
1. Giriş
Bu eğiticide, konvolüsyonel nöral ağ ile el yazısı sayıları tanımak için bir TensorFlow.js modeli oluşturacağız. İlk olarak, sınıflandırıcıyı "görünüm" ve dijital resimler ve etiketlerde arama yapın. Ardından, modelin hiç görmediği test verilerini kullanarak sınıflandırıcının doğruluğunu değerlendiririz.
Bu görev, giriş görüntüsüne bir kategori (resimde görünen basamak) atamak üzere modeli eğittiğimizden, bir sınıflandırma görevi olarak kabul edilir. Doğru çıkışla birlikte birçok giriş örneği göstererek modeli eğiteceğiz. Buna gözetimli öğrenme adı verilir.
Ne oluşturacaksınız?
Tarayıcıda bir modeli eğitmek için TensorFlow.js kullanan bir web sayfası oluşturacaksınız. Belirli bir boyuttaki siyah beyaz resim göz önünde bulundurulduğunda, resimde hangi rakamın göründüğünü sınıflandırır. İlgili adımlar şunlardır:
- Verileri yükleyin.
- Modelin mimarisini tanımlayın.
- Modeli eğitin ve eğitilirken performansını izleyin.
- Bazı tahminler yaparak eğitilen modeli değerlendirin.
Neler öğreneceksiniz?
- TensorFlow.js Katmanlar API'sini kullanarak evrişimsel modeller oluşturmak için TensorFlow.js söz dizimi.
- TensorFlow.js'de sınıflandırma görevlerini formüle etme
- tfjs-vis kitaplığını kullanarak tarayıcı içi eğitim nasıl izlenir?
Gerekenler
- Chrome'un son sürümü veya ES6 modüllerini destekleyen başka bir modern tarayıcı.
- Makinenizde yerel olarak veya Codepen ya da Glitch gibi bir araçla web'de çalışan bir metin düzenleyici.
- HTML, CSS, JavaScript ve Chrome Geliştirici Araçları (veya tercih ettiğiniz tarayıcı geliştirme araçları) hakkında bilgi sahibi olmanız gerekir.
- Nöral Ağlarla ilgili üst düzey kavramsal bilgiler. Giriş veya bilgilerinizi tazelemek isterseniz 3blue1brown adlı bu videoyu veya Ashi Krishnan'ın JavaScript'te Derin Öğrenme konulu bu videosunu izleyebilirsiniz.
Ayrıca ilk eğitim eğitimimizdeki materyale de aşina olacaksınız.
2. Hazırlanın
HTML sayfası oluşturma ve JavaScript'i dahil etme
 Aşağıdaki kodu,
Aşağıdaki kodu,
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Veriler ve kod için JavaScript dosyalarını oluşturma
- Yukarıdaki HTML dosyasıyla aynı klasörde, data.js dosyası adında bir dosya oluşturun ve bu bağlantıdan içeriği söz konusu dosyaya kopyalayın.
- Birinci adımla aynı klasörde, script.js adlı bir dosya oluşturun ve aşağıdaki kodu bu dosyanın içine girin.
console.log('Hello TensorFlow');
Test edin
HTML ve JavaScript dosyalarınızı oluşturduğunuza göre şimdi test edebilirsiniz. Tarayıcınızda index.html dosyasını açın ve devtools konsolunu açın.
Her şey yolundaysa iki genel değişken oluşturulmalıdır. tf, TensorFlow.js kitaplığına, tfvis ise tfjs-vis kitaplığına referanstır.
Hello TensorFlow, yazan bir mesaj görürsünüz. Bu durumda sonraki adıma geçmeye hazırsınız demektir.
3. Verileri yükleme
Bu eğiticide, bir modeli resimlerdeki sayıları aşağıdaki gibi tanımayı öğrenecek şekilde eğiteceksiniz. Bu görüntüler, MNIST adlı bir veri kümesinden alınan 28x28 piksellik gri tonlamalı görüntülerdir.

Bu resimleri, eğitim bölümüne odaklanabilmek için sizin için oluşturduğumuz özel bir sprite dosyasından (yaklaşık 10 MB) yüklemek üzere kod sağladık.
Verilerin nasıl yüklendiğini anlamak için data.js dosyasını inceleyebilirsiniz. Bu eğiticiyi tamamladıktan sonra verileri yüklemeyle ilgili kendi yaklaşımınızı da oluşturabilirsiniz.
Sağlanan kod, herkese açık iki yöntemi olan bir MnistData sınıfı içeriyor:
nextTrainBatch(batchSize): Eğitim kümesinden rastgele bir resim grubu ve bunların etiketlerini döndürür.nextTestBatch(batchSize): Test kümesinden bir grup resmi ve bunların etiketlerini döndürür
MnistData sınıfı, verileri karıştırma ve normalleştirme gibi önemli adımları da gerçekleştirir.
Toplam 65.000 görüntü vardır. Modeli eğitmek için 55.000'e kadar resim kullanırız. İşlem tamamlandığında modelin performansını test etmek için kullanabileceğimiz 10.000 resim kaydedilir. Ve tüm bunları tarayıcıda yapacağız!
Şimdi verileri yükleyelim ve verilerin doğru yüklenip yüklenmediğini test edelim.
Script.js dosyanıza aşağıdaki kodu ekleyin.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Sayfayı yenileyin. Birkaç saniye sonra, sol tarafta çeşitli resimlerin yer aldığı bir panel görürsünüz.

4. Görevimizi kavramaya çalışın
Giriş verilerimiz aşağıdaki gibi görünür.
Amacımız, bir resim alacak ve bir resmin ait olabileceği olası 10 sınıftan her birinin puanını (0-9 arasındaki rakamlar) tahmin etmeyi öğrenecek bir model eğitmektir.
Her resim 28 piksel genişliğinde 28 piksel yüksekliğindedir ve gri tonlamalı bir resim olduğu için 1 renk kanalına sahiptir. Dolayısıyla her bir resmin şekli [28, 28, 1] şeklindedir.
Bir sonraki bölüm için önemli olduğundan, her bir giriş örneğinin şeklinin yanı sıra 1-1 arası bir eşleme yaptığımızı unutmayın.
5. Model mimarisini tanımlama
Bu bölümde, model mimarisini açıklamak için kod yazacağız. Model mimarisi, "model çalışırken hangi işlevleri çalıştıracak?" veya "modelimiz yanıtlarını hesaplamak için hangi algoritmayı kullanacak?" gibi bir ifade anlamına gelir.
Makine öğreniminde bir mimari (veya algoritma) tanımlar ve eğitim sürecinin o algoritmanın parametrelerini öğrenmesini sağlarız.
Aşağıdaki işlevi uygulamanıza ekleyin:
script.js model mimarisini tanımlamak için dosya
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Bunu biraz daha ayrıntılı bir şekilde inceleyelim.
Konvolüsyonlar
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Burada sıralı model kullanıyoruz.
Yoğun bir katman yerine conv2d katmanı kullanıyoruz. Evrimlerin işleyiş şekliyle ilgili tüm ayrıntılara girmemiz mümkün olmasa da temel işlemi açıklayan birkaç kaynak aşağıda verilmiştir:
conv2d için yapılandırma nesnesindeki her bağımsız değişkeni ayrıntılı olarak inceleyelim:
inputShapeModelin ilk katmanına akacak verilerin şekli. Bu örnekte, MNIST örneklerimiz 28x28 piksel siyah beyaz resimlerdir. Resim verilerinin standart biçimi[row, column, depth]olduğundan burada[28, 28, 1]şeklini yapılandırmak istiyoruz. Resimlerimizin yalnızca 1 renk kanalına sahip olduğundan, her bir boyuttaki piksel sayısı için 28 satır ve sütun, derinlik ise 1 olarak belirlenmiştir. Giriş şeklinde bir grup boyutu belirtmediğimizi unutmayın. Katmanlar, grup boyutundan bağımsız olacak şekilde, çıkarım sırasında herhangi bir grup boyutunda bir tensörü geçirebilirsiniz.kernelSizeGiriş verilerine uygulanacak kayan konvolüsyonlu filtre pencerelerinin boyutu. Burada5içinkernelSizedeğeri ayarlıyoruz. Bu değer, kare şeklinde, 5x5 boyutunda kıvrımlı bir pencere belirtir.filters. Giriş verilerine uygulanacakkernelSizeboyutundaki filtre aralıklarının sayısı. Burada, verilere 8 filtre uygulayacağız.strides. "Adım boyutu" yani filtrenin resim üzerinde her hareket ettiğinde kaç piksel kaydıracağı anlamına gelir. Burada, basamakları 1 olarak belirtiriz. Bu, filtrenin 1 piksellik adımlarda resim üzerinde kayacağı anlamına gelir.activationEvrim tamamlandıktan sonra verilere uygulanacak etkinleştirme işlevi. Bu örnekte, ML modellerinde çok yaygın olarak kullanılan bir etkinleştirme işlevi olan Düzgünleştirilmiş Doğrusal Birim (ReLU) işlevini uyguluyoruz.kernelInitializerDinamikleri eğitmek için çok önemli olan, model ağırlıklarını rastgele başlatmak için kullanılacak yöntem. Burada başlatmayla ilgili ayrıntılara girmeyeceğiz, ancakVarianceScaling(burada kullanılır) genellikle iyi bir başlatıcı seçimidir.
Veri temsilimizi sadeleştirme
model.add(tf.layers.flatten());
Görüntüler yüksek boyutlu verilerdir ve kıvrım işlemleri, bu tür resimlere aktarılan verilerin boyutunu artırma eğilimindedir. Bunları son sınıflandırma katmanımıza iletmeden önce, verileri tek bir uzun dizide birleştirmemiz gerekir. Son katmanımız olarak kullandığımız yoğun katmanlar yalnızca tensor1d saniye sürdüğünden bu adım birçok sınıflandırma görevinde yaygındır.
Nihai olasılık dağılımımızı hesaplayın
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
10 olası sınıftaki olasılık dağılımlarını hesaplamak için softmax etkinleştirmesine sahip yoğun bir katman kullanacağız. En yüksek puana sahip sınıf, tahmin edilen basamak olur.
Optimize Edici ve kayıp işlevi seçme
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Modeli, bir optimize edici, kayıp işlevi ve takip etmek istediğimiz metrikleri belirterek derleriz.
Buradaki ilk eğiticimizin aksine categoricalCrossentropy kayıp işlevimiz olarak kullanılır. Adından da anlaşılacağı gibi, bu ifade, modelimizin çıktısı bir olasılık dağılımı olduğunda kullanılır. categoricalCrossentropy, modelimizin son katmanının oluşturduğu olasılık dağılımı ile doğru etiketimizin sağladığı olasılık dağılımı arasındaki hatayı ölçer.
Örneğin, basamağımız gerçekten 7 sayısını temsil ediyorsa aşağıdaki sonuçları elde edebiliriz
Dizin | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Doğru Etiket | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Tahmin | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
Kategorik çapraz entropi, tahmin vektörünün gerçek etiket vektörümüze ne kadar benzer olduğunu gösteren tek bir sayı üretir.
Burada etiketler için kullanılan veri gösterimine tek seferlik kodlama adı verilir ve bu gösterim, sınıflandırma sorunlarında yaygındır. Her sınıfın her örnek için kendisiyle ilişkilendirilmiş bir olasılığı vardır. Değerin ne olması gerektiğini tam olarak bildiğimizde o olasılığı 1’e, diğerlerini 0’a ayarlayabiliriz. Tek seferlik kodlama hakkında daha fazla bilgi edinmek için bu sayfaya bakın.
İzleyeceğimiz diğer metrik olan accuracy, sınıflandırma sorunları için tüm tahminler arasındaki doğru tahminlerin yüzdesidir.
6. Modeli Eğitme
Aşağıdaki işlevi script.js dosyanıza kopyalayın.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Ardından, aşağıdaki kodu şuraya ekleyin:
run işlevi.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Sayfayı yenileyin. Birkaç saniye sonra, eğitimin ilerlemesini bildiren bazı grafikler görürsünüz.
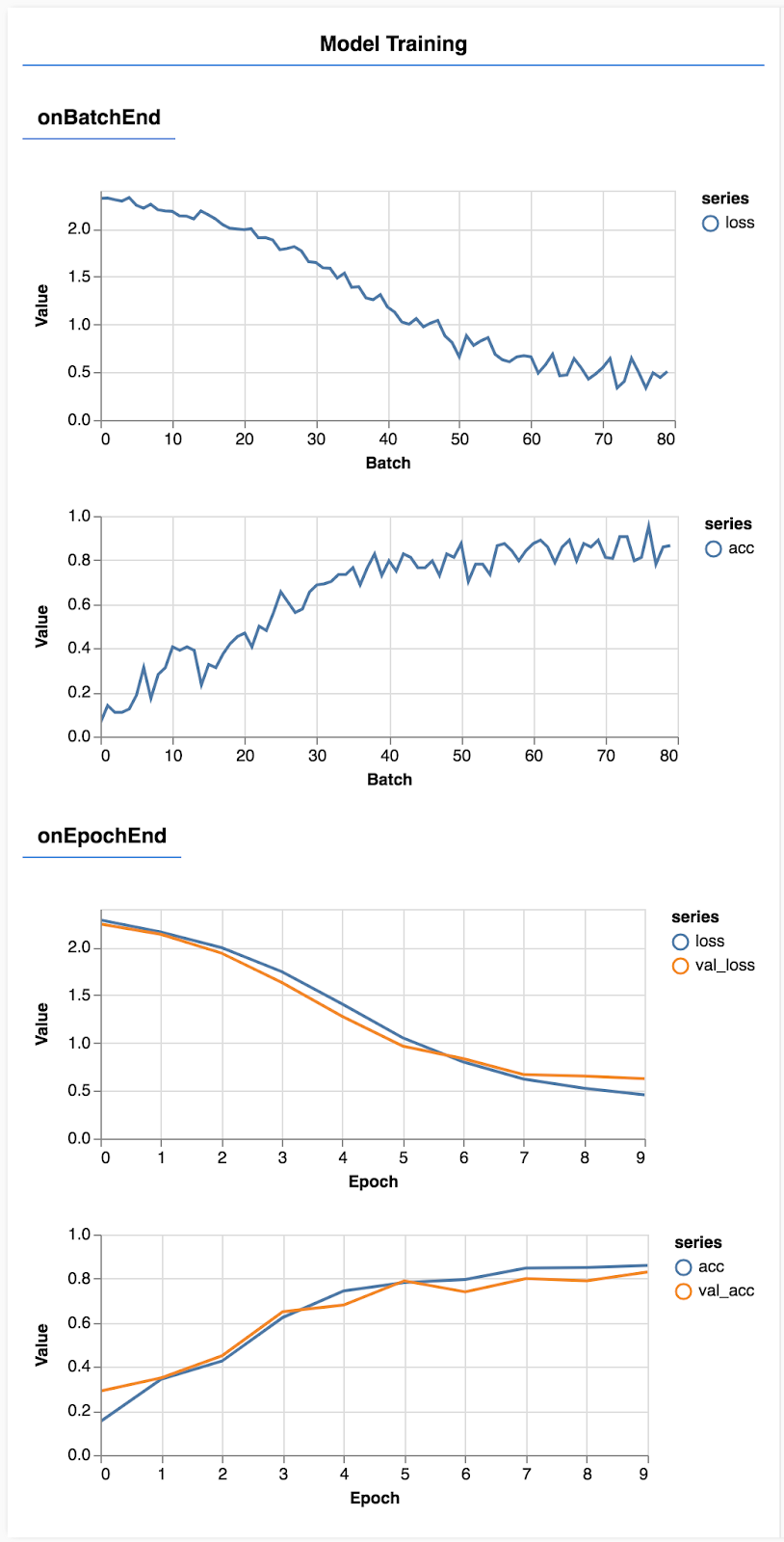
Bunu biraz daha ayrıntılı bir şekilde inceleyelim.
Metrikleri izleme
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Burada, hangi metrikleri izleyeceğimize karar veririz. Eğitim veri kümesindeki kayıp ve doğruluğun yanı sıra doğrulama kümesindeki (sırasıyla val_loss ve val_acc) kayıp ve doğruluğu izleyeceğiz. Aşağıda ayarlanan doğrulama işleminden daha fazla bahsedeceğiz.
Verileri tensör olarak hazırlama
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Burada iki veri kümesi, modeli eğiteceğimiz bir eğitim kümesi ve her dönemin sonunda modeli test edeceğimiz bir doğrulama kümesi oluştururuz. Ancak doğrulama kümesindeki veriler eğitim sırasında hiçbir zaman modele gösterilmez.
Sağladığımız veri sınıfı, görüntü verilerinden tensörleri almayı kolaylaştırmaktadır. Ancak yine de tensörleri modele beslemeden önce modelin beklediği şekle [num_examples, image_width, image_height, channels] şeklinde yeniden şekillendiririz. Her bir veri kümesi için hem girişlerimiz (X'ler) hem de etiketlerimiz (Y'ler) var.
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Eğitim döngüsünü başlatmak için model.fit adını veriyoruz. Ayrıca, her dönemden sonra modelin kendini test etmek için hangi verileri kullanması gerektiğini (eğitim için kullanmaz) belirtmek üzere bir verificationData özelliği iletiriz.
Eğitim verilerimizde iyi sonuç verirsek doğrulama verilerimizde de iyi değilse bu, modelin muhtemelen eğitim verileri için geçersiz kılındığı ve modelin daha önce görülmediği bir biçimde genelleme yapamadığı anlamına gelir.
7. Modelimizi değerlendirin
Doğrulama doğruluğu, modelimizin daha önce görmediği veriler üzerinde ne kadar iyi performans göstereceğine dair iyi bir tahmin sağlar (veriler, bir şekilde doğrulama kümesine benzediği sürece). Ancak farklı sınıflardaki performansın daha ayrıntılı dökümünü almak isteyebiliriz.
tfjs-vis'te size bu konuda yardımcı olabilecek birkaç yöntem vardır.
Script.js dosyanızın alt kısmına aşağıdaki kodu ekleyin.
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Bu kod ne işe yarıyor?
- Tahminde bulunur.
- Doğruluk metriklerini hesaplar.
- Metrikleri gösterir
Her bir adıma daha yakından bakalım.
Tahminlerde Bulunma
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
İlk olarak bazı tahminler yapmamız gerekir. Burada, 500 resim alıp bunların içindeki basamakları tahmin edeceğiz (daha büyük bir resim grubunu test etmek için bu sayıyı daha sonra artırabilirsiniz).
argmax işlevi, en yüksek olasılık sınıfının endeksini elde etmemizi sağlar. Modelin her sınıf için bir olasılık ürettiğini unutmayın. Burada en yüksek olasılığı belirler ve bunu tahmin olarak atarız.
Aynı anda 500 örneğin tümü hakkında tahmin yapabileceğimizi de fark edebilirsiniz. Bu, TensorFlow.js'nin sağladığı vektörleştirmenin gücüdür.
Sınıfa göre doğruluğu göster
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Bir dizi tahmin ve etiket kullanarak her sınıf için doğruluğu hesaplayabiliriz.
Karışıklık matrisi göster
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Karışıklık matrisi, sınıfa göre doğruluk ayarına benzer, ancak yanlış sınıflandırma kalıplarını göstermek için daha ayrıntılı bir şekilde ayrıştırır. Modelin belirli bir sınıf çiftinde karıştırılıp karıştırılmadığını görmenizi sağlar.
Değerlendirmeyi görüntüleme
Değerlendirmeyi göstermek için aşağıdaki kodu çalıştırma işlevinizin altına ekleyin.
await showAccuracy(model, data);
await showConfusion(model, data);
Aşağıdaki gibi bir ekran görürsünüz.
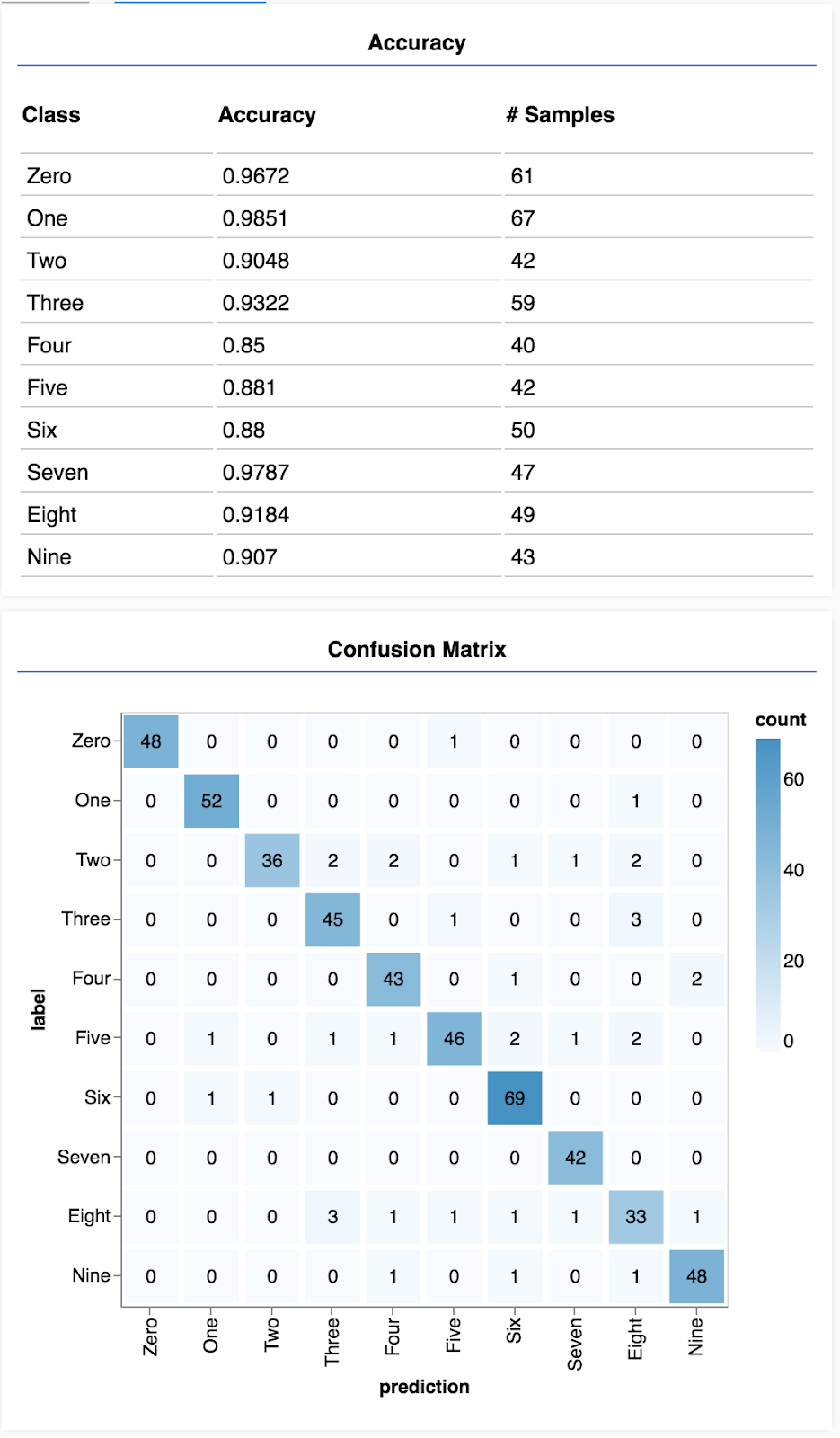
Tebrikler! Bir konvolüsyonel nöral ağ eğittiniz.
8. Temel çıkarımlar
Giriş verileri için kategorileri tahmin etmeye sınıflandırma görevi denir.
Sınıflandırma görevleri, etiketler için uygun bir veri temsili gerektirir
- Etiketlerin yaygın gösterimleri arasında kategorilerin tek seferde kodlanması yer alır
Verilerinizi hazırlama:
- Modelin eğitim sırasında hiçbir zaman görmediği bazı verileri bir kenara almanız faydalı olur. Bu verileri modeli değerlendirmek için kullanabilirsiniz. Buna doğrulama kümesi adı verilir.
Modelinizi derleyin ve çalıştırın:
- Konvolüsyonel modellerin görüntü görevlerinde iyi performans gösterdiği görülmüştür.
- Sınıflandırma problemlerinde genellikle kayıp fonksiyonları için kategorik çapraz entropi kullanılır.
- Kayıp ve doğruluk oranının artıp artmadığını görmek için eğitimi izleyin.
Modelinizi değerlendirme
- Çözmek istediğiniz ilk problemde ne kadar iyi performans gösterdiğini görmek için eğitildikten sonra modelinizi değerlendireceğiniz bir yönteme karar verin.
- Sınıfa göre doğruluk ve karışıklık matrisleri, model performansı için genel doğruluktan daha ayrıntılı bir döküm sağlayabilir.