
1. Introducción
En este codelab, aprenderás a usar Spanner Data Boost para consultar datos de Spanner desde BigQuery con consultas federadas sin ETL y sin afectar la base de datos de Spanner.

Spanner Data Boost es un servicio sin servidores completamente administrado que proporciona recursos de procesamiento independientes para las cargas de trabajo de Spanner compatibles. Data Boost te permite ejecutar consultas de estadísticas y exportaciones de datos con un impacto casi nulo en las cargas de trabajo existentes de la instancia de Spanner aprovisionada con un modelo de uso a pedido sin servidores.
Cuando se combina con las conexiones externas de BigQuery, Data Boost te permite consultar fácilmente datos de Spanner en tu plataforma de análisis de datos sin un movimiento de datos de ETL complejo.
Requisitos previos
- Conocimientos básicos sobre la consola de Google Cloud
- Habilidades básicas de la interfaz de línea de comandos y de Google Shell
Qué aprenderás
- Cómo implementar una instancia de Spanner
- Cómo cargar datos para crear una base de datos de Spanner
- Cómo acceder a los datos de Spanner desde BigQuery sin Data Boost
- Cómo acceder a los datos de Spanner desde BigQuery con Data Boost
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome
2. Configuración y requisitos
Cómo configurar el entorno a tu propio ritmo
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.


- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicie Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:

El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Crea una instancia y una base de datos de Spanner
Habilita la API de Spanner
En Cloud Shell, asegúrate de que tu ID del proyecto esté configurado:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
Configura tu región predeterminada como us-central1. Puedes cambiarla a otra región compatible con las configuraciones regionales de Spanner.
gcloud config set compute/region us-central1
Habilita la API de Spanner:
gcloud services enable spanner.googleapis.com
Crea la instancia de Spanner
En este paso, configuraremos nuestra instancia de Spanner para el codelab. Para ello, abre Cloud Shell y ejecuta este comando:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Resultado del comando:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
Crea la base de datos
Una vez que se ejecute la instancia, podrás crear la base de datos. Spanner permite tener varias bases de datos en una sola instancia.
La base de datos es donde defines tu esquema. También puedes controlar quién tiene acceso a la base de datos, configurar la encriptación personalizada, configurar el optimizador y establecer el período de retención.
Para crear la base de datos, vuelve a usar la herramienta de línea de comandos de gcloud:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Resultado del comando:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. Cargar datos
Antes de poder usar Data Boost, debes tener algunos datos en la base de datos. Para ello, crearás un bucket de Cloud Storage, subirás una importación de Avro al bucket y, luego, iniciarás un trabajo de importación de Dataflow para cargar los datos de Avro en Spanner.
Habilita las APIs
Para ello, abre un símbolo del sistema de Cloud Shell si se cerró el anterior.
Asegúrate de habilitar las APIs de Compute, Cloud Storage y Dataflow.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Resultado esperado en la consola:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Almacena en etapa intermedia los archivos de importación en Cloud Storage
Ahora, crea el bucket para almacenar los archivos Avro:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
Resultado esperado en la consola:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
A continuación, descarga el archivo tar de GitHub y extráelo.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
Resultado esperado en la consola:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
Ahora sube los archivos al bucket que creaste.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Resultado esperado en la consola:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
Importar datos
Con los archivos en Cloud Storage, puedes iniciar un trabajo de importación de Dataflow para cargar los datos en Spanner.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
Resultado esperado en la consola:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
Puedes verificar el estado del trabajo de importación con este comando.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
Resultado esperado en la consola:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Verifica los datos en Spanner
Ahora, ve a Spanner Studio y asegúrate de que los datos estén allí. Primero, expande la tabla de temas para ver las columnas.

Ahora, ejecuta la siguiente consulta para asegurarte de que los datos estén disponibles:
SELECT COUNT(*) FROM topics;
Resultado esperado:

5. Leer datos desde BigQuery
Ahora que tienes datos en Spanner, es momento de acceder a ellos desde BigQuery. Para ello, configurarás una conexión externa a Spanner en BigQuery.
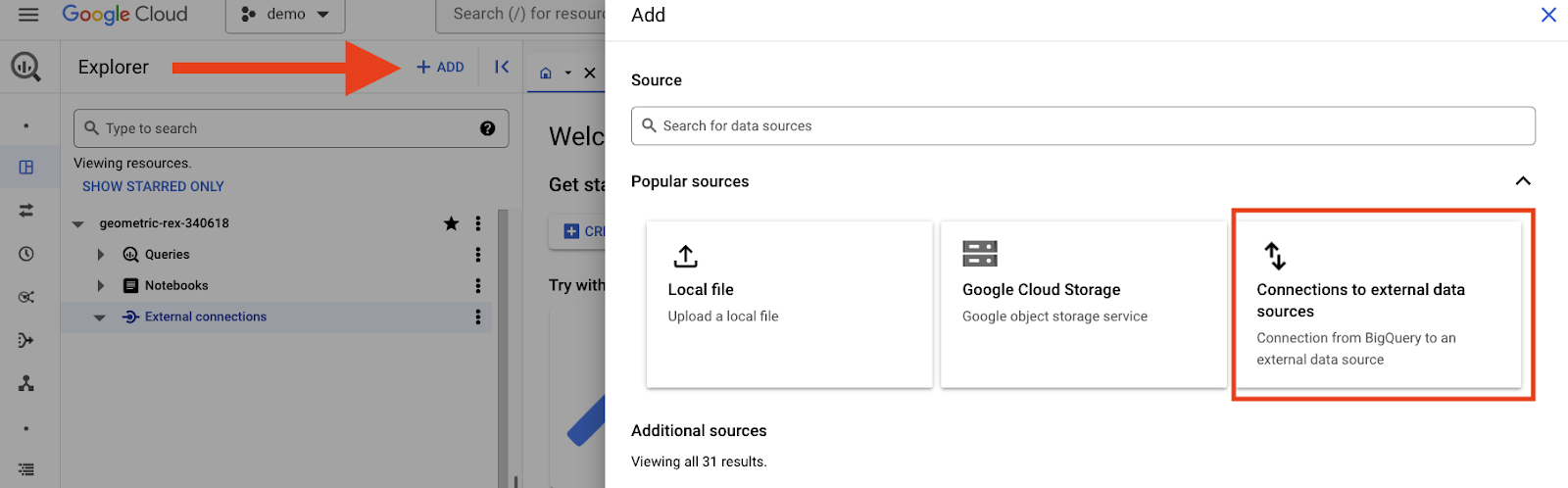
Si tienes los permisos adecuados, crea una conexión externa a Spanner siguiendo estos pasos.
Haz clic en el botón “Agregar” (Add) en la parte superior de la consola de BigQuery y selecciona la opción “Conexiones a fuentes de datos externas” (Connections to external data sources).

Ahora puedes ejecutar una consulta para leer datos de Spanner. Ejecuta esta consulta en la consola de BigQuery y asegúrate de sustituir el valor por tu ${PROJECT_ID}:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Resultado de ejemplo:

En la pestaña "Job Information", puedes ver información sobre el trabajo, como cuánto tiempo tardó en ejecutarse y cuántos datos se procesaron.

A continuación, agregarás una conexión de Data Boost a Spanner y compararás los resultados.
6. Cómo leer datos con Data Boost
Para usar Data Boost de Spanner, debes crear una conexión externa nueva de BigQuery a Spanner. Haz clic en "Agregar" en la consola de BigQuery y vuelve a seleccionar "Connections from external data sources".
Completa los detalles con el mismo URI de conexión a Spanner. Cambia el "ID de conexión" y marca la casilla "Usar Data Boost".

Con la conexión de Data Boost creada, puedes ejecutar la misma consulta, pero con el nuevo nombre de conexión. Nuevamente, sustituye tu project_id en la consulta.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Deberías obtener el mismo conjunto de resultados que antes. ¿Cambió el horario?
7. Información sobre Data Boost
Data Boost de Spanner te permite usar recursos no relacionados con los recursos de tu instancia de Spanner. Esto reduce principalmente el impacto de tus cargas de trabajo analíticas en tus cargas de trabajo operativas.
Puedes ver esto si ejecutas la consulta para no usar Data Boost varias veces durante dos o tres minutos. Recuerda sustituir ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Luego, espera unos minutos más y ejecuta la consulta para usar Data Boost varias veces más. Recuerda sustituir ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Ahora, regresa a Spanner Studio en la consola de Cloud y ve a System Insights.

Aquí puedes ver las métricas de la CPU. Las consultas que se ejecutan sin Data Boost usan la CPU para las operaciones "executesql_select_withpartitiontoken". Aunque la consulta es la misma, la ejecución de Data Boost no se muestra en el uso de CPU de tu instancia.

En muchos casos, el rendimiento de la consulta analítica mejorará cuando se use Data Boost. El conjunto de datos de este instructivo es pequeño y no hay otras cargas de trabajo que compitan por los recursos. Por lo tanto, este instructivo no espera mostrar mejoras en el rendimiento.
Puedes probar las consultas y las cargas de trabajo para ver cómo funciona Data Boost. Cuando termines, continúa con la siguiente sección para limpiar el entorno.
8. Limpia el entorno
Si creaste tu proyecto específicamente para este codelab, puedes borrarlo para limpiarlo. Si quieres conservar el proyecto y limpiar los componentes individuales, sigue los pasos que se indican a continuación.
Cómo quitar conexiones de BigQuery
Para quitar ambas conexiones, haz clic en los tres puntos junto al nombre de la conexión. Selecciona “Borrar” y, luego, sigue las instrucciones para borrar la conexión.

Borra el bucket de Cloud Storage
gcloud storage rm --recursive gs://$GCS_BUCKET
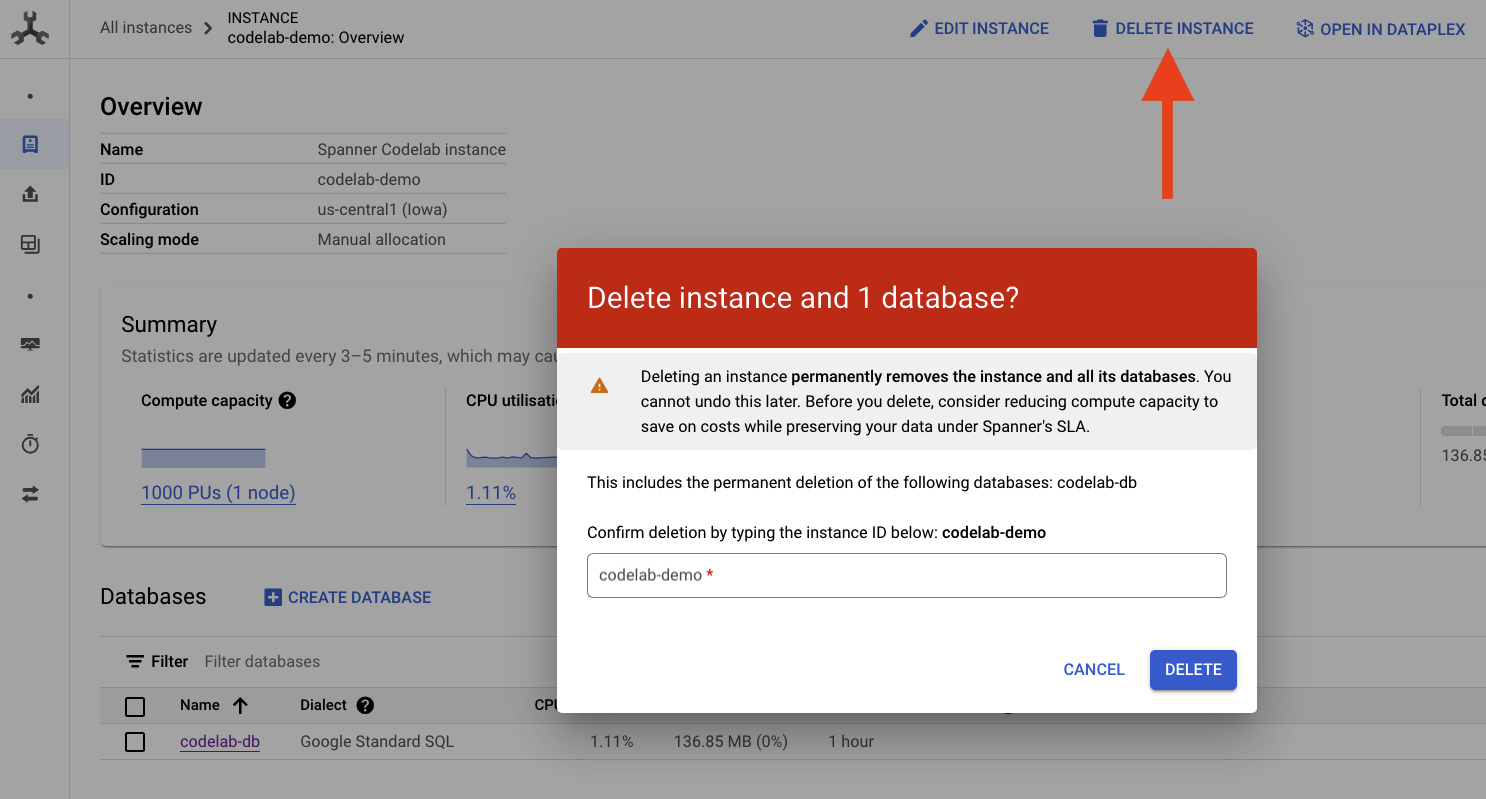
Borrar instancia de Spanner
Para limpiar, ve a la sección de Cloud Spanner de la consola de Cloud y borra la instancia “codelab-demo” que creamos en el codelab.
9. Felicitaciones
Felicitaciones por completar el codelab.
Temas abordados
- Cómo implementar una instancia de Spanner
- Cómo cargar datos en Spanner con Dataflow
- Cómo acceder a los datos de Spanner desde BigQuery
- Cómo usar Data Boost de Spanner para evitar el impacto en tu instancia de Spanner en el caso de las consultas analíticas de BigQuery
10. Encuesta
Resultado: