
1. Antes de começar
Machine learning é a palavra da moda hoje em dia. Seus aplicativos parecem não ter limites e estão preparados para atingir quase todos os setores no futuro próximo. Se você trabalha como engenheiro ou designer, front-end ou back-end e está familiarizado com JavaScript, este codelab foi escrito para ajudar você a começar a adicionar machine learning ao seu conjunto de habilidades.
Pré-requisitos
Este codelab foi escrito para engenheiros experientes que já estão familiarizados com JavaScript.
O que você vai criar
Neste codelab, você vai
- Crie uma página da Web que use machine learning diretamente no navegador da Web via TensorFlow.js para classificar e detectar objetos comuns (sim, incluindo mais de um por vez) de um stream ao vivo de webcam.
- Turbine sua webcam normal para identificar objetos e receber as coordenadas da caixa delimitadora para cada objeto encontrado
- Destaque o objeto encontrado no stream de vídeo, conforme mostrado abaixo:
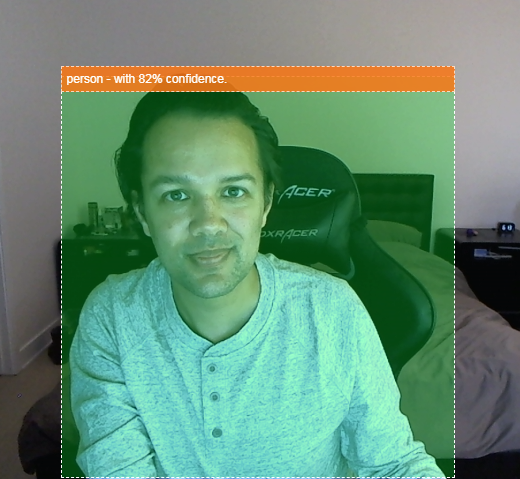
Imagine conseguir detectar se uma pessoa estava em um vídeo e contar quantas pessoas estavam presentes em um determinado momento para estimar o movimento de uma área durante o dia ou enviar a si mesmo um alerta quando seu cachorro foi detectado em um cômodo da sua casa enquanto você está fora e talvez ele não deveria estar lá. Se pudesse, você estaria no caminho certo para criar sua própria versão de uma Google Nest Cam que alertaria ao detectar um intruso (de qualquer tipo) usando seu hardware personalizado. Muito legal. É difícil de fazer? Não. Vamos começar...
O que você vai aprender
- Como carregar um modelo do TensorFlow.js pré-treinado.
- Como extrair dados de uma transmissão ao vivo por webcam e desenhá-los na tela.
- Como classificar um frame de imagem para encontrar as caixas delimitadoras de qualquer objeto que o modelo foi treinado para reconhecer.
- Como usar os dados transmitidos do modelo para destacar objetos encontrados.
O foco deste codelab é mostrar como começar a usar modelos pré-treinados do TensorFlow.js. Os conceitos e blocos de código que não são relevantes para o TensorFlow.js e o machine learning não são explicados e são fornecidos para você simplesmente copiar e colar.
2. O que é o TensorFlow.js?

O TensorFlow.js é uma biblioteca de machine learning de código aberto que pode ser executada em qualquer lugar com JavaScript. Ele é baseado na biblioteca original do TensorFlow escrita em Python e tem como objetivo recriar essa experiência de desenvolvedor e o conjunto de APIs para o ecossistema do JavaScript.
Onde pode ser usado?
Devido à portabilidade do JavaScript, agora é possível escrever em um idioma e realizar machine learning em todas as seguintes plataformas com facilidade:
- Lado do cliente no navegador da Web usando JavaScript básico
- lado do servidor e até dispositivos de IoT, como o Raspberry Pi, que usam Node.js
- Aplicativos para computador que usam o Electron
- Aplicativos nativos para dispositivos móveis que usam o React Native
O TensorFlow.js também oferece suporte a vários back-ends em cada um desses ambientes, ou seja, os ambientes reais baseados em hardware em que ele pode executar, como a CPU ou o WebGL, por exemplo. Um "back-end" neste contexto não significa um ambiente no lado do servidor (o back-end para execução pode ser no lado do cliente no WebGL, por exemplo) para garantir a compatibilidade e manter tudo funcionando rapidamente. Atualmente, o TensorFlow.js é compatível com:
- Execução de WebGL na placa de vídeo do dispositivo (GPU): essa é a maneira mais rápida de executar modelos maiores (com mais de 3 MB) com aceleração de GPU.
- Execução do Web Assembly (WASM) na CPU: para melhorar o desempenho da CPU em vários dispositivos, incluindo smartphones das gerações mais antigas, por exemplo. Isso é mais adequado para modelos menores (com menos de 3 MB), que podem ser executados mais rapidamente na CPU com o WASM do que com o WebGL, devido à sobrecarga do upload de conteúdo para um processador gráfico.
- Execução da CPU: o substituto não deverá estar disponível para nenhum dos outros ambientes. Este é o mais lento dos três, mas está sempre lá para você.
Observação:é possível forçar um desses back-ends se você souber em qual dispositivo vai executar a execução. Também é possível deixar o TensorFlow.js decidir por você se você não especificar isso.
Superpoderes do lado do cliente
Executar o TensorFlow.js no navegador da Web da máquina cliente pode gerar vários benefícios que valem a pena considerar.
Privacidade
Você pode treinar e classificar os dados na máquina cliente sem nunca enviá-los a um servidor da Web de terceiros. Em alguns casos, isso pode ser um requisito para obedecer à legislação local, como o GDPR, ou ao processar dados que o usuário quer manter na máquina e não enviar a terceiros.
Speed
Como você não precisa enviar dados a um servidor remoto, a inferência (o ato de classificar os dados) pode ser mais rápida. Melhor ainda, você tem acesso direto aos sensores do dispositivo, como a câmera, o microfone, o GPS, o acelerômetro, entre outros, caso o usuário permita o acesso.
Alcance e escala
Com um clique, qualquer pessoa no mundo pode clicar em um link que você enviou, abrir a página da Web no navegador e utilizar o que você criou. Para usar o sistema de machine learning, você não precisa de uma configuração complexa do Linux no lado do servidor com drivers CUDA e muito mais.
Custo
A ausência de servidores significa que você só precisa pagar por uma CDN para hospedar seus arquivos HTML, CSS, JS e de modelo. O custo de uma CDN é muito mais barato do que manter um servidor (possivelmente com uma placa de vídeo conectada) funcionando 24 horas por dia, 7 dias por semana.
Recursos do lado do servidor
Utilizar a implementação do TensorFlow.js em Node.js ativa os recursos a seguir.
Suporte completo para CUDA
No lado do servidor, para acelerar a placa gráfica, é necessário instalar os drivers NVIDIA CUDA para permitir que o TensorFlow funcione com a placa de vídeo (ao contrário do navegador que usa WebGL. Não é necessário instalar). No entanto, com o suporte total a CUDA, você aproveita ao máximo os recursos de nível mais baixo da placa de vídeo, o que agiliza o treinamento e a inferência. O desempenho está em paridade com a implementação do TensorFlow em Python, já que ambos compartilham o mesmo back-end em C++.
Tamanho do modelo
Para modelos modernos de pesquisa, você pode estar trabalhando com modelos muito grandes, talvez em gigabytes. No momento, esses modelos não podem ser executados no navegador da web devido às limitações de uso da memória por guia do navegador. Para executar esses modelos maiores, use o Node.js no seu próprio servidor com as especificações de hardware necessárias para executar esse modelo com eficiência.
I/T
O Node.js é compatível com computadores de placa única conhecidos, como o Raspberry Pi (link em inglês), o que significa que você também pode executar modelos do TensorFlow.js nesses dispositivos.
Speed
O Node.js é escrito em JavaScript, o que significa que ele se beneficia da compilação no momento certo. Isso significa que talvez você note ganhos de desempenho ao usar o Node.js, já que ele será otimizado no tempo de execução, especialmente para qualquer pré-processamento que você esteja fazendo. Um ótimo exemplo disso é este estudo de caso, que mostra como a Hugging Face usou o Node.js para dobrar o desempenho do modelo de processamento de linguagem natural.
Agora que você já conhece os conceitos básicos do TensorFlow.js, onde ele pode ser executado e alguns dos benefícios, vamos começar a usá-lo de forma prática.
3. Modelos pré-treinados
O TensorFlow.js fornece uma variedade de modelos de machine learning (ML) pré-treinados. Esses modelos foram treinados pela equipe do TensorFlow.js e agrupados em uma aula fácil de usar. Eles são uma ótima maneira de dar os primeiros passos no machine learning. Em vez de criar e treinar um modelo para resolver seu problema, importe um modelo pré-treinado como ponto de partida.
Acesse a página Modelos para JavaScript do Tensorflow.js, uma lista crescente de modelos pré-treinados fáceis de usar. Há também outros lugares para encontrar modelos convertidos do TensorFlow que funcionam no TensorFlow.js, incluindo o TensorFlow Hub.
Por que usar um modelo pré-treinado?
Há vários benefícios em começar com um modelo pré-treinado conhecido se ele se encaixa no caso de uso desejado, como:
- Não precisar coletar dados de treinamento por conta própria. Pode ser muito demorado e caro preparar dados no formato correto e rotulá-los de modo que um sistema de machine learning possa usá-los para aprender.
- A capacidade de prototipar uma ideia rapidamente com custo e tempo reduzidos.
Não faz sentido "reinventar a roda" quando um modelo pré-treinado pode ser bom o suficiente para fazer o que você precisa, permitindo que você se concentre no uso do conhecimento fornecido pelo modelo para implementar suas ideias criativas. - Uso de pesquisa de última geração. Os modelos pré-treinados geralmente são baseados em pesquisas populares, oferecendo exposição a esses modelos e, ao mesmo tempo, compreensão do desempenho deles no mundo real.
- Facilidade de uso e documentação extensa. Devido à popularidade desses modelos.
- Recursos de aprendizado por transferência. Alguns modelos pré-treinados oferecem capacidades de aprendizado por transferência, que é essencialmente a prática de transferir informações aprendidas de uma tarefa de machine learning para outro exemplo semelhante. Por exemplo, um modelo originalmente treinado para reconhecer gatos poderia ser treinado outra vez para reconhecer cachorros, se você fornecesse novos dados de treinamento. Isso será mais rápido, já que você não começará com uma tela em branco. O modelo pode usar o que já aprendeu para reconhecer gatos e depois reconhecer a nova coisa: os cachorros também têm olhos e orelhas. Portanto, se ele já sabe como encontrar esses atributos, estamos na metade do caminho. Treine novamente o modelo com seus próprios dados de maneira muito mais rápida.
O que é COCO-SSD?
COCO-SSD é o nome de um modelo de ML de detecção de objetos pré-treinado que você vai usar neste codelab, que tem como objetivo localizar e identificar vários objetos em uma única imagem. Em outras palavras, ele pode informar a caixa delimitadora de objetos que ele foi treinado para encontrar para fornecer a localização desses objetos em qualquer imagem que você apresentar a ele. Confira um exemplo na imagem abaixo:

Se houvesse mais de um cachorro na imagem acima, você receberia as coordenadas de duas caixas delimitadoras, descrevendo o local de cada uma. O COCO-SSD foi pré-treinado para reconhecer 90 objetos comuns do cotidiano, como uma pessoa, um carro, um gato etc.
Qual é a origem do nome?
O nome pode parecer estranho, mas é originado de duas siglas:
- COCO: refere-se ao fato de que ele foi treinado com o conjunto de dados COCO (Common Objects in Context), que está disponível sem custo financeiro para qualquer pessoa fazer o download e usar no treinamento dos próprios modelos. O conjunto de dados contém mais de 200.000 imagens rotuladas que podem ser usadas para aprendizado.
- SSD (Detecção de caixa múltipla de disparo único): refere-se à parte da arquitetura do modelo que foi usada na implementação do modelo. Você não precisa entender isso para o codelab, mas se tiver curiosidade, saiba mais sobre SSD aqui.
4. Começar a configuração
O que é necessário
- Um navegador da Web moderno.
- Conhecimento básico de HTML, CSS, JavaScript e Chrome DevTools (visualização da saída do console).
Vamos programar
Os modelos de texto padronizado para começar foram criados para o Glitch.com ou o Codepen.io. Basta clonar um modelo como seu estado base para este codelab com apenas um clique.
No Glitch, clique no botão Remixar para bifurcar o conteúdo e criar um conjunto de arquivos que você pode editar.
Como alternativa, no Codepen, clique em fork no canto inferior direito da tela.
Esse esqueleto muito simples fornece os seguintes arquivos:
- Página HTML (index.html)
- Folha de estilo (style.css)
- Arquivo para escrever nosso código JavaScript (script.js)
Para sua conveniência, há uma importação adicional no arquivo HTML da biblioteca do TensorFlow.js. Esta é a aparência dela:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternativa: use seu editor da Web preferido ou trabalhe localmente
Se você quiser fazer o download do código e trabalhar localmente ou em um editor on-line diferente, basta criar os três arquivos nomeados acima no mesmo diretório e copiar e colar o código do código boilerplate do Glitch em cada um deles.
5. Preencher o esqueleto HTML
Todos os protótipos exigem alguma estrutura HTML básica. Você usará isso para renderizar a saída do modelo de machine learning mais tarde. Vamos configurar isso agora:
- Um título para a página
- Um pouco de texto descritivo
- Um botão para ativar a webcam
- Uma tag de vídeo para renderizar o stream da webcam
Para configurar esses recursos, abra index.html e cole o código existente com o seguinte:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
Entender o código
Observe alguns itens importantes que você adicionou:
- Você adicionou uma tag
<h1>e algumas tags<p>ao cabeçalho, além de algumas informações sobre como usar a página. Nada especial aqui.
Você também adicionou uma tag de seção que representa seu espaço de demonstração:
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- Inicialmente, você vai dar a
sectiona classe "invisible". Isso serve para ilustrar ao usuário quando o modelo está pronto e é seguro clicar no botão ativar webcam. - Você adicionou o botão ativar webcam, que será estilizado em seu CSS.
- Você também adicionou uma tag de vídeo para a qual transmitirá a entrada da sua webcam. Isso será configurado no seu código JavaScript em breve.
Ao visualizar a saída agora, ela deve ser semelhante a esta:

6. Adic. estilo
Padrões do elemento
Primeiro, vamos adicionar estilos para os elementos HTML que acabamos de adicionar para garantir que eles sejam renderizados corretamente:
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
Em seguida, adicione algumas classes CSS úteis para ajudar com vários estados diferentes da nossa interface do usuário, como quando queremos ocultar o botão ou fazer com que a área de demonstração apareça como indisponível se o modelo ainda não estiver pronto.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
Ótimo! Isso é tudo o que você precisa. Se você substituiu os estilos com as duas partes do código acima, a visualização ao vivo ficará assim:

Observe como o texto e o botão da área de demonstração não estão disponíveis, já que o HTML por padrão tem a classe "invisible" aplicada. Você usará o JavaScript para remover essa classe assim que o modelo estiver pronto para uso.
7. Criar esqueleto de JavaScript
Como fazer referência a elementos principais de DOM
Primeiro, verifique se você consegue acessar as principais partes da página que precisará manipular ou acessar mais tarde em nosso código:
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
Conferir o suporte para webcam
Agora você pode adicionar algumas funções assistivas para verificar se o navegador que você está usando é compatível com o acesso ao stream por webcam via getUserMedia:
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
Buscar o stream da webcam
Em seguida, copie e cole o código abaixo para preencher o código da função enableCam vazia anteriormente definida acima:
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
Por fim, adicione um código temporário para testar se a webcam está funcionando.
O código abaixo vai fingir que seu modelo foi carregado e ativará o botão da câmera para que você possa clicar nele. Você substituirá todo esse código na próxima etapa, então prepare-se para excluí-lo novamente em breve:
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
Ótimo! Se você executar o código e clicar no botão da forma que ele está atualmente, você verá algo assim:

8. Uso do modelo de machine learning
Como carregar o modelo
Agora está tudo pronto para carregar o modelo COCO-SSD.
Quando a inicialização for concluída, ative a área de demonstração e o botão na sua página da Web (cole este código no código temporário adicionado no fim da última etapa):
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
Depois de adicionar o código acima e atualizar as imagens ao vivo, você verá que, alguns segundos após a página ser carregada (dependendo da velocidade da rede), o botão Ativar webcam aparece automaticamente quando o modelo está pronto para uso. No entanto, você também colou a função predictWebcam. Agora é hora de definir isso completamente, já que nosso código não faz nada no momento.
Vamos para a próxima etapa.
Como classificar um frame usando a webcam
Execute o código abaixo para permitir que o app capture continuamente um frame do stream da webcam quando o navegador estiver pronto e o transmita ao modelo para classificação.
Em seguida, o modelo analisa os resultados, desenha uma tag <p> nas coordenadas retornadas e define o texto como o rótulo do objeto, se estiver acima de um determinado nível de confiança.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
A chamada realmente importante neste novo código é model.detect().
Todos os modelos pré-criados para o TensorFlow.js têm uma função como essa (o nome pode mudar de modelo para modelo, portanto, consulte a documentação para mais detalhes) que realmente realiza a inferência de machine learning.
Inferência é simplesmente o ato de receber uma entrada e executá-la no modelo de machine learning (essencialmente, muitas operações matemáticas) e, em seguida, fornecer alguns resultados. Com os modelos pré-criados do TensorFlow.js, retornamos as previsões na forma de objetos JSON, o que facilita o uso.
Encontre todos os detalhes dessa função de previsão na documentação do GitHub sobre o modelo COCO-SSD aqui (link em inglês). Essa função faz um grande trabalho nos bastidores: ela pode aceitar qualquer objeto como parâmetro, por exemplo, uma imagem, um vídeo, uma tela e assim por diante. O uso de modelos pré-fabricados pode economizar muito tempo e esforço, porque você não vai precisar escrever esse código por conta própria e pode trabalhar com ele pronto para uso.
A execução desse código vai gerar uma imagem parecida com esta:
Por fim, aqui está um exemplo do código que detecta vários objetos ao mesmo tempo:

Uhuuu! Imagine agora como seria simples criar um dispositivo como uma Nest Cam usando um smartphone antigo para alertar você quando vir seu cachorro no sofá ou seu gato no sofá. Se você estiver tendo problemas com seu código, confira minha versão final de trabalho aqui para conferir se algo está incorreto.
9. Parabéns
Parabéns! Você deu os primeiros passos para usar o TensorFlow.js e o machine learning no navegador da Web. Agora, cabe a você transformar esse humilde começo em algo criativo. O que você vai preparar?
Resumo
Neste codelab, você aprendeu como:
- Conheça os benefícios de usar o TensorFlow.js em vez de outras formas de TensorFlow.
- Aprender as situações em que você pode querer começar com um modelo de machine learning pré-treinado.
- Criou uma página da web totalmente funcional que classifica objetos em tempo real usando sua webcam, incluindo:
- Como criar um esqueleto de HTML para conteúdo
- Definir estilos para elementos e classes HTML
- Configurar a estrutura de JavaScript para interagir com o HTML e detectar a presença de uma webcam
- Como carregar um modelo do TensorFlow.js pré-treinado
- Usar o modelo carregado para fazer classificações contínuas do stream da webcam e desenhar uma caixa delimitadora em torno dos objetos na imagem.
Próximas etapas
Compartilhe o que você sabe conosco! Também é possível estender facilmente o que você criou para este codelab para outros casos de uso criativos. Encorajamos você a pensar fora da caixa e continuar invadindo depois que terminar.
- Confira todos os objetos que esse modelo pode reconhecer e pense em como você poderia usar esse conhecimento para realizar uma ação. Que ideias criativas poderiam ser implementadas agora?
Talvez você possa adicionar uma camada simples do lado do servidor para enviar uma notificação a outro dispositivo quando ele detectar um determinado objeto de sua escolha usando websockets. Essa seria uma ótima maneira de reciclar um smartphone antigo e dar a ele uma nova finalidade. As possibilidades são ilimitadas!
- Marque a gente nas redes sociais usando a hashtag #MadeWithTFJS para que seu projeto apareça no blog do TensorFlow ou em eventos futuros.
Mais codelabs do TensorFlow.js para mais detalhes
- Criar uma rede neural do zero no TensorFlow.js
- Reconhecimento de áudio usando aprendizado por transferência no TensorFlow.js
- Classificação de imagens personalizada usando aprendizado por transferência no TensorFlow.js