
1. Einführung
In diesem Codelab erfahren Sie, wie Sie mit Spanner Data Boost Spanner-Daten aus BigQuery abfragen. Dazu verwenden Sie föderierte Abfragen ohne ETL und ohne Auswirkungen auf die Spanner-Datenbank.

Spanner Data Boost ist ein vollständig verwalteter, serverloser Dienst, der unabhängige Rechenressourcen für unterstützte Spanner-Arbeitslasten bereitstellt. Mit Data Boost können Sie Analyseabfragen und Datenexporte nahezu ohne Auswirkungen auf vorhandene Arbeitslasten auf der bereitgestellten Spanner-Instanz ausführen. Dabei wird ein serverloses On-Demand-Nutzungsmodell verwendet.
In Kombination mit externen BigQuery-Verbindungen können Sie mit Data Boost ganz einfach Daten aus Spanner in Ihre Datenanalyseplattform abfragen, ohne dass eine komplexe ETL-Datenverschiebung erforderlich ist.
Vorbereitung
- Grundlegende Kenntnisse der Google Cloud Console
- Grundkenntnisse der Befehlszeilenschnittstelle und der Google Cloud Shell
Lerninhalte
- Spanner-Instanz bereitstellen
- Daten zum Erstellen einer Spanner-Datenbank laden
- Ohne Data Boost auf Spanner-Daten aus BigQuery zugreifen
- Mit Data Boost auf Spanner-Daten aus BigQuery zugreifen
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.



- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Er ist eine Zeichenfolge, die von Google APIs nicht verwendet wird. Sie können ihn jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich. Sie kann also nicht geändert werden, nachdem sie festgelegt wurde. Die Cloud Console generiert automatisch eine eindeutige Zeichenfolge. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie eine eigene ID verwenden und prüfen, ob sie verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Es gibt noch einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu allen drei Werten finden Sie in der Dokumentation.
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um zu vermeiden, dass Ihnen nach Abschluss dieser Anleitung Kosten in Rechnung gestellt werden, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testprogramm im Wert von 300$ teilnehmen.
Cloud Shell starten
Sie können Google Cloud zwar von Ihrem Laptop aus per Fernzugriff nutzen, in diesem Codelab verwenden Sie jedoch Google Cloud Shell, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console in der Symbolleiste rechts oben auf das Cloud Shell-Symbol:

Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Wenn der Vorgang abgeschlossen ist, sollte etwa Folgendes angezeigt werden:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Spanner-Instanz und -Datenbank erstellen
Spanner API aktivieren
Prüfen Sie in Cloud Shell, ob Ihre Projekt-ID eingerichtet ist:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
Konfigurieren Sie die Standardregion auf us-central1. Sie können dies in eine andere Region ändern, die von regionalen Spanner Konfigurationen unterstützt wird.
gcloud config set compute/region us-central1
Aktivieren Sie die Spanner API:
gcloud services enable spanner.googleapis.com
Spanner-Instanz erstellen
In diesem Schritt richten wir unsere Spanner-Instanz für das Codelab ein. Öffnen Sie dazu Cloud Shell und führen Sie diesen Befehl aus:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Befehlsausgabe :
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
Datenbank erstellen
Sobald Ihre Instanz ausgeführt wird, können Sie die Datenbank erstellen. Spanner ermöglicht mehrere Datenbanken in einer einzelnen Instanz.
In der Datenbank definieren Sie Ihr Schema. Sie können auch steuern, wer Zugriff auf die Datenbank hat, eine benutzerdefinierte Verschlüsselung einrichten, den Optimierer konfigurieren und den Aufbewahrungszeitraum festlegen.
Verwenden Sie noch einmal das gcloud-Befehlszeilentool, um die Datenbank zu erstellen:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Befehlsausgabe :
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. Daten laden
Bevor Sie Data Boost verwenden können, müssen sich Daten in der Datenbank befinden. Dazu erstellen Sie einen Cloud Storage-Bucket, laden einen Avro-Import in den Bucket hoch und starten einen Dataflow-Importjob, um die Avro-Daten in Spanner zu laden.
APIs aktivieren
Öffnen Sie dazu eine Cloud Shell-Eingabeaufforderung, falls die vorherige geschlossen wurde.
Aktivieren Sie die Compute API, die Cloud Storage API und die Dataflow API.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Erwartete Konsolenausgabe:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
Importdateien in Cloud Storage bereitstellen
Erstellen Sie nun den Bucket zum Speichern der Avro-Dateien:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
Erwartete Konsolenausgabe:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
Laden Sie als Nächstes die Tar-Datei von GitHub herunter und extrahieren Sie sie.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
Erwartete Konsolenausgabe:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
Laden Sie nun die Dateien in den erstellten Bucket hoch.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Erwartete Konsolenausgabe:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
Daten importieren
Nachdem sich die Dateien in Cloud Storage befinden, können Sie einen Dataflow-Importjob starten, um die Daten in Spanner zu laden.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
Erwartete Konsolenausgabe:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
Mit diesem Befehl können Sie den Status des Importjobs prüfen.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
Erwartete Konsolenausgabe:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
Daten in Spanner prüfen
Rufen Sie nun Spanner Studio auf und prüfen Sie, ob die Daten vorhanden sind. Maximieren Sie zuerst die Tabelle „topics“, um die Spalten aufzurufen.

Führen Sie nun die folgende Abfrage aus, um zu prüfen, ob Daten verfügbar sind:
SELECT COUNT(*) FROM topics;
Erwartete Ausgabe:

5. Daten aus BigQuery lesen
Nachdem Sie Daten in Spanner haben, können Sie von BigQuery aus darauf zugreifen. Dazu richten Sie in BigQuery eine externe Verbindung zu Spanner ein.
Sofern Sie die richtigen Berechtigungen haben, erstellen Sie mit den folgenden Schritten eine externe Verbindung zu Spanner.
Klicken Sie oben in der BigQuery-Konsole auf die Schaltfläche „Hinzufügen“ und wählen Sie die Option „Verbindungen zu externen Datenquellen“ aus.


Sie können jetzt eine Abfrage ausführen, um Daten aus Spanner zu lesen. Führen Sie diese Abfrage in der BigQuery-Konsole aus und ersetzen Sie dabei den Wert für Ihre ${PROJECT_ID}:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Beispielausgabe:

Auf dem Tab „Jobinformationen“ finden Sie Informationen zum Job, z. B. wie lange die Ausführung gedauert hat und wie viele Daten verarbeitet wurden.
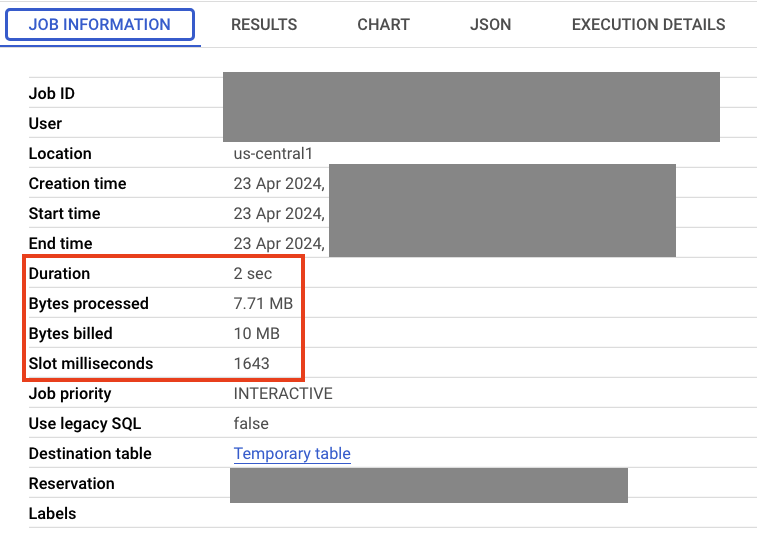
Als Nächstes fügen Sie eine Data Boost-Verbindung zu Spanner hinzu und vergleichen die Ergebnisse.
6. Daten mit Data Boost lesen
Wenn Sie Spanner Data Boost verwenden möchten, müssen Sie eine neue externe Verbindung von BigQuery zu Spanner erstellen. Klicken Sie in der BigQuery-Konsole auf „Hinzufügen“ und wählen Sie noch einmal „Connections from external data sources“ aus.
Geben Sie die Details mit demselben Verbindungs-URI zu Spanner ein. Ändern Sie die Verbindungs-ID und setzen Sie ein Häkchen im Kästchen „Data Boost verwenden“.
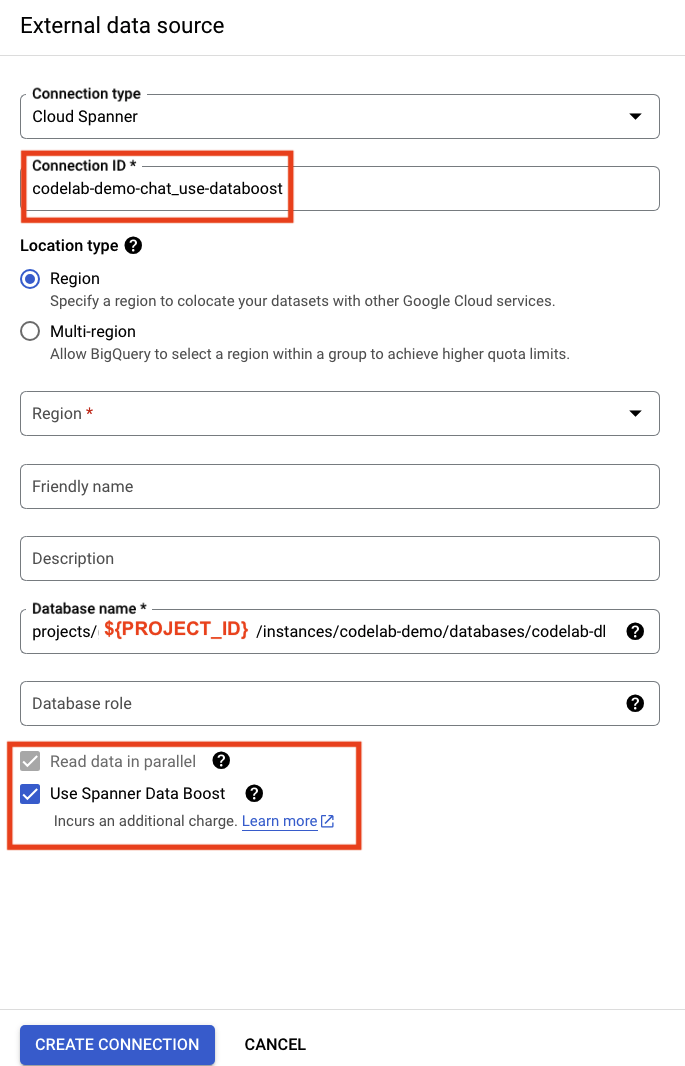
Nachdem die Data Boost-Verbindung erstellt wurde, können Sie dieselbe Abfrage mit dem neuen Verbindungsnamen ausführen. Ersetzen Sie noch einmal Ihre Projekt-ID in der Abfrage.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Sie sollten dasselbe Ergebnis wie zuvor erhalten. Hat sich die Zeit geändert?
7. Data Boost
Mit Spanner Data Boost können Sie Ressourcen verwenden, die nicht mit Ihren Spanner-Instanzressourcen zusammenhängen. Dadurch werden vor allem die Auswirkungen Ihrer analytischen Arbeitslasten auf Ihre betrieblichen Arbeitslasten reduziert.
Sie können dies sehen, wenn Sie die Abfrage, die Data Boost nicht verwendet, einige Male innerhalb von zwei oder drei Minuten ausführen. Ersetzen Sie dabei ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Warten Sie dann einige Minuten und führen Sie die Abfrage, die Data Boost verwendet, einige Male aus. Ersetzen Sie dabei ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
Kehren Sie nun in der Cloud Console zu Spanner Studio und dann zu System Insights zurück.

Hier sehen Sie die CPU-Messwerte. Bei den Abfragen, die ohne Data Boost ausgeführt werden, wird die CPU für die Vorgänge „executesql_select_withpartitiontoken“ verwendet. Obwohl die Abfrage dieselbe ist, wird die Data Boost-Ausführung nicht in der CPU-Auslastung Ihrer Instanz angezeigt.
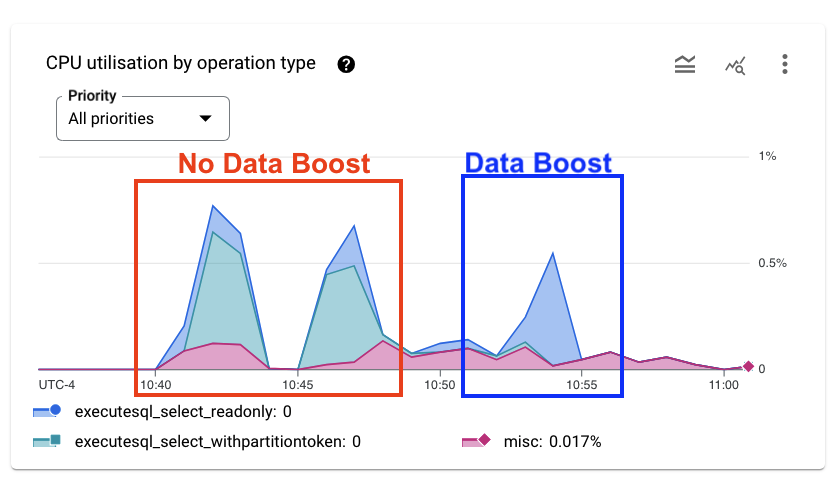
In vielen Fällen verbessert sich die Leistung der Analyseabfrage, wenn Data Boost verwendet wird. Das Dataset in dieser Anleitung ist klein und es gibt keine anderen Arbeitslasten, die um Ressourcen konkurrieren. Daher werden in dieser Anleitung keine Leistungsverbesserungen erwartet.
Sie können mit den Abfragen und Arbeitslasten experimentieren und sehen, wie Data Boost funktioniert. Wenn Sie fertig sind, fahren Sie mit dem nächsten Abschnitt fort, um die Umgebung zu bereinigen.
8. Umgebung bereinigen
Wenn Sie Ihr Projekt speziell für dieses Codelab erstellt haben, können Sie es einfach löschen, um es zu bereinigen. Wenn Sie das Projekt behalten und die einzelnen Komponenten bereinigen möchten, führen Sie die folgenden Schritte aus.
BigQuery-Verbindungen entfernen
Wenn Sie beide Verbindungen entfernen möchten, klicken Sie neben dem Verbindungsnamen auf die drei Punkte. Wählen Sie „Löschen“ aus und folgen Sie der Anleitung, um die Verbindung zu löschen.

Cloud Storage-Bucket löschen
gcloud storage rm --recursive gs://$GCS_BUCKET
Spanner-Instanz löschen
Rufen Sie zum Bereinigen einfach den Cloud Spanner-Bereich der Cloud Console auf und löschen Sie die Instanz „codelab-demo'“, die wir im Codelab erstellt haben.
9. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Behandelte Themen
- Spanner-Instanz bereitstellen
- Daten mit Dataflow in Spanner laden
- Auf Spanner-Daten aus BigQuery zugreifen
- Spanner Data Boost verwenden, um Auswirkungen auf Ihre Spanner-Instanz bei Analyseabfragen aus BigQuery zu vermeiden
10. Umfrage
Ausgabe: