
۱. مقدمه
در این آزمایشگاه کد، یاد خواهید گرفت که چگونه از BigQuery Graph برای حل مسائل پیچیده زنجیره تأمین و لجستیک استفاده کنید.
شما یک شبکه زنجیره تأمین رستوران را با تمرکز بر ایمنی مواد غذایی و کنترل کیفیت مدلسازی خواهید کرد. هنگامی که یک مشکل ایمنی مواد غذایی - مانند یک ماده آلوده از یک تأمینکننده - پیش میآید، زمان بسیار مهم است. شناسایی "شعاع انفجار" و اجرای سریع فراخوان جراحی میتواند در هزینهها صرفهجویی کرده و از مشتریان محافظت کند.

مدلهای رابطهای سنتی برای ردیابی اقلام در چندین مرحله (تأمینکننده -> توزیعکننده -> فروشگاه -> کالای نهایی) به عملیات JOIN پیچیده و چند مرحلهای نیاز دارند. با BigQuery Graph، ما این اتصالات را مستقیماً مدلسازی میکنیم و امکان پرسوجوهای شهودی و سریع را با استفاده از استاندارد ISO GQL (زبان پرسوجوی گراف) فراهم میکنیم.
آنچه یاد خواهید گرفت
- نحوه تعریف یک مدل گراف روی جداول موجود BigQuery.
- نحوه ایجاد نمودار ویژگی در BigQuery.
- نحوه اجرای پرسوجوهای پیمایشی برای ردیابی تأثیرات بالادستی و پاییندستی.
آنچه نیاز دارید
- یک پروژه ابری گوگل با قابلیت پرداخت صورتحساب.
- پوسته ابری گوگل.
برآورد هزینه
انتظار میرود این آزمایشگاه کمتر از ۵ دلار آمریکا برای هزینههای تحلیل BigQuery هزینه داشته باشد که کاملاً در محدودهی تخصیصهای رایگان برای کاربران جدید قرار میگیرد.
۲. تنظیمات و الزامات
پوسته ابری را باز کنید
شما بخش عمدهای از کار را در Cloud Shell انجام خواهید داد، محیطی پر از امکانات که هر آنچه برای استفاده از Google Cloud نیاز دارید را در خود جای داده است.
- به کنسول ابری گوگل بروید.
- روی آیکون فعالسازی پوسته ابری در نوار ابزار بالا سمت راست کلیک کنید.
- در صورت درخواست، روی ادامه کلیک کنید.
تنظیم متغیرهای محیطی
در Cloud Shell، شناسه پروژه خود را تنظیم کنید تا دستورات آینده سادهتر شوند.
export PROJECT_ID=$(gcloud config get-value project)
فعال کردن API بیگکوئری
مطمئن شوید که BigQuery API فعال است. معمولاً به طور پیشفرض فعال است، اما بهتر است برای احتیاط این کار را انجام دهید.
gcloud services enable bigquery.googleapis.com
۳. ایجاد طرحواره و جداول
شما یک مجموعه داده و جداول ایجاد خواهید کرد که اجزای زنجیره تأمین شما را نشان میدهد:
-
item: تعریف عمومی کالا (مثلاً گوجه فرنگی، مرغ). -
location: امکانات (تأمینکنندگان، مراکز توزیع، کافهها). -
itemlocation: جدول تقاطع که نشاندهنده مکانهای موجودی است. -
bom: فهرست مواد (روابط وزنی را تعریف میکند، مثلاً کالای A در کالای B قرار میگیرد). -
makes:itemlocationبهitemنگاشت میکند. -
stored_at:itemlocationآیتم را بهlocationنگاشت میکند.
ایجاد مجموعه داده
شما میتوانید دستورات SQL را در این آزمایشگاه با استفاده از Cloud Shell یا BigQuery Console اجرا کنید.
برای استفاده از کنسول BigQuery:
- کنسول BigQuery را در یک تب جدید باز کنید.
- هر قطعه کد SQL را از این آزمایشگاه در ویرایشگر پیست کنید، سپس برای اجرای آن روی دکمهی اجرا کلیک کنید.
دستور زیر را در Cloud Shell اجرا کنید یا از کنسول BigQuery برای ایجاد طرحواره استفاده کنید. شما از متغیرهای گره در SQL خود استفاده خواهید کرد.

توجه: (1) برای اجرای این دستور در Google Colab، میتوانید از دستورات جادویی BigQuery نیز استفاده کنید: %%bigquery قطعه کد زیر، طرحواره رستوران را در پروژه شما ایجاد میکند تا دادههای نمودار شما را در خود جای دهد. (2) اگر از Google Colab استفاده میکنید، باید از %%bigquery –project <PROJECT_ID> استفاده کنید. مطمئن شوید که فیلد PROJECT_ID به پروژه مناسبی که قصد استفاده از آن را دارید، نگاشت شده است: PROJECT_ID = "argolis-project-340214" # @param {"type":"string"} (3) اگر از colab استفاده میکنید، بسته به نیاز خود، باید برخی کتابخانهها را نصب کنید. اگر قرار است از تجسم نمودار استفاده کنید، مطمئن شوید که کتابخانه را با دستور pip نصب کردهاید: spanner-graph-notebook==1.1.5
%%bigquery --project=$PROJECT_ID
CREATE SCHEMA IF NOT EXISTS restaurant ;
ایجاد جداول
برای ساخت جداول، کد SQL زیر را اجرا کنید.
%%bigquery --project=$PROJECT_ID
-- 1. Item Table
DROP TABLE IF EXISTS `restaurant.item`;
CREATE TABLE `restaurant.item` (
itemKey STRING,
itemName STRING,
itemCategory STRING,
shelfLifeDays INT64,
PRIMARY KEY (itemKey) NOT ENFORCED
);
-- 2. Location Table
DROP TABLE IF EXISTS `restaurant.location`;
CREATE TABLE `restaurant.location` (
locationKey STRING,
locationType STRING,
locationCity STRING,
locationState STRING,
dunsNumber INT64,
PRIMARY KEY (locationKey) NOT ENFORCED
);
-- 3. ItemLocation Table
DROP TABLE IF EXISTS `restaurant.itemlocation`;
CREATE TABLE `restaurant.itemlocation` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED,
-- Foreign Key Definitions
FOREIGN KEY (itemKey) REFERENCES `restaurant.item`(itemKey) NOT ENFORCED,
FOREIGN KEY (locationKey) REFERENCES `restaurant.location`(locationKey) NOT ENFORCED
);
-- 4. BOM Table
DROP TABLE IF EXISTS `restaurant.bom`;
CREATE TABLE `restaurant.bom` (
bomKey INT64,
parentItemLocation STRING,
childItemLocation STRING,
childQuantity FLOAT64,
PRIMARY KEY (bomKey) NOT ENFORCED
);
-- 5. Makes Table
DROP TABLE IF EXISTS `restaurant.makes`;
CREATE TABLE `restaurant.makes` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
DROP TABLE IF EXISTS `restaurant.stored_at`;
CREATE TABLE `restaurant.stored_at` (
itemLocationKey STRING,
itemKey STRING,
locationKey STRING,
variants INT64,
PRIMARY KEY (itemLocationKey) NOT ENFORCED
);
۴. بارگذاری دادههای نمونه
برای اینکه این آزمایشگاه کاملاً مستقل باشد، جداول را با دادههای نمونه با استفاده از دستورات SQL LOAD DATA پر خواهید کرد. این نشان دهنده شبکهای است که با یک Supplier شروع میشود، از یک مرکز توزیع (DC) و آشپزخانه فروشگاه میگذرد و به یک کافه خرده فروشی میرسد.
برای بارگذاری دادهها، کوئریهای SQL زیر را اجرا کنید:

نکته: اگر مستقیماً در bigquery studio در حال اجرا هستید، میتوانید %%bigquery را حذف کنید.
%%bigquery --project=$PROJECT_ID
-- Load Item
LOAD DATA OVERWRITE `restaurant.item`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/item2.csv'], skip_leading_rows = 1);
-- Load Location
LOAD DATA OVERWRITE `restaurant.location`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/location.csv'], skip_leading_rows = 1);
-- Load ItemLocation
LOAD DATA OVERWRITE `restaurant.itemlocation`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
-- Load BOM
LOAD DATA OVERWRITE `restaurant.bom`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/bom2.csv'], skip_leading_rows = 1);
-- Load Makes
LOAD DATA OVERWRITE `restaurant.makes`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/makes.csv'], skip_leading_rows = 1);
-- Load StoredAt
LOAD DATA OVERWRITE `restaurant.stored_at`
FROM FILES (format = 'CSV', uris = ['gs://supply_chain_demo/itemlocation.csv'], skip_leading_rows = 1);
۵. اضافه کردن محدودیتها و تعریف گراف
قبل از ساخت گراف، شما روابط معنایی را با استفاده از محدودیتهای استاندارد کلید اصلی و کلید خارجی SQL اعلام میکنید. این موارد به BigQuery در درک شناسههای گره و اتصال جداول Edge به جداول گره کمک میکنند.
ایجاد نمودار ویژگی
حالا، شما این جداول را در یک ساختار گراف منسجم به نام restaurant.bombod متحد میکنید.
شما تعریف میکنید:
- گرهها :
item،location،itemlocation - لبهها :
makes،stored_atوconsists_of(BOM)
%%bigquery --project=$PROJECT_ID
CREATE OR REPLACE PROPERTY GRAPH `restaurant.bombod`
NODE TABLES (
`restaurant.item` KEY (itemKey) LABEL item PROPERTIES ALL COLUMNS,
`restaurant.location` KEY (locationKey) LABEL location PROPERTIES ALL COLUMNS,
`restaurant.itemlocation` KEY (itemLocationKey) LABEL itemlocation PROPERTIES ALL COLUMNS
)
EDGE TABLES (
`restaurant.makes`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (itemKey) REFERENCES `restaurant.item`(itemKey)
LABEL makes PROPERTIES ALL COLUMNS,
`restaurant.bom`
KEY (bomKey)
SOURCE KEY (childItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (parentItemLocation) REFERENCES `restaurant.itemlocation`(itemLocationKey)
LABEL consists_of PROPERTIES ALL COLUMNS,
`restaurant.stored_at`
KEY (itemLocationKey)
SOURCE KEY (itemLocationKey) REFERENCES `restaurant.itemlocation`(itemLocationKey)
DESTINATION KEY (locationKey) REFERENCES `restaurant.location`(locationKey)
LABEL stored_at PROPERTIES ALL COLUMNS
);
۶. تجسم زنجیره تأمین
شما میتوانید یک کوئری پیمایش از بالا به پایین اجرا کنید تا کل شبکه زنجیره تأمین را ببینید. در یک نوتبوک استاندارد یا رابط کاربری که از آن پشتیبانی میکند (مانند %%bigquery --graph )، این یک نقشه بصری را برمیگرداند.
برای تنظیم گرهها و لبهها از پرسوجوهای مطلق گراف استفاده کنید.
توجه: همانطور که قبلاً ذکر شد، برای اجرای این کار در Google Colab یا Colab Enterprise Notebooks، میتوانید از دستورات جادویی BigQuery نیز استفاده کنید: %%bigquery همچنین برای تجسم نمودار در Google Colab یا Colab Enterprise Notebooks، پرچم –graph را به صورت زیر وارد کنید: %%bigquery –graph
%%bigquery --project=$PROJECT_ID --graph output
Graph restaurant.bombod
match p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
match q=(a)-[d:stored_at]->(e:location)
optional match z=(f)-[g:makes]-(b)
return to_json(p) as ppath, to_json(q) as qpath, to_json(z) as zpath
خروجی:

۷. مورد کاربردی ۱: ردیابی یک شکایت بالادستی
سناریو : یک مشتری از کیفیت مرغ موجود در ساندویچ خود در فروشگاه نیویورک شکایت دارد. شما باید کالای نهایی را به عقب ردیابی کنید تا مراحل مونتاژ فوری آن را ببینید.
پرس و جوی پیمایشی
پرسوجو را با استفاده از قالب پرسوجوی پیمایش گراف (Graph Traversal) اجرا کنید. این قالب به لبههای consists_of که مجموعههای پاییندست را به مواد تشکیلدهنده بالادست مرتبط میکنند، نگاه میکند.
%%bigquery --project=$PROJECT_ID --graph
GRAPH restaurant.bombod
MATCH p=(a:itemlocation)-[c:consists_of]->(b:itemlocation)
OPTIONAL MATCH q=(b)-[d:stored_at]-(e)
return to_json(p) as ppath, to_json(q) as qpath
به دلیل جهت فلش در جدول لبههای consists_of ( Ingredient -> Finished )، جستجویی که به سمت بالا جریان دارد، به سرعت لینکهایی را ارائه میدهد که مواد وابسته و مکانهای ذخیرهسازی را جدا میکنند.
خروجی: 
۸. مورد استفاده ۲: تحلیل تأثیر
سناریو : کولاک مرکز توزیع در کلمبوس، اوهایو را تعطیل کرده است. شما باید بدانید که کدام مراحل آمادهسازی یا اقلام نهایی بلافاصله تحت تأثیر قرار گرفتهاند.
پرس و جوی پیمایشی
شما از location خاصی که نمایانگر مرکز توزیع است شروع میکنید، موجودی انبار شده در آنجا را شناسایی میکنید و میبینید که چه اقلام نهایی به آنها نیاز دارند.
# @title Impact of a storm on a DC
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(z:itemlocation)-[m:stored_at]->(dc:location) where dc.locationKey like '%DC-Sysco-Columbus-OH%'
match path2=(z:itemlocation)-[c:consists_of]->(b:itemlocation)
match path3=(b:itemlocation)-[n:makes]->(item:item)
optional match path4=(b)-[p:stored_at]->(q:location)
return to_json(path1) as path1, to_json(path2) as path2,to_json(path3) as path3, to_json(path4) as path4
خروجی: 
۹. مورد استفاده ۳: فراخوانی از پاییندست
سناریو : یک تأمینکننده شما را از یک سری خاص از محصول آلوده مطلع میکند: گوجهفرنگیهای رسیده از تاکستان از تأمینکننده. شما باید تمام اقلام نهایی منوی آلوده را در کافهها پیدا کنید.
پرس و جوی پیمایشی
شما به دنبال محل مواد اولیه آلوده میگردید، سپس یک پیمایش مسیر در پاییندست انجام میدهید تا اقلام نهایی آسیبدیده را پیدا کنید.
%%bigquery --project=$PROJECT_ID --graph
Graph restaurant.bombod
match path1=(a:itemlocation)-[c:consists_of]->(b:itemlocation)-[e:makes]->(f:item) where f.itemKey like '%Tomato%'
return to_json(path1) as result
این پرسوجو تمام مواردی را که با «گوجه فرنگی» مطابقت الگو دارند، پیدا میکند و این با رابطه بالادستی در هم تنیده شده و آن را به یک نگاشت قدرتمند تبدیل میکند که برای کشف اینکه کدام اقلام کافه باید فراخوانی شوند، منتشر میشود.
خروجی: 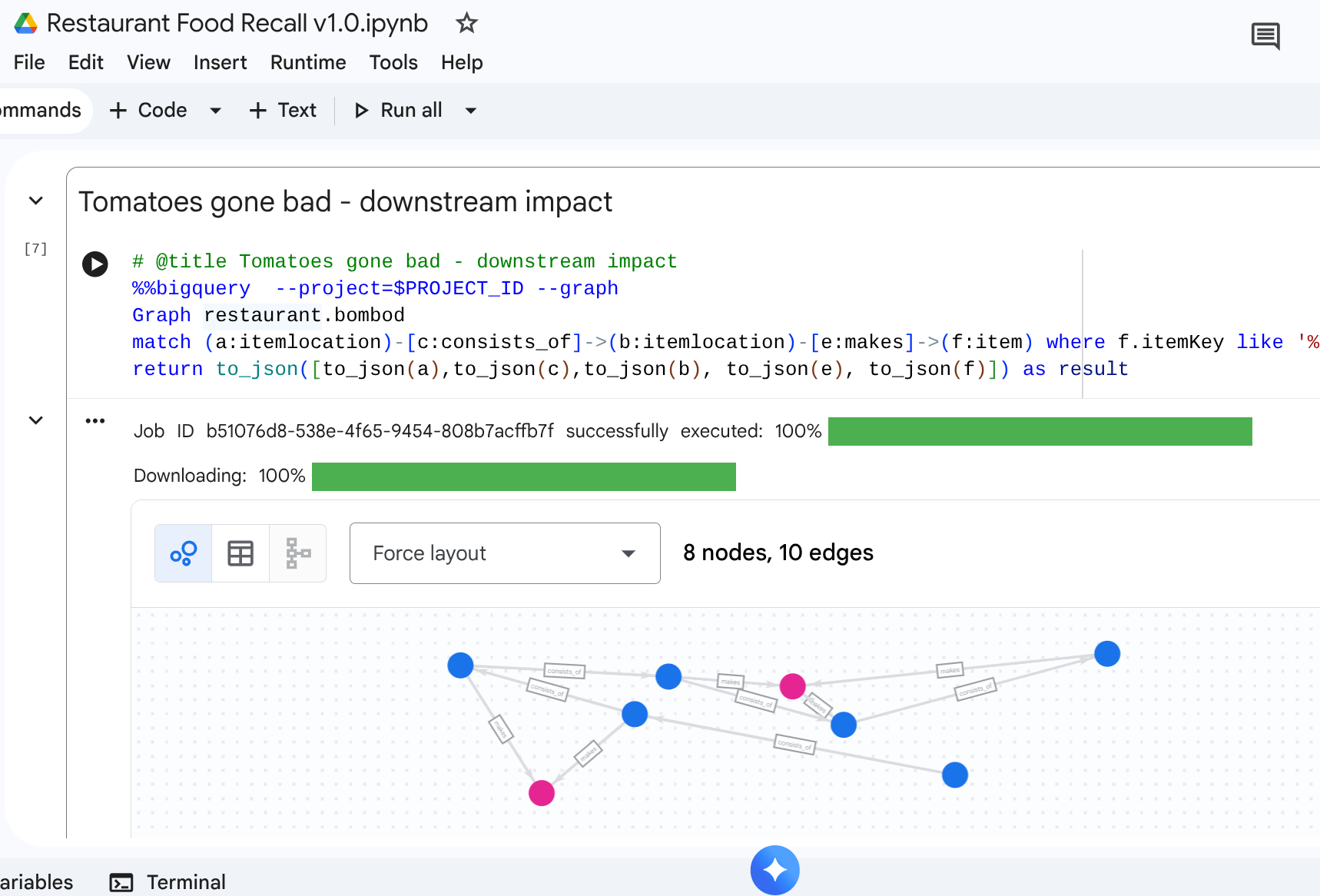
۱۰. تمیز کردن
پس از تکمیل مراحل راهنما، منابع را حذف کنید تا از هرگونه هزینه اضافی در فضای کاری خود جلوگیری کنید.
DROP SCHEMA `restaurant` CASCADE;
۱۱. نتیجهگیری
تبریک! شما یک زنجیره تأمین را مدلسازی کرده و تجزیه و تحلیل تأثیر را با استفاده از BigQuery Graph انجام دادهاید.
جمع بندی
یاد گرفتی که:
- روابط رابطهای گراف-محور را با کلیدهای اصلی/خارجی تعریف کنید.
- یک نمودار ویژگی یکپارچه ایجاد کنید.
- با استفاده از منطق پیمایش Graph Query، روابط چند گرهای را به طور کارآمد پیمایش کنید.
برای کسب اطلاعات بیشتر در مورد معماری گراف، به اسناد Google Cloud مراجعه کنید.