
1. Introdução
Neste codelab, você vai aprender a usar o Data Boost do Spanner para consultar dados do Spanner no BigQuery usando consultas federadas sem ETL e sem afetar o banco de dados do Spanner.

O Spanner Data Boost é um serviço sem servidor totalmente gerenciado que oferece recursos de computação independentes para as cargas de trabalho do Spanner compatíveis. O Data Boost permite executar consultas de análise e exportações de dados com impacto quase zero nas cargas de trabalho atuais na instância provisionada do Spanner usando um modelo de uso sem servidor sob demanda.
Quando combinado com conexões externas do BigQuery, o Data Boost permite consultar dados do Spanner na sua plataforma de análise de dados sem movimentação complexa de dados de ETL.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console
- Habilidades básicas na interface de linha de comando e no Google Shell
O que você vai aprender
- Como implantar uma instância do Spanner
- Como carregar dados para criar um banco de dados do Spanner
- Como acessar dados do Spanner no BigQuery sem o Data Boost
- Como acessar dados do Spanner no BigQuery com o Data Boost
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome
2. Configuração e requisitos
Configuração de ambiente personalizada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.


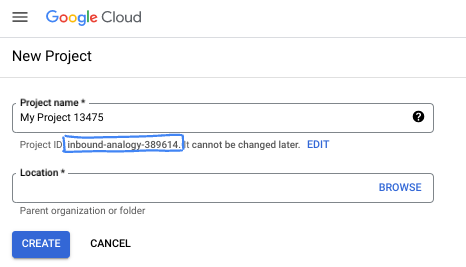
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Iniciar o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:

O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Criar uma instância e um banco de dados do Spanner
Ativar a API Spanner
No Cloud Shell, verifique se o ID do projeto está configurado:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
Configure sua região padrão como us-central1. Mude para outra região compatível com as configurações regionais do Spanner.
gcloud config set compute/region us-central1
Ative a API Spanner:
gcloud services enable spanner.googleapis.com
Criar a instância do Spanner
Nesta etapa, vamos configurar a instância do Spanner para o codelab. Para fazer isso, abra o Cloud Shell e execute este comando:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Resposta ao comando:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
Crie o banco de dados
Depois que a instância estiver em execução, você poderá criar o banco de dados. O Spanner permite vários bancos de dados em uma única instância.
O banco de dados é onde você define o esquema. Você também pode controlar quem tem acesso ao banco de dados, configurar a criptografia personalizada, configurar o otimizador e definir o período de armazenamento.
Para criar o banco de dados, use novamente a ferramenta de linha de comando gcloud:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Resposta ao comando:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. Carregar dados
Antes de usar o Data Boost, você precisa ter alguns dados no banco de dados. Para fazer isso, crie um bucket do Cloud Storage, faça upload de uma importação Avro para o bucket e inicie um job de importação do Dataflow para carregar os dados Avro no Spanner.
Ativar APIs
Para isso, abra um prompt do Cloud Shell se o anterior tiver sido fechado.
Ative as APIs Compute, Cloud Storage e Dataflow.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Saída esperada do console:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Organizar arquivos de importação no Cloud Storage
Agora, crie o bucket para armazenar os arquivos avro:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
Saída esperada do console:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
Em seguida, faça o download e extraia o arquivo tar do GitHub.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
Saída esperada do console:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
Agora faça upload dos arquivos para o bucket criado.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Saída esperada do console:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
Importar dados
Com os arquivos no Cloud Storage, é possível iniciar um job de importação do Dataflow para carregar os dados no Spanner.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
Saída esperada do console:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
É possível verificar o status do job de importação com este comando.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
Saída esperada do console:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Verificar dados no Spanner
Agora, acesse o Spanner Studio e verifique se os dados estão lá. Primeiro, expanda a tabela de tópicos para ver as colunas.

Agora, execute a consulta a seguir para garantir que os dados estejam disponíveis:
SELECT COUNT(*) FROM topics;
Saída esperada:

5. Ler dados do BigQuery
Agora que você tem dados no Spanner, é hora de acessá-los no BigQuery. Para isso, configure uma conexão externa com o Spanner no BigQuery.
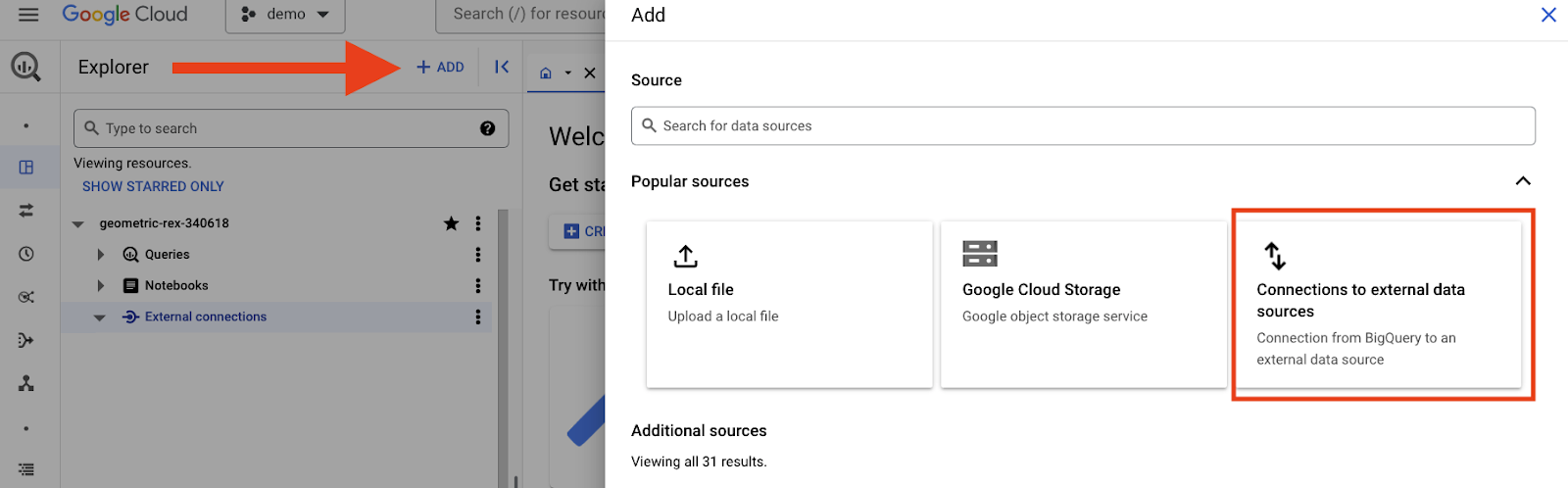
Supondo que você tenha as permissões corretas, crie uma conexão externa com o Spanner seguindo estas etapas.
Clique no botão "Adicionar" na parte de cima do console do BigQuery e selecione a opção "Conexões com fontes de dados externas".

Agora é possível executar uma consulta para ler dados do Spanner. Execute esta consulta no console do BigQuery, substituindo o valor pelo seu ${PROJECT_ID}:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Exemplo de saída:

Na guia "Informações do job", você encontra informações sobre o job, como quanto tempo ele levou para ser executado e quantos dados foram processados.

Em seguida, você vai adicionar uma conexão do Data Boost ao Spanner e comparar os resultados.
6. Ler dados usando o Data Boost
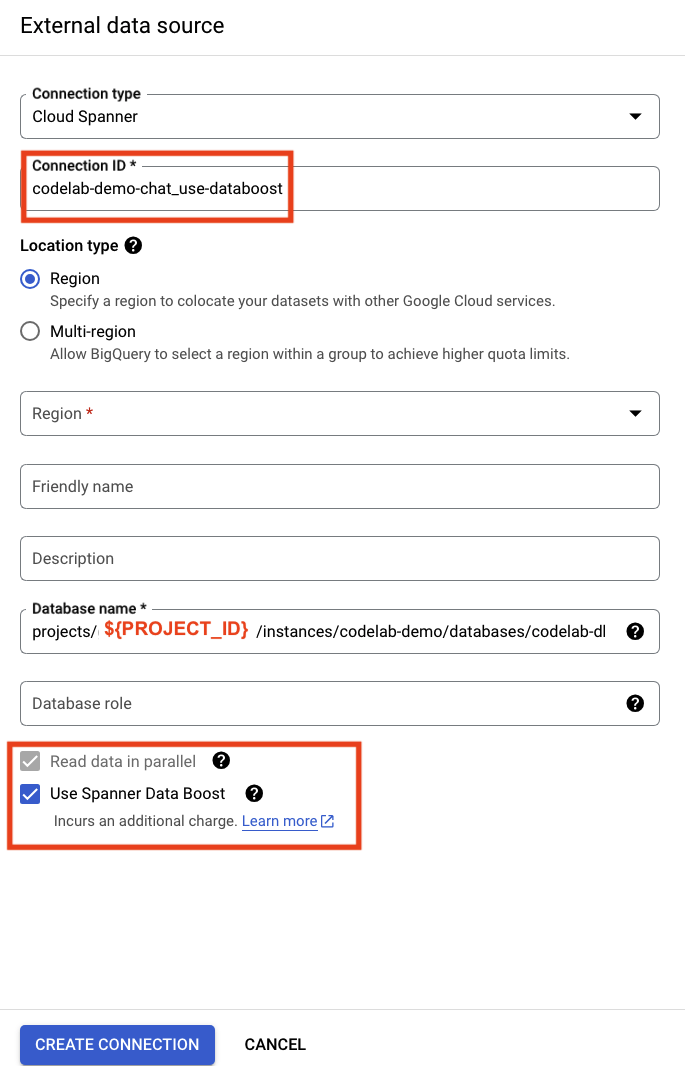
Para usar o Data Boost do Spanner, crie uma conexão externa do BigQuery para o Spanner. Clique em "Adicionar" no console do BigQuery e selecione Connections from external data sources novamente.
Preencha os detalhes com o mesmo URI de conexão com o Spanner. Mude o "ID da conexão" e marque a caixa "Usar aumento de dados".
Com a conexão do Data Boost criada, é possível executar a mesma consulta, mas com o novo nome de conexão. Substitua o project_id na consulta novamente.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Você vai receber o mesmo conjunto de resultados de antes. O horário mudou?
7. Como funciona o Data Boost
Com o Data Boost do Spanner, é possível usar recursos não relacionados aos recursos da instância do Spanner. Isso reduz principalmente o impacto das cargas de trabalho analíticas nas operacionais.
É possível ver isso se você executar a consulta para não usar o Data Boost algumas vezes em dois ou três minutos. Substitua ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Aguarde mais alguns minutos e execute a consulta para usar o Data Boost mais algumas vezes. Substitua ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Agora, volte ao Spanner Studio no console do Cloud e acesse o System Insights.

Aqui, você pode conferir as métricas da CPU. As consultas executadas sem o Data Boost usam a CPU para as operações "executesql_select_withpartitiontoken". Mesmo que a consulta seja a mesma, a execução do Data Boost não aparece na utilização da CPU da instância.

Em muitos casos, o desempenho da consulta analítica melhora ao usar o Data Boost. O conjunto de dados neste tutorial é pequeno, e não há outras cargas de trabalho disputando recursos. Portanto, este tutorial não pretende mostrar melhorias de performance.
Teste as consultas e cargas de trabalho e veja como o Data Boost funciona. Quando terminar, avance para a próxima seção para liberar espaço.
8. Limpar o ambiente
Se você criou o projeto especificamente para este codelab, basta excluí-lo para fazer a limpeza. Se você quiser manter o projeto e liberar espaço nos componentes individuais, siga as etapas abaixo.
Remover conexões do BigQuery
Para remover as duas conexões, clique nos três pontos ao lado do nome da conexão. Selecione "Excluir" e siga as instruções para excluir a conexão.

Excluir bucket do Cloud Storage
gcloud storage rm --recursive gs://$GCS_BUCKET
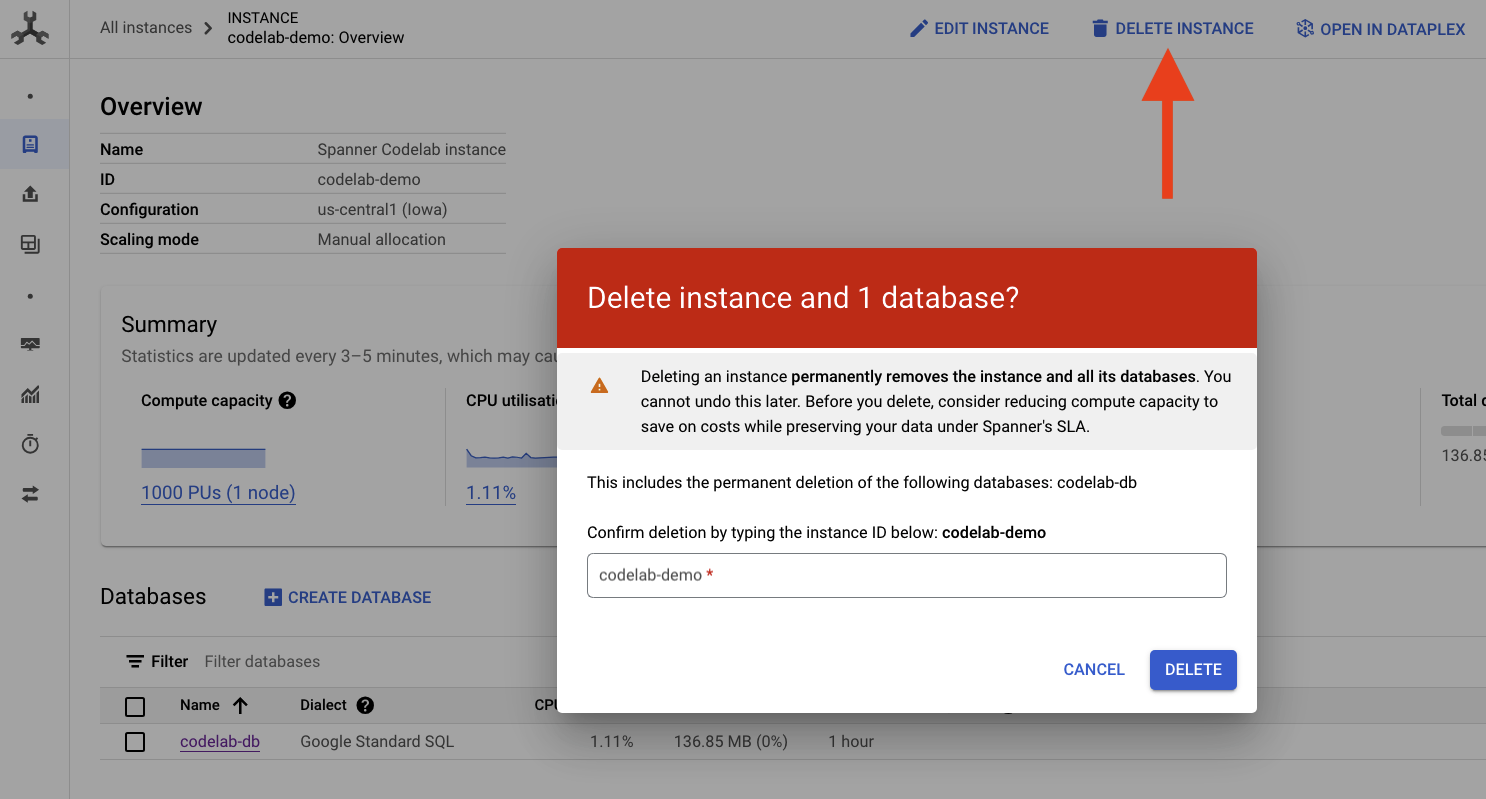
Excluir instância do Spanner
Para liberar espaço, basta acessar a seção Cloud Spanner do Console do Cloud e excluir a instância 'codelab-demo' que criamos no codelab.
9. Parabéns
Parabéns por concluir o codelab.
O que aprendemos
- Como implantar uma instância do Spanner
- Como carregar dados no Spanner usando o Dataflow
- Como acessar dados do Spanner no BigQuery
- Como usar o Data Boost do Spanner para evitar o impacto na sua instância do Spanner em consultas analíticas do BigQuery
10. Pesquisa
Saída: