
۱. مقدمه
در این آزمایشگاه کد، یاد خواهید گرفت که چگونه از Spanner Data Boost برای کوئری گرفتن از دادههای Spanner از BigQuery با استفاده از کوئریهای فدرال بدون ETL و بدون تأثیر بر پایگاه داده Spanner استفاده کنید.

Spanner Data Boost یک سرویس کاملاً مدیریتشده و بدون سرور است که منابع محاسباتی مستقلی را برای بارهای کاری پشتیبانیشدهی Spanner فراهم میکند. Data Boost به شما امکان میدهد تا با استفاده از یک مدل استفادهی بدون سرور و بر اساس تقاضا، کوئریهای تحلیلی و خروجیهای داده را با تأثیر تقریباً صفر بر بارهای کاری موجود در نمونهی Spanner ارائهشده اجرا کنید.
وقتی Data Boost با اتصالات خارجی BigQuery جفت شود، به شما این امکان را میدهد که به راحتی دادهها را از Spanner به پلتفرم تحلیل داده خود، بدون جابجایی پیچیده دادههای ETL، کوئری کنید.
پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- مهارتهای پایه در رابط خط فرمان و پوسته گوگل
آنچه یاد خواهید گرفت
- نحوه استقرار یک نمونه Spanner
- نحوه بارگذاری دادهها برای ایجاد یک پایگاه داده Spanner
- نحوه دسترسی به دادههای Spanner از BigQuery بدون Data Boost
- نحوه دسترسی به دادههای Spanner از BigQuery با Data Boost
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .


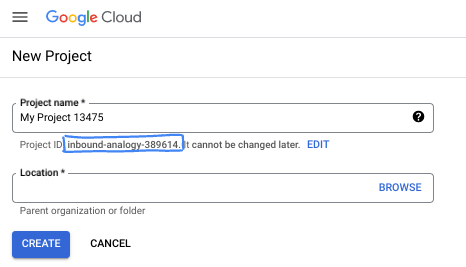
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:

آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. یک نمونه و پایگاه داده Spanner ایجاد کنید
فعال کردن Spanner API
در داخل Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
منطقه پیشفرض خود را روی us-central1 پیکربندی کنید. میتوانید این را به منطقه دیگری که توسط تنظیمات منطقهای Spanner پشتیبانی میشود، تغییر دهید.
gcloud config set compute/region us-central1
فعال کردن Spanner API:
gcloud services enable spanner.googleapis.com
نمونه Spanner را ایجاد کنید
در این مرحله، نمونه Spanner خود را برای codelab تنظیم میکنیم. برای انجام این کار، Cloud Shell را باز کنید و این دستور را اجرا کنید:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
خروجی دستور:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
ایجاد پایگاه داده
پس از اجرای نمونه، میتوانید پایگاه داده را ایجاد کنید. Spanner امکان ایجاد چندین پایگاه داده را در یک نمونه واحد فراهم میکند.
پایگاه داده جایی است که شما طرحواره خود را تعریف میکنید. همچنین میتوانید کنترل کنید چه کسی به پایگاه داده دسترسی داشته باشد، رمزگذاری سفارشی تنظیم کنید، بهینهساز را پیکربندی کنید و مدت زمان نگهداری را تعیین کنید.
برای ایجاد پایگاه داده، دوباره از ابزار خط فرمان gcloud استفاده کنید:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
خروجی دستور:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
۴. بارگذاری دادهها
قبل از اینکه بتوانید از Data Boost استفاده کنید، باید مقداری داده در پایگاه داده داشته باشید. برای انجام این کار، یک مخزن ذخیرهسازی ابری ایجاد میکنید، یک ورودی avro را در مخزن آپلود میکنید و یک کار ورودی Dataflow را برای بارگذاری دادههای Avro در Spanner آغاز میکنید.
فعال کردن APIها
برای انجام این کار، اگر پنجرهی قبلی بسته بود، پنجرهی Cloud Shell را باز کنید.
مطمئن شوید که APIهای Compute، Cloud Storage و Dataflow را فعال کردهاید.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
خروجی مورد انتظار کنسول:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
مرحلهبندی وارد کردن فایلها در فضای ذخیرهسازی ابری
حالا، یک باکت برای ذخیره فایلهای avro ایجاد کنید:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
خروجی مورد انتظار کنسول:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
سپس، فایل tar را از github دانلود و استخراج کنید.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
خروجی مورد انتظار کنسول:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
و حالا فایلها را در باکتی که ایجاد کردهاید آپلود کنید.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
خروجی مورد انتظار کنسول:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
وارد کردن داده
با فایلهای موجود در فضای ذخیرهسازی ابری، میتوانید یک کار وارد کردن جریان داده را برای بارگذاری دادهها در Spanner شروع کنید.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
خروجی مورد انتظار کنسول:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
با این دستور میتوانید وضعیت کار واردات را بررسی کنید.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
خروجی مورد انتظار کنسول:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
تأیید دادهها در Spanner
حالا، به Spanner Studio بروید و مطمئن شوید که دادهها آنجا هستند. ابتدا، جدول topics را باز کنید تا ستونها را مشاهده کنید.

اکنون، برای اطمینان از در دسترس بودن دادهها، کوئری زیر را اجرا کنید:
SELECT COUNT(*) FROM topics;
خروجی مورد انتظار:

۵. خواندن دادهها از BigQuery
حالا که دادهها را در Spanner دارید، وقت آن رسیده که از داخل BigQuery به آنها دسترسی پیدا کنید. برای انجام این کار، یک اتصال خارجی به Spanner در BigQuery برقرار خواهید کرد.
با فرض اینکه مجوزهای لازم را دارید، با مراحل زیر یک اتصال خارجی به Spanner ایجاد کنید.
روی دکمهی «افزودن» در بالای کنسول BigQuery کلیک کنید و گزینهی «اتصالات به منابع دادهی ابدی» را انتخاب کنید.


اکنون میتوانید یک کوئری برای خواندن دادهها از Spanner اجرا کنید. این کوئری را در کنسول BigQuery اجرا کنید و مطمئن شوید که مقدار ${PROJECT_ID} خود را جایگزین میکنید:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
خروجی مثال:

میتوانید اطلاعات مربوط به کار، مانند مدت زمان اجرای آن و میزان دادههای پردازششده را در برگه «اطلاعات کار» مشاهده کنید.

در مرحله بعد، یک اتصال Data Boost به Spanner اضافه خواهید کرد و نتایج را مقایسه خواهید کرد.
۶. خواندن دادهها با استفاده از Data Boost
برای استفاده از Spanner Data Boost، باید یک اتصال خارجی جدید از BigQuery به Spanner ایجاد کنید. در کنسول BigQuery روی «افزودن» کلیک کنید و دوباره « Connections from external data sources » را انتخاب کنید.
جزئیات را با همان آدرس اینترنتی اتصال به Spanner پر کنید. «شناسه اتصال» را تغییر دهید و کادر «استفاده از افزایش داده» را علامت بزنید.
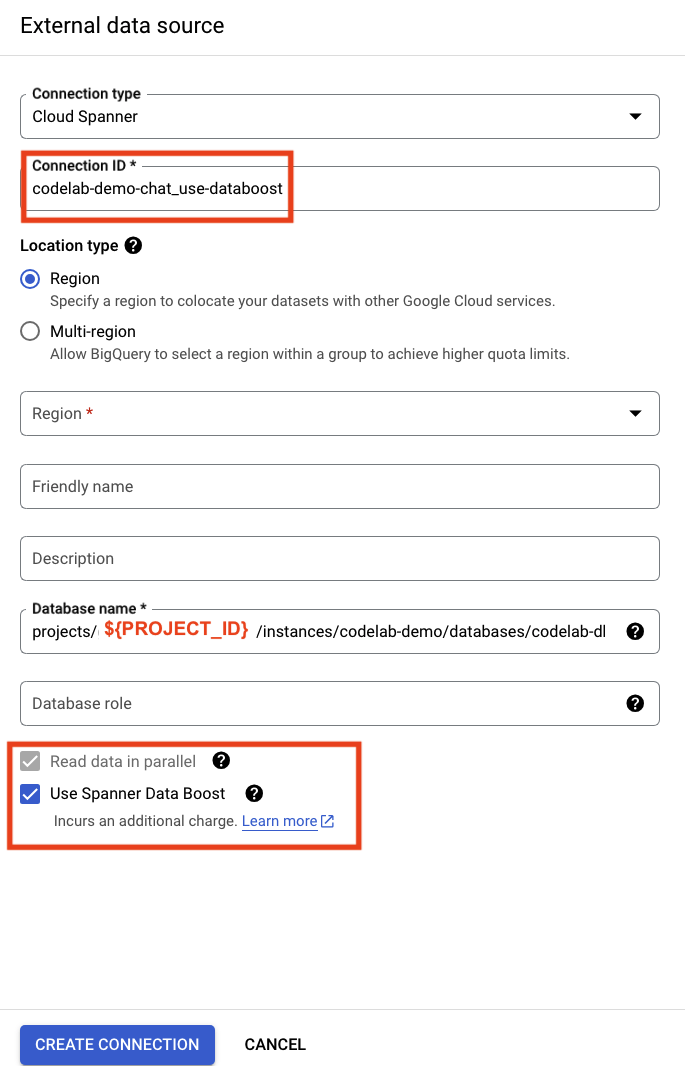
با ایجاد اتصال Data Boost، میتوانید همان کوئری را با نام اتصال جدید اجرا کنید. مجدداً، project_id خود را در کوئری جایگزین کنید.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
شما باید همان نتیجهی قبلی را دریافت کنید. آیا زمانبندی تغییر کرده است؟
۷. درک تقویت داده
Spanner Data Boost به شما امکان میدهد از منابعی غیرمرتبط با منابع نمونه Spanner خود استفاده کنید. این امر در درجه اول تأثیر حجم کار تحلیلی شما را بر حجم کار عملیاتیتان کاهش میدهد.
اگر چند بار در طول دو یا سه دقیقه درخواست عدم استفاده از Data Boost را اجرا کنید، میتوانید این را مشاهده کنید. به یاد داشته باشید که ${PROJECT_ID} را جایگزین کنید.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
سپس، چند دقیقه دیگر صبر کنید و پرس و جو را برای استفاده از Data Boost چند بار دیگر اجرا کنید. به یاد داشته باشید که ${PROJECT_ID} را جایگزین کنید.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
حالا، به Spanner studio در Cloud Console برگردید و به System Insights بروید.

در اینجا میتوانید معیارهای CPU را مشاهده کنید. کوئریهایی که بدون Data Boost اجرا میشوند، از CPU برای عملیات 'executesql_select_withpartitiontoken' استفاده میکنند. اگرچه کوئری یکسان است، اما اجرای Data Boost در نمونهی شما از CPU نشان داده نمیشود.

در بسیاری از موارد، عملکرد کوئری تحلیلی هنگام استفاده از Data Boost بهبود مییابد. مجموعه داده در این آموزش کوچک است و هیچ بار کاری دیگری برای منابع رقابت نمیکند. بنابراین، این آموزش انتظار ندارد که بهبود عملکرد را نشان دهد.
میتوانید با کوئریها و حجمهای کاری بازی کنید و ببینید Data Boost چگونه کار میکند. وقتی کارتان تمام شد، برای پاکسازی محیط به بخش بعدی بروید.
۸. محیط را تمیز کنید
اگر پروژه خود را بهطور خاص برای این آزمایشگاه کد ایجاد کردهاید، میتوانید به سادگی پروژه را حذف کنید تا آن را پاک کنید. اگر میخواهید پروژه را نگه دارید و اجزای جداگانه را پاک کنید، مراحل زیر را دنبال کنید.
حذف اتصالات BigQuery
برای حذف هر دو اتصال، روی سه نقطه کنار نام اتصال کلیک کنید، «حذف» را انتخاب کنید، سپس دستورالعملها را برای حذف اتصال دنبال کنید.

حذف فضای ذخیرهسازی ابری
gcloud storage rm --recursive gs://$GCS_BUCKET
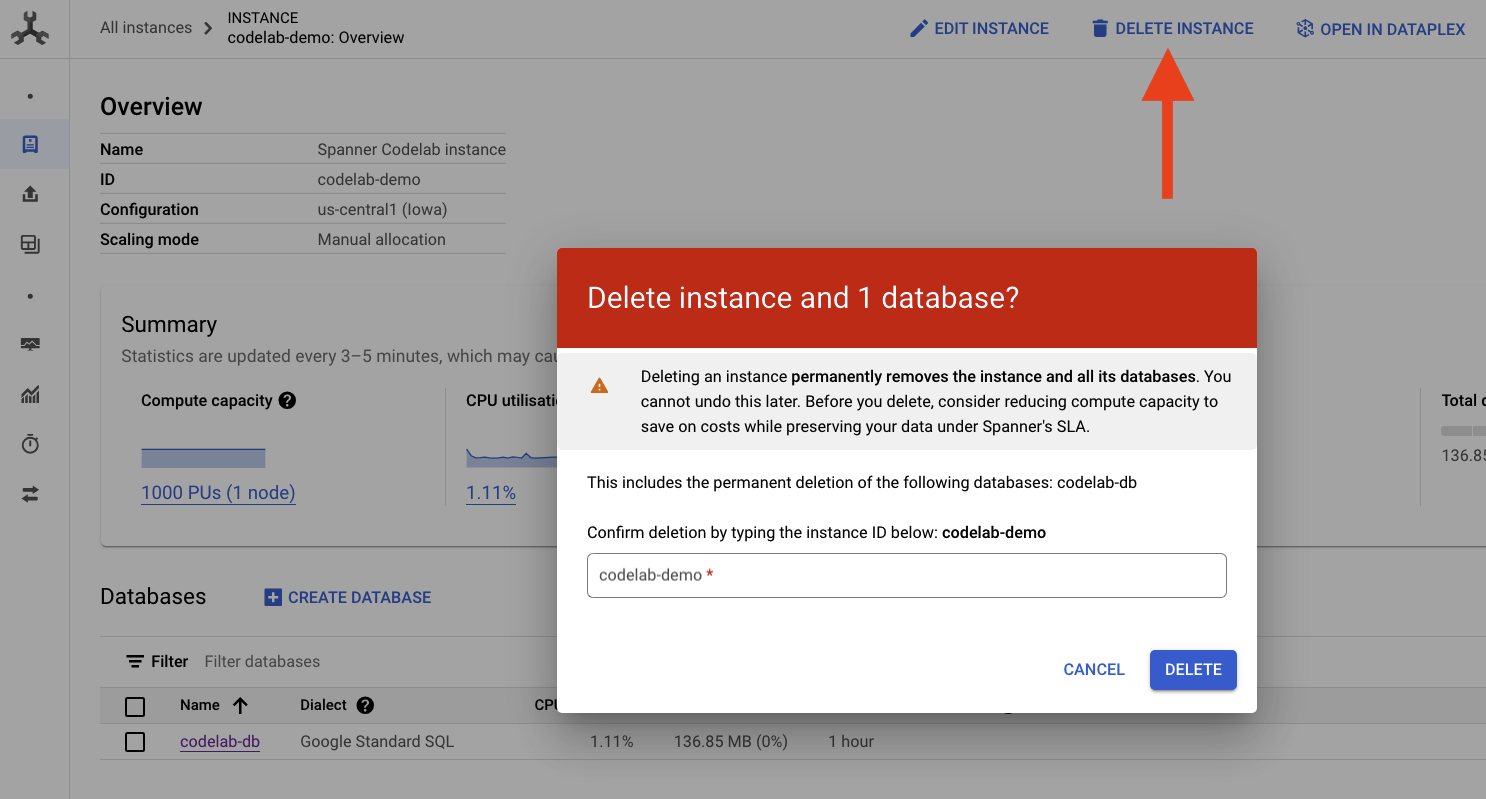
حذف نمونه Spanner
برای پاکسازی، کافیست به بخش Cloud Spanner در Cloud Console بروید و نمونه ' codelab-demo ' که در codelab ایجاد کردیم را حذف کنید.
۹. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
آنچه ما پوشش دادهایم
- نحوه استقرار یک نمونه Spanner
- نحوه بارگذاری دادهها در Spanner با استفاده از Dataflow
- نحوه دسترسی به دادههای Spanner از BigQuery
- نحوه استفاده از Spanner Data Boost برای جلوگیری از تأثیر بر نمونه Spanner شما برای پرسوجوهای تحلیلی از BigQuery
۱۰. نظرسنجی
خروجی: