
1. परिचय
इस कोडलैब में, आपको यह जानने को मिलेगा कि Spanner Data Boost का इस्तेमाल कैसे किया जाता है. इसकी मदद से, BigQuery से Spanner डेटा को क्वेरी किया जा सकता है. इसके लिए, आपको ज़ीरो-ईटीएल फ़ेडरेटेड क्वेरी का इस्तेमाल करना होगा. साथ ही, इससे Spanner डेटाबेस पर कोई असर नहीं पड़ेगा.

Spanner Data Boost, पूरी तरह से मैनेज की जाने वाली सर्वरलेस सेवा है. यह Spanner के साथ काम करने वाले वर्कलोड के लिए, स्वतंत्र कंप्यूट रिसॉर्स उपलब्ध कराती है. डेटा बूस्ट की मदद से, विश्लेषण से जुड़ी क्वेरी और डेटा एक्सपोर्ट किया जा सकता है. इससे, स्पैनर के उपलब्ध कराए गए इंस्टेंस पर मौजूदा वर्कलोड पर कोई असर नहीं पड़ता. इसके लिए, सर्वरलेस ऑन-डिमांड इस्तेमाल मॉडल का इस्तेमाल किया जाता है.
BigQuery के बाहरी कनेक्शन के साथ इस्तेमाल करने पर, डेटा बूस्ट की मदद से Spanner से डेटा को आसानी से क्वेरी किया जा सकता है. इसके लिए, आपको जटिल ईटीएल डेटा ट्रांसफ़र करने की ज़रूरत नहीं होती.
ज़रूरी शर्तें
- Google Cloud Console की बुनियादी जानकारी
- कमांड-लाइन इंटरफ़ेस और Google Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- Spanner इंस्टेंस को डिप्लॉय करने का तरीका
- Spanner डेटाबेस बनाने के लिए डेटा लोड करने का तरीका
- डेटा बूस्ट की सुविधा के बिना, BigQuery से Spanner डेटा को कैसे ऐक्सेस करें
- डेटा बूस्ट की मदद से, BigQuery से Spanner डेटा को ऐक्सेस करने का तरीका
आपको किन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- कोई वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
अपनी स्पीड से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.


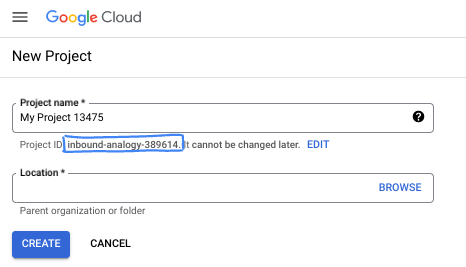
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा. वे इसे मुफ़्त में आज़मा सकते हैं.
Cloud Shell शुरू करना
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:

इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, यह Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. Spanner इंस्टेंस और डेटाबेस बनाना
Spanner API को चालू करना
Cloud Shell में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
अपनी डिफ़ॉल्ट जगह को us-central1 पर सेट करें. इसे Spanner के क्षेत्रीय कॉन्फ़िगरेशन के हिसाब से, किसी दूसरे क्षेत्र में बदला जा सकता है.
gcloud config set compute/region us-central1
Spanner API चालू करें:
gcloud services enable spanner.googleapis.com
Spanner इंस्टेंस बनाना
इस चरण में, हम कोडलैब के लिए Spanner इंस्टेंस सेट अप करते हैं. इसके लिए, Cloud Shell खोलें और यह निर्देश चलाएं:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
कमांड का आउटपुट:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
डेटाबेस बनाना
आपका इंस्टेंस चालू होने के बाद, डेटाबेस बनाया जा सकता है. Spanner में, एक इंस्टेंस पर कई डेटाबेस बनाए जा सकते हैं.
डेटाबेस में ही स्कीमा तय किया जाता है. आपके पास यह कंट्रोल करने का विकल्प भी होता है कि डेटाबेस को कौन ऐक्सेस कर सकता है. साथ ही, कस्टम एन्क्रिप्शन सेट अप करने, ऑप्टिमाइज़र को कॉन्फ़िगर करने, और डेटा सुरक्षित रखने की अवधि सेट करने का विकल्प भी होता है.
डेटाबेस बनाने के लिए, gcloud कमांड लाइन टूल का फिर से इस्तेमाल करें:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
कमांड का आउटपुट:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. डेटा लोड करें
डेटा बूस्ट का इस्तेमाल करने से पहले, आपके डेटाबेस में कुछ डेटा होना चाहिए. इसके लिए, आपको Cloud Storage बकेट बनानी होगी. इसके बाद, बकेट में avro इंपोर्ट अपलोड करना होगा. इसके बाद, Spanner में Avro डेटा लोड करने के लिए, Dataflow इंपोर्ट जॉब शुरू करना होगा.
एपीआई चालू करें
इसके लिए, अगर पिछला Cloud Shell प्रॉम्प्ट बंद हो गया है, तो उसे फिर से खोलें.
पक्का करें कि Compute, Cloud Storage, और Dataflow API चालू हों.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
कंसोल का अनुमानित आउटपुट:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Cloud Storage पर इंपोर्ट की जाने वाली फ़ाइलों को स्टेज करना
अब, avro फ़ाइलों को सेव करने के लिए बकेट बनाएं:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
कंसोल का अनुमानित आउटपुट:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
इसके बाद, github से tar फ़ाइल डाउनलोड करें और उसे एक्सट्रैक्ट करें.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
कंसोल का अनुमानित आउटपुट:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
अब बनाई गई बकेट में फ़ाइलें अपलोड करें.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
कंसोल का अनुमानित आउटपुट:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
इंपोर्ट डेटा
Cloud Storage में मौजूद फ़ाइलों की मदद से, Spanner में डेटा लोड करने के लिए डेटाफ़्लो इंपोर्ट जॉब शुरू की जा सकती है.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
कंसोल का अनुमानित आउटपुट:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
इस कमांड की मदद से, इंपोर्ट किए जा रहे डेटा की स्थिति देखी जा सकती है.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
कंसोल का अनुमानित आउटपुट:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Spanner में डेटा की पुष्टि करना
अब Spanner Studio पर जाएं और पक्का करें कि डेटा मौजूद है. कॉलम देखने के लिए, सबसे पहले विषयों की टेबल को बड़ा करें.
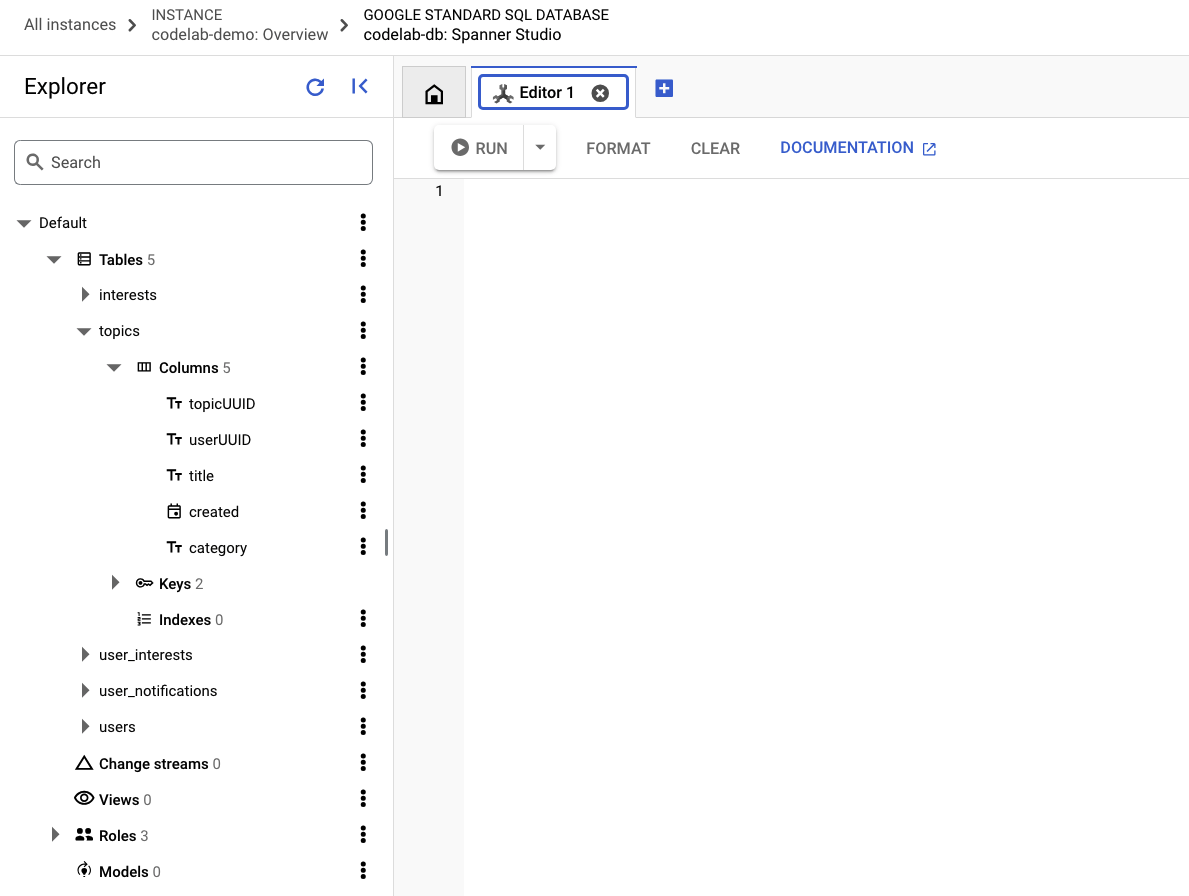
अब यह क्वेरी चलाकर देखें कि डेटा उपलब्ध है या नहीं:
SELECT COUNT(*) FROM topics;
अनुमानित आउटपुट:

5. BigQuery से डेटा पढ़ना
अब आपके पास Spanner में डेटा है. अब इसे BigQuery से ऐक्सेस करने का समय है. इसके लिए, आपको BigQuery में Spanner से बाहरी कनेक्शन सेट अप करना होगा.
मान लें कि आपके पास ज़रूरी अनुमतियां हैं. इसके बाद, यहां दिया गया तरीका अपनाकर Spanner से बाहरी कनेक्शन बनाएं.
BigQuery कंसोल में सबसे ऊपर मौजूद, ‘जोड़ें' बटन पर क्लिक करें. इसके बाद, ‘बाहरी डेटा सोर्स से कनेक्शन' विकल्प चुनें.
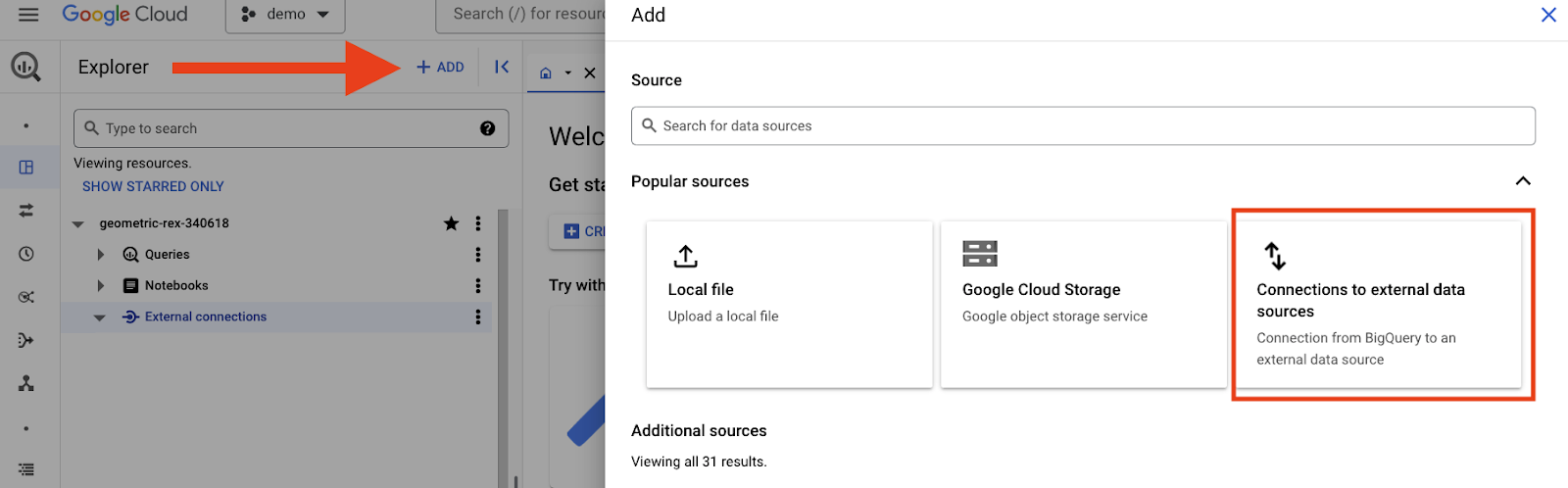

अब Spanner से डेटा पढ़ने के लिए क्वेरी चलाई जा सकती है. इस क्वेरी को BigQuery कंसोल में चलाएं. साथ ही, पक्का करें कि आपने ${PROJECT_ID} की वैल्यू बदल दी हो:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
आउटपुट का उदाहरण:

आपको जॉब के बारे में जानकारी दिख सकती है. जैसे, इसे पूरा होने में कितना समय लगा और इसमें कितना डेटा प्रोसेस किया गया. यह जानकारी, ‘जॉब की जानकारी' टैब में दिखती है.

इसके बाद, Spanner में डेटा बूस्ट कनेक्शन जोड़ा जाएगा और नतीजों की तुलना की जाएगी.
6. डेटा बूस्ट का इस्तेमाल करके डेटा पढ़ना
Spanner Data Boost का इस्तेमाल करने के लिए, आपको BigQuery से Spanner तक एक नया बाहरी कनेक्शन बनाना होगा. BigQuery कंसोल में ‘जोड़ें' पर क्लिक करें और फिर से ‘Connections from external data sources' चुनें.
Spanner से कनेक्ट करने के लिए, एक ही कनेक्शन यूआरआई का इस्तेमाल करके जानकारी भरें. ‘कनेक्शन आईडी' बदलें और ‘डेटा बूस्ट का इस्तेमाल करें' बॉक्स पर सही का निशान लगाएं.

डेटा बूस्ट कनेक्शन बन जाने के बाद, उसी क्वेरी को नए कनेक्शन के नाम के साथ चलाया जा सकता है. क्वेरी में, project_id की जगह अपना प्रोजेक्ट आईडी डालें.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
आपको पहले जैसा ही नतीजा मिलेगा. क्या समय में बदलाव हुआ है?
7. डेटा बूस्ट को समझना
Spanner Data Boost की मदद से, Spanner इंस्टेंस के संसाधनों से जुड़े नहीं हैं. इससे, आपके ऑपरेशनल वर्कलोड पर, आपके ऐनलिटिकल वर्कलोड का असर कम हो जाता है.
अगर दो या तीन मिनट में कुछ बार, डेटा बूस्ट का इस्तेमाल न करने के लिए क्वेरी चलाई जाती है, तो आपको यह मैसेज दिख सकता है. ${PROJECT_ID} को बदलना न भूलें.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
इसके बाद, कुछ और मिनट इंतज़ार करें और क्वेरी चलाकर, डेटा बूस्ट का इस्तेमाल कुछ और बार करें. ${PROJECT_ID} को बदलना न भूलें.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
अब Cloud Console में Spanner Studio पर वापस जाएं और सिस्टम की अहम जानकारी पर जाएं

यहां सीपीयू की मेट्रिक देखी जा सकती हैं. डेटा बूस्ट के बिना चलाई गई क्वेरी, ‘executesql_select_withpartitiontoken' कार्रवाइयों के लिए सीपीयू का इस्तेमाल कर रही हैं. क्वेरी एक ही होने के बावजूद, डेटा बूस्ट के एक्ज़ीक्यूशन से आपके इंस्टेंस के सीपीयू इस्तेमाल पर कोई असर नहीं पड़ता.

ज़्यादातर मामलों में, डेटा बूस्ट का इस्तेमाल करने पर, विश्लेषण से जुड़ी क्वेरी की परफ़ॉर्मेंस बेहतर हो जाएगी. इस ट्यूटोरियल में इस्तेमाल किया गया डेटा सेट छोटा है. साथ ही, संसाधनों के लिए कोई अन्य वर्कलोड नहीं है. इसलिए, इस ट्यूटोरियल में परफ़ॉर्मेंस में हुए सुधारों को नहीं दिखाया गया है.
क्वेरी और वर्कलोड के साथ एक्सपेरिमेंट करें और देखें कि डेटा बूस्ट कैसे काम करता है. इसके बाद, एनवायरमेंट को क्लीन अप करने के लिए अगले सेक्शन पर जाएं.
8. एनवायरमेंट को साफ़ करना
अगर आपने इस कोडलैब के लिए खास तौर पर अपना प्रोजेक्ट बनाया है, तो इसे मिटाकर साफ़ किया जा सकता है. अगर आपको प्रोजेक्ट को बनाए रखना है और अलग-अलग कॉम्पोनेंट को हटाना है, तो यह तरीका अपनाएं.
BigQuery कनेक्शन हटाना
दोनों कनेक्शन हटाने के लिए, कनेक्शन के नाम के बगल में मौजूद तीन बिंदुओं पर क्लिक करें. ‘मिटाएं' को चुनें. इसके बाद, कनेक्शन मिटाने के लिए दिए गए निर्देशों का पालन करें.

Cloud Storage बकेट मिटाना
gcloud storage rm --recursive gs://$GCS_BUCKET
Spanner इंस्टेंस मिटाना
क्लीन अप करने के लिए, Cloud Console के Cloud Spanner सेक्शन में जाएं. इसके बाद, कोडलैब में बनाया गया ‘codelab-demo' इंस्टेंस मिटाएं.

9. बधाई हो
कोडलैब पूरा करने के लिए बधाई.
हमने क्या-क्या कवर किया है
- Spanner इंस्टेंस को डिप्लॉय करने का तरीका
- Dataflow का इस्तेमाल करके, Spanner में डेटा लोड करने का तरीका
- BigQuery से Spanner डेटा ऐक्सेस करने का तरीका
- BigQuery से मिलने वाली विश्लेषण क्वेरी की वजह से, Spanner इंस्टेंस पर पड़ने वाले असर से बचने के लिए, Spanner Data Boost का इस्तेमाल कैसे करें
10. सर्वे
आउटपुट: