على معاملات تلك الخوارزمية.
أضِف الدالة التالية إلى
script.js لتحديد بنية النموذج
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
دعنا ننظر في هذا الأمر بمزيد من التفصيل.
الالتفاف
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
هنا نستخدم نموذجًا متسلسلاً.
نستخدم طبقة conv2d بدلاً من طبقة كثيفة. لا يمكننا الخوض في جميع التفاصيل المتعلقة بطريقة عمل الالتفاف، ولكن إليك بعض الموارد التي تشرح العملية الأساسية:
لنقسم كل وسيطة في كائن الإعدادات لـ conv2d:
inputShapeيشير ذلك المصطلح إلى شكل البيانات التي ستتدفق إلى الطبقة الأولى من النموذج. في هذه الحالة، تكون أمثلة MNIST لدينا هي صور بالأبيض والأسود بحجم 28x28 بكسل. التنسيق الأساسي لبيانات الصور هو[row, column, depth]، لذا نريد هنا ضبط شكل[28, 28, 1]. 28 صفًا وعمودًا لعدد وحدات البكسل في كل بُعد، وعمق 1 لأن صورنا تحتوي على قناة ألوان واحدة فقط. لاحظ أننا لا نحدد حجم دفعة في شكل الإدخال. تم تصميم الطبقات بحيث تكون غير متوافقة مع حجم الدفعة، بحيث يمكنك تمرير متوتر من أي حجم دفعة أثناء الاستنتاج.kernelSizeحجم نوافذ الفلاتر الالتفافية المنزلقة التي سيتم تطبيقها على بيانات الإدخال. يتم هنا ضبطkernelSizeلـ5، والتي تحدد نافذة التفافية مربّعة بحجم 5x5.filtersعدد نوافذ الفلترة ذات الحجمkernelSizeالمطلوب تطبيقها على بيانات الإدخال. هنا، سنطبق 8 عوامل تصفية على البيانات.strides"حجم الخطوة" نافذة التمرير - أي عدد وحدات البكسل التي سيغيرها عامل التصفية في كل مرة يتحرك فيها فوق الصورة. نحدد هنا خطوات من 1، مما يعني أن عامل التصفية سينزلق فوق الصورة في خطوات 1 بكسل.activationدالة التفعيل المطلوب تطبيقها على البيانات بعد اكتمال عملية الالتفاف. وفي هذه الحالة، سنطبّق دالة الوحدة الخطية المستقيمة (ReLU)، وهي دالة تفعيل شائعة جدًا في نماذج تعلُّم الآلة.kernelInitializerيشير ذلك المصطلح إلى طريقة الاستخدام في الإعداد العشوائي لقيم ترجيح النموذج، وهي طريقة بالغة الأهمية لتدريب الديناميكيات. لن ندخل في تفاصيل الإعداد هنا، ولكنVarianceScaling(المستخدم هنا) يُعدّ بصفة عامة خيارًا جيدًا للإعداد.
تنظيم تمثيل البيانات لدينا
model.add(tf.layers.flatten());
تعد الصور بيانات ذات أبعاد عالية، وتميل عمليات الالتفاف إلى زيادة حجم البيانات التي تحتوي عليها. قبل تمريرها إلى طبقة التصنيف النهائية، نحتاج إلى تسوية البيانات في صفيف واحد طويل. لا تأخذ الطبقات الكثيفة (التي نستخدمها كطبقة نهائية) سوى tensor1ds، ولذلك تعتبر هذه الخطوة شائعة في العديد من مهام التصنيف.
حساب التوزيع النهائي للاحتمالية
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
سنستخدم طبقة كثيفة مع تنشيط softmax لحساب توزيعات الاحتمالية على عشر فئات محتملة. وستكون الفئة التي تحصل على أعلى نتيجة هي الرقم المتنبأ به.
اختيار مُحسِّن ودالة الخسارة
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
نجمع النموذج الذي يحدّد المحسّن ودالة الخسارة والمقاييس التي نريد تتبّعها.
على عكس البرنامج التعليمي الأول، نستخدم هنا categoricalCrossentropy كدالة الخسارة. وكما يوحي الاسم، يتم استخدام هذا عندما يكون ناتج النموذج هو توزيع الاحتمالية. تقيس categoricalCrossentropy الخطأ بين توزيع الاحتمالية الذي تم إنشاؤه من خلال الطبقة الأخيرة من النموذج وتوزيع الاحتمالية المحدد من خلال التصنيف الصحيح.
على سبيل المثال، إذا كان الرقم يمثل 7 حقًا، قد نحصل على النتائج التالية
الفهرس | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
تصنيف صحيح | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
التوقّع | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
سينتج القصور المتقاطع الفئوي رقمًا واحدًا يشير إلى مدى تشابه خط متجه التنبؤ مع الخط المتجه للتصنيف الفعلي.
يُطلق على تمثيل البيانات المستخدَم هنا للتصنيفات اسم ترميز واحد فعال، وهو شائع في مشاكل التصنيف. لكل فئة احتمالية مرتبطة بها لكل مثال. وعندما نعرف بالضبط ما ينبغي أن تكون عليه، يمكننا تعيين تلك الاحتمالية على 1 والأخرى على 0. راجِع هذه الصفحة للحصول على مزيد من المعلومات حول الترميز الأحادي.
المقياس الآخر الذي سنراقبه هو "accuracy"، وهو بالنسبة إلى مشكلة التصنيف، هو النسبة المئوية لعبارات البحث المقترحة الصحيحة من بين جميع التوقّعات.
6- تدريب النموذج
انسخ الدالة التالية إلى ملف script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
بعد ذلك، أضِف الرمز التالي إلى
run .
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
حدّث الصفحة، وبعد بضع ثوانٍ من المفترض أن تظهر لك بعض الرسوم البيانية التي توضح تقدم التدريب.
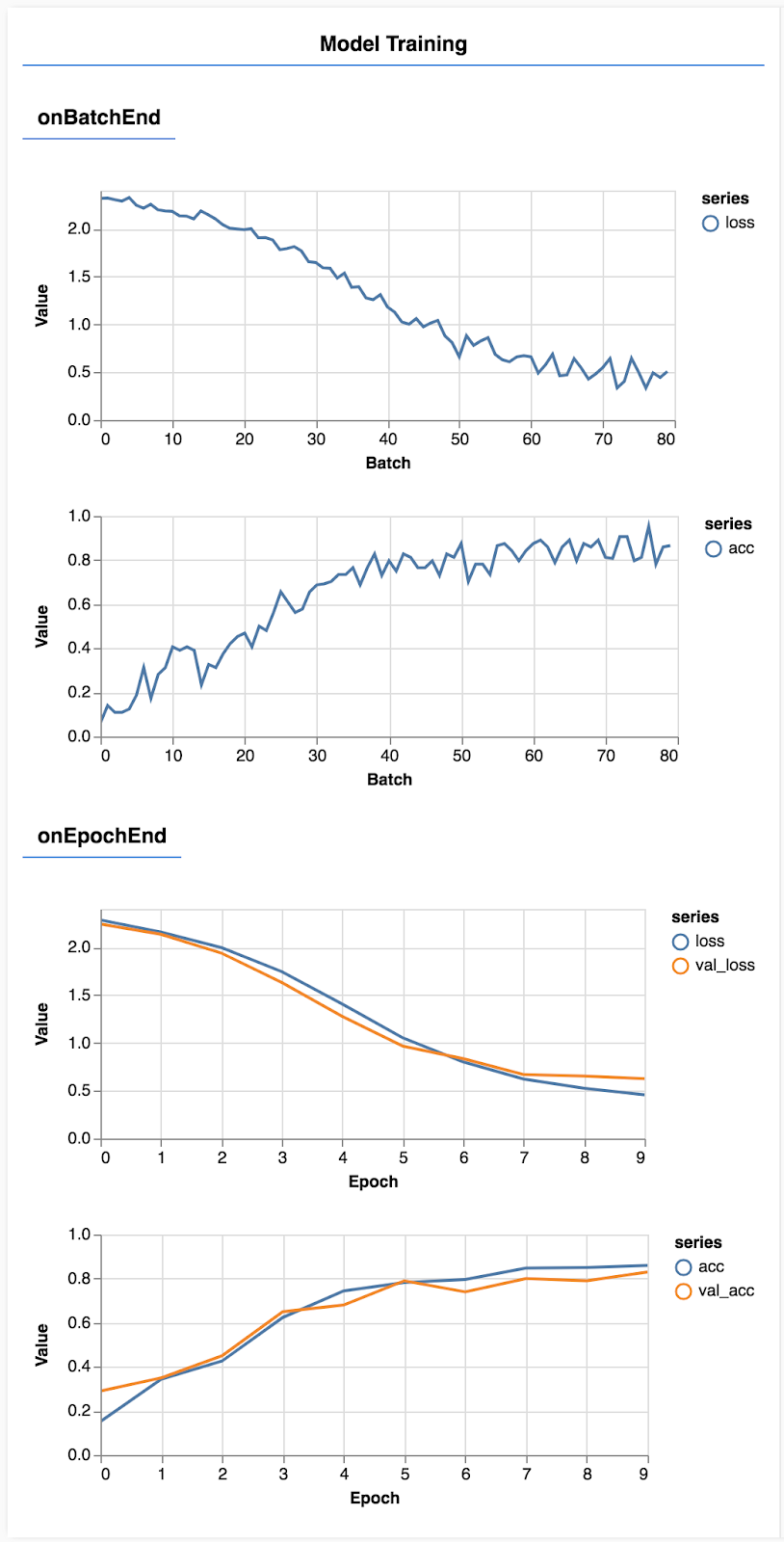
دعونا نلقي نظرة على ذلك بمزيد من التفصيل.
مراقبة المقاييس
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
هنا نقرّر المقاييس التي سنراقبها. سيتم رصد فقدان البيانات ودقتها في مجموعة التدريب، بالإضافة إلى رصد فقدانها ودقتها في مجموعة التحقّق (val_loss وval_acc على التوالي). سنتحدّث أكثر عن عملية التحقّق المحدّدة أدناه.
إعداد البيانات كعناصر مترابطة
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
هنا نضع مجموعتين، وهي مجموعة تدريب سيتم تطبيق النموذج عليها، ومجموعة تحقق سنختبر النموذج عليها في نهاية كل حقبة، ومع ذلك لا تظهر البيانات الموجودة في مجموعة التحقق أبدًا للنموذج أثناء التدريب.
تسهل فئة البيانات التي قدمناها الحصول على أدوات التوتر من بيانات الصورة. مع ذلك، ما زلنا نعيد تشكيل المؤشرات في الشكل الذي يتوقّعه النموذج، [num_examples, image_width, image_height, channels]، قبل أن نتمكّن من إدخال هذه القيم في النموذج. لكل مجموعة بيانات، لدينا كلاً من المدخلات (Xs) والتسميات (Ys).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
نستدعي model.fit لبدء حلقة التدريب. ونمرّر أيضًا خاصية التحقّق من صحة البيانات للإشارة إلى البيانات التي يجب أن يستخدمها النموذج لاختبار نفسه بعد كل حقبة (ولكن ليس استخدامها للتدريب).
إذا نجحنا في استخدام بيانات التدريب ولكن ليس على بيانات التحقق من الصحة، هذا يعني أنّ النموذج من المحتمل أن يكون مفرطًا في بيانات التدريب ولن يتم تعميم البيانات بشكل جيد لإدخاله بطريقة لم يسبق لها مثيل.
7. تقييم النموذج
توفر دقة التحقق من الصحة تقديرًا جيدًا حول مدى جودة أداء نموذجنا على البيانات التي لم يسبق لها رؤيته (طالما أن هذه البيانات تشبه مجموعة التحقق من الصحة بطريقة ما). ومع ذلك، قد نحتاج إلى تفاصيل أكثر عن الأداء على مستوى الفئات المختلفة.
هناك طريقتان في tfjs-vis يمكنهما مساعدتك في ذلك.
أضِف الرمز التالي إلى أسفل ملف script.js.
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
ما الذي تفعله هذه التعليمة البرمجية؟
- يؤدي إلى توقُّع.
- تحسب مقاييس الدقة.
- عرض المقاييس
لنلقِ نظرة فاحصة على كل خطوة.
وضع توقّعات
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
نحتاج أولاً إلى إجراء بعض التنبؤات. هنا سوف نلتقط 500 صورة ونتوقع رقمها (يمكنك زيادة هذا العدد لاحقًا لاختبار مجموعة أكبر من الصور).
ومن الجدير بالذكر أن الدالة argmax هي التي تعطينا فهرسًا لفئة الاحتمالية الأعلى. تذكر أن النموذج ينتج احتمالية لكل فئة. وهنا نجد أعلى الاحتمالية ونُعين ذلك كتنبؤ.
قد تلاحظ أيضًا أنه يمكننا وضع توقعات على جميع الأمثلة الـ 500 مرة واحدة. هذه هي قوة الخط المتجه التي توفرها TensorFlow.js.
عرض الدقة لكل صف
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
وباستخدام مجموعة من التنبؤات والتصنيفات، يمكننا حساب مدى دقة كل فئة.
إظهار مصفوفة الالتباس
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
تشبه مصفوفة التشويش الدقة لكل فئة ولكنها تقسمها بشكل أكبر لإظهار أنماط التصنيف الخاطئ. وهو يتيح لك معرفة ما إذا كان هناك ارتباك في النموذج بشأن أي أزواج معينة من الفئات.
عرض التقييم
أضِف الرمز التالي أسفل دالة التشغيل لإظهار التقييم.
await showAccuracy(model, data);
await showConfusion(model, data);
من المفترض أن تظهر لك شاشة على النحو التالي:
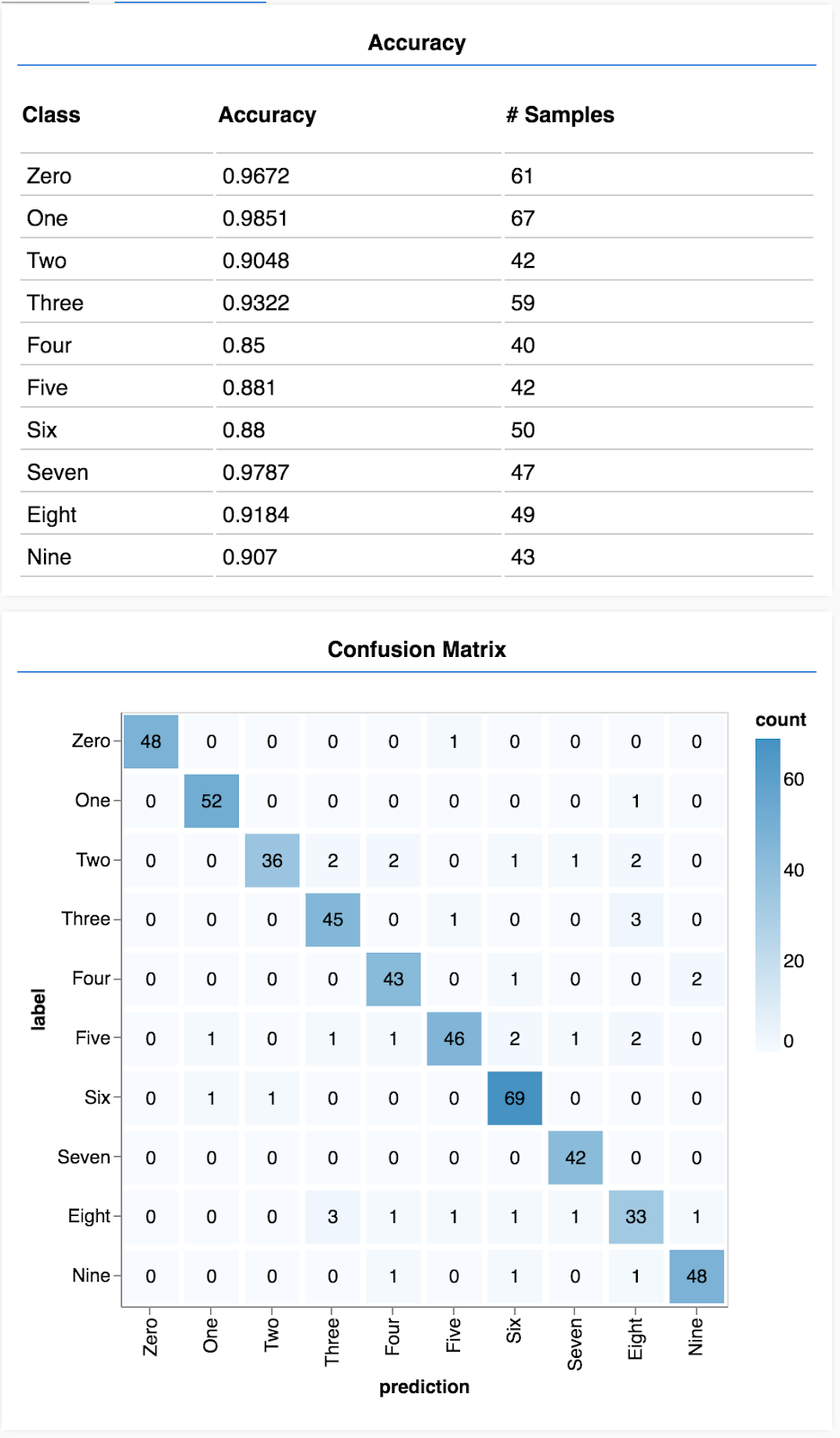
تهانينا! لقد درّبت للتو شبكة عصبية التفافية!
8. النصائح الرئيسية
يُطلق على التنبؤ بفئات البيانات المدخلة مهمة التصنيف.
تتطلب مهام التصنيف تمثيل بيانات مناسبًا للتسميات
- تشتمل التمثيلات الشائعة للتصنيفات على ترميز واحد فعال للفئات
إعداد بياناتك:
- من المفيد الاحتفاظ ببعض البيانات التي لا يراها النموذج أبدًا أثناء التدريب، ويمكنك استخدامها لتقييم النموذج. تُسمى هذه مجموعة التحقق من الصحة.
إنشاء النموذج وتشغيله:
- لقد ثبت أنّ النماذج الالتفافية تحقّق أداءً جيدًا في مهام الصور.
- تستخدم مشكلات التصنيف عادة القصور التبادلي الفئوي لدوال الخسارة الخاصة بها.
- راقب التدريب لمعرفة ما إذا كانت الخسارة تنخفض وترتفع الدقة.
تقييم النموذج
- حدِّد طريقة ما لتقييم نموذجك بعد تدريبه لمعرفة مستوى أدائه في المشكلة الأولية التي أردت حلّها.
- يمكن أن تمنحك مصفوفات الدقة والتشويش حسب كل فئة تقسيمًا أدق لأداء النموذج بدلاً من الدقة الكلية فقط.