
1. Antes de comenzar
El aprendizaje automático es la palabra de moda en la actualidad. Sus aplicaciones parecen no tener límites, y está preparada para llegar a casi todas las industrias en el futuro cercano. Si trabajas como ingeniero o diseñador, frontend o backend y conoces JavaScript, este codelab se redactó para ayudarte a comenzar a agregar el aprendizaje automático a tus habilidades.
Requisitos previos
Este codelab se redactó para ingenieros experimentados que ya están familiarizados con JavaScript.
Qué compilarás
En este codelab,
- Crea una página web que use el aprendizaje automático directamente en el navegador web a través de TensorFlow.js para clasificar y detectar objetos comunes (sí, incluidos más de uno a la vez) de una transmisión de cámara web en vivo.
- Potencia tu cámara web normal para identificar objetos y obtener las coordenadas del cuadro delimitador de cada objeto que encuentre.
- Resalta el objeto encontrado en la transmisión de video por Internet, como se muestra a continuación:
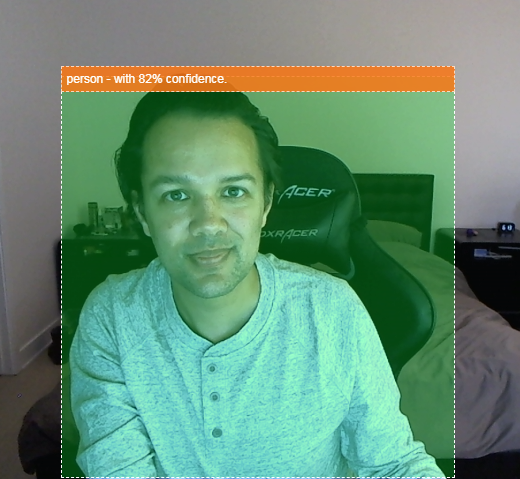
Imagina poder detectar si una persona estuvo en un video y contar cuántas personas estaban presentes en un momento dado para estimar qué tan concurrida estuvo una zona determinada durante el día o enviarte una alerta cuando se detecte a tu perro en una habitación de tu casa mientras estás fuera, en la que quizás no debería estar. Si pudieras hacerlo, estabas bien encaminado para crear tu propia versión de una cámara Google Nest que podría alertarte cuando detecte a un intruso (de cualquier tipo) con tu propio hardware personalizado. Muy bien. ¿Es difícil de hacer? No. Vamos a hackear...
Qué aprenderás
- Cómo cargar un modelo de TensorFlow.js previamente entrenado
- Cómo recopilar datos de una transmisión con una cámara web en vivo y dibujarlos en el lienzo
- Cómo clasificar un marco de imagen a fin de encontrar los cuadros delimitadores de cualquier objeto que el modelo se entrenó para reconocer.
- Cómo usar los datos transmitidos desde el modelo para destacar objetos encontrados.
Este codelab se enfoca en cómo comenzar a usar modelos previamente entrenados de TensorFlow.js. Los conceptos y los bloques de código que no son relevantes para TensorFlow.js y el aprendizaje automático no se explican y se proporcionan para que simplemente los copies y pegues.
2. ¿Qué es TensorFlow.js?

TensorFlow.js es una biblioteca de aprendizaje automático de código abierto que se puede ejecutar en cualquier lugar que pueda JavaScript. Se basa en la biblioteca original de TensorFlow escrita en Python y tiene como objetivo recrear esta experiencia de desarrollador y el conjunto de APIs para el ecosistema de JavaScript.
¿Dónde se puede utilizar?
Dada la portabilidad de JavaScript, ahora puedes escribir en 1 lenguaje y realizar el aprendizaje automático en todas las siguientes plataformas con facilidad:
- Del lado del cliente en el navegador web con JavaScript convencional
- En el servidor y también en dispositivos de IoT como Raspberry Pi con Node.js
- Apps de escritorio que usan Electron
- Apps nativas para dispositivos móviles con React Native
TensorFlow.js también admite múltiples backends dentro de cada uno de estos entornos (los entornos reales basados en hardware que puede ejecutar dentro de él, como la CPU o WebGL). Un "backend" en este contexto no significa un entorno del servidor: el backend para la ejecución podría ser del cliente en WebGL, por ejemplo, para garantizar la compatibilidad y también mantener el funcionamiento rápido. En la actualidad, TensorFlow.js admite lo siguiente:
- Ejecución de WebGL en la tarjeta gráfica del dispositivo (GPU): Es la forma más rápida de ejecutar modelos más grandes (más de 3 MB de tamaño) con aceleración de GPU.
- Ejecución de Web Assembly (WASM) en la CPU: Para mejorar el rendimiento de la CPU en todos los dispositivos, incluidos, por ejemplo, los teléfonos celulares de generaciones anteriores. Esto es más adecuado para modelos más pequeños (menos de 3 MB de tamaño) que pueden ejecutarse más rápido en la CPU con WASM que con WebGL debido a la sobrecarga que implica subir contenido a un procesador de gráficos.
- Ejecución de CPU: El resguardo no debe estar disponible ninguno de los otros entornos. Esta es la más lenta de las tres, pero siempre está ahí para ti.
Nota: Puedes optar por forzar uno de estos backends si sabes en qué dispositivo lo ejecutarás o, si no lo especificas, puedes dejar que TensorFlow.js decida por ti.
Superpoderes del cliente
La ejecución de TensorFlow.js en el navegador web de la máquina cliente puede generar varios beneficios que vale la pena considerar.
Privacidad
Puedes entrenar y clasificar datos en la máquina cliente sin tener que enviarlos a un servidor web de terceros. En algunas ocasiones, esto puede ser un requisito para cumplir con las leyes locales, como el GDPR, o cuando se procesan datos que el usuario quiere conservar en su máquina y no se envían a un tercero.
Velocidad
Como no tienes que enviar datos a un servidor remoto, la inferencia (el acto de clasificar los datos) puede ser más rápida. Aún mejor, tienes acceso directo a los sensores del dispositivo, como la cámara, el micrófono, el GPS, el acelerómetro y otros, si el usuario te otorga el acceso.
Alcance y escala
Con un solo clic, cualquier persona en el mundo puede hacer clic en el vínculo que le envías, abrir la página web en su navegador y usar lo que has hecho. No se necesita una compleja configuración de Linux en el servidor con controladores CUDA y mucho más solo para usar el sistema de aprendizaje automático.
Costo
Sin servidores significa que lo único que debes pagar es una CDN para alojar tus archivos HTML, CSS, JS y de modelo. El costo de una CDN es mucho más económico que mantener un servidor (posiblemente con una tarjeta gráfica adjunta) en funcionamiento las 24 horas, todos los días.
Funciones del servidor
Aprovechar la implementación de Node.js de TensorFlow.js habilita las siguientes funciones.
Compatibilidad total con CUDA
En el lado del servidor, para acelerar la tarjeta gráfica, debes instalar los controladores CUDA de NVIDIA para permitir que TensorFlow funcione con la tarjeta gráfica (a diferencia del navegador que usa WebGL, no es necesario instalarlo). Sin embargo, gracias a la total compatibilidad con CUDA, puedes aprovechar al máximo las capacidades de nivel inferior de la tarjeta gráfica, lo que agiliza los tiempos de inferencia y entrenamiento. El rendimiento está a la par con la implementación de TensorFlow en Python, ya que ambas comparten el mismo backend de C++.
Tamaño del modelo
Para modelos de vanguardia de la investigación, es posible que se trabaje con modelos muy grandes, quizás de gigabytes. Actualmente, estos modelos no se pueden ejecutar en el navegador web debido a las limitaciones del uso de memoria por pestaña del navegador. Para ejecutar estos modelos más grandes, puedes usar Node.js en tu propio servidor con las especificaciones de hardware que necesitas para ejecutar un modelo de este tipo de manera eficiente.
IoT
Node.js es compatible con computadoras de placa única populares como Raspberry Pi, lo que, a su vez, significa que también puedes ejecutar modelos de TensorFlow.js en esos dispositivos.
Velocidad
Node.js está escrito en JavaScript, lo que significa que se beneficia de una compilación inmediata. Esto significa que, a menudo, puedes ver mejoras en el rendimiento cuando usas Node.js, ya que se optimizará en el entorno de ejecución, especialmente para cualquier procesamiento previo que realices. Un excelente ejemplo de esto se puede observar en este caso de éxito, en el que se muestra cómo Hugging Face usó Node.js para duplicar el rendimiento de su modelo de procesamiento de lenguaje natural.
Ahora que comprendes los conceptos básicos de TensorFlow.js, dónde se puede ejecutar y algunos de sus beneficios, comencemos a hacer cosas útiles con él.
3. Modelos previamente entrenados
TensorFlow.js proporciona una variedad de modelos de aprendizaje automático (AA) previamente entrenados. Estos modelos fueron entrenados por el equipo de TensorFlow.js y los incluyeron en una clase fácil de usar. Además, son una excelente manera de dar los primeros pasos en el aprendizaje automático. En lugar de crear y entrenar un modelo para resolver tu problema, puedes importar un modelo previamente entrenado como punto de partida.
Puedes encontrar una lista creciente de modelos previamente entrenados fáciles de usar en la página Modelos para JavaScript de TensorFlow. También hay otros lugares donde puedes obtener modelos de TensorFlow convertidos que funcionan en TensorFlow.js, como TensorFlow Hub.
¿Por qué se recomienda usar un modelo previamente entrenado?
Comenzar con un modelo popular previamente entrenado si se ajusta al caso de uso deseado tiene una serie de beneficios, como los siguientes:
- No necesitas recopilar datos de entrenamiento por tu cuenta. Preparar los datos en el formato correcto y etiquetarlos para que un sistema de aprendizaje automático pueda usarlos para aprender puede llevar mucho tiempo y ser costoso.
- La capacidad de crear rápidamente un prototipo de una idea con menores costos y tiempo.
No tiene sentido "reinventar la rueda" cuando un modelo previamente entrenado puede ser suficiente para hacer lo que necesitas, lo que te permite concentrarte en usar el conocimiento que proporciona el modelo para implementar tus ideas creativas. - Uso de investigaciones de vanguardia. Los modelos previamente entrenados suelen basarse en investigaciones populares, lo que te permite exponer esos modelos a la vez que comprendes su rendimiento en el mundo real.
- Facilidad de uso y documentación extensa. Debido a la popularidad de estos modelos,
- Funciones de aprendizaje por transferencia. Algunos modelos previamente entrenados ofrecen capacidades de aprendizaje por transferencia, que es básicamente la práctica de transferir la información que se aprende de una tarea de aprendizaje automático a otro ejemplo similar. Por ejemplo, un modelo que originalmente se entrenó para reconocer gatos podría volver a entrenarse para que reconozca perros, si le diste datos de entrenamiento nuevos. Esto será más rápido, ya que no empezarás con un lienzo en blanco. El modelo puede usar lo que ya aprendió para reconocer gatos para luego reconocer algo nuevo. Después de todo, los perros también tienen ojos y orejas, por lo que, si ya sabe cómo encontrar esos atributos, estamos a medio camino. Volver a entrenar el modelo con tus propios datos de una manera mucho más rápida.
¿Qué es COCO-SSD?
COCO-SSD es el nombre de un modelo de AA de detección de objetos previamente entrenado que usarás durante este codelab, cuyo objetivo es identificar y localizar varios objetos en una sola imagen. En otras palabras, puede informarte el cuadro delimitador de los objetos que se entrenó para encontrar, a fin de brindarte la ubicación de esos objetos en cualquier imagen que le presentes. En la siguiente imagen, se muestra un ejemplo:

Si hubiera más de 1 perro en la imagen de arriba, se te proporcionarán las coordenadas de 2 cuadros delimitadores, que describen la ubicación de cada uno. COCO-SSD previamente entrenado para reconocer 90 objetos cotidianos comunes, como una persona, un auto, un gato, etc.
¿De dónde provino el nombre?
El nombre puede sonar extraño, pero se origina de 2 siglas:
- COCO: Se refiere a que se entrenó con el conjunto de datos COCO (objetos comunes en contexto), que está disponible de forma gratuita para que cualquiera lo descargue y use cuando entrene sus propios modelos. El conjunto de datos contiene más de 200,000 imágenes etiquetadas de las que se puede aprender.
- SSD (detección de una sola toma de MultiBox): Se refiere a parte de la arquitectura del modelo que se usó en la implementación del modelo. No es necesario que lo entiendas para el codelab, pero, si tienes curiosidad, puedes obtener más información sobre SSD aquí.
4. Prepárate
Requisitos
- Un navegador web moderno
- Conocimientos básicos de HTML, CSS, JavaScript y Herramientas para desarrolladores de Chrome (visualización del resultado de la consola)
Comencemos a programar
Se crearon plantillas plantillas para comenzar en Glitch.com o Codepen.io. Puedes clonar cualquiera de las plantillas como tu estado base para este codelab con solo un clic.
En Glitch, haz clic en el botón remix this para bifurcarlo y crear un nuevo conjunto de archivos que puedas editar.
Como alternativa, en CodePen, haz clic en bifurcar en la esquina inferior derecha de la pantalla.
Este esqueleto simple te proporciona los siguientes archivos:
- Página HTML (index.html)
- Hoja de estilo (style.css)
- Archivo para escribir el código JavaScript (script.js)
Para tu comodidad, hay una importación adicional en el archivo HTML de la biblioteca de TensorFlow.js. El aspecto resultante será el siguiente:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternativa: Usa tu editor web preferido o trabaja de manera local
Si quieres descargar el código y trabajar de forma local o en un editor en línea diferente, simplemente crea los 3 archivos nombrados anteriormente en el mismo directorio y copia y pega el código de nuestro código estándar de Glitch en cada uno de ellos.
5. Propaga el esqueleto de HTML
Todos los prototipos requieren un andamiaje básico de HTML. Usarás esto para renderizar el resultado del modelo de aprendizaje automático más adelante. Configúralo ahora:
- Un título para la página
- Algo de texto descriptivo
- Un botón para habilitar la cámara web
- Una etiqueta de video para procesar la transmisión de la cámara web
Para configurar estas funciones, abre index.html y pega el código existente con lo siguiente:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
Información sobre el código
Observa algunos puntos clave que agregaste:
- Agregaste una etiqueta
<h1>y algunas etiquetas<p>al encabezado, así como información sobre cómo usar la página. Aquí no hay nada especial.
También agregaste una etiqueta de sección que representa tu espacio de demostración:
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- Inicialmente, le asignarás a este
sectionuna clase de "invisible". Esto es para que puedas explicarle visualmente al usuario cuando el modelo está listo, y puedes hacer clic en el botón Habilitar cámara web sin problemas. - Agregaste el botón Habilitar cámara web, al que aplicarás diseño en tu CSS.
- También agregaste una etiqueta de video, a la que transmitirás la entrada de tu cámara web. Podrás configurar esto en tu código JavaScript en breve.
Si obtienes una vista previa del resultado ahora mismo, debería verse de la siguiente manera:

6. Agr. estilo
Valores predeterminados de los elementos
Primero, agregaremos estilos para los elementos HTML que acabamos de agregar para asegurarnos de que se rendericen correctamente:
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
A continuación, agrega algunas clases de CSS útiles para ayudar con varios estados diferentes de nuestra interfaz de usuario, como cuándo queremos ocultar el botón o hacer que el área de demostración parezca no estar disponible si el modelo aún no está listo.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
¡Genial! ¡Eso es todo lo que necesitas! Si reemplazaste correctamente tus estilos con los 2 fragmentos de código anteriores, la vista previa en vivo debería verse de la siguiente manera:

Observa que el texto del área de demostración y el botón no están disponibles, ya que el HTML, de forma predeterminada, tiene la clase "invisible". se aplicó. Usarás JavaScript para quitar esta clase una vez que el modelo esté listo para usarse.
7. Crea el esqueleto de JavaScript
Cómo hacer referencia a elementos clave del DOM
Primero, asegúrate de que puedas acceder a las partes clave de la página que deberás manipular o a las que podrás acceder más adelante en nuestro código:
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
Cómo comprobar la compatibilidad con la cámara web
Ahora puedes agregar algunas funciones asistivas para verificar si el navegador que estás usando admite el acceso a la transmisión de la cámara web a través de getUserMedia:
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
Recupera la transmisión de la cámara web
A continuación, copia y pega el siguiente código para completar el código de la función enableCam previamente vacía que definimos anteriormente:
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
Por último, agrega código temporal para probar si la cámara web funciona.
El siguiente código simulará que tu modelo está cargado y habilitará el botón de la cámara para que puedas hacer clic en él. Reemplazarás todo este código en el siguiente paso, así que prepárate para volver a borrarlo en unos instantes:
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
¡Genial! Si ejecutaste el código e hiciste clic en el botón tal como está actualmente, deberías ver algo como esto:

8. Uso del modelo de aprendizaje automático
Carga el modelo
Ya está todo listo para cargar el modelo COCO-SSD.
Cuando termine de inicializarse, habilita el área de demostración y el botón en tu página web (pega este código sobre el código temporal que agregaste al final del último paso):
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
Una vez que hayas agregado el código anterior y actualizado la visualización en vivo, notarás que, unos segundos después de que se cargue la página (según la velocidad de tu red), el botón para habilitar la cámara web aparecerá automáticamente cuando el modelo esté listo para usarse. Sin embargo, también pegaste la función predictWebcam. Ahora es el momento de definir esto completamente, ya que nuestro código no realizará ninguna acción en la actualidad.
Pasemos al siguiente paso.
Cómo clasificar un fotograma de la cámara web
Ejecuta el siguiente código para permitir que la app tome continuamente un fotograma de la transmisión de la cámara web cuando el navegador esté listo y lo pase al modelo para que lo clasifique.
Luego, el modelo analizará los resultados, dibujará una etiqueta <p> en las coordenadas que regresan y establecerá el texto en la etiqueta del objeto si supera un cierto nivel de confianza.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
La llamada realmente importante en este código nuevo es model.detect().
Todos los modelos prediseñados para TensorFlow.js tienen una función como esta (cuyo nombre puede cambiar de modelo a modelo, así que consulta la documentación para obtener detalles) que realiza la inferencia del aprendizaje automático.
La inferencia es simplemente el acto de recibir una entrada y ejecutarla a través del modelo de aprendizaje automático (básicamente muchas operaciones matemáticas) y, luego, proporcionar algunos resultados. Con los modelos prediseñados de TensorFlow.js, devolvemos nuestras predicciones en forma de objetos JSON, por lo que es fácil de usar.
Puedes encontrar los detalles completos de esta función de predicción en nuestra documentación de GitHub para el modelo COCO-SSD. Esta función realiza mucho trabajo pesado detrás de escena: puede aceptar cualquier "como" objeto como su parámetro, por ejemplo, una imagen, un video, un lienzo, etcétera. Usar modelos prediseñados puede ahorrarte mucho tiempo y esfuerzo, ya que no tendrás que escribir este código tú mismo y podrás trabajar de inmediato.
Cuando ejecutes este código, deberías obtener una imagen similar a la siguiente:
Por último, aquí te mostramos un ejemplo del código que detecta varios objetos al mismo tiempo:

¡Muy bien! Ahora te puedes imaginar lo simple que sería tomar algo así para crear un dispositivo como una Nest Cam usando un teléfono antiguo para alertarte cuando ve a tu perro en el sofá o a tu gato en el sofá. Si tienes problemas con el código, revisa mi versión de trabajo final aquí para ver si copiaste algo incorrecto.
9. Felicitaciones
Felicitaciones, diste tus primeros pasos para usar TensorFlow.js y el aprendizaje automático en un navegador web. Ahora debes tomar estos humildes comienzos y convertirlos en algo creativo. ¿Qué crearás?
Resumen
En este codelab, aprendimos a hacer lo siguiente:
- Conoce los beneficios de usar TensorFlow.js en lugar de otras formas de TensorFlow.
- Conoce las situaciones en las que puedes comenzar con un modelo de aprendizaje automático previamente entrenado.
- Creaste una página web totalmente funcional que puede clasificar objetos en tiempo real con tu cámara web. Incluye lo siguiente:
- Crear un esquema HTML para el contenido
- Cómo definir estilos para elementos y clases HTML
- Configurar el andamiaje de JavaScript para interactuar con el código HTML y detectar la presencia de una cámara web
- Carga un modelo de TensorFlow.js previamente entrenado
- Usar el modelo cargado para realizar clasificaciones continuas de la transmisión de la cámara web y dibujar un cuadro delimitador alrededor de los objetos de la imagen.
Próximos pasos
¡Comparte tus creaciones con nosotros! También puedes extender con facilidad lo que creaste para este codelab a otros casos de uso de creatividades. Te recomendamos que pienses de forma innovadora y sigas hackeando una vez que hayas terminado.
- Revisa todos los objetos que este modelo puede reconocer y piensa cómo podrías usar ese conocimiento para realizar una acción. ¿Qué ideas creativas se podrían implementar ahora extendiendo lo que hiciste hoy?
(Tal vez podrías agregar una capa simple del servidor para entregar una notificación a otro dispositivo cuando vea un objeto determinado de tu elección usando websockets. Esta sería una excelente manera de reciclar un smartphone viejo y darle un propósito nuevo. Las posibilidades son ilimitadas).
- Etiquétanos en las redes sociales con el hashtag #MadeWithTFJS para tener la oportunidad de que tu proyecto se destaque en nuestro blog de TensorFlow o, incluso, en futuros eventos de TensorFlow.
Más codelabs de TensorFlow.js para obtener más información
- Escribe una red neuronal desde cero en TensorFlow.js
- Reconocimiento de audio mediante aprendizaje por transferencia en TensorFlow.js
- Clasificación de imágenes personalizadas con aprendizaje por transferencia en TensorFlow.js