
1. Введение
В этом практическом занятии вы узнаете, как использовать Spanner Data Boost для запроса данных Spanner из BigQuery с помощью федеративных запросов с нулевым ETL-процессом и без влияния на базу данных Spanner.

Spanner Data Boost — это полностью управляемый бессерверный сервис, предоставляющий независимые вычислительные ресурсы для поддерживаемых рабочих нагрузок Spanner. Data Boost позволяет выполнять аналитические запросы и экспорт данных практически без влияния на существующие рабочие нагрузки на выделенном экземпляре Spanner, используя бессерверную модель использования по запросу.
В сочетании с внешними подключениями BigQuery, Data Boost позволяет легко запрашивать данные из Spanner и передавать их на вашу платформу анализа данных без сложных операций ETL-перемещения данных.
Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовые навыки работы с командной строкой и оболочкой Google.
Что вы узнаете
- Как развернуть экземпляр Spanner
- Как загрузить данные для создания базы данных Spanner
- Как получить доступ к данным Spanner из BigQuery без использования Data Boost.
- Как получить доступ к данным Spanner из BigQuery с помощью Data Boost
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
2. Настройка и требования
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .



- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:

Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть примерно следующее:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Создайте экземпляр Spanner и базу данных.
Включите API Spanner
Внутри Cloud Shell убедитесь, что идентификатор вашего проекта указан правильно:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
Установите регион по умолчанию на us-central1 . При желании вы можете изменить его на другой регион, поддерживаемый региональными настройками Spanner.
gcloud config set compute/region us-central1
Включите API Spanner:
gcloud services enable spanner.googleapis.com
Создайте экземпляр Spanner.
На этом этапе мы настраиваем наш экземпляр Spanner для выполнения практического задания. Для этого откройте Cloud Shell и выполните следующую команду:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Вывод команды:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
Создайте базу данных
После запуска экземпляра вы можете создать базу данных. Spanner позволяет использовать несколько баз данных на одном экземпляре.
В базе данных вы определяете свою схему. Вы также можете контролировать доступ к базе данных, настраивать пользовательское шифрование, конфигурировать оптимизатор и устанавливать период хранения.
Для создания базы данных снова воспользуйтесь инструментом командной строки gcloud:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Вывод команды:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. Загрузка данных
Прежде чем использовать Data Boost, вам необходимо иметь данные в базе данных. Для этого вам нужно создать сегмент Cloud Storage, загрузить в него данные Avro и запустить задание импорта Dataflow для загрузки данных Avro в Spanner.
Включить API
Для этого откройте командную строку Cloud Shell, если предыдущая была закрыта.
Обязательно включите API для вычислительных ресурсов, облачного хранилища и потоков данных.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Ожидаемый вывод в консоль:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Временный модуль импорта файлов в облачное хранилище.
Теперь создайте хранилище для файлов Avro:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
Ожидаемый вывод в консоль:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
Далее скачайте tar-архив с GitHub и распакуйте его.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
Ожидаемый вывод в консоль:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
А теперь загрузите файлы в созданное вами хранилище.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Ожидаемый вывод в консоль:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
Импорт данных
Имея файлы в облачном хранилище, вы можете запустить задачу импорта данных в Spanner с помощью потока данных.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
Ожидаемый вывод в консоль:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
Проверить статус задания импорта можно с помощью этой команды.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
Ожидаемый вывод в консоль:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Проверьте данные в Spanner.
Теперь перейдите в Spanner Studio и убедитесь, что данные там присутствуют. Сначала разверните таблицу тем, чтобы увидеть столбцы.

Теперь выполните следующий запрос, чтобы убедиться в наличии данных:
SELECT COUNT(*) FROM topics;
Ожидаемый результат:

5. Чтение данных из BigQuery
Теперь, когда у вас есть данные в Spanner, пришло время получить к ним доступ из BigQuery. Для этого вам нужно настроить внешнее подключение к Spanner в BigQuery.
Предполагая, что у вас есть необходимые права доступа, создайте внешнее соединение со Spanner, выполнив следующие шаги.
Нажмите кнопку «Добавить» в верхней части консоли BigQuery и выберите параметр «Подключения к внешним источникам данных».

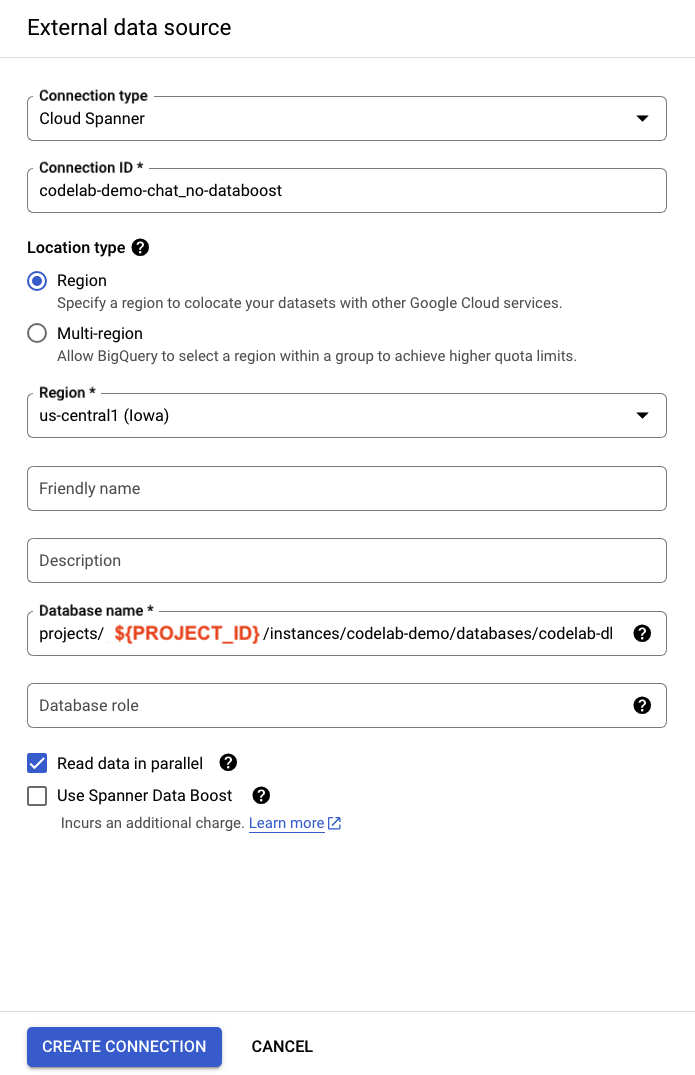
Теперь вы можете выполнить запрос для чтения данных из Spanner. Выполните этот запрос в консоли BigQuery, обязательно заменив значение ${PROJECT_ID}:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Пример выходных данных:

Информацию о задании, например, сколько времени оно заняло и какой объем данных был обработан, можно посмотреть на вкладке «Информация о задании».

Далее вам нужно будет добавить подключение Data Boost в Spanner и сравнить результаты.
6. Считывание данных с помощью Data Boost.
Для использования Spanner Data Boost необходимо создать новое внешнее подключение из BigQuery к Spanner. Нажмите «Добавить» в консоли BigQuery и снова выберите « Connections from external data sources ».
Укажите тот же URI подключения, что и для Spanner. Измените «Идентификатор подключения» и поставьте галочку в поле «Использовать ускорение передачи данных».

После создания подключения к Data Boost вы можете выполнить тот же запрос, но с новым именем подключения. Снова замените свой project_id в запросе.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Вы должны получить тот же набор результатов, что и раньше. Изменилось ли время выполнения?
7. Понимание эффективности использования данных
Spanner Data Boost позволяет использовать ресурсы, не связанные с ресурсами вашего экземпляра Spanner. Это в первую очередь снижает влияние аналитических задач на операционные задачи.
Это можно увидеть, если несколько раз в течение двух-трех минут выполнить запрос без использования Data Boost. Не забудьте заменить ${PROJECT_ID} .
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Затем подождите еще несколько минут и выполните запрос для использования Data Boost еще несколько раз. Не забудьте заменить ${PROJECT_ID} .
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Теперь вернитесь в Spanner Studio в облачной консоли и перейдите в раздел «Системная аналитика».
Здесь вы можете увидеть метрики использования ЦП. Запросы, выполняемые без Data Boost, используют ЦП для операций 'executesql_select_withpartitiontoken'. Несмотря на то, что запрос тот же, выполнение с помощью Data Boost не отображается в показателях использования ЦП вашего экземпляра.

Во многих случаях производительность аналитического запроса улучшится при использовании Data Boost. В этом руководстве используется небольшой набор данных, и нет других задач, конкурирующих за ресурсы. Поэтому данное руководство не ставит целью продемонстрировать улучшение производительности.
Не стесняйтесь экспериментировать с запросами и рабочими нагрузками и посмотрите, как работает Data Boost. Когда закончите, перейдите к следующему разделу, чтобы очистить среду.
8. Очистка окружающей среды
Если вы создали свой проект специально для этого практического занятия, вы можете просто удалить его, чтобы очистить его. Если вы хотите сохранить проект и очистить отдельные компоненты, перейдите к следующим шагам.
Удалите подключения BigQuery
Чтобы удалить оба соединения, нажмите на три точки рядом с названием соединения, выберите «Удалить», а затем следуйте инструкциям по удалению соединения.

Удалить сегмент облачного хранилища
gcloud storage rm --recursive gs://$GCS_BUCKET
Удалить экземпляр Spanner
Для очистки просто перейдите в раздел Cloud Spanner в Cloud Console и удалите экземпляр ' codelab-demo ', созданный нами в рамках учебного модуля.

9. Поздравляем!
Поздравляем с завершением практического занятия!
Что мы рассмотрели
- Как развернуть экземпляр Spanner
- Как загрузить данные в Spanner с помощью Dataflow
- Как получить доступ к данным Spanner из BigQuery
- Как использовать Spanner Data Boost, чтобы избежать негативного влияния на ваш экземпляр Spanner при выполнении аналитических запросов из BigQuery.
10. Опрос
Выход: