
Neste tutorial, criaremos um modelo TensorFlow.js para reconhecer dígitos de escrita à mão com uma rede neural convolucional. Primeiro, vamos treinar o classificador permitindo que ele "olhe" milhares de imagens de dígitos escritos à mão e o rótulo deles. Em seguida, avaliaremos a precisão do classificador usando dados de teste que o modelo nunca viu.
Essa tarefa é considerada uma tarefa de classificação, já que treinamos o modelo para atribuir uma categoria (o dígito que aparece na imagem) à imagem de entrada. Vamos treinar o modelo mostrando muitos exemplos de entradas junto com o resultado correto. Isso é chamado de aprendizado supervisionado.
O que você criará
Você criará uma página da Web que usa o TensorFlow.js para treinar um modelo no navegador. Dada uma imagem em preto e branco de um tamanho específico, ele classificará o dígito exibido na imagem. As etapas envolvidas são:
- Carregar os dados.
- Definir a arquitetura do modelo.
- Treinar o modelo e monitorar o desempenho dele durante o treinamento.
- Avaliar o modelo treinado fazendo algumas previsões.
O que você aprenderá
- A sintaxe do TensorFlow.js para criar modelos convolucionais usando a API Layers do TensorFlow.
- Como formular tarefas de classificação no TensorFlow.js
- Como monitorar o treinamento no navegador usando a biblioteca tfjs-vis.
Pré-requisitos
- Uma versão recente do Chrome ou outro navegador moderno compatível com módulos ES6
- Um editor de texto executado localmente na sua máquina ou na Web por meio de algo como Codepen ou Glitch.
- Conhecimento sobre HTML, CSS, JavaScript e Chrome DevTools (ou as DevTools do seu navegador preferido)
- Conhecimento conceitual de alto nível sobre redes neurais. Se você precisar de uma introdução ou revisão, assista a este vídeo da 3blue1brown ou este vídeo sobre aprendizado profundo em JavaScript por Ashi Krishnan (links em inglês).
Você também precisa ter familiaridade com o material do nosso primeiro tutorial de treinamento.
Criar uma página HTML e incluir o JavaScript
 Copie o código a seguir para um arquivo html chamado
Copie o código a seguir para um arquivo html chamado
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
Criar os arquivos JavaScript para os dados e o código
- Na mesma pasta do arquivo HTML acima, crie um arquivo chamado data.js e copie o conteúdo deste link para esse arquivo.
- Na mesma pasta da primeira etapa, crie um arquivo chamado script.js e coloque o código a seguir nele.
console.log('Hello TensorFlow');
Testar
Agora que você criou os arquivos HTML e JavaScript, teste-os. Abra o arquivo index.html no navegador e abra o console do DevTools.
Se tudo estiver funcionando, serão criadas duas variáveis globais. tf é uma referência à biblioteca do TensorFlow.js, tfvis é uma referência à biblioteca tfjs-vis.
Se você vir uma mensagem que diz Hello TensorFlow*,* poderá avançar para a próxima etapa.
Neste tutorial, você treinará um modelo para aprender a reconhecer dígitos em imagens como as mostradas abaixo. Elas são imagens em escala de cinza de 28 x 28 px de um conjunto de dados chamado MNIST.
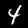

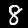
Fornecemos o código para carregar essas imagens de um arquivo sprite especial (aproximadamente 10 MB) que criamos para você para que possamos nos concentrar no treinamento.
Fique à vontade para estudar o arquivo data.js e entender como os dados são carregados. Após concluir este tutorial, crie sua própria abordagem para carregar os dados.
O código fornecido contém uma classe MnistData que tem dois métodos públicos:
nextTrainBatch(batchSize): retorna um lote aleatório de imagens e os rótulos correspondentes do conjunto de treinamento.nextTestBatch(batchSize): retorna um lote de imagens e os rótulos correspondentes do conjunto de teste.
A classe MnistData também realiza as etapas importantes de embaralhamento e normalização dos dados.
Há um total de 65.000 imagens. Usaremos até 55.000 imagens para treinar o modelo, guardando 10.000 imagens que podem ser usadas para testar o desempenho do modelo assim que ele for concluído. E faremos tudo isso no navegador.
Vamos carregar os dados e testar se eles foram carregados corretamente.
Adicione o seguinte código ao seu arquivo script.js.
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
Atualize a página e, após alguns segundos, você verá um painel à esquerda com uma série de imagens.

Os dados de entrada são assim.
Nosso objetivo é treinar um modelo que use uma imagem e aprenda a prever uma pontuação para cada uma das 10 classes possíveis às quais essa imagem pode pertencer (os dígitos de 0 a 9).
Cada imagem tem 28 pixels de largura, 28 pixels de altura e tem um canal de cor, já que é uma imagem em escala de cinza. Portanto, o formato de cada imagem é [28, 28, 1].
Lembre-se de que fazemos um mapeamento um para dez, assim como o formato de cada exemplo de entrada, porque ele é importante para a próxima seção.
Nesta seção, criaremos um código para descrever a arquitetura do modelo. A arquitetura do modelo é uma maneira sofisticada de dizer "quais funções o modelo executará quando estiver em execução" ou "qual algoritmo nosso modelo usará para calcular as respostas".
Em machine learning, definimos uma arquitetura (ou algoritmo) e deixamos o processo de treinamento aprender os parâmetros desse algoritmo.
Adicione a função a seguir a
script.js para definir a arquitetura do modelo
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Vamos analisar isso com mais detalhes.
Convoluções
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
Estamos usando um modelo sequencial.
Estamos usando uma camada conv2d em vez de uma camada densa. Não podemos falar todos os detalhes de como as convoluções funcionam, mas veja alguns recursos que explicam a operação subjacente:
Vamos detalhar cada argumento no objeto de configuração para conv2d:
inputShape. O formato dos dados que fluem para a primeira camada do modelo. Neste caso, os exemplos do MNIST são imagens em preto e branco de 28 x 28 pixels. O formato canônico para dados de imagem é[row, column, depth]. Então, vamos configurar aqui um formato de[28, 28, 1]. 28 linhas e colunas para o número de pixels em cada dimensão e uma profundidade de 1, porque nossas imagens têm somente um canal de cor. Não especificamos um tamanho de lote no formato de entrada. As camadas são projetadas para serem independentes de tamanho de lote de modo que, durante a inferência, você possa transmitir um tensor com qualquer tamanho de lote.kernelSize. O tamanho das janelas deslizantes do filtro convolucional a serem aplicadas aos dados de entrada. Aqui, definimoskernelSizecomo5, que especifica uma janela convolucional quadrada de 5 x 5.filters. O número de janelas de filtro com o tamanhokernelSizea serem aplicadas aos dados de entrada. Aqui, aplicaremos oito filtros aos dados.strides. O "tamanho da etapa" da janela deslizante, ou seja, quantos pixels o filtro mudará sempre que ele passar sobre a imagem. Aqui, especificamos os passos de 1. Isso significa que o filtro será movido sobre a imagem em etapas de 1 pixel.activation. A função de ativação a ser aplicada aos dados após a realização da convolução. Nesse caso, estamos aplicando uma função de Related Linear Unit (ReLU), que é uma função de ativação muito comum em modelos de ML.kernelInitializer. O método a ser usado para inicializar aleatoriamente os pesos do modelo, o que é muito importante para o treinamento dinâmico. Não entraremos em detalhes sobre a inicialização aqui, masVarianceScaling(usado aqui) é uma boa opção de inicializador.
Como nivelar nossa representação de dados
model.add(tf.layers.flatten());
As imagens são dados de alta dimensão, e as operações de convolução tendem a aumentar o tamanho dos dados enviados. Antes de transmiti-los para a camada de classificação final, precisamos nivelar os dados em uma única matriz longa. As camadas densas (que usamos como camada final) levam apenas tensor1d s. Portanto, essa etapa é comum em muitas tarefas de classificação.
Calcular a distribuição de probabilidade final
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
Usaremos uma camada densa com uma ativação softmax para calcular distribuições de probabilidade nas 10 classes possíveis. A classe com a maior pontuação será o dígito previsto.
Escolher um otimizador e uma função de perda
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
Compilamos o modelo que especifica um otimizador, uma função de perda e métricas que queremos acompanhar.
Em contraste com o primeiro tutorial, usamos categoricalCrossentropy como função de perda. Como o nome indica, ela é usada quando o resultado do modelo é uma distribuição de probabilidade. categoricalCrossentropy mede o erro entre a distribuição de probabilidade gerada pela última camada do nosso modelo e a distribuição de probabilidade fornecida pelo rótulo verdadeiro.
Por exemplo, se nosso dígito realmente representar um 7, podemos ter os seguintes resultados
Índice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Rótulo verdadeiro | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Previsão | 0,1 | 0,01 | 0,01 | 0,01 | 0,20 | 0,01 | 0,01 | 0,60 | 0,03 | 0,02 |
A entropia cruzada categórica produzirá um número único que indica a semelhança do vetor de previsão com o vetor real do rótulo.
A representação de dados usada aqui para os rótulos é chamada de codificação one-hot e é comum em problemas de classificação. Cada classe tem uma probabilidade associada a ela para cada exemplo. Quando sabemos exatamente o que deveria ser, podemos definir essa probabilidade como 1 e as outras como 0. Consulte esta página para mais informações sobre a codificação one-hot.
A outra métrica que monitoraremos é accuracy, que para um problema de classificação é a porcentagem de previsões corretas entre todas as previsões.
Copie a função a seguir para o arquivo script.js.
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Em seguida, adicione o seguinte código à sua
função run.
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
Atualize a página e, após alguns segundos, você verá alguns gráficos que informam o progresso do treinamento.
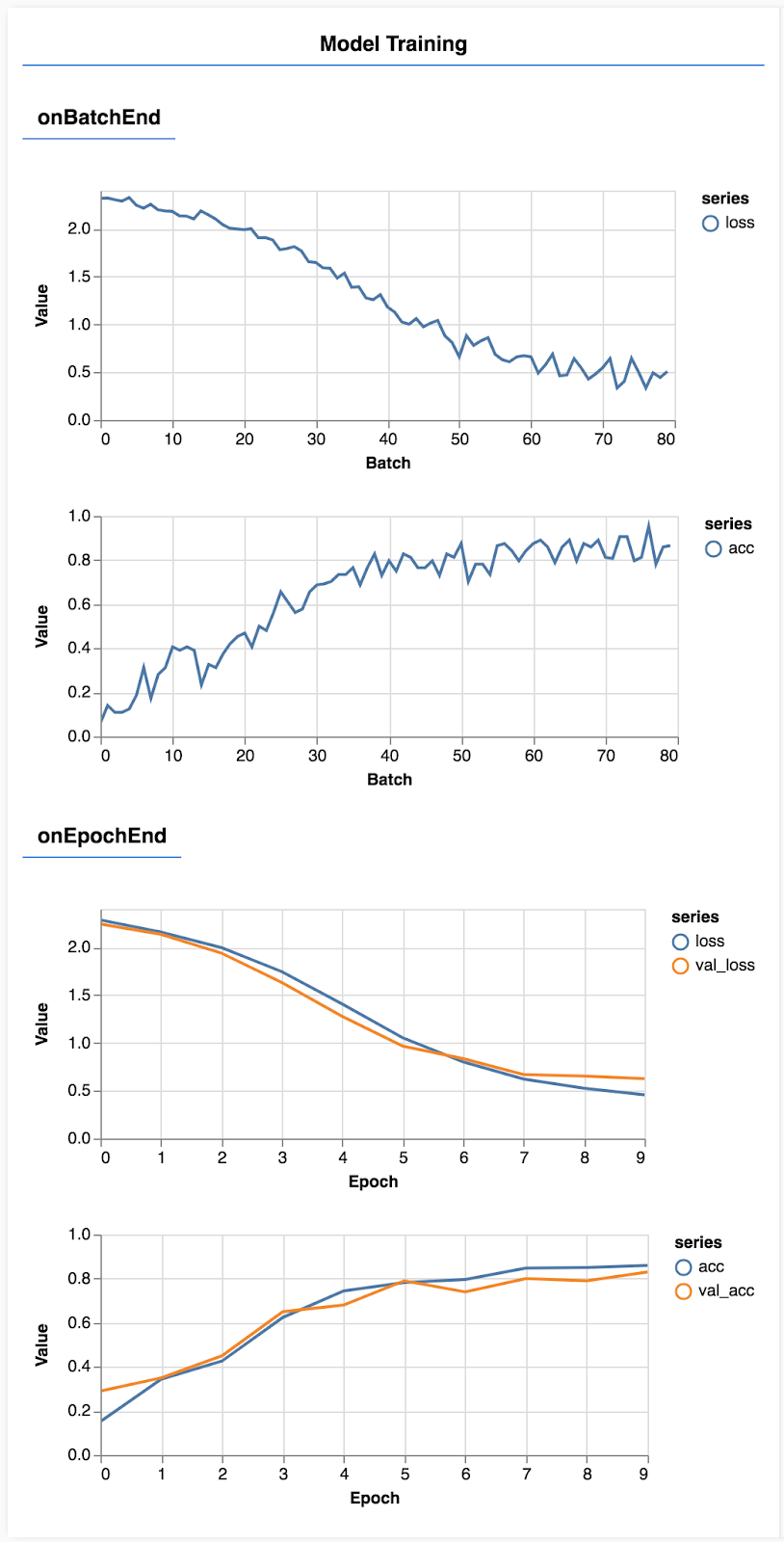
Vamos ver isso com mais detalhes.
Monitorar as métricas
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
Aqui, decidimos quais métricas serão monitoradas. Vamos monitorar a perda e a precisão no conjunto de treinamento, bem como a perda e a precisão no conjunto de validação (val_loss e val_acc respectivamente). Falaremos mais sobre o conjunto de validação abaixo.
Preparar dados como tensores
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
Aqui, temos dois conjuntos de dados: um conjunto de treinamento em que treinaremos o modelo e um conjunto de validação em que testaremos o modelo ao final de cada período. No entanto, os dados no conjunto de validação nunca são mostrados ao modelo durante o treinamento.
Com a classe de dados fornecida, é mais fácil conseguir tensores dos dados de imagem. No entanto, ainda estamos remodelando os tensores para o formato esperado pelo modelo [num_examples, image_width, image_height, channels] antes de enviá-los ao modelo. Para cada conjunto de dados, temos as entradas (os X) e os rótulos (os Ys).
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
Chamamos model.fit para iniciar o loop de treinamento. Além disso, transmitimos uma propriedade validationData para indicar quais dados o modelo deve usar para realizar testes após cada período (mas não para usar no treinamento).
Se nosso desempenho for satisfatório com os dados de treinamento, mas não com os dados de validação, o modelo provavelmente está com overfitting para os dados de treinamento e não generaliza bem as entradas que não foram vistas anteriormente.
A precisão da validação é uma boa estimativa do desempenho do modelo em dados que não foram vistos antes, desde que os dados sejam parecidos com o conjunto de validação de alguma maneira. No entanto, queremos um detalhamento maior do desempenho nas diferentes classes.
Há alguns métodos no tfjs-vis que podem ajudar você com isso.
Adicione o seguinte código ao final do seu arquivo script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
O que o código está fazendo?
- Faz uma previsão.
- Calcula as métricas de precisão.
- Mostra as métricas
Vamos dar uma olhada em cada etapa.
Fazer previsões
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
Primeiro, precisamos fazer algumas previsões. Aqui, vamos selecionar 500 imagens e prever qual dígito aparece nelas. Você pode aumentar esse número mais tarde para testar em um conjunto maior de imagens.
A função argmax é a que nos fornece o índice da classe de probabilidade mais alta. Lembre-se de que o modelo gera uma probabilidade para cada classe. Aqui descobrimos a maior probabilidade e a usamos como previsão.
Você também notará que podemos fazer previsões para todos os 500 exemplos de uma só vez. Esse é o poder de vetorização que o TensorFlow.js fornece.
Mostrar precisão por classe
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
Com um conjunto de previsões e rótulos, podemos calcular a precisão de cada classe.
Mostrar uma matriz de confusão
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
Uma matriz de confusão é semelhante à precisão da classe, mas a detalha mais para mostrar padrões de classificação incorreta. Isso permite ver se o modelo está confuso sobre pares de classes específicos.
Exibir a avaliação
Adicione o seguinte código à parte inferior da função de execução para exibir a avaliação.
await showAccuracy(model, data);
await showConfusion(model, data);
Você verá uma tela parecida com a seguinte.
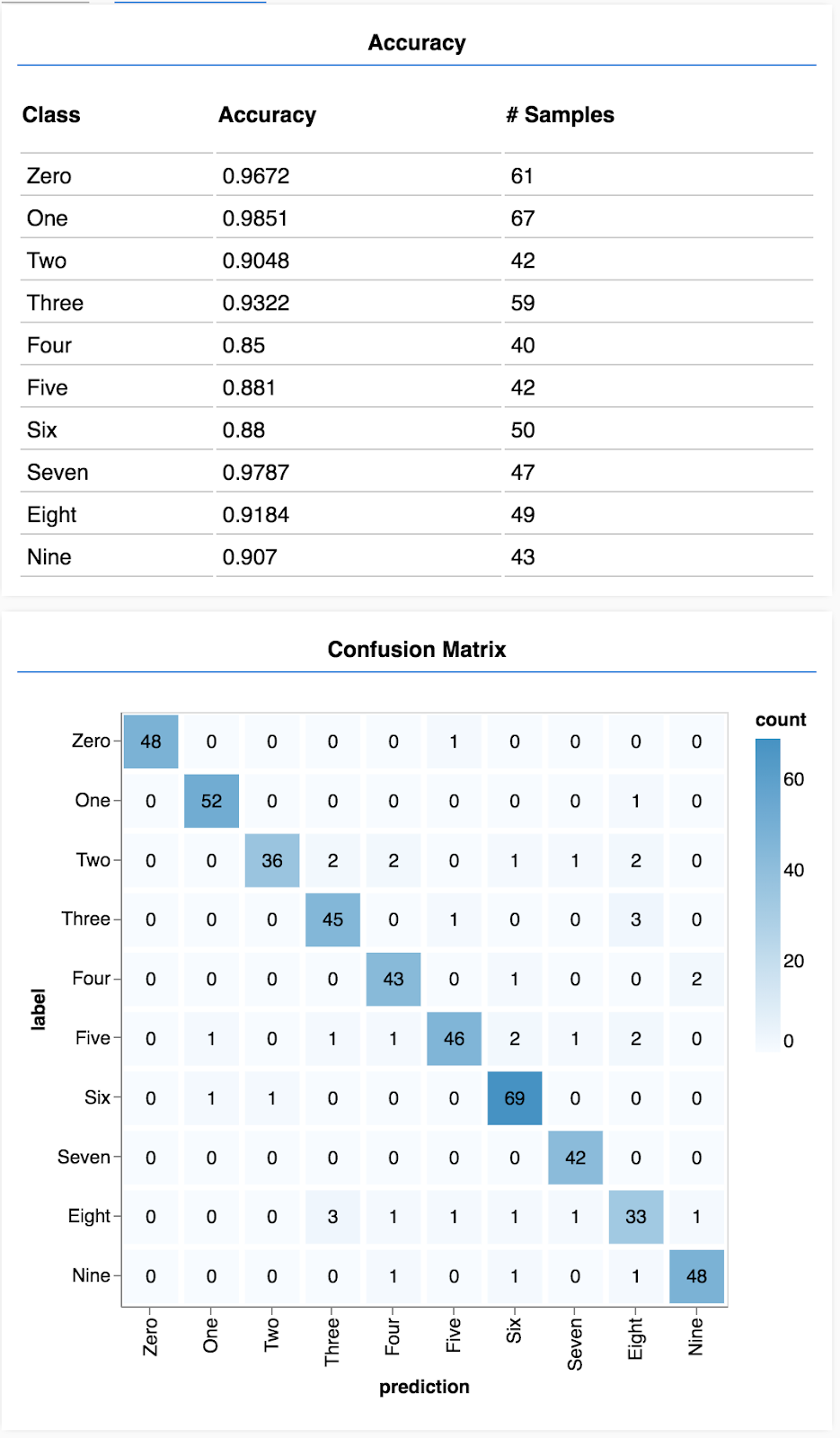
Parabéns! Você acabou de treinar uma rede neural convolucional.
A previsão de categorias para dados de entrada é chamada de tarefa de classificação.
As tarefas de classificação exigem uma representação de dados apropriada para os rótulos.
- Representações comuns de rótulos incluem codificação one-hot de categorias
Prepare os dados:
- É útil separar alguns dados que o modelo nunca verá durante o treinamento para serem usados na avaliação do modelo. Isso é chamado de conjunto de validação.
Crie e execute o modelo:
- Os modelos convolucionais tiveram um bom desempenho com tarefas de imagem.
- Os problemas de classificação geralmente usam entropia cruzada categórica para as funções de perda.
- Monitore o treinamento para ver se a perda está diminuindo e a precisão está aumentando.
Avalie o modelo
- Escolha uma maneira de avaliar o modelo após o treinamento para ver o desempenho dele no problema inicial que você quer resolver.
- A precisão por classe e as matrizes de confusão podem oferecer uma visão mais refinada do desempenho do modelo do que apenas a precisão geral.