
1. 准备工作
机器学习是当今的流行词。它的应用似乎不受限制,而且几乎会在不久的将来接触到几乎所有行业。如果您是一名工程师或设计师,从事前端或后端工作,并且熟悉 JavaScript,那么此 Codelab 可以帮助您开始将机器学习添加到您的技能组合中。
前提条件
此 Codelab 是为已熟悉 JavaScript 的经验丰富的工程师编写的。
构建内容
在此 Codelab 中,您将:
- 创建一个网页,直接在网络浏览器中通过 TensorFlow.js 使用机器学习技术,对实时摄像头直播中的常见对象进行分类和检测(是的,包括一次多个对象)。
- 增强常规网络摄像头的识别能力,并获取它找到的每个对象的边界框坐标
- 突出显示在视频流中找到的对象,如下所示:
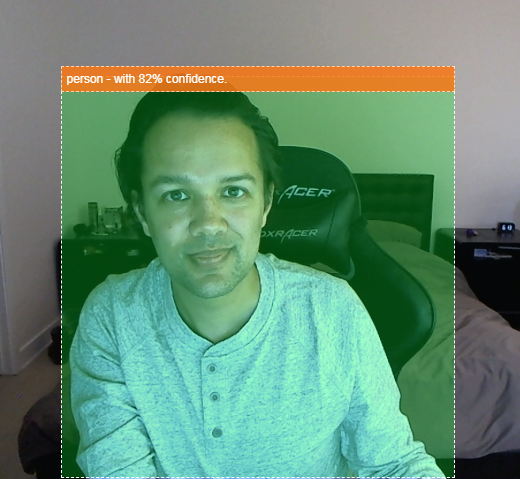
想象一下,如果能够检测视频是否有人出现在视频中,以便统计任意指定时间的参与者人数来估算一天当中特定区域的繁忙程度,或者当检测到狗在您家的某个房间内时发送提醒,而您可能不在该区域内。如果您能做到这一点,那您就完全可以打造自己的专属版本 Google Nest 摄像头了。它能够使用您自己的定制硬件,在检测到入侵者(任何类型的)入侵时向您发出提醒!这挺好看的。是否难以实现?不正确。开始入侵...
学习内容
- 如何加载预训练的 TensorFlow.js 模型。
- 如何从实时摄像头直播中获取数据并将其绘制到画布。
- 如何对图片帧进行分类,以查找模型经过训练可识别的任何对象的边界框。
- 如何使用从模型传回的数据突出显示找到的对象。
此 Codelab 将重点介绍如何开始使用 TensorFlow.js 预训练模型。本单元未解释与 TensorFlow.js 和机器学习无关的概念和代码块,提供这些内容只是供您复制和粘贴。
2. 什么是 TensorFlow.js?

TensorFlow.js 是一个开源机器学习库,可在任何 JavaScript 环境下运行。它基于以 Python 编写的原始 TensorFlow 库,旨在为 JavaScript 生态系统重新创建这种开发者体验和一组 API。
它的使用范围如何?
鉴于 JavaScript 的可移植性,您现在可以使用 1 种语言编写,并轻松地在以下所有平台上执行机器学习:
- 网络浏览器中的客户端(使用原始 JavaScript)
- 服务器端,甚至是 Raspberry Pi 等 IoT 设备,使用 Node.js
- 使用 Electron 的桌面应用
- 使用 React Native 的原生移动应用
TensorFlow.js 还支持在这些环境(例如,它可以在 CPU 或 WebGL 等实际基于硬件的环境)中执行多个后端。“后端”这里的环境并不意味着服务器端环境(例如,在 WebGL 中用于执行的后端可以是客户端),以便确保兼容性并保持快速运行。TensorFlow.js 目前支持:
- 在设备的显卡 (GPU) 上执行 WebGL - 这是通过 GPU 加速执行较大模型(大小超过 3MB)的最快方式。
- 在 CPU 上执行 Web Assembly (WASM) - 提高各种设备的 CPU 性能,包括老一代手机。这更适合较小的模型(小于 3MB),因为将内容上传到图形处理器的开销实际上比使用 WebGL 时在 CPU 上执行得更快。
- CPU 执行 - 如果其他环境均不可用,则备用环境。这是三个速度中速度最慢的,但是您可以一直保持下去。
注意:如果您知道要在哪种设备上执行,则可以选择强制使用其中一个后端;如果您不指定,也可以直接让 TensorFlow.js 为您决定。
客户端超能力
在客户端计算机的网络浏览器中运行 TensorFlow.js 可带来诸多好处,值得考虑。
隐私权
您可以在客户端计算机上训练和对数据进行分类,而无需将数据发送到第三方网络服务器。有时,您可能需要遵守当地法律(例如 GDPR),或者在处理用户可能希望保留在其计算机上而不发送给第三方的任何数据时。
速度
由于您不必将数据发送到远程服务器,因此推断(数据分类)可以更快完成。更棒的是,您还可以直接访问设备的传感器,例如摄像头、麦克风、GPS、加速度计等(如果用户授予您访问权限)。
覆盖面和规模
世界上的任何人都可以点击您发送的链接,在浏览器中打开网页,然后利用您的成果。无需使用 CUDA 驱动程序进行复杂的服务器端 Linux 设置,只需使用机器学习系统即可。
费用
没有服务器意味着您只需为托管 HTML、CSS、JS 和模型文件的 CDN 付费。CDN 的成本比保持服务器(可能连接了显卡)全天候运行更便宜。
服务器端功能
利用 TensorFlow.js 的 Node.js 实现可启用以下功能。
全面支持 CUDA
在服务器端,对于显卡加速,您必须安装 NVIDIA CUDA 驱动程序,以使 TensorFlow 能够与显卡搭配使用(这与使用 WebGL 的浏览器不同,无需安装)。但是,有了全面的 CUDA 支持,您可以充分利用显卡较低级别的功能,从而缩短训练和推理时间。性能与 Python TensorFlow 实现相当,因为它们共享同一个 C++ 后端。
模型大小
对于研究中的尖端模型,您使用的模型可能非常大,也可能高达 GB。由于每个浏览器标签页的内存用量限制,这些模型目前无法在网络浏览器中运行。要运行这些较大的模型,您可以在自己的服务器上使用 Node.js,并满足高效运行此类模型所需的硬件规格。
IOT
Raspberry Pi 等热门单板计算机支持 Node.js,这也意味着您也可以在此类设备上执行 TensorFlow.js 模型。
速度
Node.js 是使用 JavaScript 编写的,这意味着它受益于即时编译。这意味着,在使用 Node.js 时,您通常可能会看到性能提升,因为它将在运行时进行优化,尤其是对于您可能正在进行的任何预处理。此案例研究展示了 Hugging Face 如何使用 Node.js 将自然语言处理模型的性能提升至原来的 2 倍。
现在,您已了解 TensorFlow.js 的基础知识、其运行位置以及一些优势,下面我们开始使用 TensorFlow.js 做一些有用的事吧!
3. 预训练模型
TensorFlow.js 提供了各种预训练的机器学习 (ML) 模型。这些模型经过 TensorFlow.js 团队训练,封装在一个易于使用的类中,是迈出使用机器学习的第一步的好方法。您可以导入预训练模型作为起点,而不是通过构建和训练模型来解决问题。
您可以访问 Tensorflow.js JavaScript 模型页面,查看越来越多的简单易用的预训练模型。您还可以通过其他途径(包括 TensorFlow Hub)获取适用于 TensorFlow.js 的已转换 TensorFlow 模型。
为什么要使用预训练模型?
如果一个热门的预训练模型适合您所需的使用场景,那么从它入手有诸多好处,例如:
- 无需自行收集训练数据。以正确的格式准备数据并添加标签,以便机器学习系统可以用它来学习,可能非常耗时,成本高昂。
- 能够以更低的成本和时间快速为想法设计原型。
没有必要“白费力气”。 - 运用先进的研究成果。预训练模型通常基于热门研究,让您能够接触此类模型,同时了解其在现实世界中的表现。
- 易于使用和丰富的文档。因为这些模型非常受欢迎。
- 迁移学习 功能。一些预训练模型提供迁移学习功能,这本质上是将从一个机器学习任务学到的信息转移到另一个类似示例的做法。例如,如果您向模型提供新的训练数据,那么最初为了识别猫而训练的模型可以被重新训练为识别狗。这样速度更快,因为您不会从空白的画布开始。模型可以利用它已经学到的关于猫的识别信息来识别新事物 - 狗狗毕竟有眼睛和耳朵,所以如果它已经知道如何找到这些特征,那么我们就已经完成了一半。以更快的速度使用您自己的数据重新训练模型。
什么是 COCO-SSD?
COCO-SSD 是您将在此 Codelab 中使用的预训练对象检测机器学习模型的名称,该模型旨在定位和识别单个图片中的多个对象。换言之,它可以告诉您由训练过的对象组成的边界框,以便了解对象在您向其呈现的任何图片中的位置。下图显示了一个示例:

如果上图中有 1 个以上的狗,您将获得 2 个边界框的坐标,分别描述每个边界框的位置。COCO-SSD 已经过预训练,可识别 90 种常见的日常物体,例如人、汽车、猫等。
这个名字从何而来?
名称听起来可能很奇怪,但它源自 2 个首字母缩写词:
- COCO:指的是在 COCO(情境中的常见对象)数据集上进行训练的,COCO 数据集可供任何人在训练自己的模型时免费下载和使用。该数据集包含超过 20 万张已加标签的图片,可用于学习。
- SSD(单镜头 MultiBox 检测):是指模型实现中使用的模型架构的一部分。您无需在此 Codelab 中了解这一点,但如果您有兴趣,可以在此处详细了解 SSD。
4. 进行设置
所需条件
- 一款现代网络浏览器。
- 具备 HTML、CSS、JavaScript 和 Chrome 开发者工具的基础知识(查看控制台输出)。
开始编码
我们已为 Glitch.com 或 Codepen.io 创建了样板模板,以供您参考。您只需点击一下,即可将任一模板克隆为此 Codelab 的基础状态。
在 Glitch 上,点击 remix this 按钮,为它创建分支,然后创建一组可供编辑的新文件。
或者,在 Codepen 上,点击屏幕右下角的 fork。
这个非常简单的框架可为您提供以下文件:
- HTML 网页 (index.html)
- 样式表 (style.css)
- 用于编写 JavaScript 代码 (script.js) 的文件
为方便起见,我们在 HTML 文件中为 TensorFlow.js 库添加了一项导入。如下所示:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
替代方案:使用您偏好的网页编辑器或在本地处理文件
如果您想下载代码并在本地运行,或使用其他在线编辑器运行,只需在同一目录中创建上面命名的 3 个文件,然后将 Glitch 样板中的代码复制并粘贴到每个文件中即可。
5. 填充 HTML 框架
所有原型都需要一些基本的 HTML 基架。稍后您将使用它来渲染机器学习模型的输出。现在,我们来进行设置:
- 网页的标题
- 一些描述性文字
- 用于启用摄像头的按钮
- 用于呈现摄像头视频流的视频代码
要设置这些功能,请打开 index.html 并粘贴到现有代码及以下内容中:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
了解代码
请注意您添加的一些重要内容:
- 您针对标头添加了
<h1>标记和一些<p>标记,并提供了有关如何使用网页的一些信息。没什么特别的。
您还添加了一个代表演示空间的版块标记:
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- 最初,您将为此
section指定一个“不可见”类。这样,模型准备就绪后,您可以直观地向用户说明,并且你可以放心点击启用摄像头按钮。 - 您添加了启用摄像头按钮,将在 CSS 中设置此按钮的样式。
- 您还添加了一个视频标签,用于流式传输摄像头的输入信息。您很快会在 JavaScript 代码中完成这项设置。
如果您现在预览输出,它应如下所示:

6. 添加样式
元素默认值
首先,让我们为刚刚添加的 HTML 元素添加样式,以确保其正确呈现:
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
接下来,添加一些有用的 CSS 类,以帮助处理界面的各种不同状态,例如,当我们想要隐藏按钮时,或者当模型尚未准备就绪时使演示区域显示为不可用。
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
太棒了!这就是您所需的一切。如果您使用上述 2 段代码成功替换了样式,您的实时预览现在应如下所示:

请注意,演示区域文本和按钮不可用,因为 HTML 的默认类为“invisible”。该模型可供使用后,您将使用 JavaScript 移除此类。
7. 创建 JavaScript 框架
引用关键 DOM 元素
首先,确保您可以访问页面的关键部分,而这些关键部分需要稍后通过我们的代码进行处理或访问:
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
检查是否支持摄像头
现在,您可以添加一些辅助功能来检查您使用的浏览器是否支持通过 getUserMedia 访问摄像头直播:
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
获取摄像头直播
接下来,复制并粘贴以下代码,为我们在上面定义的先前空的 enableCam 函数填写代码:
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
最后,添加一些临时代码,以便测试摄像头是否正常工作。
以下代码将假装您的模型已加载并启用相机按钮,以便您点击该按钮。您将在下一步中替换所有此代码,因此请准备好立即再次删除:
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
太棒了!如果您运行代码并点击按钮(当前状态),则应该看到如下内容:

8. 机器学习模型用法
加载模型
现在,您可以加载 COCO-SSD 模型了。
当它完成初始化后,在网页上启用演示区域和按钮(将此代码粘贴到您在最后一步末尾添加的临时代码上):
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
添加上述代码并刷新实时视图后,您会发现,在页面加载几秒钟后(具体取决于您的网速),当模型可供使用时,启用摄像头按钮会自动显示。不过,您同时粘贴到了 predictWebcam 函数上。现在是时候完全定义一下了,因为我们的代码目前不会执行任何操作。
继续下一步!
对摄像头拍摄的帧进行分类
运行以下代码,让应用可以在浏览器就绪后持续从摄像头直播画面中抓取一帧画面,并将其传递给要分类的模型。
然后,模型将解析结果,在返回的坐标处绘制 <p> 标记,并将文本设置为对象的标签(如果置信度超过一定置信度)。
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
这个新代码中非常重要的调用是 model.detect()。
所有适用于 TensorFlow.js 的预制模型都具有一个实际执行机器学习推理的函数(其名称可能因模型而异,因此请查看文档了解详情)。
推断只是接受一些输入并将其用在机器学习模型中(基本上是大量的数学运算),然后提供一些结果。借助 TensorFlow.js 预制模型,我们以 JSON 对象的形式返回预测结果,因此易于使用。
如需了解此预测函数的完整详细信息,请参阅此处 COCO-SSD 模型的 GitHub 文档。此函数在后台完成许多繁重工作:它可以接受对象作为其参数,例如图片、视频、画布等。使用预制模型可以节省大量时间和精力,因为您无需自行编写此代码,并且可以“开箱即用”地运行。
运行此代码现在应生成如下所示的图片:
最后,下面是一个同时检测多个对象的代码示例:

棒极了!现在,您可以想象一下,如果这样操作,会多么简单地使用旧手机创建 Nest Cam 等设备,以便在沙发上看到您的狗或您的猫在沙发上时提醒您。如果代码存在问题,请点击此处查看我最终可正常工作的版本,看看您复制的内容是否有误。
9. 恭喜
恭喜,您已迈出在网络浏览器中使用 TensorFlow.js 和机器学习的第一步!现在,应该由您来发挥这些不起眼的开端,把它变成一些有创意的内容。你要制作什么?
回顾
在此 Codelab 中,我们完成了以下内容:
- 了解使用 TensorFlow.js 相较于其他 TensorFlow 形式的优势。
- 了解在哪些情况下您可能需要从预训练的机器学习模型入手。
- 创建一个功能齐全的网页,可以使用摄像头对对象进行实时分类,包括:
- 为内容创建 HTML 框架
- 为 HTML 元素和类定义样式
- 设置 JavaScript 基架,以便与 HTML 交互并检测是否存在摄像头
- 加载预训练的 TensorFlow.js 模型
- 使用加载的模型对摄像头数据流进行连续分类,并在图片中的对象周围绘制边界框。
后续步骤
欢迎与我们分享您的成果!您也可以轻松地将此 Codelab 创建的内容扩展到其他广告素材用例。我们建议您跳出思维定式,在完成之后继续入侵。
- 查看此模型可以识别的所有对象,并思考如何运用这些知识来执行操作。现在哪些创意想法可以通过扩展目前的成果来实现?
(或许您可以添加一个简单的服务器端层,以便在设备使用 websocket 看到您选择的某个对象时向其他设备传送通知。这是将旧智能手机升级并赋予新用途的好方法。这一切有无限可能!)
- 请在社交媒体上使用 #MadeWithTFJS # 标签为我们添加标签,即有机会在 TensorFlow 博客中推介自己的项目,甚至在以后的 TensorFlow 活动中展示你的项目。