
Dalam tutorial ini, kita akan mem-build model TensorFlow.js untuk mengenali angka dari tulisan tangan dengan jaringan neural konvolusional. Pertama, kita akan melatih pengklasifikasi dengan menugaskannya untuk "melihat" ribuan gambar angka dari tulisan tangan dan labelnya. Kemudian, kita akan mengevaluasi akurasi pengklasifikasi menggunakan data pengujian yang belum pernah dilihat model tersebut.
Tugas ini dianggap sebagai tugas klasifikasi karena kita melatih model untuk menetapkan kategori (angka yang muncul di gambar) ke gambar input. Kita akan melatih model dengan menampilkan banyak contoh input dibarengi dengan output yang benar. Ini disebut sebagai pembelajaran terarah.
Hal yang akan Anda build
Anda akan membuat halaman web yang menggunakan TensorFlow.js untuk melatih model di browser. Saat diberikan gambar hitam dan putih berukuran tertentu, model akan mengklasifikasikan angka mana yang muncul dalam gambar. Langkah-langkah yang diperlukan adalah:
- Memuat data.
- Menentukan arsitektur model.
- Melatih model dan memantau performanya saat pelatihan berlangsung.
- Mengevaluasi model yang dilatih dengan membuat beberapa prediksi.
Hal yang akan Anda pelajari
- Sintaksis TensorFlow.js untuk membuat model konvolusional menggunakan TensorFlow.js Layers API.
- Merumuskan tugas klasifikasi di TensorFlow.js
- Cara memantau pelatihan dalam browser menggunakan library tfjs-vis.
Hal yang akan Anda perlukan
- Versi terbaru Chrome atau browser modern lainnya yang mendukung modul ES6.
- Editor teks, yang dijalankan secara lokal di komputer Anda atau di web melalui sesuatu seperti Codepen atau Glitch.
- Pengetahuan tentang HTML, CSS, JavaScript, dan Chrome DevTools (atau devtool browser pilihan Anda).
- Pemahaman konseptual tingkat tinggi tentang Jaringan Neural. Jika Anda memerlukan informasi pengantar atau penyegaran terkait materi yang akan dipelajari, pertimbangkan untuk menonton video 3blue1brown ini atau video Deep Learning in JavaScript dari Ashi Krishnan.
Anda juga harus sudah memahami materi dalam tutorial pelatihan pertama.
Membuat halaman HTML dan menyertakan JavaScript
 Salin kode berikut ke file html yang disebut
Salin kode berikut ke file html yang disebut
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Membuat file JavaScript untuk data dan kode
- Dalam folder yang sama dengan file HTML di atas, buat file yang disebut file data.js dan salin konten dari link ini ke file tersebut.
- Dalam folder yang sama di langkah pertama, buat file yang disebut script.js dan masukkan kode berikut di dalamnya.
console.log('Hello TensorFlow');
Melakukan pengujian
Setelah Anda mendapatkan file HTML dan JavaScript, uji file tersebut. Buka file index.html di browser dan buka konsol devtools.
Jika semuanya berfungsi, akan ada dua variabel global yang dibuat. tf adalah referensi ke library TensorFlow.js, tfvis adalah referensi ke library tfjs-vis.
Anda akan melihat pesan yang bertuliskan Hello TensorFlow*,* jika demikian, Anda siap melanjutkan ke langkah berikutnya.
Dalam tutorial ini, Anda akan melatih model untuk belajar mengenali angka dalam gambar seperti di bawah ini. Gambar-gambar ini adalah gambar hitam putih berukuran 28x28px dari set data yang disebut MNIST.
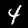

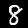
Kami telah menyediakan kode untuk memuat gambar ini dari file sprite khusus (~10 MB) yang telah kami buat untuk Anda sehingga kita dapat berfokus pada bagian pelatihan.
Anda dapat mempelajari file data.js untuk memahami cara data dimuat. Atau setelah selesai dengan tutorial ini, buat pendekatan Anda sendiri untuk memuat data.
Kode yang diberikan berisi class MnistData yang memiliki dua metode publik:
nextTrainBatch(batchSize): menampilkan kumpulan gambar acak dan labelnya dari set pelatihan.nextTestBatch(batchSize): menampilkan kumpulan gambar dan labelnya dari set pengujian
Class MnistData juga melakukan langkah penting untuk melakukan shuffle dan normalisasi pada data.
Dari total 65.000 gambar, kita akan menggunakan hingga 55.000 gambar untuk melatih model dan menyimpan 10.000 gambar sisanya yang dapat digunakan untuk menguji performa model setelah pelatihan selesai. Kita akan melakukan semua itu di browser.
Mari kita memuat datanya dan menguji apakah pemuatan dilakukan dengan benar atau tidak.
Tambahkan kode berikut ke file script.js Anda.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Muat ulang halaman dan setelah beberapa detik, Anda akan melihat panel di sebelah kiri dengan sejumlah gambar.

Data input terlihat seperti ini.
Tujuan kita adalah melatih model yang akan mengambil satu gambar dan mempelajari cara memprediksi skor untuk masing-masing dari 10 class yang mungkin sesuai dengan gambar tersebut (angka 0-9).
Setiap gambar berukuran lebar 28px tinggi 28px dan memiliki 1 saluran warna karena merupakan gambar hitam putih. Jadi, bentuk setiap gambar adalah [28, 28, 1].
Ingat bahwa kita melakukan pemetaan satu hingga sepuluh, serta bentuk setiap contoh input, karena hal ini penting untuk bagian selanjutnya.
Di bagian ini, kita akan menulis kode untuk mendeskripsikan arsitektur model. Arsitektur model juga bisa dianggap sebagai "fungsi mana yang akan dijalankan model saat model dieksekusi", atau "apa algoritme yang akan digunakan model untuk menghitung jawabannya".
Dalam machine learning, kita menentukan arsitektur (atau algoritme) dan membiarkan proses pelatihan mempelajari parameter dari algoritme tersebut.
Tambahkan fungsi berikut ke
file script.js untuk menentukan arsitektur model
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Mari kita lihat sedikit lebih mendetail.
Konvolusi
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Di sini, kita menggunakan model berurutan.
Kita menggunakan lapisan conv2d, bukan lapisan padat. Kita tidak dapat membahas semua detail cara kerja konvolusi, tetapi berikut adalah beberapa referensi yang menjelaskan operasi yang mendasari:
Mari kita uraikan setiap argumen di objek konfigurasi untuk conv2d:
inputShape. Bentuk data yang akan mengalir ke lapisan pertama model. Dalam hal ini, contoh MNIST kita adalah gambar hitam putih berukuran 28x28 piksel. Format kanonis untuk data gambar adalah[row, column, depth], jadi di sini kita ingin mengonfigurasi bentuk[28, 28, 1]. 28 baris dan kolom untuk jumlah piksel di setiap dimensi, dan kedalaman 1 karena gambar yang digunakan hanya memiliki 1 saluran warna. Perlu diperhatikan bahwa kita tidak menetapkan ukuran tumpukan dalam bentuk input. Lapisan didesain agar tidak bergantung pada ukuran tumpukan, sehingga selama inferensi Anda bisa meneruskan tensor dengan berbagai ukuran tumpukan.kernelSize. Ukuran jendela saringan konvolusional geser yang akan diterapkan pada data input. Di sini, kita menetapkankernelSizedari5, yang menentukan jendela konvolusional persegi 5x5.filters. Jumlah jendela filter berukurankernelSizeyang akan diterapkan ke data input. Di sini, kita akan menerapkan 8 filter ke data.strides. "Ukuran langkah" jendela geser—yaitu, jumlah piksel pergeseran filter setiap kali filter bergerak di atas gambar. Di sini, kita menetapkan jangka berukuran 1, yang berarti filter akan menggeser ke gambar dalam langkah 1 piksel.activation. Fungsi aktivasi untuk diterapkan pada data setelah konvolusi selesai. Dalam kasus ini, kita menerapkan fungsi Unit Linear Terarah (ULT), yang merupakan fungsi aktivasi yang sangat umum pada model ML.kernelInitializer. Metode yang digunakan untuk menginisialisasi bobot model secara acak, yang sangat penting untuk pelatihan dinamis. Kita tidak akan membahas detail inisialisasi di sini, tetapiVarianceScaling(digunakan di sini) umumnya merupakan pilihan penginisialisasi yang baik.
Meratakan representasi data
model.add(tf.layers.flatten());
Gambar adalah data berdimensi tinggi dan operasi konvolusi cenderung meningkatkan ukuran data yang masuk ke dalamnya. Sebelum meneruskannya ke lapisan klasifikasi akhir, kita perlu meratakan data menjadi satu array panjang. Lapisan padat (yang digunakan sebagai lapisan akhir) hanya memerlukan tensor1d, sehingga langkah ini umum dalam banyak tugas klasifikasi.
Menghitung distribusi probabilitas akhir
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Kita akan menggunakan lapisan padat dengan aktivasi softmax untuk menghitung distribusi probabilitas di atas 10 class yang mungkin. Class dengan skor tertinggi akan menjadi angka yang diprediksi.
Memilih pengoptimal dan fungsi kerugian
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Kita mengompilasi model yang menentukan pengoptimal, fungsi kerugian, dan metrik yang ingin dilacak.
Berbeda dengan tutorial pertama kita, di sini kita menggunakan categoricalCrossentropy sebagai fungsi kerugian. Sesuai dengan namanya, ini digunakan saat output model kita adalah distribusi probabilitas. categoricalCrossentropy mengukur error antara distribusi probabilitas yang dihasilkan oleh lapisan terakhir model dan distribusi probabilitas yang diberikan oleh label benar.
Misalnya, jika angka benar-benar mewakili 7, kita mungkin akan mendapatkan hasil berikut
Indeks | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Label Benar | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Prediksi | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
Entropi silang kategori akan menghasilkan angka tunggal yang menunjukkan seberapa mirip vektor prediksi dengan vektor label benar.
Representasi data yang digunakan di sini untuk label disebut enkode one-hot dan umum digunakan dalam masalah klasifikasi. Setiap class memiliki probabilitas yang terkait dengannya untuk setiap contoh. Jika kita tahu pasti label yang seharusnya, kita dapat menetapkan probabilitas tersebut ke 1 dan yang lainnya ke 0. Lihat halaman ini untuk mengetahui informasi lebih lanjut tentang enkode one-hot.
Metrik lainnya yang akan kita pantau adalah accuracy yang merupakan persentase prediksi yang benar dari semua prediksi dalam masalah klasifikasi.
Salin fungsi berikut ke file script.js Anda.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Lalu, tambahkan kode berikut ke fungsi
run.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Muat ulang halaman dan setelah beberapa detik, Anda akan melihat beberapa grafik yang melaporkan progres pelatihan.
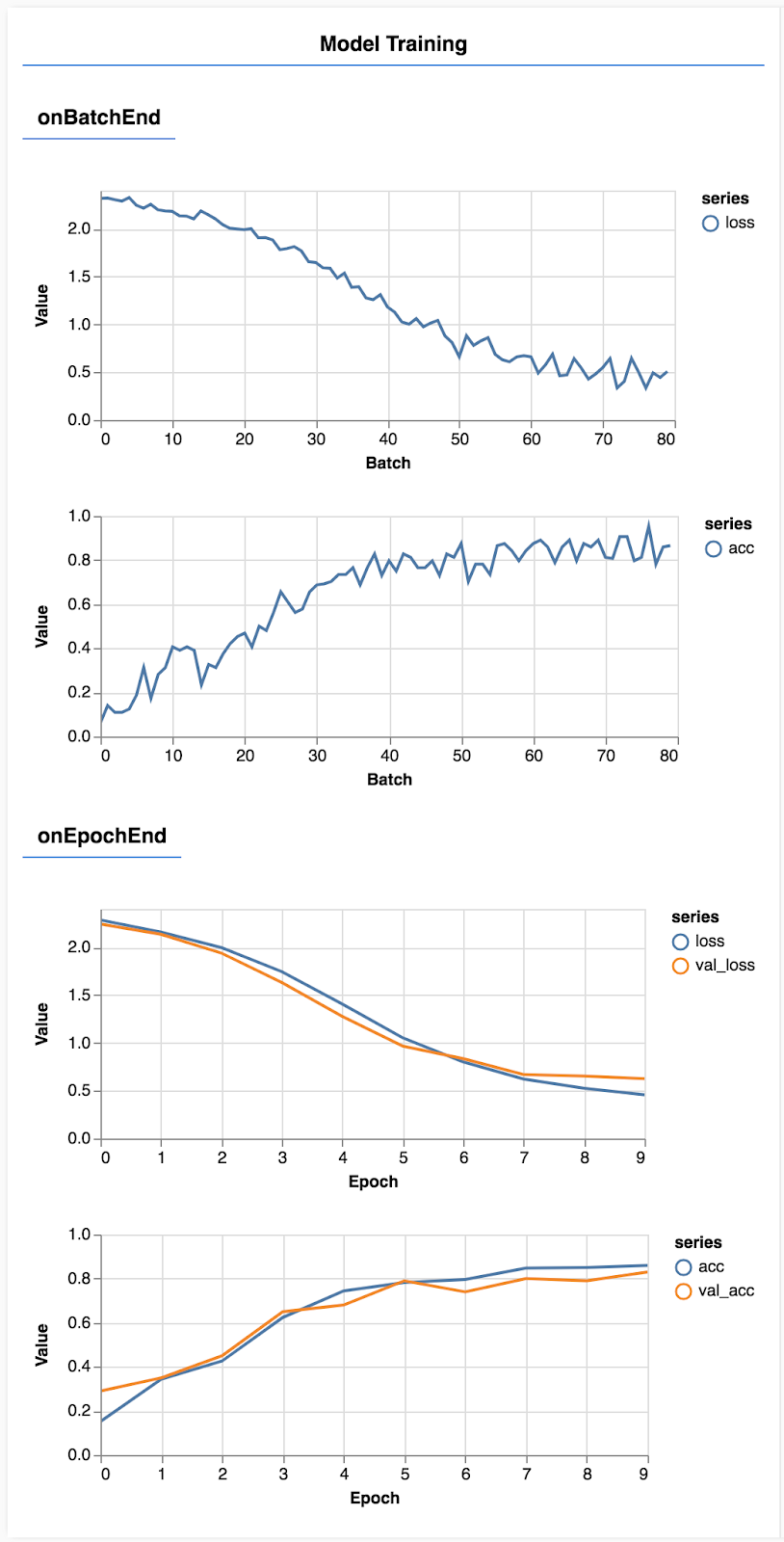
Mari kita lihat sedikit lebih mendetail.
Memantau metrik
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Di sini, kita menetapkan metrik mana yang akan dipantau. Kita akan memantau kerugian dan akurasi pada set pelatihan serta kerugian dan akurasi pada set validasi (val_loss dan val_acc). Kita akan membahas lebih lanjut tentang set validasi di bawah.
Menyiapkan data sebagai tensor
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Di sini kita membuat dua set data, yaitu set pelatihan yang akan digunakan untuk melatih model, dan set validasi yang akan digunakan untuk menguji model di akhir setiap iterasi pelatihan. Namun, data dalam set validasi tidak akan pernah ditampilkan ke model selama pelatihan.
Class data yang disediakan memudahkan Anda untuk mendapatkan tensor dari data gambar. Namun, kita masih membentuk ulang tensor ke dalam bentuk yang diharapkan oleh model, [num_example, image_width, image_height, channels], sebelum kita dapat memasukkannya ke model. Untuk setiap set data, kita memiliki input (X) dan label (Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Kita memanggil model.fit untuk memulai loop pelatihan. Kita juga meneruskan properti validationData untuk menunjukkan data mana yang harus digunakan model untuk menguji dirinya sendiri setelah setiap iterasi pelatihan (tetapi tidak digunakan untuk pelatihan).
Jika performa kita baik pada data pelatihan tetapi tidak pada data validasi, artinya model tersebut cenderung melakukan overfitting ke data pelatihan dan tidak akan melakukan generalisasi dengan baik pada input yang sebelumnya tidak dilihat.
Akurasi validasi memberikan estimasi yang baik tentang kualitas performa model terhadap data yang belum pernah dilihat sebelumnya (asalkan data tersebut menyerupai validasi dengan cara tertentu). Namun, kita mungkin menginginkan perincian performa yang lebih mendetail di seluruh class yang berbeda.
Ada beberapa metode dalam tfjs-vis yang dapat membantu Anda dalam hal ini.
Tambahkan kode berikut ke bagian bawah file script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Apa yang dilakukan kode ini?
- Membuat prediksi.
- Menghitung metrik akurasi.
- Menampilkan metrik
Mari kita pelajari setiap langkahnya lebih lanjut.
Membuat Prediksi
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Pertama, kita perlu membuat beberapa prediksi. Di sini, kita akan mengambil 500 gambar dan memprediksi jumlah angka di dalamnya (Anda dapat meningkatkan jumlah ini nanti untuk menguji kumpulan gambar yang lebih besar).
Khususnya fungsi argmax yang memberikan indeks dari class probabilitas tertinggi. Ingat bahwa model menghasilkan output probabilitas untuk setiap class. Di sini kita melihat probabilitas tertinggi dan menetapkannya sebagai prediksi.
Anda juga mungkin melihat bahwa kita dapat memprediksi 500 contoh sekaligus. Ini adalah kecanggihan vektorisasi yang disediakan TensorFlow.js.
Menampilkan akurasi per class
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Dengan kumpulan prediksi dan label, kita dapat menghitung akurasi untuk setiap class.
Menampilkan matriks konfusi
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Matriks konfusi mirip dengan akurasi per class, tetapi dipecah lebih lanjut untuk menunjukkan pola kesalahan klasifikasi. Dengan demikian, Anda dapat melihat apakah model mengalami kebingungan terkait pasangan class tertentu.
Menampilkan evaluasi
Tambahkan kode berikut ke bagian bawah fungsi yang dijalankan untuk menampilkan evaluasi.
await showAccuracy(model, data);
await showConfusion(model, data);
Anda akan melihat tampilan seperti ini.
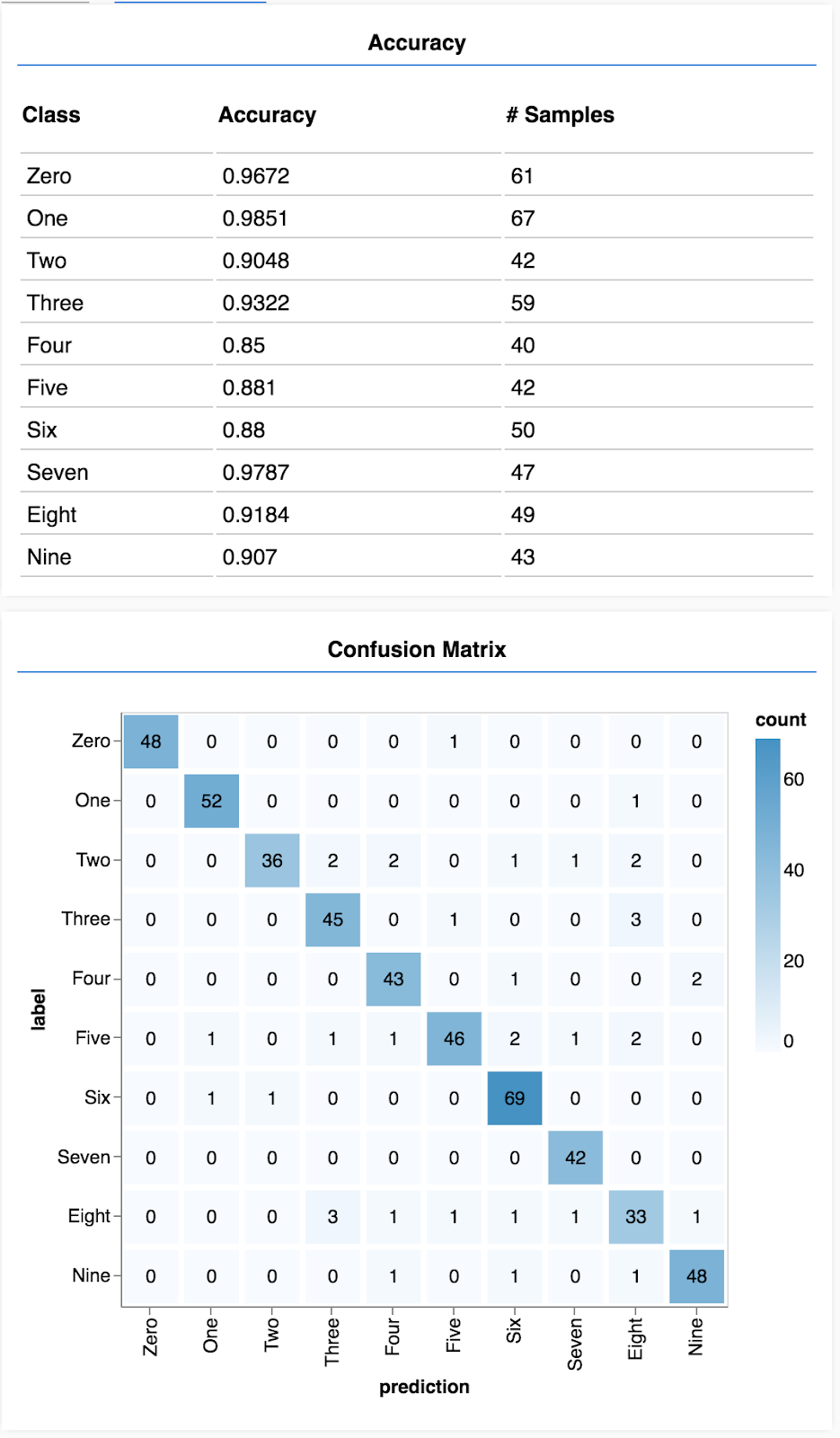
Selamat! Anda baru saja berhasil melatih jaringan neural konvolusional!
Memprediksi kategori untuk data input disebut tugas klasifikasi.
Tugas klasifikasi memerlukan representasi data yang sesuai untuk label
- Representasi umum label mencakup enkode one-hot untuk kategori
Menyiapkan data:
- Sebaiknya simpan beberapa data yang tidak pernah dilihat model selama pelatihan yang dapat Anda gunakan untuk mengevaluasi model. Ini disebut set validasi.
Mem-build dan menjalankan model:
- Model konvolusional telah terbukti berperforma dengan baik dalam tugas gambar.
- Masalah klasifikasi biasanya menggunakan entropi silang kategori untuk fungsi kerugian.
- Pantau pelatihan untuk melihat apakah kerugian menurun dan akurasinya meningkat.
Mengevaluasi model Anda
- Tentukan beberapa cara untuk mengevaluasi model Anda setelah dilatih untuk melihat seberapa baik performanya pada masalah awal yang ingin Anda pecahkan.
- Akurasi per class dan matriks konfusi dapat memberikan perincian performa model yang lebih baik daripada sekadar akurasi secara keseluruhan.