
1. Introduzione
In questo codelab imparerai a utilizzare Spanner Data Boost per eseguire query sui dati di Spanner da BigQuery utilizzando query federate zero-ETL e senza influire sul database Spanner.

Spanner Data Boost è un servizio serverless completamente gestito che fornisce risorse di calcolo indipendenti per i carichi di lavoro Spanner supportati. Data Boost consente di eseguire query di analisi ed esportazioni di dati con un impatto quasi nullo sui carichi di lavoro esistenti nell'istanza Spanner di cui è stato eseguito il provisioning utilizzando un modello di utilizzo serverless on demand.
Se abbinato alle connessioni esterne BigQuery, Data Boost ti consente di eseguire facilmente query sui dati da Spanner nella tua piattaforma di analisi dei dati senza complessi spostamenti di dati ETL.
Prerequisiti
- Una conoscenza di base di Google Cloud Console
- Competenze di base nell'interfaccia a riga di comando e nella shell Google
Obiettivi didattici
- Come eseguire il deployment di un'istanza Spanner
- Come caricare i dati per creare un database Spanner
- Come accedere ai dati Spanner da BigQuery senza Data Boost
- Come accedere ai dati di Spanner da BigQuery con Data Boost
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.


- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Crea un'istanza e un database Spanner
Abilita l'API Spanner
In Cloud Shell, assicurati che l'ID progetto sia configurato:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
Configura la regione predefinita su us-central1. Puoi modificarla con un'altra regione supportata dalle configurazioni regionali di Spanner.
gcloud config set compute/region us-central1
Abilita l'API Spanner:
gcloud services enable spanner.googleapis.com
Crea l'istanza Spanner
In questo passaggio configuriamo l'istanza Spanner per il codelab. Per farlo, apri Cloud Shell ed esegui questo comando:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Output comando:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
Crea il database
Una volta che l'istanza è in esecuzione, puoi creare il database. Spanner consente più database su una singola istanza.
Il database è il luogo in cui definisci lo schema. Puoi anche controllare chi ha accesso al database, configurare la crittografia personalizzata, configurare l'ottimizzatore e impostare il periodo di conservazione.
Per creare il database, utilizza di nuovo lo strumento a riga di comando gcloud:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Output comando:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. Carica dati
Prima di poter utilizzare Data Boost, devi disporre di alcuni dati nel database. Per farlo, devi creare un bucket Cloud Storage, caricare un'importazione Avro nel bucket e avviare un job di importazione Dataflow per caricare i dati Avro in Spanner.
Abilita API
Per farlo, apri un prompt di Cloud Shell se quello precedente è stato chiuso.
Assicurati di abilitare le API Compute, Cloud Storage e Dataflow.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Output console previsto:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Organizzare i file di importazione su Cloud Storage
Ora crea il bucket per archiviare i file Avro:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
Output console previsto:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
Poi scarica il file tar da GitHub ed estrailo.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
Output console previsto:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
Ora carica i file nel bucket che hai creato.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Output console previsto:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
Importa dati
Con i file in Cloud Storage, puoi avviare un job di importazione Dataflow per caricare i dati in Spanner.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
Output console previsto:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
Puoi controllare lo stato del job di importazione con questo comando.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
Output console previsto:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Verifica i dati in Spanner
Ora vai a Spanner Studio e assicurati che i dati siano presenti. Innanzitutto, espandi la tabella degli argomenti per visualizzare le colonne.

Ora esegui la seguente query per assicurarti che i dati siano disponibili:
SELECT COUNT(*) FROM topics;
Output previsto:

5. Leggere i dati da BigQuery
Ora che hai i dati in Spanner, è il momento di accedervi da BigQuery. Per farlo, devi configurare una connessione esterna a Spanner in BigQuery.
Supponendo di disporre delle autorizzazioni corrette, crea una connessione esterna a Spanner seguendo questi passaggi.
Fai clic sul pulsante "Aggiungi" nella parte superiore della console BigQuery e seleziona l'opzione "Connessioni a origini dati esterne".


Ora puoi eseguire una query per leggere i dati da Spanner. Esegui questa query nella console BigQuery, assicurandoti di sostituire il valore di ${PROJECT_ID}:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Output di esempio:

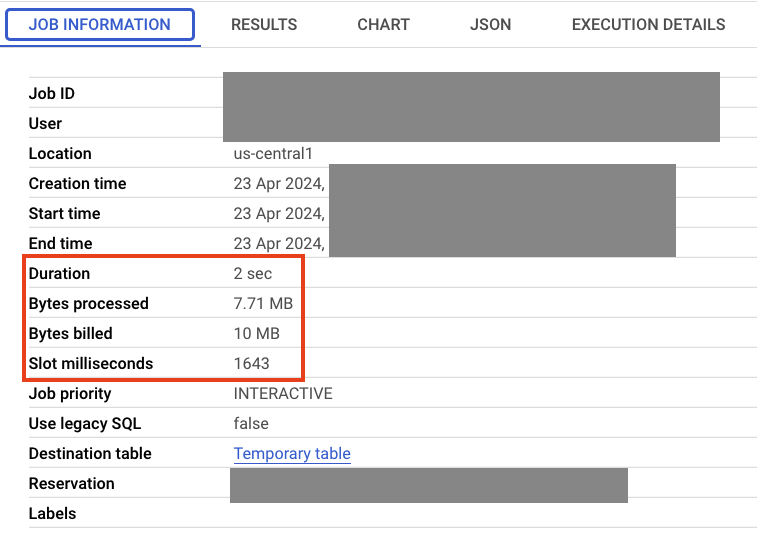
Nella scheda "Informazioni job" puoi visualizzare informazioni sul job, ad esempio la durata dell'esecuzione e la quantità di dati elaborati.
A questo punto, aggiungerai una connessione Data Boost a Spanner e confronterai i risultati.
6. Lettura dei dati utilizzando Data Boost
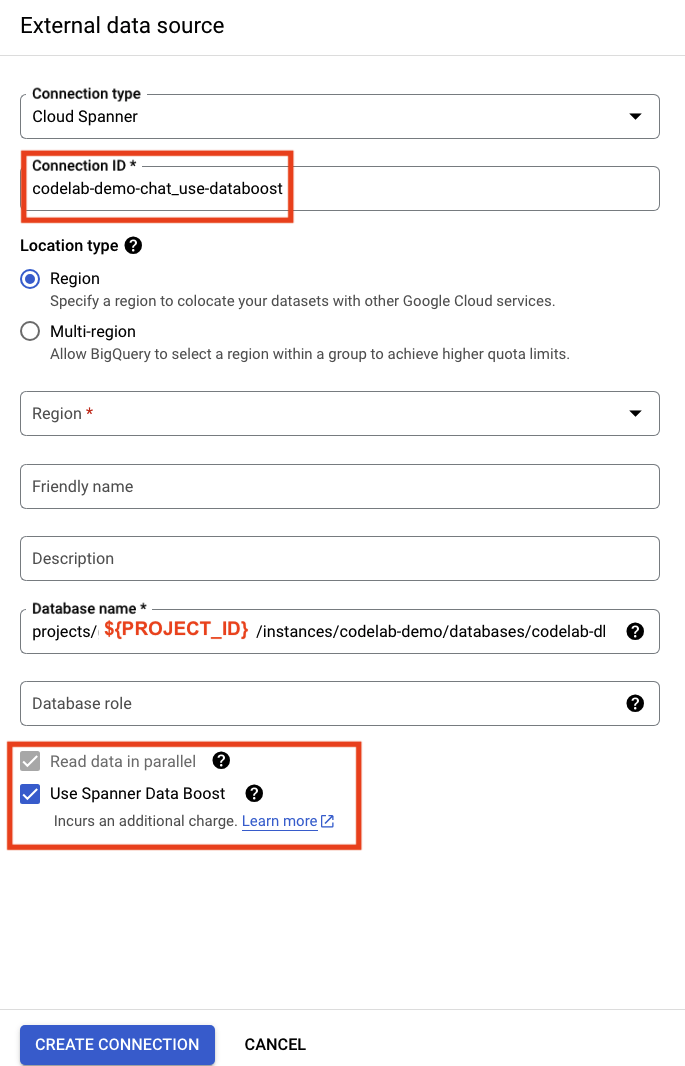
Per utilizzare Spanner Data Boost, devi creare una nuova connessione esterna da BigQuery a Spanner. Fai clic su "Aggiungi" nella console BigQuery e seleziona di nuovo "Connections from external data sources".
Compila i dettagli con lo stesso URI di connessione a Spanner. Modifica "ID connessione" e seleziona la casella "Usa Data Boost".
Con la connessione Data Boost creata, puoi eseguire la stessa query, ma con il nuovo nome della connessione. Anche in questo caso, sostituisci project_id nella query.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Dovresti ottenere lo stesso insieme di risultati di prima. La tempistica è cambiata?
7. Informazioni su Data Boost
Spanner Data Boost ti consente di utilizzare risorse non correlate alle risorse dell'istanza Spanner. In questo modo si riduce principalmente l'impatto dei carichi di lavoro analitici su quelli operativi.
Puoi visualizzarlo se esegui la query per non utilizzare Data Boost più volte in due o tre minuti. Ricordati di sostituire ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Poi, attendi qualche altro minuto ed esegui la query per utilizzare Data Boost altre volte. Ricordati di sostituire ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Ora torna a Spanner Studio nella console Cloud e vai a System Insights.

Qui puoi vedere le metriche della CPU. Le query eseguite senza Data Boost utilizzano la CPU per le operazioni "executesql_select_withpartitiontoken". Anche se la query è la stessa, l'esecuzione di Data Boost non viene visualizzata nell'utilizzo della CPU dell'istanza.

In molti casi, le prestazioni della query analitica migliorano quando si utilizza Data Boost. Il set di dati in questo tutorial è piccolo e non ci sono altri workload in competizione per le risorse. Pertanto, questo tutorial non prevede di mostrare miglioramenti del rendimento.
Non esitare a sperimentare con le query e i workload e a scoprire come funziona Data Boost. Al termine, passa alla sezione successiva per liberare spazio nell'ambiente.
8. Pulizia dell'ambiente
Se hai creato il progetto appositamente per questo codelab, puoi semplicemente eliminarlo per eseguire la pulizia. Se vuoi conservare il progetto e liberare spazio nei singoli componenti, segui questi passaggi.
Rimuovere le connessioni BigQuery
Per rimuovere entrambe le connessioni, fai clic sui tre puntini accanto al nome della connessione. Seleziona "Elimina", quindi segui le istruzioni per eliminare il collegamento.

Elimina il bucket Cloud Storage
gcloud storage rm --recursive gs://$GCS_BUCKET
Elimina istanza Spanner
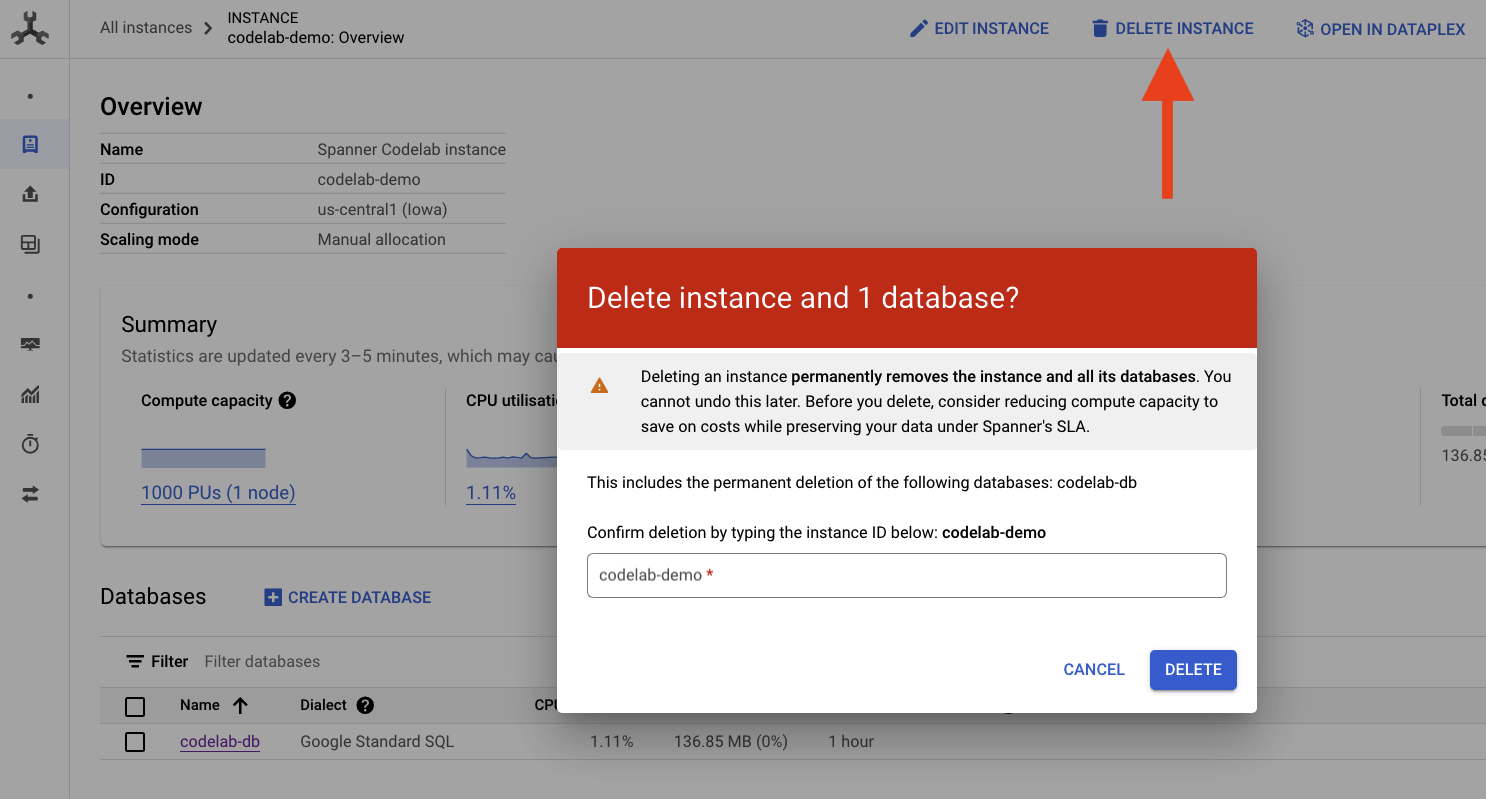
Per eseguire la pulizia, vai alla sezione Cloud Spanner della console Google Cloud ed elimina l'istanza "codelab-demo" che abbiamo creato nel codelab.
9. Complimenti
Congratulazioni per aver completato il codelab.
Argomenti trattati
- Come eseguire il deployment di un'istanza Spanner
- Come caricare dati in Spanner utilizzando Dataflow
- Come accedere ai dati di Spanner da BigQuery
- Come utilizzare Spanner Data Boost per evitare l'impatto sull'istanza Spanner per le query analitiche da BigQuery
10. Sondaggio
Output: