
1. 시작하기 전에
요즘 머신러닝은 가장 유행하는 단어입니다. 이 기술은 응용 분야에 한계가 없는 것처럼 보이며 가까운 미래에 거의 모든 산업에 영향을 미칠 것으로 보입니다. 프런트엔드 또는 백엔드의 엔지니어나 디자이너로 일하고 자바스크립트에 익숙하다면, 이 Codelab은 머신러닝을 자신의 스킬에 추가하는 데 도움이 되도록 작성되었습니다.
기본 요건
이 Codelab은 이미 JavaScript에 익숙한 숙련된 엔지니어를 대상으로 작성되었습니다.
빌드할 항목
이 Codelab에서는
- TensorFlow.js를 통해 웹브라우저에서 직접 머신러닝을 사용하는 웹페이지를 만들어 라이브 웹캠 스트림에서 일반적인 객체(한 번에 두 개 이상 포함)를 분류하고 감지합니다.
- 일반 웹캠을 사용하여 객체를 식별하고 발견한 각 객체의 경계 상자 좌표를 얻습니다.
- 아래와 같이 동영상 스트림에서 찾은 객체를 강조표시합니다.
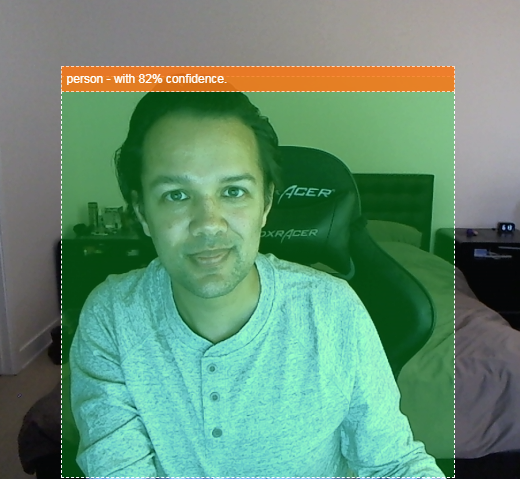
동영상에 사람이 있는지 감지할 수 있고, 특정 시간에 얼마나 많은 사람이 있었는지 집계하여 하루 동안 특정 구역이 얼마나 붐비는지 추정하거나, 집에 있으면 안 될 수 있는 집 방에 반려견이 감지되면 알림을 보낼 수 있다고 상상해 보세요. 그렇게 할 수 있다면 나만의 맞춤 하드웨어를 사용하는 침입자 (모든 유형)를 감지할 때 알림을 받을 수 있는 Google Nest Cam의 자체 버전을 만들 수 있습니다. 꽤 깔끔하네요. 어려운 작업인가요? 아니요. 해킹을 시작해 보자...
학습할 내용
- 선행 학습된 TensorFlow.js 모델을 로드하는 방법
- 라이브 웹캠 스트림에서 데이터를 가져와 캔버스에 그리는 방법
- 이미지 프레임을 분류하여 모델이 인식하도록 학습된 객체의 경계 상자를 찾는 방법
- 모델에서 다시 전달된 데이터를 사용하여 찾은 객체를 강조 표시하는 방법
이 Codelab에서는 TensorFlow.js 선행 학습된 모델을 사용하여 시작하는 방법을 중점적으로 다룹니다. TensorFlow.js 및 머신러닝과 관련 없는 개념과 코드 블록은 설명하지 않으며 간단히 복사하여 붙여넣을 수 있도록 제공됩니다.
2. TensorFlow.js란 무엇인가요?

TensorFlow.js는 JavaScript가 가능한 모든 곳에서 실행할 수 있는 오픈소스 머신러닝 라이브러리입니다. Python으로 작성된 원래 TensorFlow 라이브러리를 기반으로 하며 JavaScript 생태계용 개발자 환경과 API 세트를 다시 만드는 것을 목표로 합니다.
어디에서 사용할 수 있나요?
JavaScript의 이식성을 고려할 때, 이제 단일 언어로 작성하고 다음과 같은 모든 플랫폼에서 머신러닝을 쉽게 수행할 수 있습니다.
- Vanilla JavaScript를 사용하는 웹브라우저의 클라이언트 측
- Node.js를 사용하는 서버 측 및 IoT 기기(예: Raspberry Pi)
- Electron을 사용하는 데스크톱 앱
- React Native를 사용하는 네이티브 모바일 앱
또한 TensorFlow.js는 이러한 각 환경 (예: CPU 또는 WebGL) 내에서 실행할 수 있는 실제 하드웨어 기반 환경 내에서 여러 백엔드를 지원합니다. '백엔드' 이 맥락에서 서버 측 환경을 의미하지는 않습니다. 호환성을 보장하고 빠르게 실행하기 위해 실행을 위한 백엔드는 WebGL의 클라이언트 측일 수 있습니다. 현재 TensorFlow.js는 다음을 지원합니다.
- 기기의 그래픽 카드에서 WebGL 실행 (GPU) - GPU 가속을 사용하여 더 큰 모델 (크기 3MB 이상)을 가장 빠르게 실행할 수 있습니다.
- CPU에서 웹 어셈블리 (WASM) 실행 - 이전 세대의 휴대전화를 비롯한 여러 기기에서 CPU 성능을 개선합니다. 이는 그래픽 프로세서에 콘텐츠를 업로드하는 오버헤드로 인해 WebGL보다 WASM을 사용할 때 CPU에서 더 빠르게 실행될 수 있는 작은 모델 (크기 3MB 미만)에 더 적합합니다.
- CPU 실행 - 다른 환경을 사용할 수 없어야 합니다. 이 세 가지 방법 중 가장 느리지만 언제나 도움이 됩니다.
참고: 실행할 기기를 알고 있는 경우 이러한 백엔드 중 하나를 강제하도록 선택하거나, 지정하지 않는 경우 TensorFlow.js가 자동으로 결정하도록 할 수 있습니다.
클라이언트 측 슈퍼 파워
클라이언트 컴퓨터의 웹브라우저에서 TensorFlow.js를 실행하면 고려할 만한 여러 이점을 얻을 수 있습니다.
개인 정보 보호
서드 파티 웹 서버로 데이터를 전송하지 않고도 클라이언트 시스템에서 데이터를 학습시키고 분류할 수 있습니다. 데이터 수집은 GDPR과 같은 현지 법규의 준수를 위해 요구되거나, 사용자가 제3자에게 보내지 않고 컴퓨터에 보관하고자 하는 데이터를 처리하는 경우일 수 있습니다.
Speed
데이터를 원격 서버로 전송할 필요가 없으므로 추론 (데이터를 분류하는 작업)이 더 빠를 수 있습니다. 더 좋은 점은 사용자가 액세스 권한을 부여하면 카메라, 마이크, GPS, 가속도계와 같은 기기의 센서에 직접 액세스할 수 있다는 것입니다.
도달범위 및 확장
전 세계 누구나 클릭 한 번으로 내가 보낸 링크를 클릭하고, 자신의 브라우저에서 웹페이지를 열고, 내가 만든 것을 활용할 수 있습니다. CUDA 드라이버를 사용하는 복잡한 서버 측 Linux 설정이 필요 없으며 머신러닝 시스템만 사용하기만 하면 됩니다.
비용
서버가 없다는 것은 HTML, CSS, JS 및 모델 파일을 호스팅하는 CDN만 비용을 지불하면 됨을 의미합니다. CDN 비용은 연중무휴 24시간 실행되는 서버 (그래픽 카드가 연결될 수 있음)보다 훨씬 저렴합니다.
서버 측 기능
TensorFlow.js의 Node.js 구현을 활용하면 다음 기능을 사용할 수 있습니다.
완벽한 CUDA 지원
서버 측에서 그래픽 카드 가속을 위해 NVIDIA CUDA 드라이버를 설치하여 TensorFlow가 그래픽 카드와 호환할 수 있도록 해야 합니다 (WebGL을 사용하는 브라우저와 달리 설치 필요 없음). 하지만 완전한 CUDA 지원을 통해 그래픽 카드의 하위 수준 기능을 최대한 활용하여 학습 및 추론 시간을 단축할 수 있습니다. 둘 다 동일한 C++ 백엔드를 공유하므로 Python TensorFlow 구현과 동일한 성능을 발휘합니다.
모델 크기
연구 중인 최첨단 모델의 경우, 크기가 기가바이트에 달할 정도로 매우 큰 모델로 작업하게 될 수도 있습니다. 이 모델은 브라우저 탭당 메모리 사용량 한도로 인해 현재 웹브라우저에서 실행할 수 없습니다. 이러한 더 큰 모델을 실행하려면 이러한 모델을 효율적으로 실행하는 데 필요한 하드웨어 사양을 갖춘 Node.js를 자체 서버에서 사용하면 됩니다.
IOT
Node.js는 Raspberry Pi와 같이 널리 사용되는 단일 보드 컴퓨터에서 지원되므로 이러한 기기에서도 TensorFlow.js 모델을 실행할 수 있습니다.
Speed
Node.js는 자바스크립트로 작성되므로 적시 컴파일의 이점을 활용할 수 있습니다. 즉, Node.js를 사용하면 런타임에 최적화되므로 특히 실행 중인 전처리에 대해 성능이 향상되는 경우가 많습니다. 이에 대한 좋은 예는 Hugging Face가 Node.js를 사용하여 자연어 처리 모델의 성능을 2배 향상한 방법을 보여주는 우수사례에서 확인할 수 있습니다.
이제 TensorFlow.js의 기본사항과 실행 위치, 몇 가지 이점을 이해했습니다. 이제 TensorFlow.js로 유용한 작업을 해보겠습니다.
3. 선행 학습된 모델
TensorFlow.js는 선행 학습된 다양한 머신러닝 (ML) 모델을 제공합니다. 이 모델은 TensorFlow.js팀에서 학습하고 사용하기 쉬운 클래스로 래핑되었으며, 머신러닝의 첫 단계를 시작하는 좋은 방법입니다. 문제를 해결하기 위해 모델을 빌드하고 학습시키는 대신 선행 학습된 모델을 시작점으로 가져올 수 있습니다.
Tensorflow.js JavaScript용 모델 페이지에서 사용하기 쉬운 선행 학습된 모델 목록을 계속해서 확인할 수 있습니다. TensorFlow Hub 등 TensorFlow.js에서 작동하는 변환된 TensorFlow 모델을 가져올 수 있는 다른 방법도 있습니다.
선행 학습된 모델을 사용해야 하는 이유는 무엇인가요?
원하는 사용 사례에 적합한 경우 널리 사용되는 선행 학습된 모델로 시작하면 다음과 같은 많은 이점이 있습니다.
- 학습 데이터를 직접 수집할 필요가 없습니다. 머신러닝 시스템이 데이터를 사용하여 학습할 수 있도록 데이터를 올바른 형식으로 준비하고 라벨을 지정하는 것은 시간이 오래 걸리고 비용이 많이 들 수 있습니다.
- 단축된 비용과 시간으로 아이디어의 프로토타입을 신속하게 제작할 수 있는 능력
'시간을 재창조'하는 것은 무의미함 모델을 사용하면 선행 학습된 모델이 필요한 작업을 충분히 수행할 수 있으므로 모델이 제공한 지식을 활용하여 창의적인 아이디어를 구현하는 데 집중할 수 있습니다. - 최첨단 연구 활용. 선행 학습된 모델은 인기 있는 연구를 토대로 하는 경우가 많으므로 이러한 모델을 접하는 동시에 실제 성능도 파악할 수 있습니다.
- 사용 편의성 및 광범위한 문서. 이러한 모델의 인기 덕분입니다.
- 전이 학습 기능. 일부 선행 학습된 모델은 본질적으로 한 머신러닝 작업에서 학습한 정보를 다른 유사한 예시로 전달하는 방식인 전이 학습 기능을 제공합니다. 예를 들어 원래 고양이를 인식하도록 학습된 모델이 새로운 학습 데이터를 제공한다면 개를 인식하도록 재학습할 수 있습니다. 빈 캔버스에서 시작하지 않으므로 더 빠르게 시작할 수 있습니다. 이 모델은 이미 학습한 내용을 활용하여 고양이를 인식한 다음 새로운 것을 인식할 수 있습니다. 개도 눈과 귀가 있기 때문에 이러한 특성을 찾는 방법을 이미 알고 있다면 인간의 중간 단계에 있습니다. 자체 데이터로 모델을 훨씬 더 빠르게 재학습시킬 수 있습니다.
COCO-SSD란 무엇인가요?
COCO-SSD는 이 Codelab에서 사용할 선행 학습된 객체 감지 ML 모델의 이름으로, 단일 이미지에서 여러 객체를 현지화하고 식별하는 것을 목표로 합니다. 즉, 주어진 이미지에서 객체의 위치를 제공하도록 학습한 객체의 경계 상자를 알 수 있습니다. 아래 이미지의 예를 참고하세요.

위 이미지에 개가 두 마리 이상 있는 경우, 각각의 위치를 나타내는 2개의 경계 상자 좌표가 주어집니다. COCO-SSD는 사람, 자동차, 고양이 등 일상에 흔히 사용되는 90가지 사물을 인식하도록 선행 학습되었습니다.
이름은 어디에서 유래되었나요?
이 이름은 이상하게 들릴 수 있지만 다음 두 약어에서 유래되었습니다.
- COCO: 자체 모델을 학습시킬 때 누구나 무료로 다운로드하여 사용할 수 있는 COCO (Common Objects in Context) 데이터 세트를 기반으로 학습되었다는 사실을 의미합니다. 데이터 세트에는 학습에 사용할 수 있는 라벨이 지정된 200,000개 이상의 이미지가 포함되어 있습니다.
- SSD (단일 장면 멀티박스 감지): 모델 구현에 사용된 모델 아키텍처의 일부를 의미합니다. Codelab에서는 이 내용을 이해할 필요는 없지만, 궁금한 점이 있으면 여기에서 SSD에 관해 자세히 알아보세요.
4. 설정
필요한 항목
- 최신 웹브라우저입니다.
- HTML, CSS, JavaScript, Chrome DevTools (콘솔 출력 보기)에 관한 기본 지식
코딩을 시작해 볼까요?
Glitch.com 또는 Codepen.io용으로 만든 상용구 템플릿이 있습니다. 클릭 한 번으로 간단히 이 Codelab의 기본 상태로 두 템플릿 중 하나를 클론할 수 있습니다.
Glitch에서 리믹스 버튼을 클릭하여 새로운 파일 세트를 포크하고 수정할 수 있습니다.
또는 Codepen에서 화면 오른쪽 하단의 포크를 클릭합니다.
이 매우 간단한 구조는 다음과 같은 파일을 제공합니다.
- HTML 페이지 (index.html)
- 스타일시트 (style.css)
- JavaScript 코드 (script.js)를 작성할 파일
편의를 위해 TensorFlow.js 라이브러리의 HTML 파일에 추가된 가져오기가 있습니다. 상태 메시지가 표시됩니다.
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
대안: 선호하는 웹편집기 사용 또는 로컬에서 작업
코드를 다운로드하여 로컬에서 작업하거나 다른 온라인 편집기에서 작업하려면 위에 나온 3개의 파일을 같은 디렉터리에 만들고 Glitch 상용구에서 코드를 복사하여 각각에 붙여넣으면 됩니다.
5. HTML 스켈레톤 채우기
모든 프로토타입에는 기본적인 HTML 스캐폴딩이 필요합니다. 나중에 이를 사용하여 머신러닝 모델의 출력을 렌더링합니다. 이제 이를 설정해 보겠습니다.
- 페이지 제목
- 설명 텍스트
- 웹캠 사용 설정 버튼
- 웹캠 스트림을 렌더링하는 동영상 태그
이 기능을 설정하려면 index.html을 열고 기존 코드 위에 다음 코드를 붙여넣으세요.
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
코드 이해하기
추가한 몇 가지 주요 사항을 확인하세요.
- 헤더에
<h1>태그와<p>태그를 추가하고 페이지 사용 방법에 관한 정보를 추가했습니다. 특별한 건 없어요.
데모 공간을 나타내는 섹션 태그도 추가했습니다.
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- 처음에는 이
section에 'invisible' 클래스를 제공합니다. 이렇게 하면 모델이 준비되었을 때 사용자에게 시각적으로 설명할 수 있으므로 웹캠 사용 설정 버튼을 클릭해도 안전합니다. - CSS에서 스타일을 지정할 웹캠 사용 설정 버튼을 추가했습니다.
- 웹캠 입력을 스트리밍할 동영상 태그도 추가했습니다. 곧 자바스크립트 코드에서 이를 설정할 것입니다.
지금 출력을 미리 보면 다음과 같이 표시됩니다.

6. 스타일 추가
요소 기본값
먼저 올바르게 렌더링되도록 방금 추가한 HTML 요소의 스타일을 추가해 보겠습니다.
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
다음으로, 버튼을 숨기거나 모델이 아직 준비되지 않은 경우 데모 영역을 사용할 수 없는 것처럼 보이게 할 때와 같이 사용자 인터페이스의 다양한 상태에 도움이 되는 유용한 CSS 클래스를 추가합니다.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
좋습니다. 완료되었습니다. 위의 두 코드로 스타일을 덮어쓰면 실시간 미리보기가 다음과 같이 표시됩니다.

HTML에는 기본적으로 'invisible' 클래스가 있으므로 데모 영역 텍스트와 버튼을 사용할 수 없습니다. 적용됩니다. 모델을 사용할 준비가 되면 JavaScript를 사용하여 이 클래스를 삭제합니다.
7. JavaScript 스켈레톤 만들기
주요 DOM 요소 참조
먼저, 향후 Google 코드에서 조작하거나 액세스해야 하는 페이지의 주요 부분에 액세스할 수 있어야 합니다.
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
웹캠 지원 여부 확인하기
이제 사용 중인 브라우저에서 getUserMedia를 통한 웹캠 스트림 액세스를 지원하는지 확인하는 보조 함수를 추가할 수 있습니다.
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
웹캠 스트림 가져오기
다음으로, 아래 코드를 복사하고 붙여넣어 위에서 정의한 이전에 비어 있는 enableCam 함수의 코드를 작성합니다.
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
마지막으로 웹캠이 작동하는지 테스트할 수 있도록 임시 코드를 추가합니다.
아래 코드는 모델이 로드된 것으로 간주하고 카메라 버튼을 사용 설정하여 사용자가 클릭할 수 있도록 합니다. 다음 단계에서 이 코드를 모두 대체하므로 잠시 후 다시 삭제할 수 있도록 준비하세요.
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
좋습니다. 코드를 실행하고 현재 상태 그대로 버튼을 클릭하면 다음과 같이 표시됩니다.

8. 머신러닝 모델 사용
모델 로드
이제 COCO-SSD 모델을 로드할 준비가 되었습니다.
초기화가 완료되면 웹페이지의 데모 영역과 버튼을 사용 설정합니다 (이전 단계의 끝부분에서 추가한 임시 코드 위에 이 코드를 붙여넣으세요).
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
위 코드를 추가하고 실시간 보기를 새로고침하면 페이지가 로드된 후 네트워크 속도에 따라 몇 초 후에 모델을 사용할 준비가 되었을 때 웹캠 사용 설정 버튼이 자동으로 표시됩니다. 그러나 predictWebcam 함수도 붙여넣었습니다. 이제 코드가 현재 아무 작업도 하지 않으므로 이를 완전히 정의할 차례입니다.
다음 단계로 나아가세요!
웹캠에서 프레임 분류하기
아래 코드를 실행하여 브라우저가 준비되면 앱이 계속해서 웹캠 스트림에서 프레임을 가져와 분류할 모델에 전달하도록 합니다.
그런 다음 모델은 결과를 파싱하고 반환되는 좌표에 <p> 태그를 그리고 텍스트가 특정 신뢰도 수준을 초과하는 경우 텍스트를 객체의 라벨로 설정합니다.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
이 새 코드에서 정말 중요한 호출은 model.detect()입니다.
TensorFlow.js용으로 사전 제작된 모든 모델에는 실제로 머신러닝 추론을 수행하는 다음과 같은 함수 (이름은 모델마다 다를 수 있으므로 자세한 내용은 문서를 확인하세요)가 있습니다.
추론은 단순히 입력을 받고 머신러닝 모델 (본질적으로 많은 수학적 연산)을 통해 실행한 다음 결과를 제공하는 작업입니다. TensorFlow.js 사전 제작 모델을 사용하면 예측을 JSON 객체 형식으로 반환하므로 쉽게 사용할 수 있습니다.
이 예측 함수에 대한 자세한 내용은 COCO-SSD 모델에 대한 GitHub 문서를 참조하세요. 이 함수는 보이지 않는 많은 작업 부담을 덜어줍니다. 어떤 '이미지' 같은 이미지도 객체를 매개변수로 사용할 수 있습니다. 사전 제작된 모델을 사용하면 이 코드를 직접 작성할 필요가 없고 '즉시 사용'할 수 있으므로 많은 시간과 노력을 절약할 수 있습니다.
이제 이 코드를 실행하면 다음과 같은 이미지가 표시됩니다.
마지막으로 동시에 여러 객체를 감지하는 코드의 예는 다음과 같습니다.

축하합니다. Nest Cam과 같은 기기를 만들어 소파에 강아지가 있거나 소파에 고양이가 있으면 오래된 휴대전화로 알림을 보내는 것이 이렇게 간단합니다. 코드에 문제가 있는 경우 여기에서 정상적으로 작동하는 최종 버전을 확인하여 잘못 복사했는지 확인하세요.
9. 축하합니다
축하합니다. TensorFlow.js와 웹브라우저에서 머신러닝을 사용하는 첫 단계를 마쳤습니다. 이제 이러한 소박한 시작을 바탕으로 창조적인 시도를 해 보시기 바랍니다. 무엇을 만들고 싶으신가요?
요약
이 Codelab에서 배운 내용은 다음과 같습니다.
- TensorFlow.js 사용의 이점을 다른 형식의 TensorFlow와 비교해 봤습니다.
- 선행 학습된 머신러닝 모델로 시작할 수 있는 상황을 배웠습니다.
- 웹캠을 사용하여 실시간으로 객체를 분류할 수 있으며 다음과 같이 완벽하게 작동하는 웹 페이지를 만들었습니다.
- 콘텐츠의 HTML 스켈레톤 만들기
- HTML 요소 및 클래스의 스타일 정의
- HTML과 상호작용하고 웹캠이 있는지 감지하도록 JavaScript 스캐폴딩 설정
- 선행 학습된 TensorFlow.js 모델 로드
- 로드된 모델을 사용하여 웹캠 스트림을 연속적으로 분류하고 이미지의 객체 주위에 경계 상자를 그립니다.
다음 단계
결과물을 Google과 공유해 주세요. 이 Codelab을 위해 만든 내용을 다른 광고 소재 사용 사례로 쉽게 확장할 수 있습니다. 고정관념을 깨고 이 작업을 마친 후에도 계속 해킹을 시도해 보시기 바랍니다.
- 이 모델이 인식할 수 있는 모든 객체를 확인하고 이 지식을 사용하여 작업을 실행할 수 있는 방법을 생각해 보세요. 오늘 만든 콘텐츠를 확장하여 어떤 창의적인 아이디어를 실현할 수 있을까요?
(간단한 서버 측 레이어를 추가하여 다른 기기가 WebSocket을 사용하여 선택한 특정 객체를 인식할 때 알림을 전송할 수도 있습니다. 이는 오래된 스마트폰을 업사이클링하고 새로운 목적을 부여하는 좋은 방법이 될 것입니다. 가능성은 무한합니다!)
- 소셜 미디어에서 #MadeWithTFJS 해시태그를 사용해 태그하여 여러분의 프로젝트가 TensorFlow 블로그에 추천되거나 향후 TensorFlow 이벤트에서 소개될 기회를 잡으세요.
더 자세히 알아볼 수 있는 추가 TensorFlow.js Codelab
- TensorFlow.js에서 신경망을 처음부터 작성
- TensorFlow.js에서 전이 학습을 사용한 오디오 인식
- TensorFlow.js에서 전이 학습을 사용한 커스텀 이미지 분류