
1. はじめに
この Codelab では、Spanner Data Boost を使用して、Spanner データベースに影響を与えることなく、ゼロ ETL 連携クエリを使用して BigQuery から Spanner データをクエリする方法を学びます。

Spanner Data Boost は、サポートされている Spanner ワークロード用の独立したコンピューティング リソースを提供する、フルマネージドのサーバーレス サービスです。Data Boost を使用すると、サーバーレスのオンデマンド使用モデルを使用して、プロビジョニングされた Spanner インスタンス上の既存のワークロードへの影響がほぼゼロの状態で、分析クエリとデータ エクスポートを実行できます。
BigQuery 外部接続と組み合わせることで、Data Boost を使用して、複雑な ETL データ移動を行うことなく、Spanner からデータ分析プラットフォームにデータを簡単にクエリできます。
前提条件
- Google Cloud コンソールの基本的な知識
- コマンドライン インターフェースと Google Shell の基本的なスキル
学習内容
- Spanner インスタンスをデプロイする方法
- データを読み込んで Spanner データベースを作成する方法
- Data Boost を使用せずに BigQuery から Spanner データにアクセスする方法
- Data Boost を使用して BigQuery から Spanner データにアクセスする方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
2. 設定と要件
セルフペース型の環境設定
- Google Cloud Console にログインして、プロジェクトを新規作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。

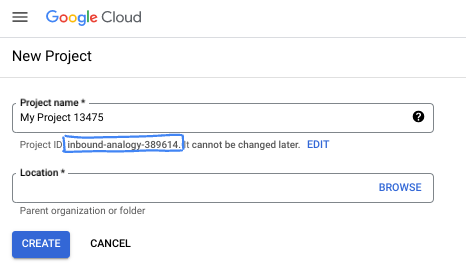
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
- 次に、Cloud のリソースや API を使用するために、Cloud コンソールで課金を有効にする必要があります。この Codelab の操作をすべて行って、費用が生じたとしても、少額です。このチュートリアルの終了後に請求が発生しないようにリソースをシャットダウンするには、作成したリソースを削除するか、プロジェクトを削除します。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。

プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. Spanner のインスタンスとデータベースを作成する
Spanner API を有効にする
Cloud Shell で、プロジェクト ID が設定されていることを確認します。
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
デフォルト リージョンを us-central1 に構成します。これは、Spanner のリージョン構成でサポートされている別のリージョンに変更できます。
gcloud config set compute/region us-central1
Spanner API を有効にします。
gcloud services enable spanner.googleapis.com
Spanner インスタンスを作成する
この手順では、Codelab 用に Spanner インスタンスを設定します。これを行うには、Cloud Shell を開いて次のコマンドを実行します。
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
コマンド出力:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
データベースを作成する
インスタンスが実行されたら、データベースを作成できます。Spanner では、1 つのインスタンスに複数のデータベースを作成できます。
データベースは、スキーマを定義する場所です。データベースにアクセスできるユーザーの制御、カスタム暗号化の設定、オプティマイザーの構成、保持期間の設定も可能です。
データベースを作成するには、もう一度 gcloud コマンドライン ツールを使用します。
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
コマンド出力:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. データを読み込む
Data Boost を使用する前に、データベースにデータが必要です。これを行うには、Cloud Storage バケットを作成し、Avro インポートをバケットにアップロードして、Dataflow インポート ジョブを開始し、Avro データを Spanner に読み込みます。
API を有効にする
これを行うには、前のプロンプトが閉じている場合は、Cloud Shell プロンプトを開きます。
Compute Engine API、Cloud Storage API、Dataflow API を有効にしてください。
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
想定されるコンソール出力:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Cloud Storage にインポート ファイルをステージングする
次に、avro ファイルを保存するバケットを作成します。
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
想定されるコンソール出力:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
次に、github から tar ファイルをダウンロードして展開します。
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
想定されるコンソール出力:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
作成したバケットにファイルをアップロードします。
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
想定されるコンソール出力:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
データをインポートする
Cloud Storage にファイルが保存されたら、データフロー インポート ジョブを開始して、データを Spanner に読み込むことができます。
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
想定されるコンソール出力:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
このコマンドを使用して、インポート ジョブのステータスを確認できます。
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
想定されるコンソール出力:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Spanner でデータを確認する
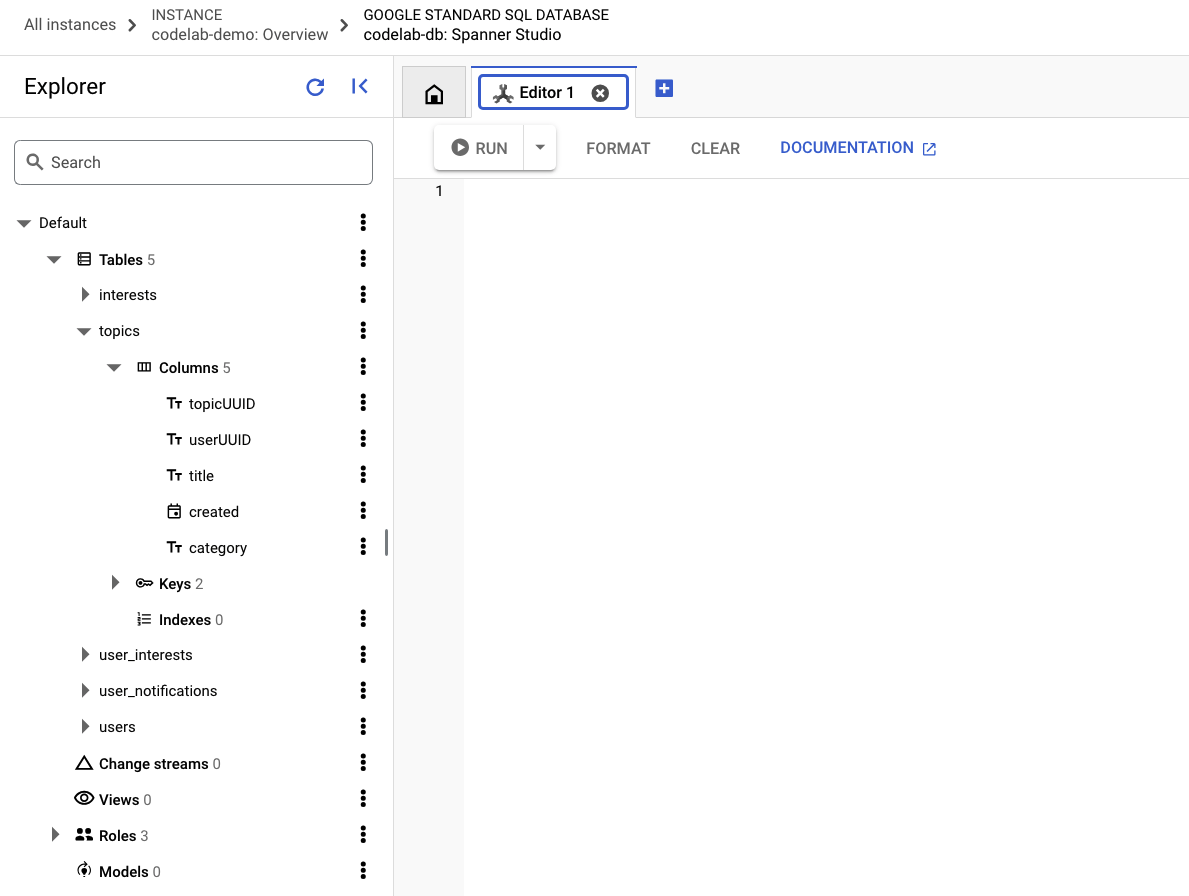
次に、Spanner Studio に移動して、データが存在することを確認します。まず、トピック テーブルを開いて列を表示します。
次に、次のクエリを実行して、データが利用可能であることを確認します。
SELECT COUNT(*) FROM topics;
予想される出力:

5. BigQuery からデータを読み取る
Spanner にデータが格納されたので、BigQuery 内からデータにアクセスします。これを行うには、BigQuery で Spanner への外部接続を設定します。
適切な権限があることを前提として、次の手順で Spanner への外部接続を作成します。
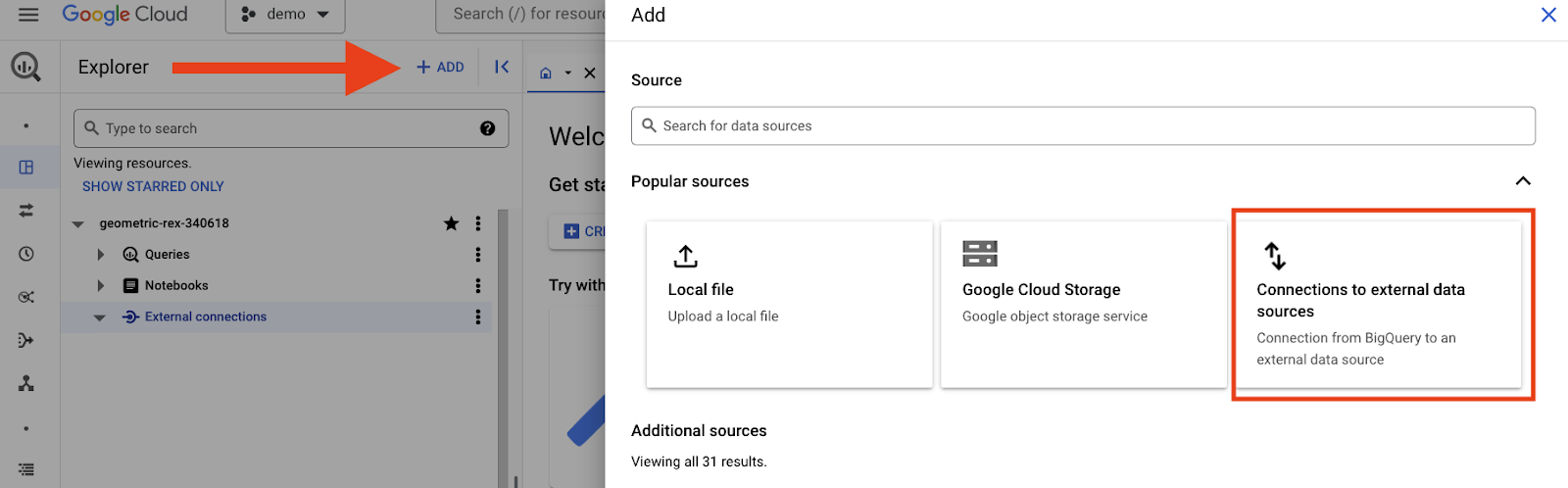
BigQuery コンソールの上部にある [追加] ボタンをクリックし、[外部データソースへの接続] オプションを選択します。

これで、クエリを実行して Spanner からデータを読み取ることができます。BigQuery コンソールで次のクエリを実行します。必ず ${PROJECT_ID} の値を置き換えてください。
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
出力例:

[ジョブ情報] タブで、ジョブの実行時間や処理されたデータ量などの情報を確認できます。
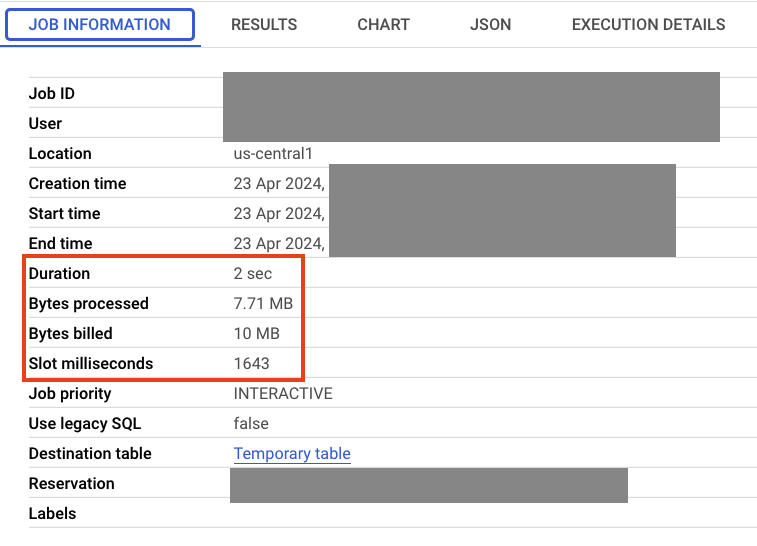
次に、Spanner に Data Boost 接続を追加し、結果を比較します。
6. Data Boost を使用してデータを読み取る
Spanner Data Boost を使用するには、BigQuery から Spanner への新しい外部接続を作成する必要があります。BigQuery コンソールで [追加] をクリックし、もう一度 [Connections from external data sources] を選択します。
Spanner への接続 URI と同じ詳細情報を入力します。[Connection ID] を変更し、[use data boost] チェックボックスをオンにします。

Data Boost 接続が作成されたら、同じクエリを新しい接続名で実行できます。ここでも、クエリ内の project_id を置き換えます。
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
前と同じ結果セットが返されます。タイミングが変わりましたか?
7. Data Boost について
Spanner Data Boost を使用すると、Spanner インスタンスのリソースに関連しないリソースを使用できます。これにより、分析ワークロードが運用ワークロードに与える影響を軽減できます。
この状態は、Data Boost を使用しないクエリを 2 ~ 3 分間に数回実行すると確認できます。${PROJECT_ID} は置き換えてください。
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
数分待ってから、クエリを実行して Data Boost を数回使用します。${PROJECT_ID} は置き換えてください。
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Cloud Console の Spanner Studio に戻り、[システム分析情報] に移動します。

ここでは、CPU 指標を確認できます。Data Boost を使用せずに実行されるクエリは、executesql_select_withpartitiontoken オペレーションに CPU を使用しています。クエリは同じでも、Data Boost の実行はインスタンスの CPU 使用率に表示されません。

多くの場合、Data Boost を使用すると分析クエリのパフォーマンスが向上します。このチュートリアルのデータセットは小さく、リソースを競合する他のワークロードはありません。そのため、このチュートリアルではパフォーマンスの改善は期待できません。
クエリとワークロードを自由に試して、Data Boost の仕組みを確認してください。完了したら、次のセクションに進んで環境をクリーンアップします。
8. 環境をクリーンアップする
この Codelab 専用にプロジェクトを作成した場合は、プロジェクトを削除するだけでクリーンアップできます。プロジェクトを保持し、個々のコンポーネントをクリーンアップする場合は、次の手順に進みます。
BigQuery 接続を削除する
両方の接続を削除するには、接続名の横にあるその他アイコンをクリックします。[削除] を選択し、手順に沿って接続を削除します。

Cloud Storage バケットを削除する
gcloud storage rm --recursive gs://$GCS_BUCKET
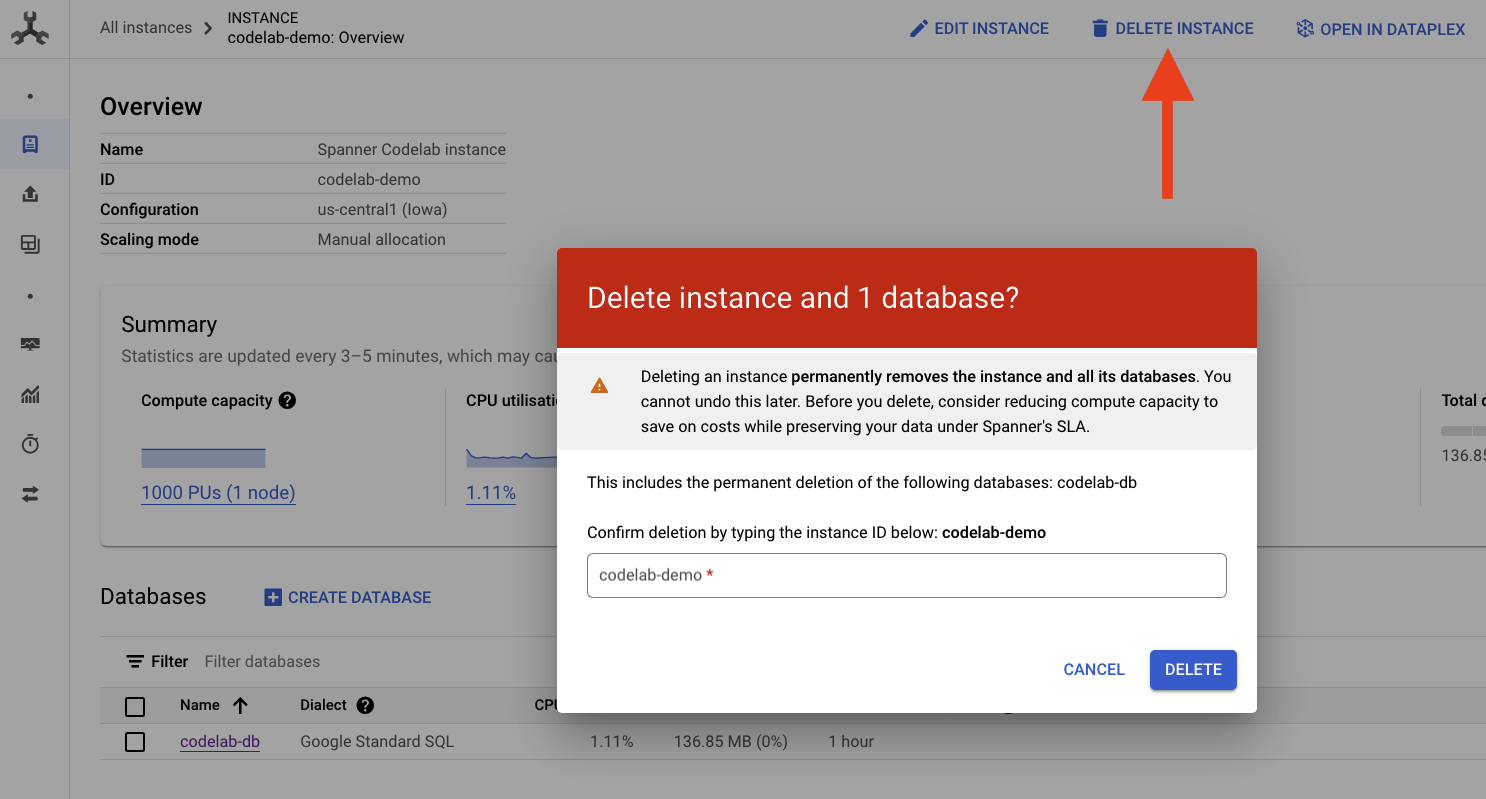
Spanner インスタンスを削除
クリーンアップするには、Cloud Console の Cloud Spanner セクションに移動して、Codelab で作成した「codelab-demo」インスタンスを削除します。
9. 完了
以上で、この Codelab は完了です。
学習した内容
- Spanner インスタンスをデプロイする方法
- Dataflow を使用して Spanner にデータを読み込む方法
- BigQuery から Spanner データにアクセスする方法
- Spanner Data Boost を使用して、BigQuery からの分析クエリによる Spanner インスタンスへの影響を回避する方法
10. アンケート
出力: