
1. Giới thiệu
Trong hướng dẫn này, chúng ta sẽ xây dựng một mô hình TensorFlow.js để nhận dạng các chữ số viết tay bằng mạng nơron tích chập. Trước tiên, chúng tôi sẽ huấn luyện thuật toán phân loại bằng cách "xem" hàng nghìn hình ảnh có chữ số viết tay và nhãn của chúng. Sau đó, chúng ta sẽ đánh giá độ chính xác của thuật toán phân loại bằng cách sử dụng dữ liệu kiểm thử mà mô hình chưa từng thấy.
Nhiệm vụ này được coi là nhiệm vụ phân loại vì chúng tôi đang huấn luyện mô hình để gán một danh mục (chữ số xuất hiện trong hình ảnh) cho hình ảnh đầu vào. Chúng ta sẽ huấn luyện mô hình bằng cách cho xem nhiều ví dụ về dữ liệu đầu vào cùng với dữ liệu đầu ra chính xác. Phương pháp này được gọi là học có giám sát.
Sản phẩm bạn sẽ tạo ra
Bạn sẽ tạo một trang web sử dụng TensorFlow.js để huấn luyện một mô hình trong trình duyệt. Khi cung cấp hình ảnh đen trắng có kích thước cụ thể, ứng dụng sẽ phân loại chữ số nào xuất hiện trong hình ảnh. Các bước thực hiện như sau:
- Tải dữ liệu.
- Xác định cấu trúc của mô hình.
- Huấn luyện mô hình và theo dõi hiệu suất của mô hình trong quá trình huấn luyện.
- Đánh giá mô hình đã huấn luyện bằng cách đưa ra một số dự đoán.
Kiến thức bạn sẽ học được
- Cú pháp TensorFlow.js để tạo mô hình tích chập bằng API Lớp TensorFlow.js.
- Lập nhiệm vụ phân loại trong TensorFlow.js
- Cách theo dõi hoạt động huấn luyện trong trình duyệt bằng thư viện tfjs-vis.
Bạn cần có
- Phiên bản Chrome mới nhất hoặc một trình duyệt hiện đại khác hỗ trợ các mô-đun ES6.
- Một trình chỉnh sửa văn bản, chạy cục bộ trên máy của bạn hoặc trên web thông qua Codepen hoặc Glitch.
- Có kiến thức về HTML, CSS, JavaScript và Công cụ của Chrome cho nhà phát triển (hoặc công cụ cho nhà phát triển của trình duyệt mà bạn ưu tiên).
- Có kiến thức khái niệm tổng quan về Mạng nơron. Nếu bạn cần giới thiệu hoặc ôn tập lại, hãy cân nhắc xem video này của 3blue1brown hoặc video về Học sâu bằng JavaScript của Ashi Krishnan.
Bạn cũng đã nắm rõ tài liệu này trong hướng dẫn đào tạo đầu tiên của chúng tôi.
2. Bắt đầu thiết lập
Tạo trang HTML và đưa JavaScript vào
 Sao chép mã sau đây vào tệp html có tên
Sao chép mã sau đây vào tệp html có tên
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Tạo tệp JavaScript cho dữ liệu và mã
- Trong cùng thư mục với tệp HTML ở trên, hãy tạo tệp có tên data.js và sao chép nội dung từ đường liên kết này vào tệp đó.
- Trong cùng thư mục với bước 1, hãy tạo một tệp có tên script.js và đặt đoạn mã sau vào đó.
console.log('Hello TensorFlow');
Dùng thử
Giờ bạn đã tạo các tệp HTML và JavaScript, hãy kiểm tra chúng. Mở tệpindex.html trong trình duyệt của bạn và mở bảng điều khiển công cụ cho nhà phát triển.
Nếu mọi thứ đang hoạt động, bạn nên tạo 2 biến toàn cục. tf là mã tham chiếu đến thư viện TensorFlow.js, tfvis là tham chiếu đến thư viện tfjs-vis.
Bạn sẽ thấy một thông báo cho biết Hello TensorFlow, nếu vậy thì tức là bạn đã sẵn sàng chuyển sang bước tiếp theo.
3. Tải dữ liệu
Trong hướng dẫn này, bạn sẽ huấn luyện một mô hình học cách nhận dạng các chữ số trong ảnh như các chữ số dưới đây. Những hình ảnh này là hình ảnh thang màu xám có kích thước 28x28px từ một tập dữ liệu có tên là MNIST.
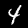

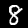
Chúng tôi đã cung cấp mã để tải những hình ảnh này từ một tệp sprite đặc biệt (~10MB) mà chúng tôi đã tạo cho bạn để có thể tập trung vào phần huấn luyện.
Vui lòng nghiên cứu tệp data.js để hiểu cách dữ liệu được tải. Hoặc sau khi bạn hoàn tất hướng dẫn này, hãy tạo phương pháp tải dữ liệu của riêng bạn.
Mã đã cung cấp chứa một lớp MnistData có hai phương thức công khai:
nextTrainBatch(batchSize): trả về một loạt hình ảnh ngẫu nhiên và nhãn của các hình ảnh đó từ tập hợp huấn luyện.nextTestBatch(batchSize): trả về một loạt hình ảnh và nhãn của các hình ảnh đó từ nhóm kiểm thử
Lớp MnistData cũng thực hiện các bước quan trọng để xáo trộn và chuẩn hoá dữ liệu.
Có tổng cộng 65.000 hình ảnh, chúng ta sẽ sử dụng tối đa 55.000 hình ảnh để huấn luyện mô hình, lưu 10.000 hình ảnh mà chúng ta có thể sử dụng để kiểm thử hiệu suất của mô hình sau khi hoàn tất. Và chúng ta sẽ thực hiện tất cả những điều đó trong trình duyệt!
Hãy tải dữ liệu và kiểm tra để đảm bảo rằng dữ liệu đã được tải đúng cách.
Thêm mã sau vào tệp script.js của bạn.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Hãy làm mới trang. Sau vài giây, bạn sẽ thấy một bảng điều khiển ở bên trái có nhiều hình ảnh.

4. Khái niệm nhiệm vụ của chúng ta
Dữ liệu đầu vào của chúng ta có dạng như sau.
Mục tiêu của chúng ta là huấn luyện một mô hình sẽ chụp một hình ảnh và tìm hiểu cách dự đoán điểm cho mỗi lớp trong số 10 lớp có thể chứa hình ảnh đó (các chữ số 0-9).
Mỗi hình ảnh rộng 28px, cao 28px và có một kênh màu vì nó là một hình ảnh có thang màu xám. Vì vậy, hình dạng của mỗi hình ảnh là [28, 28, 1].
Hãy nhớ rằng chúng ta thực hiện ánh xạ một với mười, cũng như hình dạng của mỗi ví dụ về dữ liệu đầu vào, vì điều này rất quan trọng đối với phần tiếp theo.
5. Xác định cấu trúc mô hình
Trong phần này, chúng ta sẽ viết mã để mô tả cấu trúc mô hình. Cấu trúc mô hình là một cách nói khác lạ để cho biết "mô hình sẽ chạy những hàm nào khi đang thực thi", hoặc một cách khác là "mô hình của chúng ta sẽ sử dụng thuật toán nào để tính toán các câu trả lời".
Trong công nghệ học máy, chúng ta xác định một cấu trúc (hoặc thuật toán) và để quá trình huấn luyện tìm hiểu các tham số của thuật toán đó.
Thêm hàm sau vào
Tệp script.js để xác định cấu trúc mô hình
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Hãy cùng xem xét điều này chi tiết hơn một chút.
Tích chập
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Ở đây chúng tôi sử dụng mô hình tuần tự.
Chúng ta đang sử dụng lớp conv2d thay vì lớp dày đặc. Chúng tôi không thể đi sâu vào toàn bộ thông tin chi tiết về cách hoạt động của phép chập, nhưng sau đây là một số tài liệu giải thích về phép toán cơ bản:
Hãy phân tích từng đối số trong đối tượng cấu hình cho conv2d:
inputShape. Hình dạng của dữ liệu sẽ chuyển vào lớp đầu tiên của mô hình. Trong trường hợp này, ví dụ về MNIST của chúng tôi là ảnh đen trắng 28x28 pixel. Định dạng chuẩn cho dữ liệu hình ảnh là[row, column, depth], vì vậy, ở đây chúng ta muốn định cấu hình hình dạng của[28, 28, 1]. 28 hàng và cột cho số lượng pixel trong mỗi chiều và độ sâu là 1 vì hình ảnh của chúng ta chỉ có 1 kênh màu. Lưu ý rằng chúng ta không chỉ định kích thước lô trong hình dạng dữ liệu nhập. Lớp được thiết kế không phụ thuộc vào kích thước lô để trong quá trình suy luận, bạn có thể truyền một tensor có kích thước lô bất kỳ vào.kernelSize. Kích thước của các cửa sổ bộ lọc tích chập trượt được áp dụng cho dữ liệu đầu vào. Ở đây, chúng ta đặtkernelSizelà5. Giá trị này chỉ định một cửa sổ tích chập hình vuông có kích thước 5x5.filters. Số lượng cửa sổ bộ lọc có kích thướckernelSizeđể áp dụng cho dữ liệu đầu vào. Ở đây, chúng ta sẽ áp dụng 8 bộ lọc cho dữ liệu.strides. "Kích thước bước" của cửa sổ trượt, tức là số lượng pixel mà bộ lọc sẽ dịch chuyển mỗi khi di chuyển qua hình ảnh. Ở đây, chúng tôi xác định các bước là 1, có nghĩa là bộ lọc sẽ trượt trên hình ảnh theo các bước 1 pixel.activation. Hàm kích hoạt để áp dụng cho dữ liệu sau khi tích chập hoàn tất. Trong trường hợp này, chúng ta sẽ áp dụng hàm Đơn vị tuyến tính đã chỉnh sửa (ReLU). Đây là hàm kích hoạt rất phổ biến trong các mô hình học máy.kernelInitializer. Phương thức sử dụng để khởi tạo ngẫu nhiên trọng số mô hình, rất quan trọng trong việc huấn luyện động lực học. Chúng ta sẽ không đi vào thông tin chi tiết về việc khởi chạy ở đây, nhưngVarianceScaling(được sử dụng ở đây) thường là một lựa chọn tốt về trình khởi tạo.
Làm phẳng nội dung trình bày trong dữ liệu
model.add(tf.layers.flatten());
Hình ảnh là dữ liệu chứa nhiều thứ nguyên và phép toán tích chập có xu hướng làm tăng kích thước của dữ liệu chứa hình ảnh. Trước khi chuyển chúng đến lớp phân loại cuối cùng, chúng ta cần làm phẳng dữ liệu thành một mảng dài. Các lớp dày đặc (mà chúng ta sử dụng làm lớp cuối cùng) chỉ mất tensor1d, vì vậy, bước này phổ biến trong nhiều tác vụ phân loại.
Tính toán hàm phân phối xác suất cuối cùng
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Chúng ta sẽ sử dụng một lớp dày đặc có kích hoạt softmax để tính toán phân phối xác suất trên 10 lớp có thể có. Lớp có điểm cao nhất sẽ là chữ số được dự đoán.
Chọn trình tối ưu hoá và hàm ngừng sử dụng
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Chúng ta biên dịch mô hình chỉ định trình tối ưu hoá, hàm mất và các chỉ số mà chúng ta muốn theo dõi.
Trái ngược với hướng dẫn đầu tiên, ở đây chúng ta sử dụng categoricalCrossentropy làm hàm mất dữ liệu. Đúng như tên gọi, hàm này được sử dụng khi đầu ra của mô hình là phân phối xác suất. categoricalCrossentropy đo lường lỗi giữa phân phối xác suất do lớp cuối cùng của mô hình tạo ra và phân phối xác suất do nhãn thực của chúng ta đưa ra.
Ví dụ: nếu chữ số của chúng ta thực sự đại diện cho số 7, chúng ta có thể có kết quả như sau
Chỉ mục | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Nhãn thực | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Dự đoán | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
Entropy chéo phân loại sẽ tạo ra một số duy nhất cho biết vectơ dự đoán tương tự như vectơ dự đoán với vectơ nhãn thực của chúng ta.
Cách trình bày dữ liệu dùng ở đây cho các nhãn được gọi là mã hoá một lần và thường gặp trong các vấn đề phân loại. Mỗi lớp đều có một xác suất liên kết với lớp đó cho từng ví dụ. Khi chúng ta biết chính xác giá trị đó, chúng ta có thể đặt xác suất đó thành 1 và các xác suất khác thành 0. Xem trang này để biết thêm thông tin về phương thức mã hoá một lần.
Chỉ số khác mà chúng tôi sẽ theo dõi là accuracy. Đối với vấn đề về phân loại, chúng tôi sẽ theo dõi tỷ lệ phần trăm cụm từ gợi ý chính xác trong số tất cả các cụm từ gợi ý.
6. Huấn luyện mô hình
Sao chép hàm sau đây vào tệp script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Sau đó, hãy thêm mã sau vào
run hàm.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Hãy làm mới trang. Sau vài giây, bạn sẽ thấy một số biểu đồ báo cáo tiến độ đào tạo.
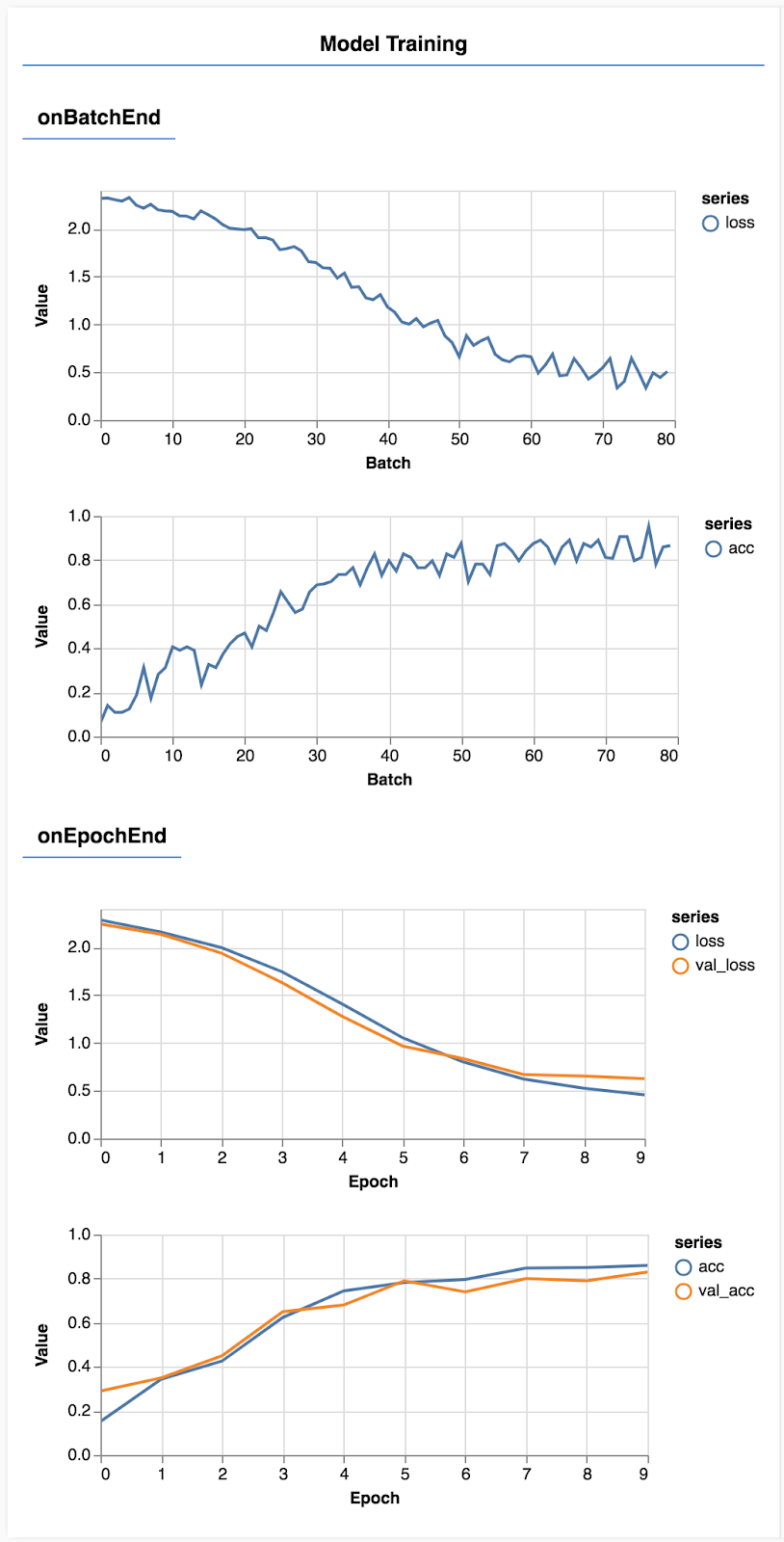
Hãy xem xét chi tiết hơn một chút.
Theo dõi các chỉ số
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Tại đây, chúng tôi quyết định sẽ theo dõi các chỉ số nào. Chúng tôi sẽ theo dõi mức độ mất mát và độ chính xác trên tập huấn luyện, cũng như sự mất mát và độ chính xác trên tập hợp xác thực (val_loss và val_acc tương ứng). Chúng ta sẽ tìm hiểu thêm về tập hợp quy trình xác thực ở bên dưới.
Chuẩn bị dữ liệu dưới dạng tensor
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Ở đây, chúng ta tạo 2 tập dữ liệu: tập huấn luyện mà chúng ta sẽ huấn luyện mô hình và tập xác thực mà chúng ta sẽ kiểm thử mô hình vào cuối mỗi thời gian bắt đầu của hệ thống. Tuy nhiên, dữ liệu trong tập xác thực sẽ không bao giờ được hiển thị cho mô hình trong quá trình huấn luyện.
Lớp dữ liệu mà chúng tôi cung cấp giúp bạn dễ dàng lấy tensor từ dữ liệu hình ảnh. Tuy nhiên, chúng ta vẫn tạo lại hình dạng tensor thành hình dạng mà mô hình mong đợi, [num_examples, image_width, image_height, channels], trước khi có thể cấp dữ liệu cho mô hình. Đối với mỗi tập dữ liệu, chúng ta có cả dữ liệu đầu vào (X) và nhãn (Y).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Chúng ta gọi model.fit để bắt đầu vòng lặp huấn luyện. Chúng ta cũng chuyển thuộc tính verificationData để cho biết mô hình nên sử dụng dữ liệu nào để tự kiểm thử sau mỗi khoảng thời gian bắt đầu của hệ thống (nhưng không dùng để huấn luyện).
Nếu chúng ta xử lý tốt dữ liệu huấn luyện nhưng không xử lý tốt dữ liệu xác thực, thì có nghĩa là mô hình đó nhiều khả năng sẽ phù hợp với dữ liệu huấn luyện và sẽ không tổng quát hoá hiệu quả cho dữ liệu đầu vào chưa từng thấy trước đây.
7. Đánh giá mô hình của chúng tôi
Độ chính xác xác thực cung cấp số liệu ước tính chính xác về mức độ hiệu quả của mô hình của chúng tôi đối với dữ liệu mà mô hình đó chưa từng thấy trước đây (miễn là dữ liệu đó giống với tập hợp xác thực theo một cách nào đó). Tuy nhiên, chúng ta nên xem bảng phân tích chi tiết hơn về hiệu suất của các lớp.
Có một vài phương pháp trong tfjs-vis có thể giúp bạn thực hiện việc này.
Thêm mã sau vào cuối tệp script.js của bạn
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Mã này có tác dụng gì?
- Tạo thông tin dự đoán.
- Tính toán các chỉ số về độ chính xác.
- Hiện các chỉ số
Hãy xem xét từng bước kỹ hơn.
Đưa ra dự đoán
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Trước tiên, chúng ta cần đưa ra một vài dự đoán. Ở đây chúng ta sẽ chụp 500 hình ảnh và dự đoán chữ số nào trong đó (bạn có thể tăng số này sau để thử nghiệm trên một tập hợp hình ảnh lớn hơn).
Đáng chú ý là hàm argmax là hàm cung cấp cho chúng ta chỉ mục của lớp có xác suất cao nhất. Hãy nhớ rằng mô hình sẽ xuất ra một xác suất cho mỗi lớp. Ở đây, chúng tôi tìm ra xác suất cao nhất và chỉ định xác suất đó làm thông tin dự đoán.
Bạn cũng có thể nhận thấy rằng chúng tôi có thể đưa ra dự đoán cho tất cả 500 ví dụ cùng một lúc. Đây là khả năng vectơ hoá mà TensorFlow.js mang lại.
Hiển thị độ chính xác theo lớp
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Với một bộ các dự đoán và nhãn, chúng ta có thể tính toán độ chính xác cho từng lớp.
Hiển thị ma trận nhầm lẫn
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Ma trận nhầm lẫn cũng tương tự như độ chính xác theo từng lớp nhưng chia nhỏ hơn để cho thấy các mẫu phân loại sai. Hàm này cho phép bạn xem liệu mô hình có bị nhầm lẫn về bất kỳ cặp lớp cụ thể nào hay không.
Hiển thị đánh giá
Thêm mã sau vào cuối hàm chạy của bạn để hiển thị đánh giá.
await showAccuracy(model, data);
await showConfusion(model, data);
Bạn sẽ thấy một màn hình giống như sau.
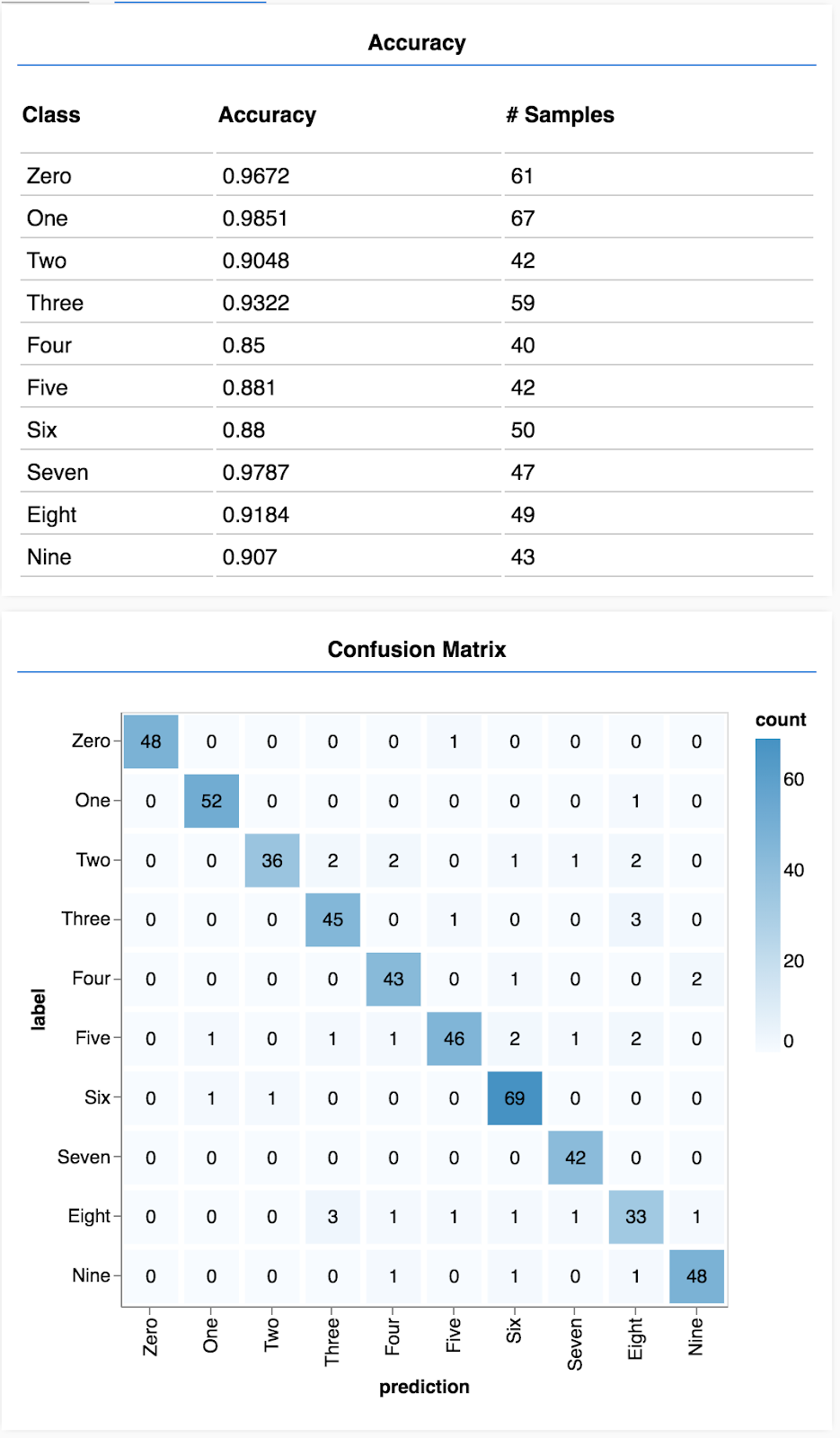
Xin chúc mừng! Bạn vừa huấn luyện một mạng nơron tích chập!
8. Những điểm chính cần nhớ
Việc dự đoán các danh mục cho dữ liệu đầu vào được gọi là tác vụ phân loại.
Nhiệm vụ phân loại yêu cầu trình bày dữ liệu thích hợp cho nhãn
- Các cách trình bày nhãn phổ biến bao gồm mã hoá một lần cho các danh mục
Chuẩn bị dữ liệu của bạn:
- Bạn nên giữ lại một số dữ liệu mà mô hình không bao giờ nhìn thấy trong quá trình huấn luyện để bạn có thể dùng để đánh giá mô hình. Đây được gọi là nhóm xác thực.
Tạo và chạy mô hình của bạn:
- Mô hình tích chập đã được chứng minh là hoạt động tốt trong các tác vụ hình ảnh.
- Bài toán phân loại thường sử dụng entropy chéo phân loại cho các hàm mất mát của chúng.
- Theo dõi quá trình huấn luyện để xem liệu mức tổn thất có giảm và độ chính xác có tăng lên hay không.
Đánh giá mô hình
- Quyết định một số cách đánh giá mô hình của bạn sau khi mô hình được huấn luyện để xem hiệu suất của mô hình đối với vấn đề ban đầu mà bạn muốn giải quyết.
- Ma trận về độ chính xác và ma trận nhầm lẫn trên mỗi lớp có thể cung cấp cho bạn thông tin chi tiết hơn về hiệu suất của mô hình thay vì chỉ độ chính xác tổng thể.