
1. ভূমিকা
এই টিউটোরিয়ালে, আমরা একটি কনভোলিউশনাল নিউরাল নেটওয়ার্কের সাথে হাতে লেখা অঙ্কগুলি চিনতে TensorFlow.js মডেল তৈরি করব। প্রথমত, আমরা হাজার হাজার হাতে লেখা অঙ্কের ছবি এবং তাদের লেবেলগুলিকে "দেখতে" দিয়ে ক্লাসিফায়ারকে প্রশিক্ষণ দেব। তারপরে আমরা পরীক্ষার ডেটা ব্যবহার করে ক্লাসিফায়ারের নির্ভুলতা মূল্যায়ন করব যা মডেলটি কখনও দেখেনি।
এই কাজটিকে একটি শ্রেণীবিভাগের কাজ হিসাবে বিবেচনা করা হয় কারণ আমরা ইনপুট ছবিতে একটি বিভাগ (ছবিতে প্রদর্শিত অঙ্ক) বরাদ্দ করার জন্য মডেলটিকে প্রশিক্ষণ দিচ্ছি। আমরা মডেলটিকে সঠিক আউটপুট সহ ইনপুটের অনেক উদাহরণ দেখিয়ে প্রশিক্ষণ দেব। এটিকে তত্ত্বাবধান করা শিক্ষা হিসাবে উল্লেখ করা হয়।
যা আপনি নির্মাণ করবেন
আপনি একটি ওয়েবপেজ তৈরি করবেন যা ব্রাউজারে একটি মডেলকে প্রশিক্ষণ দিতে TensorFlow.js ব্যবহার করে। একটি নির্দিষ্ট আকারের একটি কালো এবং সাদা চিত্র দেওয়া হলে এটি শ্রেণীবদ্ধ করবে যে চিত্রটিতে কোন সংখ্যাটি উপস্থিত হবে। জড়িত পদক্ষেপগুলি হল:
- ডেটা লোড করুন।
- মডেলের আর্কিটেকচারের সংজ্ঞা দাও।
- মডেলকে প্রশিক্ষণ দিন এবং এটি প্রশিক্ষণের সাথে সাথে এর কার্যকারিতা নিরীক্ষণ করুন।
- কিছু ভবিষ্যদ্বাণী করে প্রশিক্ষিত মডেলের মূল্যায়ন করুন।
আপনি কি শিখবেন
- TensorFlow.js লেয়ার এপিআই ব্যবহার করে কনভোলিউশনাল মডেল তৈরির জন্য TensorFlow.js সিনট্যাক্স।
- TensorFlow.js-এ শ্রেণীবিভাগের কাজ প্রণয়ন করা
- কিভাবে tfjs-vis লাইব্রেরি ব্যবহার করে ইন-ব্রাউজার প্রশিক্ষণ নিরীক্ষণ করা যায়।
আপনি কি প্রয়োজন হবে
- Chrome এর একটি সাম্প্রতিক সংস্করণ বা অন্য একটি আধুনিক ব্রাউজার যা ES6 মডিউল সমর্থন করে৷
- একটি টেক্সট এডিটর, হয় স্থানীয়ভাবে আপনার মেশিনে বা ওয়েবে কোডপেন বা গ্লিচের মতো কিছুর মাধ্যমে চলছে।
- HTML, CSS, JavaScript এবং Chrome DevTools (বা আপনার পছন্দের ব্রাউজার devtools) সম্পর্কে জ্ঞান।
- নিউরাল নেটওয়ার্কগুলির একটি উচ্চ স্তরের ধারণাগত বোঝাপড়া। আপনার যদি পরিচিতি বা রিফ্রেশারের প্রয়োজন হয়, তাহলে 3blue1brown-এর এই ভিডিওটি অথবা Ashi Krishnan-এর Javascript-এ ডিপ লার্নিং-এর এই ভিডিওটি দেখার কথা বিবেচনা করুন।
আমাদের প্রথম প্রশিক্ষণ টিউটোরিয়ালের উপাদানগুলির সাথে আপনার আরামদায়ক হওয়া উচিত।
2. সেট আপ করুন
একটি HTML পৃষ্ঠা তৈরি করুন এবং জাভাস্ক্রিপ্ট অন্তর্ভুক্ত করুন
 নামক একটি html ফাইলে নিচের কোডটি কপি করুন
নামক একটি html ফাইলে নিচের কোডটি কপি করুন
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
ডেটা এবং কোডের জন্য জাভাস্ক্রিপ্ট ফাইল তৈরি করুন
- উপরের HTML ফাইলের মতো একই ফোল্ডারে, data.js ফাইল নামে একটি ফাইল তৈরি করুন এবং এই লিঙ্ক থেকে সেই ফাইলটিতে সামগ্রীটি অনুলিপি করুন।
- প্রথম ধাপের একই ফোল্ডারে, script.js নামে একটি ফাইল তৈরি করুন এবং এতে নিম্নলিখিত কোডটি রাখুন।
console.log('Hello TensorFlow');
এটা পরীক্ষা করে দেখুন
এখন আপনি HTML এবং JavaScript ফাইল তৈরি করেছেন, সেগুলি পরীক্ষা করুন। আপনার ব্রাউজারে index.html ফাইলটি খুলুন এবং devtools কনসোল খুলুন।
যদি সবকিছু কাজ করে, তাহলে দুটি গ্লোবাল ভেরিয়েবল তৈরি করা উচিত। tf হল TensorFlow.js লাইব্রেরির একটি রেফারেন্স, tfvis হল tfjs-vis লাইব্রেরির একটি রেফারেন্স।
আপনি একটি বার্তা দেখতে পাবেন যা বলে Hello TensorFlow , যদি তাই হয়, আপনি পরবর্তী ধাপে যেতে প্রস্তুত।
3. ডেটা লোড করুন
এই টিউটোরিয়ালে আপনি নীচের চিত্রগুলির মতো অঙ্কগুলি চিনতে শেখার জন্য একটি মডেলকে প্রশিক্ষণ দেবেন। এই ছবিগুলি হল MNIST নামক ডেটাসেট থেকে 28x28px গ্রেস্কেল ছবি৷
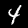

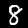
আমরা একটি বিশেষ স্প্রাইট ফাইল (~10MB) থেকে এই ছবিগুলি লোড করার জন্য কোড প্রদান করেছি যা আমরা আপনার জন্য তৈরি করেছি যাতে আমরা প্রশিক্ষণের অংশে ফোকাস করতে পারি।
ডেটা কীভাবে লোড হয় তা বুঝতে নির্দ্বিধায় data.js ফাইলটি অধ্যয়ন করুন। অথবা একবার আপনার এই টিউটোরিয়ালটি শেষ হয়ে গেলে, ডেটা লোড করার জন্য আপনার নিজস্ব পদ্ধতি তৈরি করুন।
প্রদত্ত কোডে একটি ক্লাস MnistData রয়েছে যার দুটি সর্বজনীন পদ্ধতি রয়েছে:
-
nextTrainBatch(batchSize): প্রশিক্ষণ সেট থেকে ইমেজ এবং তাদের লেবেলগুলির একটি এলোমেলো ব্যাচ প্রদান করে। -
nextTestBatch(batchSize): পরীক্ষার সেট থেকে একটি ব্যাচ এবং তাদের লেবেল ফেরত দেয়
MnistData ক্লাস ডাটা পরিবর্তন এবং স্বাভাবিক করার গুরুত্বপূর্ণ পদক্ষেপগুলিও করে।
মোট 65,000টি চিত্র রয়েছে, আমরা মডেলটিকে প্রশিক্ষণ দেওয়ার জন্য 55,000টি পর্যন্ত চিত্র ব্যবহার করব, 10,000টি চিত্র সংরক্ষণ করব যা আমরা একবার হয়ে গেলে মডেলটির কার্যকারিতা পরীক্ষা করতে ব্যবহার করতে পারি৷ এবং আমরা ব্রাউজারে যে সব করতে যাচ্ছি!
আসুন ডেটা লোড করি এবং পরীক্ষা করি যে এটি সঠিকভাবে লোড হয়েছে।
আপনার script.js ফাইলে নিম্নলিখিত কোড যোগ করুন।
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
পৃষ্ঠাটি রিফ্রেশ করুন এবং কয়েক সেকেন্ড পরে আপনি অনেকগুলি চিত্র সহ বাম দিকে একটি প্যানেল দেখতে পাবেন৷

4. আমাদের টাস্ক ধারণা
আমাদের ইনপুট তথ্য এই মত দেখায়.
আমাদের লক্ষ্য হল এমন একটি মডেলকে প্রশিক্ষণ দেওয়া যা একটি ছবি তুলবে এবং সম্ভাব্য 10টি শ্রেণীর প্রতিটির জন্য একটি স্কোর ভবিষ্যদ্বাণী করতে শিখবে যেটি চিত্রের অন্তর্গত হতে পারে (0-9 সংখ্যা)।
প্রতিটি চিত্র 28px চওড়া 28px উচ্চ এবং একটি 1 রঙের চ্যানেল রয়েছে কারণ এটি একটি গ্রেস্কেল চিত্র। তাই প্রতিটি ছবির আকৃতি হল [28, 28, 1] ।
মনে রাখবেন যে আমরা এক থেকে দশটি ম্যাপিং করি, সেইসাথে প্রতিটি ইনপুট উদাহরণের আকার, যেহেতু এটি পরবর্তী বিভাগের জন্য গুরুত্বপূর্ণ।
5. মডেল আর্কিটেকচার সংজ্ঞায়িত করুন
এই বিভাগে আমরা মডেল আর্কিটেকচার বর্ণনা করার জন্য কোড লিখব। মডেল আর্কিটেকচার হল "মডেলটি চালানোর সময় কোন ফাংশনগুলি চলবে" বা বিকল্পভাবে "আমাদের মডেল তার উত্তরগুলি গণনা করতে কী অ্যালগরিদম ব্যবহার করবে" বলার একটি অভিনব উপায়৷
মেশিন লার্নিং-এ আমরা একটি আর্কিটেকচার (বা অ্যালগরিদম) সংজ্ঞায়িত করি এবং প্রশিক্ষণ প্রক্রিয়াটিকে সেই অ্যালগরিদমের পরামিতিগুলি শিখতে দেই।
আপনার নিম্নলিখিত ফাংশন যোগ করুন
মডেল আর্কিটেকচার সংজ্ঞায়িত করতে script.js ফাইল
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
আমাদের একটু বিস্তারিতভাবে এই তাকান করা যাক.
কনভল্যুশন
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
এখানে আমরা একটি অনুক্রমিক মডেল ব্যবহার করছি।
আমরা একটি ঘন স্তরের পরিবর্তে একটি conv2d স্তর ব্যবহার করছি। কনভোল্যুশনগুলি কীভাবে কাজ করে তার সমস্ত বিবরণে আমরা যেতে পারি না, তবে এখানে কয়েকটি সংস্থান রয়েছে যা অন্তর্নিহিত ক্রিয়াকলাপ ব্যাখ্যা করে:
আসুন conv2d এর জন্য কনফিগারেশন অবজেক্টের প্রতিটি আর্গুমেন্ট ভেঙে ফেলি:
-
inputShape। ডেটার আকৃতি যা মডেলের প্রথম স্তরে প্রবাহিত হবে। এই ক্ষেত্রে, আমাদের MNIST উদাহরণ হল 28x28-পিক্সেলের কালো-সাদা ছবি। ইমেজ ডেটার ক্যানোনিকাল ফরম্যাট হল[row, column, depth], তাই এখানে আমরা[28, 28, 1]একটি আকৃতি কনফিগার করতে চাই। প্রতিটি মাত্রায় পিক্সেল সংখ্যার জন্য 28টি সারি এবং কলাম এবং 1 এর গভীরতা কারণ আমাদের চিত্রগুলিতে শুধুমাত্র 1টি রঙের চ্যানেল রয়েছে। মনে রাখবেন যে আমরা ইনপুট আকারে একটি ব্যাচের আকার নির্দিষ্ট করি না। স্তরগুলি ব্যাচ আকারের অজ্ঞেয়বাদী হওয়ার জন্য ডিজাইন করা হয়েছে যাতে অনুমানের সময় আপনি যে কোনও ব্যাচ আকারের একটি টেনসর পাস করতে পারেন। -
kernelSize। স্লাইডিং কনভোল্যুশনাল ফিল্টার উইন্ডোর আকার ইনপুট ডেটাতে প্রয়োগ করা হবে। এখানে, আমরা5এর একটিkernelSizeসেট করেছি, যা একটি বর্গাকার, 5x5 কনভোলিউশনাল উইন্ডো নির্দিষ্ট করে। -
filtersইনপুট ডেটাতে প্রয়োগ করার জন্যkernelSizeসাইজের আকারের ফিল্টার উইন্ডোর সংখ্যা। এখানে, আমরা ডেটাতে 8টি ফিল্টার প্রয়োগ করব। -
stridesস্লাইডিং উইন্ডোর "স্টেপ সাইজ"—অর্থাৎ, ফিল্টারটি প্রতিবার ছবিটির উপর দিয়ে গেলে কত পিক্সেল স্থানান্তরিত হবে। এখানে, আমরা 1 এর স্ট্রাইড উল্লেখ করেছি, যার অর্থ হল ফিল্টারটি 1 পিক্সেলের ধাপে চিত্রের উপর স্লাইড করবে। -
activationকনভল্যুশন সম্পূর্ণ হওয়ার পরে ডেটাতে প্রয়োগ করার জন্য সক্রিয়করণ ফাংশন । এই ক্ষেত্রে, আমরা একটি Rectified Linear Unit (ReLU) ফাংশন প্রয়োগ করছি, যা ML মডেলগুলিতে একটি খুব সাধারণ অ্যাক্টিভেশন ফাংশন। -
kernelInitializer। এলোমেলোভাবে মডেল ওজন শুরু করার জন্য ব্যবহার করার পদ্ধতি, যা গতিবিদ্যা প্রশিক্ষণের জন্য খুবই গুরুত্বপূর্ণ। আমরা এখানে প্রারম্ভিকতার বিশদ বিবরণে যাব না, তবেVarianceScaling(এখানে ব্যবহৃত) সাধারণত একটি ভাল সূচনাকারী পছন্দ ।
আমাদের তথ্য উপস্থাপনা সমতল করা
model.add(tf.layers.flatten());
চিত্রগুলি উচ্চমাত্রিক ডেটা, এবং কনভোল্যুশন অপারেশনগুলি সেগুলিতে প্রবেশ করা ডেটার আকার বাড়িয়ে দেয়। আমাদের চূড়ান্ত শ্রেণিবিন্যাস স্তরে তাদের পাস করার আগে আমাদের একটি দীর্ঘ অ্যারেতে ডেটা সমতল করতে হবে। ঘন স্তরগুলি (যা আমরা আমাদের চূড়ান্ত স্তর হিসাবে ব্যবহার করি) শুধুমাত্র tensor1d s গ্রহণ করে, তাই এই ধাপটি অনেক শ্রেণীবিভাগের কাজগুলিতে সাধারণ।
আমাদের চূড়ান্ত সম্ভাব্যতা বন্টন গণনা
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
আমরা 10টি সম্ভাব্য ক্লাসে সম্ভাব্যতা বন্টন গণনা করতে একটি সফটম্যাক্স অ্যাক্টিভেশন সহ একটি ঘন স্তর ব্যবহার করব। সর্বোচ্চ স্কোর সহ ক্লাস হবে পূর্বাভাসিত সংখ্যা।
একটি অপ্টিমাইজার এবং ক্ষতি ফাংশন চয়ন করুন
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
আমরা একটি অপ্টিমাইজার , লস ফাংশন এবং মেট্রিক্স যা আমরা ট্র্যাক রাখতে চাই তা নির্দিষ্ট করে মডেলটি কম্পাইল করি।
আমাদের প্রথম টিউটোরিয়ালের বিপরীতে, এখানে আমরা আমাদের ক্ষতি ফাংশন হিসাবে categoricalCrossentropy ব্যবহার করি। নামটি বোঝায় এটি ব্যবহার করা হয় যখন আমাদের মডেলের আউটপুট একটি সম্ভাব্যতা বন্টন হয়। categoricalCrossentropy আমাদের মডেলের শেষ স্তর দ্বারা উত্পন্ন সম্ভাব্যতা বন্টন এবং আমাদের প্রকৃত লেবেল দ্বারা প্রদত্ত সম্ভাব্যতা বিতরণের মধ্যে ত্রুটি পরিমাপ করে।
উদাহরণস্বরূপ, যদি আমাদের অঙ্কটি সত্যিই 7 প্রতিনিধিত্ব করে তবে আমাদের নিম্নলিখিত ফলাফল থাকতে পারে
সূচক | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
সত্য লেবেল | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
ভবিষ্যদ্বাণী | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
শ্রেণীবদ্ধ ক্রস এনট্রপি আমাদের প্রকৃত লেবেল ভেক্টরের সাথে পূর্বাভাস ভেক্টর কতটা মিল তা নির্দেশ করে একটি একক সংখ্যা তৈরি করবে।
লেবেলগুলির জন্য এখানে ব্যবহৃত ডেটা উপস্থাপনাকে এক-হট এনকোডিং বলা হয় এবং এটি শ্রেণীবিভাগের সমস্যাগুলিতে সাধারণ। প্রতিটি শ্রেণীর প্রতিটি উদাহরণের জন্য এটির সাথে যুক্ত একটি সম্ভাবনা রয়েছে। যখন আমরা জানি এটি ঠিক কী হওয়া উচিত আমরা সেই সম্ভাবনাটিকে 1 এবং অন্যগুলিকে 0 তে সেট করতে পারি৷ ওয়ান-হট এনকোডিং সম্পর্কে আরও তথ্যের জন্য এই পৃষ্ঠাটি দেখুন৷
অন্য যে মেট্রিকটি আমরা নিরীক্ষণ করব তা হল accuracy যা একটি শ্রেণিবিন্যাস সমস্যার জন্য সমস্ত ভবিষ্যদ্বাণীর মধ্যে সঠিক ভবিষ্যদ্বাণীর শতাংশ।
6. মডেল প্রশিক্ষণ
আপনার script.js ফাইলে নিম্নলিখিত ফাংশনটি অনুলিপি করুন।
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
তারপর আপনার নিম্নলিখিত কোড যোগ করুন
ফাংশন run ।
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
পৃষ্ঠাটি রিফ্রেশ করুন এবং কয়েক সেকেন্ড পরে আপনি প্রশিক্ষণের অগ্রগতি প্রতিবেদনকারী কিছু গ্রাফ দেখতে পাবেন।
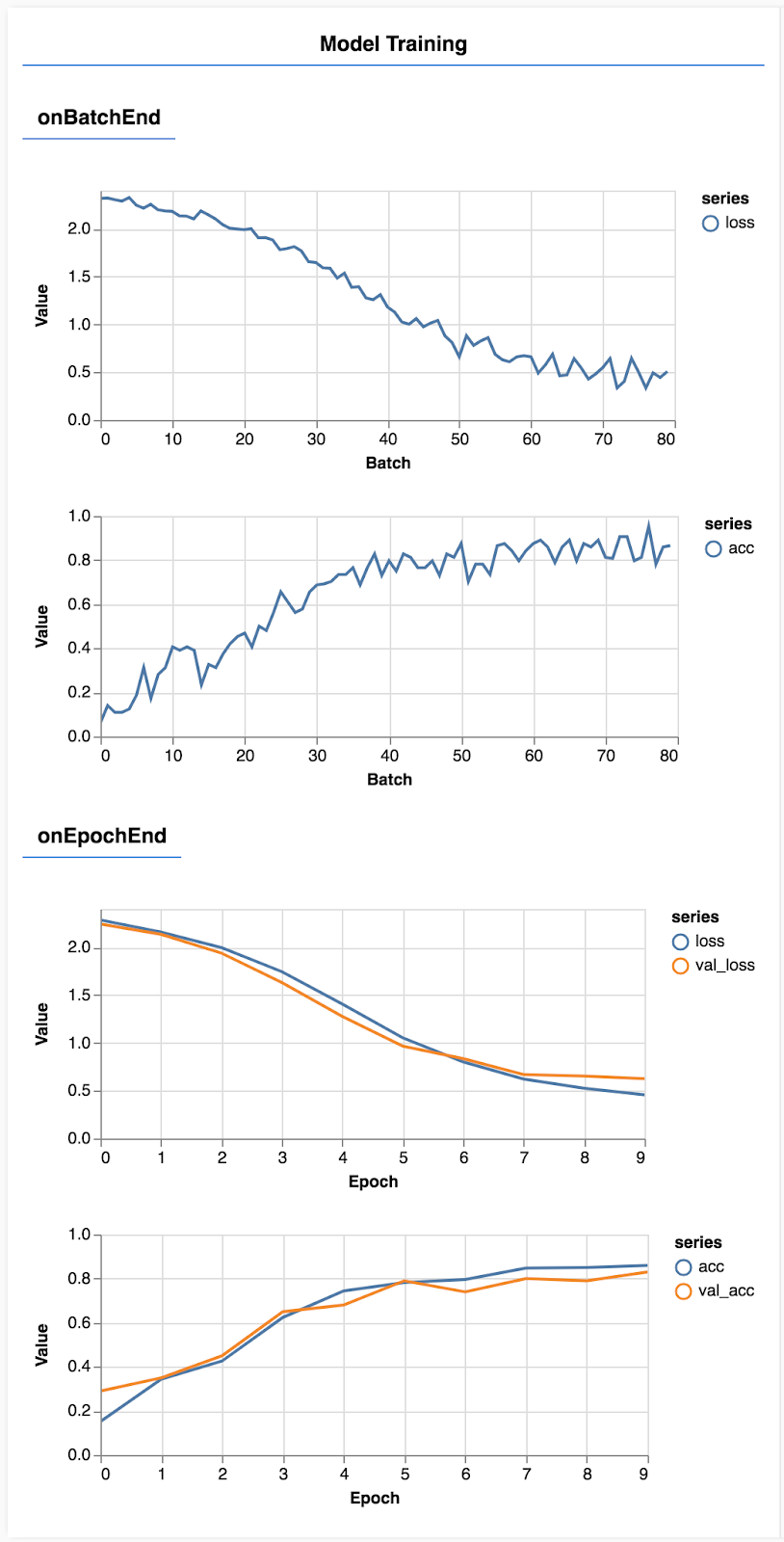
এর একটু বিস্তারিতভাবে তাকান.
মেট্রিক্স মনিটর করুন
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
এখানে আমরা সিদ্ধান্ত নিই যে আমরা কোন মেট্রিক্স নিরীক্ষণ করতে যাচ্ছি। আমরা প্রশিক্ষণ সেটের ক্ষতি এবং নির্ভুলতার পাশাপাশি বৈধতা সেটের ক্ষতি এবং নির্ভুলতা (যথাক্রমে val_loss এবং val_acc) নিরীক্ষণ করব। আমরা নীচে সেট করা বৈধতা সম্পর্কে আরও কথা বলব।
টেনসর হিসাবে ডেটা প্রস্তুত করুন
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
এখানে আমরা দুটি ডেটাসেট তৈরি করি, একটি প্রশিক্ষণ সেট যা আমরা মডেলটিকে প্রশিক্ষণ দেব এবং একটি বৈধতা সেট যা আমরা প্রতিটি যুগের শেষে মডেলটি পরীক্ষা করব, তবে বৈধতা সেটের ডেটা কখনই প্রশিক্ষণের সময় মডেলকে দেখানো হয় না। .
আমরা যে ডেটা ক্লাস দিয়েছি তা ইমেজ ডেটা থেকে টেনসর পাওয়া সহজ করে তোলে। কিন্তু আমরা এখনও টেনসরগুলিকে মডেলের দ্বারা প্রত্যাশিত আকারে পুনর্নির্মাণ করি, [num_examples, image_width, image_height, channels] , আমরা এইগুলিকে মডেলে খাওয়ানোর আগে। প্রতিটি ডেটাসেটের জন্য আমাদের উভয় ইনপুট (Xs) এবং লেবেল (Ys) আছে।
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
আমরা ট্রেনিং লুপ শুরু করতে model.fit কল করি। আমরা একটি বৈধতা ডেটা বৈশিষ্ট্যও পাস করি যা নির্দেশ করে যে মডেলটি প্রতিটি যুগের পরে নিজেকে পরীক্ষা করার জন্য কোন ডেটা ব্যবহার করবে (কিন্তু প্রশিক্ষণের জন্য ব্যবহার করবে না)।
আমরা যদি আমাদের প্রশিক্ষণের ডেটাতে ভাল করি কিন্তু আমাদের বৈধতা ডেটাতে না করি, তাহলে এর মানে হল যে মডেলটি সম্ভবত প্রশিক্ষণের ডেটার সাথে ওভারফিটিং করছে এবং ইনপুট করার জন্য এটি আগে দেখা যায়নি।
7. আমাদের মডেল মূল্যায়ন
যাচাইকরণের নির্ভুলতা আমাদের মডেলটি আগে না দেখা ডেটার উপর কতটা ভাল কাজ করবে তার একটি ভাল অনুমান প্রদান করে (যতক্ষণ সেই ডেটাটি কোনও উপায়ে যাচাইকরণ সেটের সাথে সাদৃশ্যপূর্ণ হয়)৷ যাইহোক, আমরা বিভিন্ন শ্রেণীতে পারফরম্যান্সের আরও বিস্তারিত ভাঙ্গন চাই।
tfjs-vis-এ কয়েকটি পদ্ধতি রয়েছে যা আপনাকে এতে সাহায্য করতে পারে।
নিচের কোডটি আপনার script.js ফাইলের নিচে যোগ করুন
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
এই কোড কি করছেন?
- একটি ভবিষ্যদ্বাণী করে।
- নির্ভুলতা মেট্রিক্স গণনা করে।
- মেট্রিক্স দেখায়
আসুন প্রতিটি ধাপে ঘনিষ্ঠভাবে নজর দেওয়া যাক।
ভবিষ্যদ্বাণী করুন
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
প্রথমে আমাদের কিছু ভবিষ্যদ্বাণী করা দরকার। এখানে আমরা 500টি ছবি তুলব এবং ভবিষ্যদ্বাণী করব যে সেগুলির মধ্যে কোন সংখ্যা রয়েছে (আপনি এই সংখ্যাটি পরে আরও বড় আকারের চিত্রের সেটে পরীক্ষা করতে পারেন)৷
উল্লেখযোগ্যভাবে argmax ফাংশন আমাদের সর্বোচ্চ সম্ভাব্যতা শ্রেণীর সূচক দেয়। মনে রাখবেন যে মডেলটি প্রতিটি শ্রেণীর জন্য একটি সম্ভাব্যতা আউটপুট করে। এখানে আমরা সর্বোচ্চ সম্ভাব্যতা খুঁজে বের করি এবং ভবিষ্যদ্বাণী হিসাবে ব্যবহার করি।
আপনি লক্ষ্য করতে পারেন যে আমরা একবারে সমস্ত 500টি উদাহরণের উপর ভবিষ্যদ্বাণী করতে পারি। এটি ভেক্টরাইজেশনের শক্তি যা TensorFlow.js প্রদান করে।
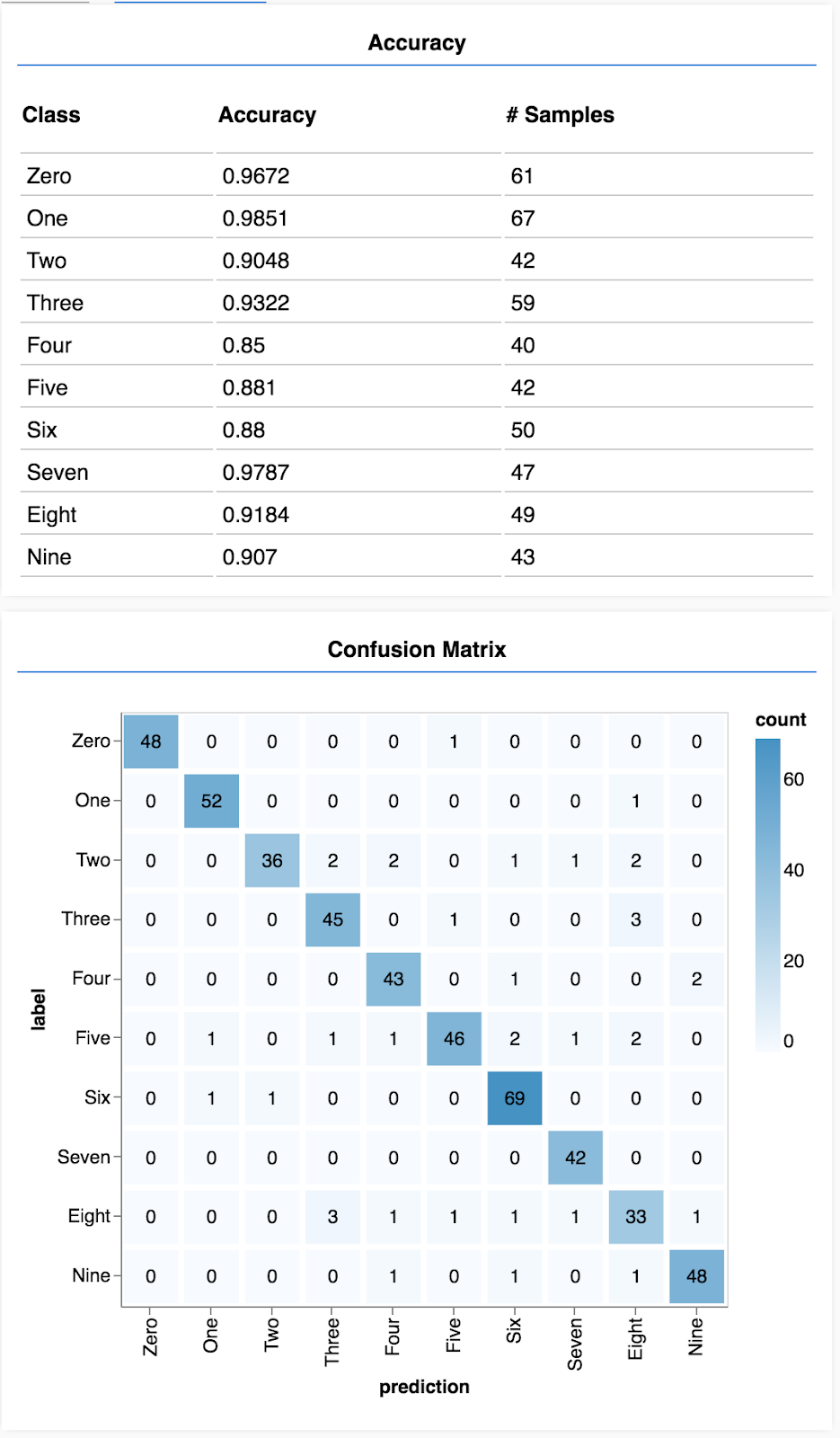
প্রতি ক্লাস নির্ভুলতা দেখান
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
ভবিষ্যদ্বাণী এবং লেবেলের একটি সেটের সাহায্যে আমরা প্রতিটি শ্রেণীর জন্য নির্ভুলতা গণনা করতে পারি।
একটি বিভ্রান্তি ম্যাট্রিক্স দেখান
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
একটি বিভ্রান্তি ম্যাট্রিক্স প্রতি শ্রেণী নির্ভুলতার অনুরূপ তবে ভুল শ্রেণিবিন্যাসের নিদর্শন দেখানোর জন্য এটিকে আরও ভেঙে দেয়। এটি আপনাকে দেখতে দেয় যে মডেলটি কোনো নির্দিষ্ট জোড়া ক্লাস সম্পর্কে বিভ্রান্ত হচ্ছে কিনা।
মূল্যায়ন প্রদর্শন করুন
মূল্যায়ন দেখানোর জন্য আপনার রান ফাংশনের নীচে নিম্নলিখিত কোড যোগ করুন।
await showAccuracy(model, data);
await showConfusion(model, data);
আপনি নিম্নলিখিত মত দেখায় যে একটি প্রদর্শন দেখতে হবে.
অভিনন্দন! আপনি সবেমাত্র একটি কনভোলিউশনাল নিউরাল নেটওয়ার্ক প্রশিক্ষিত করেছেন!
8. প্রধান টেক-অ্যাওয়ে
ইনপুট ডেটার জন্য বিভাগগুলির ভবিষ্যদ্বাণী করাকে একটি শ্রেণিবিন্যাস কাজ বলা হয়।
শ্রেণীবিভাগের কাজগুলির জন্য লেবেলের জন্য উপযুক্ত ডেটা উপস্থাপনা প্রয়োজন
- লেবেলগুলির সাধারণ উপস্থাপনাগুলির মধ্যে বিভাগগুলির এক-হট এনকোডিং অন্তর্ভুক্ত
আপনার ডেটা প্রস্তুত করুন:
- কিছু ডেটা একপাশে রাখা দরকারী যে মডেলটি প্রশিক্ষণের সময় কখনও দেখে না যা আপনি মডেলটি মূল্যায়ন করতে ব্যবহার করতে পারেন। একে বলে ভ্যালিডেশন সেট।
আপনার মডেল তৈরি করুন এবং চালান:
- কনভোল্যুশনাল মডেলগুলি ইমেজ টাস্কগুলিতে ভাল সঞ্চালন করতে দেখানো হয়েছে।
- শ্রেণীবিভাগ সমস্যা সাধারণত তাদের ক্ষতি ফাংশন জন্য শ্রেণীবদ্ধ ক্রস এনট্রপি ব্যবহার করে।
- ক্ষয়ক্ষতি কমে যাচ্ছে এবং নির্ভুলতা বাড়ছে কিনা তা দেখার জন্য প্রশিক্ষণ নিরীক্ষণ করুন।
আপনার মডেল মূল্যায়ন
- আপনি যে প্রাথমিক সমস্যাটি সমাধান করতে চেয়েছিলেন তাতে এটি কতটা ভাল করছে তা দেখার জন্য প্রশিক্ষিত হয়ে গেলে আপনার মডেলটিকে মূল্যায়ন করার কিছু উপায় নির্ধারণ করুন।
- প্রতি শ্রেণির নির্ভুলতা এবং বিভ্রান্তি ম্যাট্রিক্স আপনাকে সামগ্রিক নির্ভুলতার চেয়ে মডেলের কার্যক্ষমতার একটি সূক্ষ্ম ভাঙ্গন দিতে পারে।