
1. Einführung
In dieser Anleitung erstellen wir ein TensorFlow.js-Modell, um handschriftliche Ziffern mit einem Convolutional Neural Network zu erkennen. Zuerst trainieren wir den Klassifikator, Tausende handschriftliche Ziffern und ihre Beschriftungen. Anschließend bewerten wir die Genauigkeit des Klassifikators anhand von Testdaten, die das Modell noch nie gesehen hat.
Diese Aufgabe gilt als Klassifizierungsaufgabe, da wir das Modell so trainieren, dass es dem Eingabebild eine Kategorie (die im Bild angezeigte Ziffer) zuweist. Wir trainieren das Modell, indem wir ihm viele Beispiele für Eingaben und die richtige Ausgabe zeigen. Dies wird als überwachtes Lernen bezeichnet.
Umfang
Sie erstellen eine Webseite, auf der mithilfe von TensorFlow.js ein Modell im Browser trainiert wird. Bei einem Schwarz-Weiß-Bild einer bestimmten Größe wird klassifiziert, welche Ziffer im Bild zu sehen ist. Dazu sind folgende Schritte erforderlich:
- Laden Sie die Daten.
- Definieren Sie die Architektur des Modells.
- Trainieren Sie das Modell und überwachen Sie seine Leistung während des Trainings.
- Trainiertes Modell anhand einiger Vorhersagen bewerten.
Aufgaben in diesem Lab
- TensorFlow.js-Syntax zum Erstellen von Faltungsmodellen mit der TensorFlow.js Layers API.
- Klassifizierungsaufgaben in TensorFlow.js formulieren
- Browsertraining mit der tfjs-vis-Bibliothek überwachen
Voraussetzungen
- Eine aktuelle Version von Chrome oder eines anderen modernen Browsers, der ES6-Module unterstützt
- Einen Texteditor, der entweder lokal auf Ihrem Computer oder im Web über Codepen oder Glitch ausgeführt wird
- Kenntnisse in HTML, CSS, JavaScript und Chrome-Entwicklertools bzw. den Entwicklertools Ihrer bevorzugten Browser
- Ein konzeptionelles Verständnis von neuronalen Netzwerken. Wenn Sie eine Einführung oder Auffrischung benötigen, können Sie sich dieses Video von 3blue1brown oder dieses Video zu Deep Learning in JavaScript von Ashi Krishnan ansehen.
Außerdem sollten Sie mit den Inhalten unserer ersten Schulungsanleitung vertraut sein.
2. Einrichten
Erstellen Sie eine HTML-Seite und fügen Sie den JavaScript-Code
 Kopieren Sie den folgenden Code in eine HTML-Datei namens
Kopieren Sie den folgenden Code in eine HTML-Datei namens
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
JavaScript-Dateien für die Daten und den Code erstellen
- Erstellen Sie im selben Ordner wie die HTML-Datei oben eine Datei mit dem Namen data.js und kopieren Sie den Inhalt aus diesem Link in diese Datei.
- Erstellen Sie im selben Ordner wie Schritt 1 eine Datei mit dem Namen script.js und fügen Sie den folgenden Code ein.
console.log('Hello TensorFlow');
Jetzt testen
Nachdem Sie nun die HTML- und JavaScript-Dateien erstellt haben, testen Sie sie. Öffnen Sie die Datei „index.html“ in Ihrem Browser und öffnen Sie die Entwicklertools-Konsole.
Wenn alles funktioniert, sollten zwei globale Variablen erstellt werden. tf ist ein Verweis auf die TensorFlow.js-Bibliothek, tfvis ein Verweis auf die tfjs-vis-Bibliothek.
Die Meldung Hello TensorFlow, sollte angezeigt werden,wenn ja, können Sie mit dem nächsten Schritt fortfahren.
3. Laden Sie die Daten:
In dieser Anleitung trainieren Sie ein Modell, das Ziffern wie in den folgenden Bildern erkennt. Diese Bilder sind 28 × 28 Pixel große Graustufenbilder aus einem Dataset mit dem Namen MNIST.

Wir haben Code bereitgestellt, um diese Bilder aus einer speziellen Sprite-Datei (~10 MB) zu laden, die wir für Sie erstellt haben. So können wir uns auf den Trainingsteil konzentrieren.
Sehen Sie sich die Datei data.js genau an, um zu verstehen, wie die Daten geladen werden. Wenn Sie mit dieser Anleitung fertig sind, können Sie auch einen eigenen Ansatz zum Laden der Daten erstellen.
Der bereitgestellte Code enthält die Klasse MnistData mit zwei öffentlichen Methoden:
nextTrainBatch(batchSize): gibt einen zufälligen Batch von Bildern und ihren Labels aus dem Trainings-Dataset zurücknextTestBatch(batchSize): gibt einen Batch von Bildern und ihren Labels aus dem Test-Dataset zurück
Die MnistData-Klasse führt außerdem die wichtigen Schritte für die Shuffle- und Normalisierung der Daten aus.
Es gibt insgesamt 65.000 Bilder. Wir verwenden bis zu 55.000 Bilder, um das Modell zu trainieren, und speichern 10.000 Bilder, mit denen wir die Leistung des Modells testen können, sobald wir fertig sind. Und all das machen wir im Browser!
Lassen Sie uns die Daten laden und testen, ob sie korrekt geladen wurden.
Fügen Sie der Datei script.js den folgenden Code hinzu.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Aktualisieren Sie die Seite. Nach einigen Sekunden sollten Sie links einen Bereich mit einer Reihe von Bildern sehen.

4. Unsere Aufgabe entwerfen
Unsere Eingabedaten sehen so aus.
Unser Ziel ist es, ein Modell zu trainieren, das ein Bild nimmt und lernt, eine Punktzahl für jede der möglichen zehn Klassen vorherzusagen, zu denen das Bild gehören könnte (die Ziffern 0–9).
Jedes Bild ist 28 Pixel breit und 28 Pixel hoch und hat einen Farbkanal wie ein Graustufenbild. Die Form jedes Bildes ist also [28, 28, 1].
Denken Sie daran, dass wir eine 1:1-Zuordnung sowie die Form jedes Eingabebeispiels erstellen, da dies für den nächsten Abschnitt wichtig ist.
5. Modellarchitektur definieren
In diesem Abschnitt schreiben wir Code, um die Modellarchitektur zu beschreiben. Modellarchitektur ist eine raffinierte Art zu sagen: „Welche Funktionen wird das Modell ausgeführt, wenn es ausgeführt wird?“ oder alternativ „Welchen Algorithmus verwendet unser Modell zur Berechnung seiner Antworten“.
Beim maschinellen Lernen definieren wir eine Architektur (oder einen Algorithmus) und lassen den Trainingsprozess die Parameter dieses Algorithmus lernen.
Fügen Sie Ihrem die folgende Funktion hinzu:
Datei script.js zum Definieren der Modellarchitektur
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Sehen wir uns das etwas genauer an.
Faltungen
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Hier verwenden wir ein sequenzielles Modell.
Wir verwenden eine conv2d-Ebene anstelle einer dichten Ebene. Wir können nicht im Detail auf die Funktionsweise von Faltungen eingehen, aber hier sind einige Ressourcen, in denen die zugrunde liegende Operation erläutert wird:
Schlüsseln wir die einzelnen Argumente im Konfigurationsobjekt für conv2d auf:
inputShapeDie Form der Daten, die in die erste Ebene des Modells einfließen. In diesem Fall sind unsere MNIST-Beispiele 28 x 28 Pixel große Schwarz-Weiß-Bilder. Das kanonische Format für Bilddaten ist[row, column, depth]. Hier möchten wir die Form[28, 28, 1]konfigurieren. 28 Zeilen und Spalten für die Anzahl der Pixel in jeder Dimension und eine Tiefe von 1, da unsere Bilder nur einen Farbkanal haben. Beachten Sie, dass wir keine Batchgröße in der Eingabeform angeben. Layer sind so konzipiert, dass sie die Batchgröße unabhängig sind, sodass Sie während der Inferenz einen Tensor mit einer beliebigen Batchgröße übergeben können.kernelSizeDie Größe der gleitenden Faltungsfilterfenster, die auf die Eingabedaten angewendet werden sollen. Hier legen wir einekernelSizevon5fest, was ein quadratisches 5x5-Faltungsfenster angibt.filtersDie Anzahl der Filterfenster der GrößekernelSize, die auf die Eingabedaten angewendet werden sollen. Hier wenden wir acht Filter auf die Daten an.stridesDie „Schrittgröße“ des gleitenden Fensters, d.h. um wie viele Pixel der Filter jedes Mal verschoben wird, wenn er über das Bild bewegt wird. Hier geben wir Schrittschritte von 1 an, was bedeutet, dass der Filter in Schritten von 1 Pixel über das Bild gleitet.activationDie Aktivierungsfunktion, die auf die Daten angewendet werden soll, nachdem die Faltung abgeschlossen ist. In diesem Fall wenden wir eine ReLU-Funktion (ReLU) an. Dies ist eine in ML-Modellen sehr häufige Aktivierungsfunktion.kernelInitializerDie Methode zur zufälligen Initialisierung der Modellgewichtungen, die für das Training der Dynamik sehr wichtig ist. Wir gehen hier nicht auf die Details der Initialisierung ein, aberVarianceScaling(hier verwendet) ist im Allgemeinen eine gute Initialisierungslösung.
Datendarstellung vereinfachen
model.add(tf.layers.flatten());
Bilder sind hochdimensionale Daten und Faltungsvorgänge erhöhen tendenziell die Größe der Daten, die in sie aufgenommen werden. Bevor wir sie an unsere letzte Klassifizierungsschicht übergeben, müssen wir die Daten in einem langen Array zusammenfassen. Dichte Ebenen, die wir als letzte Ebene verwenden, benötigen nur tensor1ds, daher ist dieser Schritt bei vielen Klassifizierungsaufgaben üblich.
Die endgültige Wahrscheinlichkeitsverteilung berechnen
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Wir verwenden eine dichte Schicht mit einer Softmax-Aktivierung, um die Wahrscheinlichkeitsverteilungen über die zehn möglichen Klassen zu berechnen. Die Klasse mit der höchsten Punktzahl ist die vorhergesagte Ziffer.
Optimierungs- und Verlustfunktion auswählen
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Wir stellen das Modell zusammen und geben ein Optimierungstool, eine Verlustfunktion und Messwerte an, die wir verfolgen möchten.
Im Gegensatz zu unserer ersten Anleitung verwenden wir hier categoricalCrossentropy als Verlustfunktion. Wie der Name schon sagt, wird dies verwendet, wenn die Ausgabe unseres Modells eine Wahrscheinlichkeitsverteilung ist. categoricalCrossentropy misst den Fehler zwischen der Wahrscheinlichkeitsverteilung, die von der letzten Schicht unseres Modells generiert wurde, und der Wahrscheinlichkeitsverteilung, die durch unser wahres Label vorgegeben wird.
Wenn unsere Ziffer beispielsweise wirklich eine 7 darstellt, könnten wir die folgenden Ergebnisse erhalten:
Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Richtiges Label | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Vorhersage | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
Bei der kategorialen Kreuzentropie wird eine einzelne Zahl erzeugt, die angibt, wie ähnlich der Vorhersagevektor unserem tatsächlichen Labelvektor ist.
Die hier für die Labels verwendete Datendarstellung wird als One-Hot-Codierung bezeichnet und kommt häufig bei Klassifizierungsproblemen vor. Jeder Klasse ist für jedes Beispiel eine Wahrscheinlichkeit zugeordnet. Wenn wir genau wissen, wie es sein soll, können wir diese Wahrscheinlichkeit auf 1 und die anderen auf 0 setzen. Weitere Informationen zur One-Hot-Codierung
Der andere Messwert, den wir beobachten, ist accuracy. Dieser gibt für ein Klassifizierungsproblem den Prozentsatz der richtigen Vorhersagen aus allen Vorhersagen an.
6. Modell trainieren
Kopieren Sie die folgende Funktion in Ihre script.js-Datei.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Fügen Sie dann folgenden Code zu Ihrem
run -Funktion.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Aktualisieren Sie die Seite. Nach einigen Sekunden sollten Sie einige Grafiken sehen, die den Trainingsfortschritt melden.
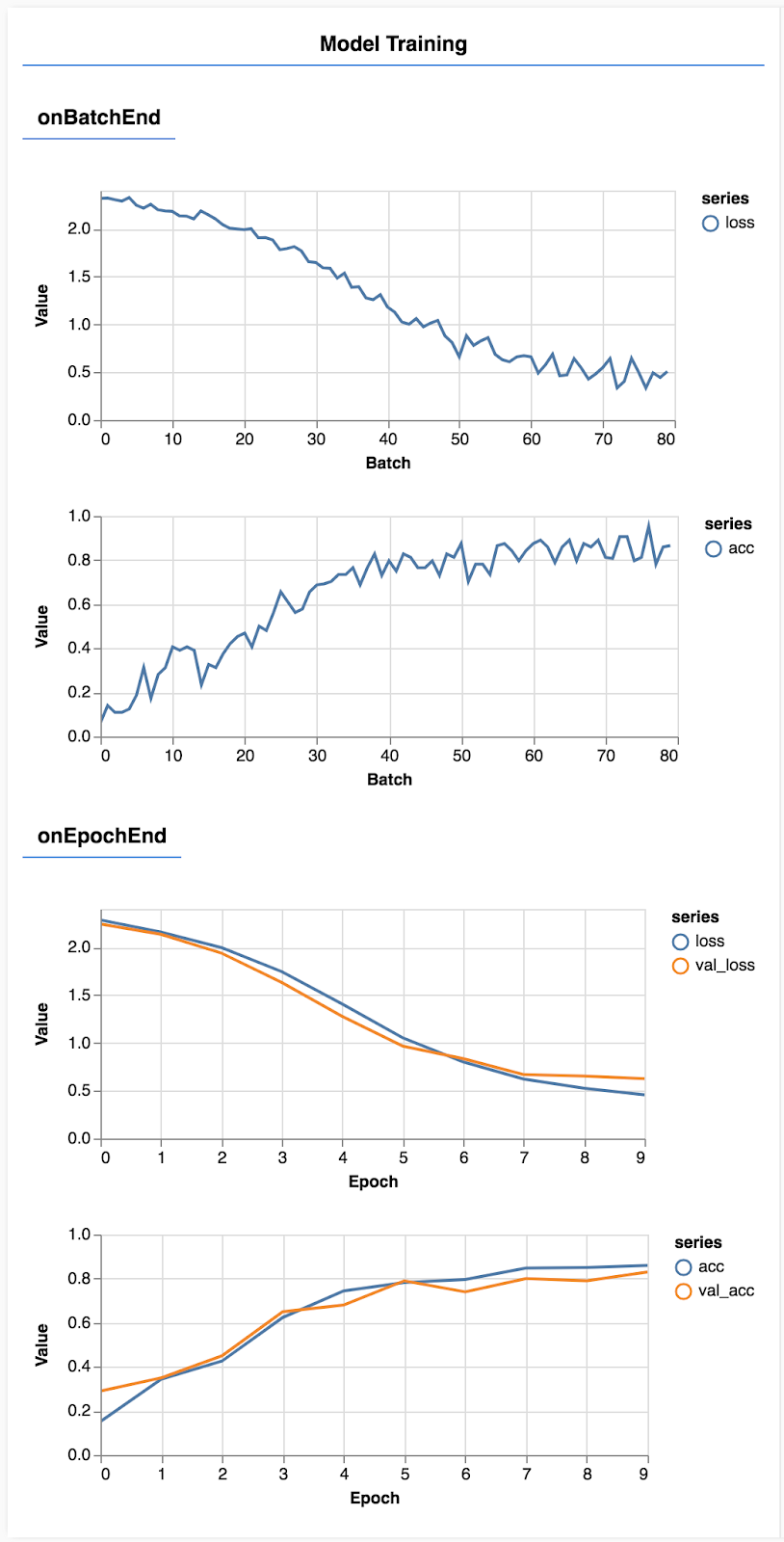
Sehen wir uns das etwas genauer an.
Messwerte beobachten
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Hier entscheiden wir, welche Metriken überwacht werden. Wir beobachten den Verlust und die Genauigkeit des Trainings-Datasets sowie den Verlust und die Genauigkeit des Validierungs-Datasets (val_loss bzw. val_acc). Im Folgenden gehen wir näher auf das Validierungs-Dataset ein.
Daten als Tensoren vorbereiten
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Hier erstellen wir zwei Datasets: ein Trainings-Dataset, mit dem das Modell trainiert wird, und ein Validierungs-Dataset, mit dem wir das Modell am Ende jeder Epoche testen. Die Daten im Validierungs-Dataset werden dem Modell jedoch während des Trainings nie angezeigt.
Die bereitgestellte Datenklasse erleichtert das Abrufen von Tensoren aus den Bilddaten. Aber wir formen die Tensoren noch in die vom Modell erwartete Form [num_examples, image_width, image_height, channels], bevor wir sie in das Modell einspeisen. Für jedes Dataset gibt es sowohl Eingaben (X) als auch Beschriftungen (Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Wir rufen „model.fit“ auf, um die Trainingsschleife zu starten. Außerdem übergeben wir eine Eigenschaft „validationData“, um anzugeben, mit welchen Daten sich das Modell nach jeder Epoche selbst testen soll (aber nicht für das Training).
Wenn wir mit unseren Trainingsdaten gute Ergebnisse erzielen, aber nicht mit unseren Validierungsdaten, ist das Modell wahrscheinlich überanpassung an die Trainingsdaten und wird nicht richtig verallgemeinern, um bisher unbekannte Eingaben zu treffen.
7. Modell bewerten
Die Validierungsgenauigkeit ist eine gute Schätzung, wie gut unser Modell mit Daten abschneiden wird, die es zuvor noch nicht gesehen hat – solange diese Daten dem Validierungs-Dataset in irgendeiner Weise ähneln. Möglicherweise benötigen wir jedoch eine detailliertere Aufschlüsselung der Leistung der verschiedenen Klassen.
In tfjs-vis gibt es einige Methoden, die Ihnen dabei helfen können.
Fügen Sie unten in der script.js-Datei den folgenden Code ein:
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Wozu dient dieser Code?
- Trifft eine Vorhersage.
- Berechnet die Genauigkeitsmesswerte.
- Zeigt die Messwerte an
Sehen wir uns die einzelnen Schritte etwas genauer an.
Vorhersagen treffen
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Zunächst müssen wir einige Vorhersagen treffen. Hier erstellen wir 500 Bilder und vorhersagen, welche Ziffer darin enthalten ist. Sie können diese Zahl später erhöhen, um sie mit einer größeren Anzahl von Bildern zu testen.
Insbesondere die argmax-Funktion gibt uns den Index der höchsten Wahrscheinlichkeitsklasse. Denken Sie daran, dass das Modell für jede Klasse eine Wahrscheinlichkeit ausgibt. Hier ermitteln wir die höchste Wahrscheinlichkeit und weisen diese als Vorhersage zu.
Sie werden auch feststellen, dass wir Vorhersagen für alle 500 Beispiele gleichzeitig erstellen können. Dies ist die Leistungsfähigkeit der Vektorisierung, die TensorFlow.js bietet.
Genauigkeit nach Klasse anzeigen
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Mit einem Satz von Vorhersagen und Labels können wir die Genauigkeit für jede Klasse berechnen.
Wahrheitsmatrix anzeigen
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Eine Wahrheitsmatrix ist der Genauigkeit pro Klasse ähnlich, schlüsselt sie jedoch weiter auf, um Muster für falsche Klassifizierungen aufzuzeigen. Damit können Sie feststellen, ob das Modell in Bezug auf bestimmte Klassenpaare verwechselt wird.
Bewertung anzeigen
Fügen Sie am Ende der Ausführungsfunktion den folgenden Code ein, um die Bewertung anzuzeigen.
await showAccuracy(model, data);
await showConfusion(model, data);
Sie sollten eine Anzeige sehen, die in etwa so aussieht:
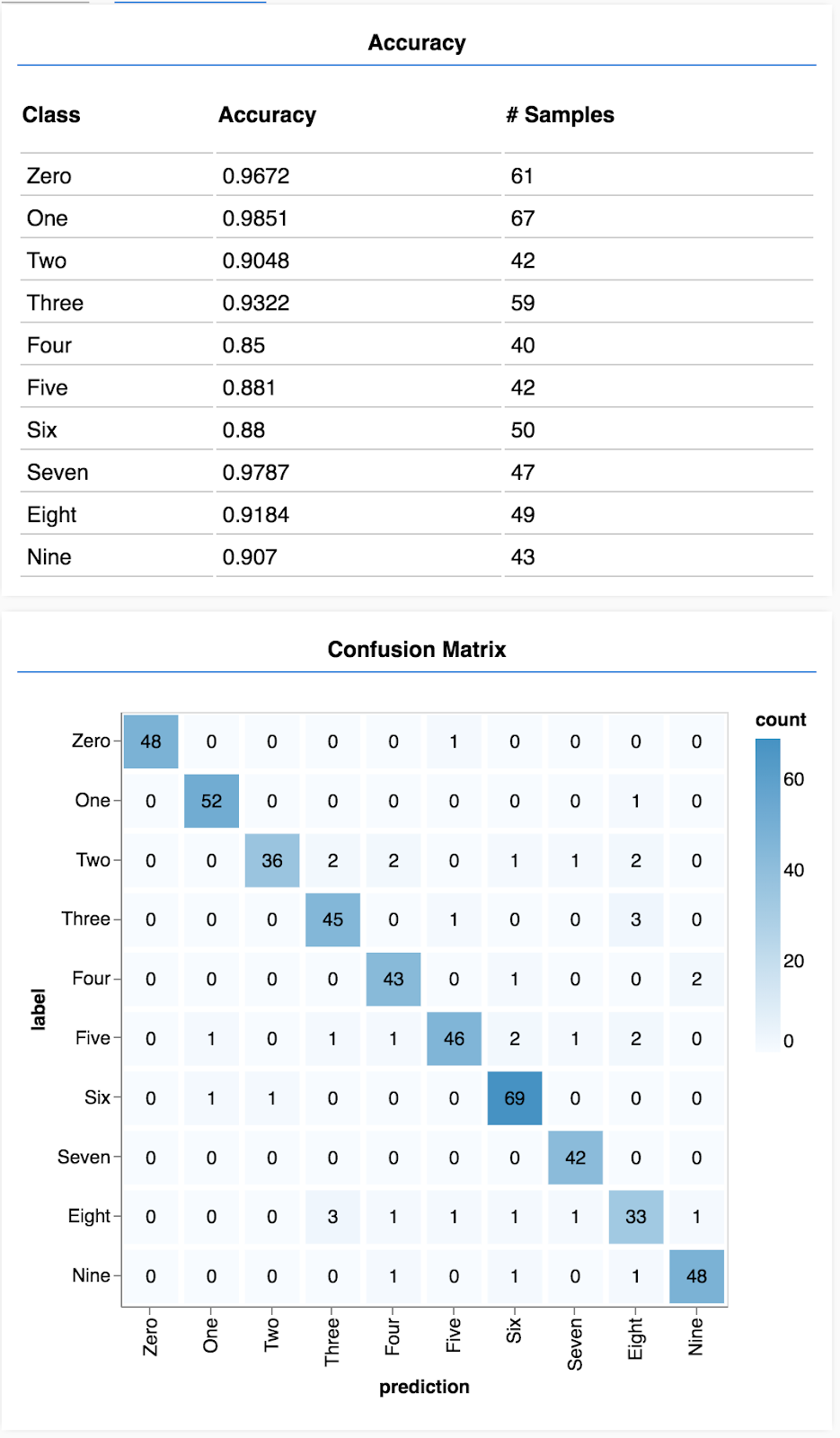
Glückwunsch! Sie haben gerade ein Convolutional Neural Network trainiert!
8. Wichtigste Erkenntnisse
Das Vorhersage von Kategorien für Eingabedaten wird als Klassifizierungsaufgabe bezeichnet.
Klassifizierungsaufgaben erfordern eine entsprechende Datendarstellung für die Labels
- Zu den gängigen Darstellungen von Labels gehört die One-Hot-Codierung von Kategorien
Bereiten Sie Ihre Daten vor:
- Es ist hilfreich, einige Daten beiseitezuhalten, die das Modell während des Trainings nicht sieht und die Sie zum Bewerten des Modells verwenden können. Dies wird als Validierungs-Dataset bezeichnet.
Erstellen Sie Ihr Modell und führen Sie es aus:
- Faltungsmodelle funktionieren nachweislich gut bei Bildaufgaben.
- Bei Klassifizierungsproblemen wird normalerweise die kategoriale Kreuzentropie für ihre Verlustfunktionen verwendet.
- Überwachen Sie das Training, um zu sehen, ob der Verlust sinkt und die Genauigkeit steigt.
Modell bewerten
- Entscheiden Sie sich für eine Möglichkeit, Ihr Modell nach dem Training zu bewerten, um zu sehen, wie gut es bei dem ursprünglichen Problem, das Sie lösen wollten, funktioniert.
- Genauigkeits- und Wahrheitsmatrizen pro Klasse können eine detailliertere Aufschlüsselung der Modellleistung als nur die Gesamtgenauigkeit ermöglichen.