
1. Hinweis
Maschinelles Lernen ist heutzutage ein Modewort. Die Anwendungen scheinen unbegrenzt zu sein, und in naher Zukunft wird es fast jede Branche betreffen. Wenn Sie als Entwickler oder Designer, Frontend oder Backend arbeiten und mit JavaScript vertraut sind, wurde dieses Codelab geschrieben, um Ihnen den Einstieg in maschinelles Lernen zu erleichtern.
Voraussetzungen
Dieses Codelab wurde für erfahrene Entwickler geschrieben, die bereits mit JavaScript vertraut sind.
Inhalt
In diesem Codelab
- Sie können eine Webseite erstellen, die maschinelles Lernen direkt im Webbrowser über TensorFlow.js nutzt, um häufige Objekte (auch mehrere Objekte gleichzeitig) aus einem Live-Webcam-Stream zu klassifizieren und zu erkennen.
- Verstärken Sie Ihre Webcam, um Objekte zu identifizieren und die Koordinaten des Begrenzungsrahmens für jedes gefundene Objekt zu ermitteln.
- Markieren Sie das gefundene Objekt im Videostream, wie unten gezeigt:
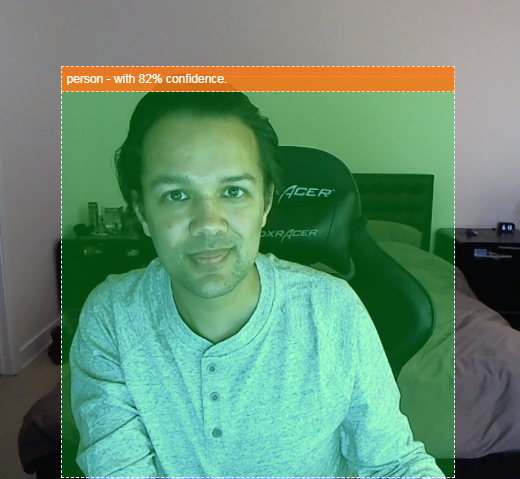
Stellen Sie sich vor, Sie könnten erkennen, ob eine Person in einem Video zu sehen war, und dann zählen, wie viele Personen zu einem bestimmten Zeitpunkt anwesend waren, um einzuschätzen, wie viel in einem bestimmten Bereich am Tag los war, oder sich selbst eine Warnung senden, wenn Ihr Hund während Ihrer Abwesenheit in einem Raum Ihres Hauses erkannt wurde und dass er vielleicht gar nicht zu Hause sein sollte. Wenn du das kannst, bist du auf dem besten Weg, deine eigene Version einer Google Nest Cam zu bauen, die dich mit deiner eigenen Hardware warnen könnte, wenn sie einen Einbrecher (egal welchen Typs) erkennt. Ziemlich praktisch. Ist das nicht einfach? Nö. Lass uns hacken...
Aufgaben in diesem Lab
- Vortrainiertes TensorFlow.js-Modell laden
- So erfassen Sie Daten aus einem Livestream über eine Webcam und zeichnen sie in einen Canvas.
- Klassifizieren eines Bildframes, um die Begrenzungsrahmen von Objekten zu finden, für die das Modell trainiert wurde.
- Hier erfahren Sie, wie Sie mit den vom Modell zurückgegebenen Daten gefundene Objekte hervorheben.
In diesem Codelab werden die ersten Schritte mit vortrainierten TensorFlow.js-Modellen beschrieben. Konzepte und Codeblöcke, die für TensorFlow.js und maschinelles Lernen nicht relevant sind, werden nicht erläutert und können einfach durch Kopieren und Einfügen bereitgestellt werden.
2. Was ist TensorFlow.js?

TensorFlow.js ist eine Open-Source-Bibliothek für maschinelles Lernen, die überall JavaScript ausgeführt werden kann. Es basiert auf der ursprünglichen TensorFlow-Bibliothek, die in Python geschrieben wurde, und zielt darauf ab, diese Entwicklerumgebung und eine Reihe von APIs für die JavaScript-Umgebung nachzubilden.
Wo kann sie verwendet werden?
Aufgrund der Übertragbarkeit von JavaScript können Sie jetzt problemlos in nur einer Sprache schreiben und maschinelles Lernen ganz einfach auf allen folgenden Plattformen ausführen:
- Clientseite im Webbrowser mit einfachem JavaScript
- Serverseitige und sogar IoT-Geräte wie Raspberry Pi mit Node.js
- Desktop-Apps mit Electron
- Native mobile Apps, in denen React Native verwendet wird
TensorFlow.js unterstützt außerdem mehrere Back-Ends in jeder dieser Umgebungen (die tatsächlichen hardwarebasierten Umgebungen, in denen es ausgeführt werden kann, z. B. die CPU oder WebGL). Ein „Back-End“ bedeutet in diesem Zusammenhang keine serverseitige Umgebung. Das Back-End für die Ausführung könnte beispielsweise clientseitig in WebGL ausgeführt werden, um die Kompatibilität sicherzustellen und gleichzeitig eine schnelle Ausführung zu gewährleisten. Derzeit unterstützt TensorFlow.js:
- WebGL-Ausführung auf der Grafikkarte (GPU) des Geräts: Dies ist die schnellste Möglichkeit, größere Modelle (über 3 MB) mit GPU-Beschleunigung auszuführen.
- Web Assembly-Ausführung (WASM) auf der CPU – zur Verbesserung der CPU-Leistung auf verschiedenen Geräten, z. B. auf Smartphones älterer Generationen. Diese Methode eignet sich besser für kleinere Modelle (kleiner als 3 MB), die auf der CPU mit WASM schneller ausgeführt werden können als mit WebGL, da Inhalte auf einen Grafikprozessor hochgeladen werden müssen.
- CPU-Ausführung: Das Fallback sollte keine der anderen Umgebungen verfügbar sein. Das ist zwar die langsamste Methode, ist aber immer für dich da.
Hinweis:Sie können eines dieser Back-Ends erzwingen, wenn Sie wissen, auf welchem Gerät die Ausführung erfolgen soll, oder einfach TensorFlow.js die Entscheidung überlassen, wenn Sie dies nicht angeben.
Clientseitige Funktionen
Die Ausführung von TensorFlow.js im Webbrowser auf dem Clientcomputer kann mehrere Vorteile bieten, die in Betracht gezogen werden sollten.
Datenschutz
Sie können Daten auf dem Clientcomputer trainieren und klassifizieren, ohne Daten an einen Drittanbieter-Webserver senden zu müssen. In bestimmten Fällen kann dies erforderlich sein, um lokale Gesetze wie die DSGVO einzuhalten oder wenn Daten verarbeitet werden, die der Nutzer auf seinem Computer behalten und nicht an Dritte senden möchte.
Geschwindigkeit
Da keine Daten an einen Remote-Server gesendet werden müssen, kann die Inferenz (die Klassifizierung der Daten) schneller erfolgen. Noch besser: Sie haben direkten Zugriff auf die Sensoren des Geräts, wie Kamera, Mikrofon, GPS, Beschleunigungsmesser und mehr, wenn der Nutzer Ihnen Zugriff gewährt.
Reichweite und Skalierung
Mit nur einem Klick kann jeder auf der Welt auf einen Link klicken, den Sie ihm senden, die Webseite in einem Browser öffnen und Ihre Arbeit nutzen. Eine komplexe serverseitige Linux-Einrichtung mit CUDA-Treibern entfällt und vieles mehr, nur um das ML-System zu verwenden.
Kosten
Da es keine Server gibt, müssen Sie nur für ein CDN bezahlen, das Ihre HTML-, CSS-, JS- und Modelldateien hostet. Die Kosten für ein CDN sind wesentlich günstiger als den Betrieb eines Servers (ggf. mit angeschlossener Grafikkarte) rund um die Uhr.
Serverseitige Funktionen
Durch die Nutzung der Node.js-Implementierung von TensorFlow.js werden die folgenden Funktionen aktiviert.
Vollständiger CUDA-Support
Auf der Serverseite müssen Sie für die Grafikkartenbeschleunigung die NVIDIA CUDA-Treiber installieren, damit TensorFlow mit der Grafikkarte funktioniert. Im Gegensatz zum Browser, der WebGL verwendet, ist keine Installation erforderlich. Mit vollständiger CUDA-Unterstützung können Sie jedoch die niedrigeren Fähigkeiten der Grafikkarte voll nutzen, was zu kürzeren Trainings- und Inferenzzeiten führt. Die Leistung entspricht der Python-Implementierung von TensorFlow, da beide dasselbe C++-Backend nutzen.
Modellgröße
Bei hochmodernen Modellen aus der Forschung arbeiten Sie möglicherweise mit sehr großen Modellen, die vielleicht Gigabyte groß sind. Diese Modelle können derzeit aufgrund der Einschränkungen der Arbeitsspeichernutzung pro Browsertab nicht im Webbrowser ausgeführt werden. Wenn Sie diese größeren Modelle ausführen möchten, können Sie Node.js auf Ihrem eigenen Server mit den Hardwarespezifikationen verwenden, die für eine effiziente Ausführung eines solchen Modells erforderlich sind.
IOT
Node.js wird auf gängigen Einplatinencomputern wie Raspberry Pi unterstützt, was wiederum bedeutet, dass Sie TensorFlow.js-Modelle auch auf diesen Geräten ausführen können.
Geschwindigkeit
Node.js ist in JavaScript geschrieben und profitiert daher von einer Just-in-Time-Kompilierung. Das bedeutet, dass Sie bei der Verwendung von Node.js häufig eine Leistungssteigerung erzielen, da das Programm während der Laufzeit optimiert wird, insbesondere für die Vorverarbeitung. Ein gutes Beispiel hierfür ist diese Fallstudie, die zeigt, wie Hugging Face mit Node.js die Leistung seines Natural Language Processing-Modells verdoppeln konnte.
Sie kennen jetzt die Grundlagen von TensorFlow.js, wissen, wo es ausgeführt werden kann und welche Vorteile es bietet. Lassen Sie uns nun anfangen, nützliche Dinge damit zu beginnen.
3. Vortrainierte Modelle
TensorFlow.js bietet eine Vielzahl von vortrainierten Modellen für maschinelles Lernen (ML). Diese Modelle wurden vom TensorFlow.js-Team trainiert und in einer nutzerfreundlichen Klasse zusammengefasst. Sie sind eine hervorragende Möglichkeit, um erste Schritte mit maschinellem Lernen zu machen. Anstatt ein Modell zur Lösung Ihres Problems zu erstellen und zu trainieren, können Sie ein vortrainiertes Modell als Ausgangspunkt importieren.
Auf der Seite Modelle für JavaScript von TensorFlow.js finden Sie eine stetig wachsende Liste nutzerfreundlicher vortrainierter Modelle. Es gibt auch andere Orte, an denen Sie konvertierte TensorFlow-Modelle finden können, die in TensorFlow.js funktionieren, z. B. TensorFlow Hub.
Warum sollte ich ein vortrainiertes Modell verwenden?
Ein beliebtes vortrainiertes Modell bietet eine Reihe von Vorteilen, wenn es zu Ihrem gewünschten Anwendungsfall passt. Zum Beispiel:
- Sie müssen keine Trainingsdaten selbst erheben. Daten im richtigen Format vorzubereiten und zu kennzeichnen, damit ein ML-System daraus lernen kann, kann sehr zeit- und kostenaufwendig sein.
- Die Fähigkeit, schnell einen Prototyp einer Idee mit reduzierten Kosten und Zeit zu entwickeln.
Es bringt nichts, das Rad neu zu erfinden wenn ein vortrainiertes Modell gut genug ist, um das zu tun, was Sie benötigen. So können Sie sich darauf konzentrieren, das vom Modell bereitgestellte Wissen zur Umsetzung Ihrer kreativen Ideen zu nutzen. - Nutzung auf dem neuesten Stand der Forschung. Vortrainierte Modelle basieren oft auf populären Forschungsergebnissen. So erhalten Sie einen Einblick in solche Modelle und können gleichzeitig ihre Leistung in der realen Welt nachvollziehen.
- Nutzerfreundlichkeit und umfangreiche Dokumentation Aufgrund der Beliebtheit solcher Modelle.
- Lerntransfer: Einige vortrainierte Modelle bieten Lerntransferfunktionen, bei denen im Wesentlichen die bei einer Aufgabe des maschinellen Lernens erlernten Informationen an ein anderes ähnliches Beispiel übertragen werden. Ein Modell, das ursprünglich dafür trainiert wurde, Katzen zu erkennen, könnte neu trainiert werden, um Hunde zu erkennen, wenn Sie ihm neue Trainingsdaten geben. Das geht schneller, da Sie nicht mit einem leeren Canvas beginnen müssen. Das Modell kann das, was es bereits gelernt hat, um Katzen zu erkennen, dann das neue Ding erkennen – Hunde haben auch Augen und Ohren, wenn es also bereits weiß, wie diese Merkmale zu finden sind, haben wir die Hälfte geschafft. Das Modell mit Ihren eigenen Daten viel schneller neu trainieren.
Was ist COCO-SSD?
COCO-SSD ist der Name eines vortrainierten ML-Modells zur Objekterkennung, das Sie in diesem Codelab verwenden. Er zielt darauf ab, mehrere Objekte in einem einzelnen Bild zu lokalisieren und zu identifizieren. Mit anderen Worten, sie kann Ihnen den Begrenzungsrahmen von Objekten mitteilen, für deren Suche er trainiert wurde. So können Sie die Position dieses Objekts in einem beliebigen Bild ermitteln, das Sie ihm präsentieren. Ein Beispiel sehen Sie in der folgenden Abbildung:

Wenn auf dem Bild oben mehr als ein Hund zu sehen ist, würden Ihnen die Koordinaten von zwei Begrenzungsrahmen zur Verfügung stehen, die jeweils die jeweilige Position beschreiben. COCO-SSD wurde vortrainiert, 90 gängige Alltagsgegenstände zu erkennen, zum Beispiel Personen, Autos oder Katzen.
Woher kommt der Name?
Der Name klingt vielleicht etwas merkwürdig, stammt aber aus zwei Akronymen:
- COCO: Das Modell wurde mit dem COCO-Dataset (Common Objects in Context) trainiert, das jeder kostenlos herunterladen und zum Trainieren seiner eigenen Modelle verwenden kann. Das Dataset enthält über 200.000 mit Labels versehene Bilder,aus denen Sie lernen können.
- SSD (Single-Shot-Multibox-Erkennung): Bezieht sich auf den Teil der Modellarchitektur, der bei der Implementierung des Modells verwendet wurde. Für das Codelab müssen Sie dies nicht verstehen. Wenn Sie sich jedoch dafür interessieren, finden Sie hier weitere Informationen zu SSD.
4. Einrichten
Voraussetzungen
- Ein moderner Webbrowser.
- Grundkenntnisse in HTML, CSS, JavaScript und Chrome DevTools (Betrachten der Konsolenausgabe)
Erste Schritte mit dem Programmieren
Standardvorlagen wurden für Glitch.com oder Codepen.io erstellt. Sie können beide Vorlagen mit nur einem Klick als Basisstatus für dieses Code-Lab klonen.
Klicke in Glitch auf die Schaltfläche Remix this (Remix erstellen), um ihn zu verzweigen und einen neuen Satz Dateien zu erstellen, die du bearbeiten kannst.
Alternativ können Sie auf Codepen unten rechts auf dem Bildschirm auf Fork klicken.
Dieses sehr einfache Gerüst stellt folgende Dateien bereit:
- HTML-Seite (index.html)
- Stylesheet (style.css)
- Datei zum Schreiben des JavaScript-Codes (script.js)
Der Einfachheit halber gibt es in der HTML-Datei einen zusätzlichen Import für die TensorFlow.js-Bibliothek. Sie sieht so aus:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternative: Ihren bevorzugten Webeditor verwenden oder lokal bearbeiten
Wenn du den Code herunterladen und lokal oder in einem anderen Online-Editor arbeiten möchtest, erstelle einfach die drei oben genannten Dateien im selben Verzeichnis, kopiere den Code aus unserem Glitch-Boilerplate und füge ihn dann in die einzelnen Dateien ein.
5. Das HTML-Skeleton ausfüllen
Alle Prototypen erfordern ein grundlegendes HTML-Gerüst. Damit wird die Ausgabe des Modells für maschinelles Lernen später gerendert. Richten wir das jetzt so ein:
- Einen Titel für die Seite
- Beschreibender Text
- Eine Schaltfläche zum Aktivieren der Webcam
- Ein Video-Tag, in dem der Webcam-Stream gerendert wird
Um diese Funktionen einzurichten, öffnen Sie "index.html" und fügen Sie den vorhandenen Code folgendermaßen ein:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
Code verstehen
Beachten Sie einige wichtige Informationen, die Sie hinzugefügt haben:
- Du hast ein
<h1>-Tag und einige<p>-Tags für den Header sowie Informationen zur Verwendung der Seite hinzugefügt. Hier gibt es nichts Besonderes.
Sie haben außerdem ein Bereichs-Tag hinzugefügt, das Ihren Demobereich darstellt:
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- Zu Beginn ordnen Sie diesem
sectiondie Klasse „unsichtbar“ zu. Auf diese Weise können Sie dem Nutzer visuell veranschaulichen, wann das Modell fertig ist. Sie können bedenkenlos auf die Schaltfläche Webcam aktivieren klicken. - Sie haben die Schaltfläche Webcam aktivieren hinzugefügt, die Sie in Ihrem CSS gestalten.
- Sie haben außerdem ein Video-Tag hinzugefügt, über das Sie Ihre Webcam-Eingabe streamen. Sie werden diese in Kürze in Ihrem JavaScript-Code einrichten.
Wenn Sie jetzt eine Vorschau der Ausgabe anzeigen, sollte sie in etwa so aussehen:

6. Stil hinzufügen
Standardeinstellungen für Elemente
Fügen wir zunächst den soeben hinzugefügten HTML-Elementen Stile hinzu, um sicherzustellen, dass sie korrekt gerendert werden:
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
Fügen Sie als Nächstes einige nützliche CSS-Klassen hinzu, die bei verschiedenen Zuständen unserer Benutzeroberfläche helfen, z. B. wenn wir die Schaltfläche ausblenden oder den Demobereich als nicht verfügbar anzeigen lassen möchten, wenn das Modell noch nicht bereit ist.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
Sehr gut! Das ist alles, was du brauchst. Wenn Sie Ihre Stile erfolgreich mit den beiden obigen Code-Elementen überschrieben haben, sollte Ihre Live-Vorschau jetzt wie folgt aussehen:

Beachten Sie, dass der Text des Demobereichs und die Schaltfläche nicht verfügbar sind, da der HTML-Code standardmäßig die Klasse "unvisible" hat. angewendet. Sie verwenden JavaScript, um diese Klasse zu entfernen, sobald das Modell einsatzbereit ist.
7. JavaScript-Skeleton erstellen
Auf wichtige DOM-Elemente verweisen
Stellen Sie zunächst sicher, dass Sie auf die wichtigsten Teile der Seite zugreifen können, die Sie später in unserem Code bearbeiten oder aufrufen müssen:
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
Webcam-Unterstützung prüfen
Du kannst jetzt einige unterstützende Funktionen hinzufügen, um zu prüfen, ob der von dir verwendete Browser den Zugriff auf den Webcam-Stream über getUserMedia unterstützt:
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
Webcam-Stream abrufen
Geben Sie als Nächstes den Code für die zuvor leere enableCam-Funktion ein, die wir oben definiert haben, indem Sie den folgenden Code kopieren und einfügen:
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
Fügen Sie zum Schluss etwas temporäres Code hinzu, damit Sie testen können, ob die Webcam funktioniert.
Der folgende Code gibt an, als wäre Ihr Modell geladen und aktiviert die Kameraschaltfläche, sodass Sie darauf klicken können. Der gesamte Code wird im nächsten Schritt ersetzt. Bereiten Sie sich also darauf vor, ihn gleich wieder zu löschen:
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
Sehr gut! Wenn Sie den Code ausgeführt und auf die Schaltfläche geklickt haben, wie sie jetzt steht, sollten Sie in etwa Folgendes sehen:

8. Modell für maschinelles Lernen verwenden
Modell laden
Jetzt können Sie das COCO-SSD-Modell laden.
Aktivieren Sie nach Abschluss der Initialisierung den Demobereich und die Schaltfläche auf Ihrer Webseite (fügen Sie diesen Code über den temporären Code ein, den Sie am Ende des letzten Schritts hinzugefügt haben):
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
Nachdem Sie den Code oben hinzugefügt und den Livestream aktualisiert haben, werden Sie feststellen, dass die Schaltfläche Webcam aktivieren einige Sekunden nach dem Laden der Seite (abhängig von Ihrer Netzwerkgeschwindigkeit) automatisch angezeigt wird, sobald das Modell einsatzbereit ist. Damit haben Sie aber auch die Funktion predictWebcam eingefügt. Jetzt ist es an der Zeit, dies vollständig zu definieren, da unser Code derzeit nichts bewirkt.
Weiter gehts!
Frames über die Webcam klassifizieren
Führen Sie den folgenden Code aus, damit die App kontinuierlich einen Frame aus dem Webcam-Stream abrufen kann, wenn der Browser bereit ist, und ihn an das zu klassifizierende Modell übergeben.
Das Modell parst dann die Ergebnisse und zeichnet ein <p>-Tag an den zurückgegebenen Koordinaten. Der Text wird auf das Label des Objekts gesetzt, wenn es über einem bestimmten Konfidenzniveau liegt.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
Der wirklich wichtige Aufruf in diesem neuen Code ist model.detect().
Alle vorgefertigten Modelle für TensorFlow.js haben eine Funktion wie diese (der Name kann sich von Modell zu Modell ändern, daher finden Sie in der Dokumentation weitere Informationen), die die Inferenz des maschinellen Lernens tatsächlich durchführt.
Bei der Inferenz wird einfach eine Eingabe durch das Modell für maschinelles Lernen durchgeführt (im Wesentlichen viele mathematische Operationen) und dann einige Ergebnisse zu liefern. Mit den vorgefertigten TensorFlow.js-Modellen geben wir unsere Vorhersagen in Form von JSON-Objekten zurück, was die Verwendung erleichtert.
Alle Details zu dieser Vorhersagefunktion finden Sie hier in unserer GitHub-Dokumentation für das COCO-SSD-Modell. Diese Funktion ist im Hintergrund sehr aufwendig: Sie kann jede Art von Bild akzeptieren, -Objekt als Parameter verwendet, z. B. ein Bild, ein Video oder ein Canvas-Element. Die Verwendung vorgefertigter Modelle kann Ihnen viel Zeit und Mühe sparen, da Sie diesen Code nicht selbst schreiben müssen und ihn sofort ausführen können.
Wenn Sie diesen Code ausführen, sollten Sie jetzt ein Bild erhalten, das in etwa so aussieht:
Hier noch ein Beispiel für den Code, bei dem mehrere Objekte gleichzeitig erkannt werden:

Endlich! Du kannst dir jetzt vorstellen, wie einfach es wäre, ein Gerät wie eine Nest Cam mit einem alten Smartphone zu erstellen, das dich benachrichtigt, wenn dein Hund auf dem Sofa oder deine Katze auf dem Sofa zu sehen ist. Wenn Sie Probleme mit Ihrem Code haben, prüfen Sie hier meine endgültige Arbeitsversion, um zu sehen, ob Sie etwas falsch kopiert haben.
9. Glückwunsch
Herzlichen Glückwunsch! Sie haben Ihre ersten Schritte zur Verwendung von TensorFlow.js und maschinellem Lernen im Webbrowser getan. Jetzt ist es an dir, diese bescheidenen Anfänge in etwas Kreatives zu verwandeln. Was willst du herstellen?
Zusammenfassung
In diesem Codelab haben wir Folgendes getan:
- Hier haben Sie die Vorteile von TensorFlow.js gegenüber anderen Formen von TensorFlow kennengelernt.
- Sie haben gelernt, in welchen Situationen Sie mit einem vortrainierten Modell für maschinelles Lernen beginnen sollten.
- Es wurde eine voll funktionsfähige Webseite erstellt, auf der Objekte in Echtzeit mithilfe Ihrer Webcam klassifiziert werden können. Dazu gehören:
- HTML-Struktur für Inhalte erstellen
- Stile für HTML-Elemente und -Klassen definieren
- JavaScript-Gerüst einrichten, um mit dem HTML-Code zu interagieren und das Vorhandensein einer Webcam zu erkennen
- Vortrainiertes TensorFlow.js-Modell laden
- Das geladene Modell verwenden, um den Webcam-Stream kontinuierlich zu klassifizieren und einen Begrenzungsrahmen um Objekte im Bild zu zeichnen.
Nächste Schritte
Erzähl uns deine Arbeit! Sie können das, was Sie für dieses Codelab erstellt haben, ganz einfach auf andere kreative Anwendungsfälle erweitern. Wir empfehlen dir, unkonventionell zu denken und weiter zu hacken, wenn du fertig bist.
- Sehen Sie sich alle Objekte an, die dieses Modell erkennen kann, und überlegen Sie, wie Sie dieses Wissen nutzen könnten, um eine Aktion auszuführen. Welche kreativen Ideen könntest du jetzt umsetzen, indem du deine bisherigen Ideen weiter ausbaust?
Vielleicht könnten Sie eine einfache serverseitige Schicht hinzufügen, um eine Benachrichtigung an ein anderes Gerät zu senden, wenn es mithilfe von WebSockets ein bestimmtes Objekt Ihrer Wahl erkennt. Das wäre eine gute Möglichkeit, ein altes Smartphone aufzuwerten und ihm einen neuen Zweck zu geben. Die Möglichkeiten sind unbegrenzt!)
- Wenn Sie uns in den sozialen Medien mit dem Hashtag #MadeWithTFJS taggen, wird Ihr Projekt in unserem TensorFlow-Blog oder sogar bei zukünftigen TensorFlow-Veranstaltungen vorgestellt.
Weitere TensorFlow.js-Codelabs, um tiefer in das Thema einzutauchen
- In TensorFlow.js ein komplett neues neuronales Netzwerk schreiben
- Audioerkennung mit Lerntransfer in TensorFlow.js
- Benutzerdefinierte Bildklassifizierung mit Lerntransfer in TensorFlow.js