
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية استخدام Spanner Data Boost للاستعلام عن بيانات Spanner من BigQuery باستخدام استعلامات موحّدة بدون الحاجة إلى استخراج البيانات وتحويلها وتحميلها، وبدون التأثير في قاعدة بيانات Spanner.

Spanner Data Boost هي خدمة بدون خادم ومُدارة بالكامل توفّر موارد حوسبة مستقلة لأحمال عمل Spanner المتوافقة. تتيح لك ميزة "تعزيز البيانات" تنفيذ طلبات بحث الإحصاءات وعمليات تصدير البيانات بدون التأثير تقريبًا في أحمال العمل الحالية على مثيل Spanner الذي تم توفيره باستخدام نموذج الاستخدام عند الطلب بدون خادم.
عند استخدام Data Boost مع عمليات الربط الخارجية في BigQuery، تتيح لك هذه الميزة طلب البحث بسهولة عن البيانات من Spanner إلى منصة إحصاءات البيانات بدون الحاجة إلى نقل البيانات المعقّد باستخدام عملية استخراج وتحويل وتحميل (ETL).
المتطلبات الأساسية
- فهم أساسي لـ Google Cloud وConsole
- مهارات أساسية في واجهة سطر الأوامر وGoogle Shell
أهداف الدورة التعليمية
- كيفية نشر مثيل Spanner
- كيفية تحميل البيانات لإنشاء قاعدة بيانات Spanner
- كيفية الوصول إلى بيانات Spanner من BigQuery بدون Data Boost
- كيفية الوصول إلى بيانات Spanner من BigQuery باستخدام Data Boost
المتطلبات
- حساب Google Cloud ومشروع Google Cloud
- متصفّح ويب، مثل Chrome
2. الإعداد والمتطلبات
إعداد البيئة بوتيرة ذاتية
- سجِّل الدخول إلى Google Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.



- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. وهي سلسلة أحرف لا تستخدمها Google APIs. ويمكنك تعديلها في أي وقت.
- رقم تعريف المشروع هو معرّف فريد في جميع مشاريع Google Cloud ولا يمكن تغييره بعد ضبطه. تنشئ Cloud Console تلقائيًا سلسلة فريدة، ولا يهمّك عادةً ما هي. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك (يُشار إليه عادةً باسم
PROJECT_ID). إذا لم يعجبك رقم التعريف الذي تم إنشاؤه، يمكنك إنشاء رقم تعريف عشوائي آخر. يمكنك بدلاً من ذلك تجربة اسم من اختيارك ومعرفة ما إذا كان متاحًا. لا يمكن تغيير هذا الخيار بعد هذه الخطوة وسيظل ساريًا طوال مدة المشروع. - للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console لاستخدام موارد/واجهات برمجة تطبيقات Cloud. لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير، إن وُجدت أي تكلفة على الإطلاق. لإيقاف الموارد وتجنُّب تحمّل تكاليف فوترة تتجاوز هذا البرنامج التعليمي، يمكنك حذف الموارد التي أنشأتها أو حذف المشروع. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:

لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا ثابتًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
3- إنشاء مثيل وقاعدة بيانات Spanner
تفعيل Spanner API
داخل Cloud Shell، تأكَّد من إعداد رقم تعريف مشروعك:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID=$(gcloud config get-value project)
اضبط منطقتك التلقائية على us-central1. يمكنك تغيير هذه المنطقة إلى منطقة أخرى تتيحها الإعدادات الإقليمية في Spanner.
gcloud config set compute/region us-central1
فعِّل Spanner API باتّباع الخطوات التالية:
gcloud services enable spanner.googleapis.com
إنشاء مثيل Spanner
في هذه الخطوة، سنعدّ مثيل Spanner للدرس التطبيقي حول الترميز العملي. لإجراء ذلك، افتح Cloud Shell ونفِّذ الأمر التالي:
export SPANNER_INSTANCE_ID=codelab-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
ناتج الأمر:
$ gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--description="Spanner Codelab instance" \
--nodes=1
Creating instance...done.
إنشاء قاعدة البيانات
بعد تشغيل مثيلك، يمكنك إنشاء قاعدة البيانات. تسمح خدمة Spanner بإنشاء قواعد بيانات متعددة على مثيل واحد.
قاعدة البيانات هي المكان الذي تحدّد فيه المخطط. يمكنك أيضًا التحكّم في المستخدمين الذين يمكنهم الوصول إلى قاعدة البيانات، وإعداد تشفير مخصّص، وضبط أداة التحسين، وتحديد فترة التخزين.
لإنشاء قاعدة البيانات، استخدِم أداة سطر الأوامر gcloud مرة أخرى:
export SPANNER_DATABASE=codelab-db
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
ناتج الأمر:
$ gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Creating database...done.
4. تحميل البيانات
قبل استخدام ميزة "تعزيز البيانات"، يجب أن تتوفّر لديك بعض البيانات في قاعدة البيانات. لإجراء ذلك، عليك إنشاء حزمة Cloud Storage، وتحميل عملية استيراد بتنسيق Avro إلى الحزمة، وبدء مهمة استيراد Dataflow لتحميل بيانات Avro إلى Spanner.
تفعيل واجهات برمجة التطبيقات
لإجراء ذلك، افتح نافذة Cloud Shell إذا تم إغلاق النافذة السابقة.
تأكَّد من تفعيل واجهات برمجة التطبيقات Compute وCloud Storage وDataflow.
gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
الناتج المتوقّع في وحدة التحكّم:
$ gcloud services enable compute.googleapis.com storage.googleapis.com dataflow.googleapis.com
Operation "operations/acat.*snip*" finished successfully.
تجهيز ملفات الاستيراد على Cloud Storage
الآن، أنشئ الحزمة لتخزين ملفات avro:
export GCS_BUCKET=spanner-codelab-import_$(date '+%Y-%m-%d_%H_%M_%S')
gcloud storage buckets create gs://$GCS_BUCKET
الناتج المتوقّع في وحدة التحكّم:
$ gcloud storage buckets create gs://$GCS_BUCKET
Creating gs://spanner-codelab-import/...
بعد ذلك، نزِّل ملف tar من GitHub واستخرِجه.
wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
tar -xzvf spanner-chat-db.tar.gz
الناتج المتوقّع في وحدة التحكّم:
$ wget https://github.com/dtest/spanner-databoost-tutorial/releases/download/v0.1/spanner-chat-db.tar.gz
*snip*
*snip*(123 MB/s) - ‘spanner-chat-db.tar.gz' saved [46941709/46941709]
$
$ tar -xzvf spanner-chat-db.tar.gz
spanner-chat-db/
spanner-chat-db/users.avro-00000-of-00002
spanner-chat-db/user_notifications-manifest.json
spanner-chat-db/interests-manifest.json
spanner-chat-db/users-manifest.json
spanner-chat-db/users.avro-00001-of-00002
spanner-chat-db/topics-manifest.json
spanner-chat-db/topics.avro-00000-of-00002
spanner-chat-db/topics.avro-00001-of-00002
spanner-chat-db/user_interests-manifest.json
spanner-chat-db/spanner-export.json
spanner-chat-db/interests.avro-00000-of-00001
spanner-chat-db/user_notifications.avro-00000-of-00001
spanner-chat-db/user_interests.avro-00000-of-00001
والآن، حمِّل الملفات إلى الحِزمة التي أنشأتها.
gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
الناتج المتوقّع في وحدة التحكّم:
$ gcloud storage cp spanner-chat-db gs://$GCS_BUCKET --recursive
Copying file://spanner-chat-db/users.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00000-of-00002
Copying file://spanner-chat-db/user_notifications-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_notifications-manifest.json
Copying file://spanner-chat-db/interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/interests-manifest.json
Copying file://spanner-chat-db/users-manifest.json to gs://spanner-codelab-import/spanner-chat-db/users-manifest.json
Copying file://spanner-chat-db/users.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/users.avro-00001-of-00002
Copying file://spanner-chat-db/topics-manifest.json to gs://spanner-codelab-import/spanner-chat-db/topics-manifest.json
Copying file://spanner-chat-db/topics.avro-00000-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00000-of-00002
Copying file://spanner-chat-db/topics.avro-00001-of-00002 to gs://spanner-codelab-import/spanner-chat-db/topics.avro-00001-of-00002
Copying file://spanner-chat-db/user_interests-manifest.json to gs://spanner-codelab-import/spanner-chat-db/user_interests-manifest.json
Copying file://spanner-chat-db/spanner-export.json to gs://spanner-codelab-import/spanner-chat-db/spanner-export.json
Copying file://spanner-chat-db/interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/interests.avro-00000-of-00001
Copying file://spanner-chat-db/user_notifications.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_notifications.avro-00000-of-00001
Copying file://spanner-chat-db/user_interests.avro-00000-of-00001 to gs://spanner-codelab-import/spanner-chat-db/user_interests.avro-00000-of-00001
Completed files 13/13 | 54.6MiB/54.6MiB
Average throughput: 46.4MiB/s
استيراد البيانات
بعد نقل الملفات إلى Cloud Storage، يمكنك بدء مهمة استيراد Dataflow لتحميل البيانات إلى Spanner.
gcloud dataflow jobs run import_chatdb \
--gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
--region us-central1 \
--staging-location gs://$GCS_BUCKET/tmp \
--parameters \
instanceId=$SPANNER_INSTANCE_ID,\
databaseId=$SPANNER_DATABASE,\
inputDir=gs://$GCS_BUCKET/spanner-chat-db
الناتج المتوقّع في وحدة التحكّم:
$ gcloud dataflow jobs run import_chatdb \
> --gcs-location gs://dataflow-templates-us-central1/latest/GCS_Avro_to_Cloud_Spanner \
> --region us-central1 \
> --staging-location gs://$GCS_BUCKET/tmp \
> --parameters \
> instanceId=$SPANNER_INSTANCE_ID,\
> databaseId=$SPANNER_DATABASE,\
> inputDir=gs://$GCS_BUCKET/spanner-chat-db
createTime: '*snip*'
currentStateTime: '*snip*'
id: *snip*
location: us-central1
name: import_chatdb
projectId: *snip*
startTime: '*snip*'
type: JOB_TYPE_BATCH
يمكنك التحقّق من حالة مهمة الاستيراد باستخدام هذا الأمر.
gcloud dataflow jobs list --filter="name=import_chatdb" --region us-central1
الناتج المتوقّع في وحدة التحكّم:
$ gcloud dataflow jobs list --filter="name=import_chatdb"
`--region` not set; getting jobs from all available regions. Some jobs may be missing in the event of an outage. https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
JOB_ID NAME TYPE CREATION_TIME STATE REGION
*snip* import_chatdb Batch 2024-04-*snip* Done us-central1
التحقّق من البيانات في Spanner
الآن، انتقِل إلى Spanner Studio وتأكَّد من توفّر البيانات. أولاً، وسِّع جدول المواضيع لعرض الأعمدة.

الآن، نفِّذ طلب البحث التالي للتأكّد من توفّر البيانات:
SELECT COUNT(*) FROM topics;
الناتج المتوقّع:

5- قراءة البيانات من BigQuery
بعد نقل البيانات إلى Spanner، حان الوقت للوصول إليها من داخل BigQuery. لإجراء ذلك، عليك إعداد اتصال خارجي بـ Spanner في BigQuery.
بافتراض أنّ لديك الأذونات المناسبة، يمكنك إنشاء عملية ربط خارجية بـ Spanner باتّباع الخطوات التالية.
انقر على الزر "إضافة" في أعلى وحدة تحكّم BigQuery، ثم اختَر الخيار "عمليات الربط بمصادر البيانات الخارجية".


يمكنك الآن تنفيذ طلب بحث لقراءة البيانات من Spanner. نفِّذ طلب البحث هذا في وحدة تحكّم BigQuery، مع الحرص على استبدال القيمة بـ ${PROJECT_ID}:
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
مثال على الناتج:

يمكنك الاطّلاع على معلومات حول المهمة، مثل المدة التي استغرقتها وكمية البيانات التي تمت معالجتها في علامة التبويب "معلومات المهمة".
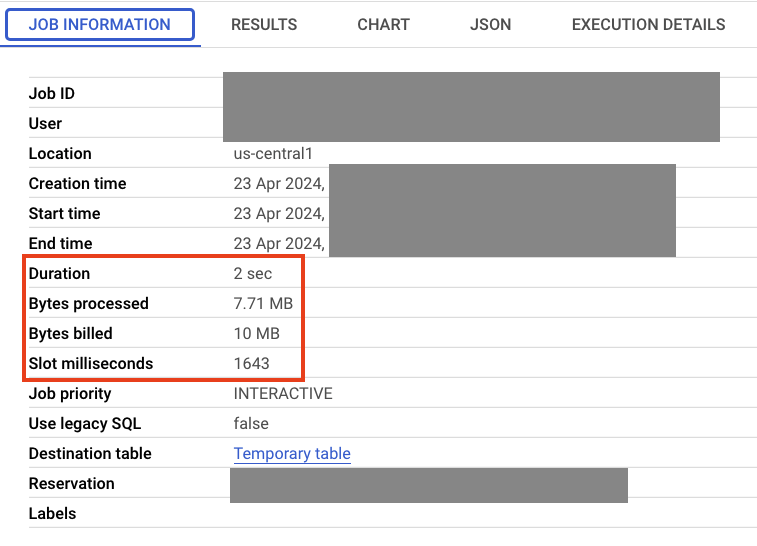
بعد ذلك، ستضيف عملية ربط Data Boost إلى Spanner، وستقارن النتائج.
6. قراءة البيانات باستخدام ميزة "تعزيز البيانات"
لاستخدام Spanner Data Boost، عليك إنشاء عملية ربط خارجية جديدة من BigQuery إلى Spanner. انقر على "إضافة" في وحدة تحكّم BigQuery واختَر "Connections from external data sources" مرة أخرى.
املأ التفاصيل باستخدام عنوان URI نفسه للاتصال بـ Spanner. غيِّر "معرّف الاتصال" وضع علامة في المربّع "استخدام ميزة تسريع البيانات".

بعد إنشاء عملية الربط في Data Boost، يمكنك تنفيذ طلب البحث نفسه ولكن باستخدام اسم عملية الربط الجديدة. مرة أخرى، استبدِل project_id في طلب البحث.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
من المفترض أن تحصل على مجموعة النتائج نفسها كما كان من قبل. هل تغيّر التوقيت؟
7. التعرّف على ميزة "تعزيز البيانات"
تتيح لك ميزة "تحسين بيانات Spanner" استخدام موارد غير مرتبطة بموارد مثيل Spanner. يؤدي ذلك في المقام الأول إلى الحدّ من تأثير أعباء العمل التحليلية في أعباء العمل التشغيلية.
يمكنك ملاحظة ذلك إذا نفّذت طلب البحث لعدم استخدام ميزة "تعزيز البيانات" عدة مرات خلال دقيقتَين أو ثلاث دقائق. يُرجى استبدال ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_no-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
بعد ذلك، انتظِر بضع دقائق أخرى، ونفِّذ طلب البحث لاستخدام ميزة "تحسين البيانات" عدة مرات أخرى. يُرجى استبدال ${PROJECT_ID}.
SELECT *
FROM (
SELECT * FROM EXTERNAL_QUERY("projects/${PROJECT_ID}/locations/us-central1/connections/codelab-demo-chat_use-databoost", "SELECT users.userUUID, SHA256(users.email) as hashed_email, COUNT(*) num_topics, m.last_posted from users HASH JOIN (select MAX(t.created) last_posted, t.userUUID FROM topics t GROUP BY 2) m USING (userUUID)HASH JOIN topics USING (userUUID) GROUP BY users.userUUID, users.email, m.last_posted")
)
ORDER BY num_topics DESC;
الآن، ارجع إلى Spanner Studio في Cloud Console، ثم انتقِل إلى "إحصاءات النظام".

يمكنك هنا الاطّلاع على مقاييس وحدة المعالجة المركزية. تستخدم طلبات البحث التي يتم تنفيذها بدون Data Boost وحدة المعالجة المركزية لعمليات "executesql_select_withpartitiontoken". على الرغم من أنّ طلب البحث هو نفسه، لا يظهر تنفيذ Data Boost في استخدام وحدة المعالجة المركزية (CPU) في مثيلك.
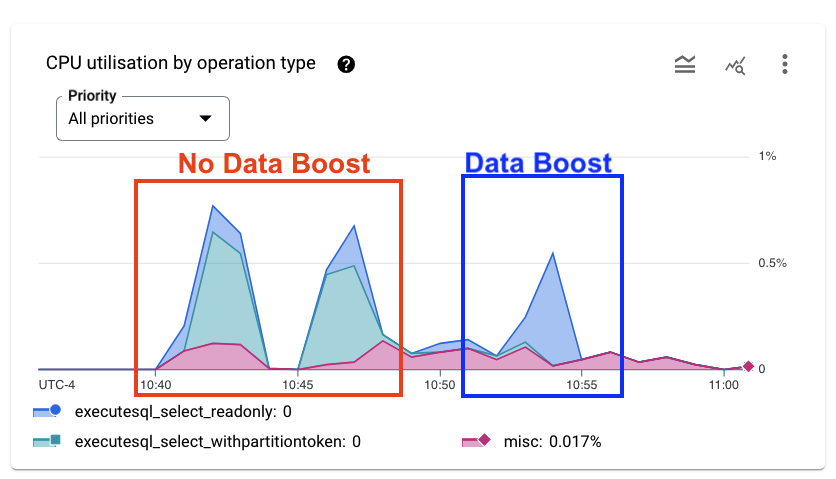
في كثير من الحالات، سيتحسّن أداء طلب البحث التحليلي عند استخدام Data Boost. مجموعة البيانات في هذا البرنامج التعليمي صغيرة ولا توجد أحمال عمل أخرى تتنافس على الموارد. لذلك، لا يتوقّع هذا البرنامج التعليمي عرض تحسينات في الأداء.
يمكنك تجربة طلبات البحث وأحمال العمل المختلفة والاطّلاع على طريقة عمل Data Boost. عند الانتهاء، انتقِل إلى القسم التالي لتنظيف البيئة.
8. إخلاء مساحة
إذا أنشأت مشروعك خصيصًا لهذا الدرس التطبيقي حول الترميز، يمكنك ببساطة حذف المشروع لتنظيفه. إذا كنت تريد الاحتفاظ بالمشروع وتنظيف المكوّنات الفردية، يمكنك المتابعة في الخطوات التالية.
إزالة عمليات الربط بخدمة BigQuery
لإزالة كلا الاتصالين، انقر على النقاط الثلاث بجانب اسم الاتصال. انقر على "حذف"، ثم اتّبِع التعليمات لإلغاء الربط.

حذف حزمة Cloud Storage
gcloud storage rm --recursive gs://$GCS_BUCKET
حذف مثيل Spanner
لإجراء عملية التنظيف، ما عليك سوى الانتقال إلى قسم Cloud Spanner في Cloud Console وحذف مثيل "codelab-demo" الذي أنشأناه في برنامج التدريب العملي.
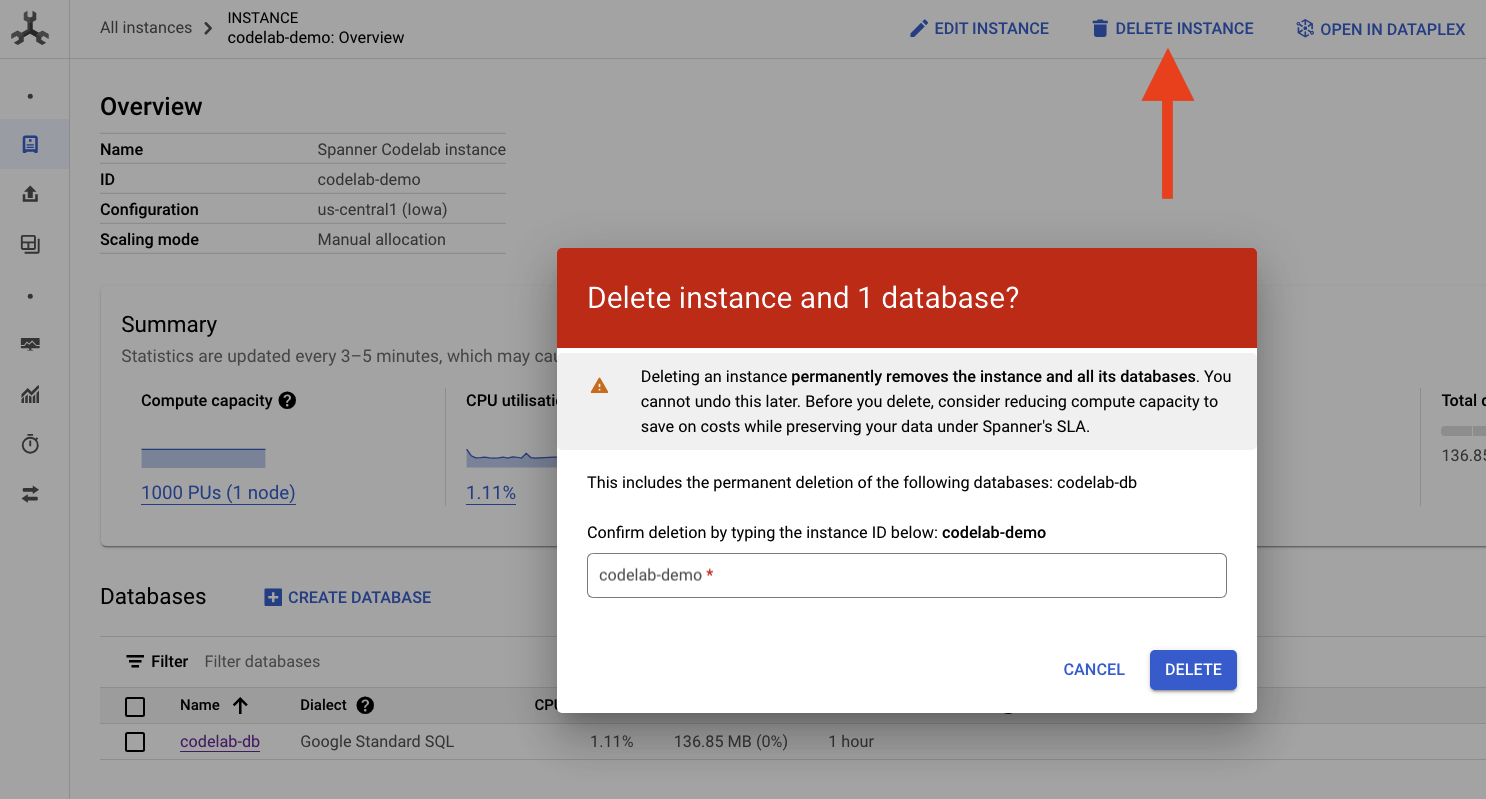
9- تهانينا
تهانينا على إكمال تجربة البرمجة.
المواضيع التي تناولناها
- كيفية نشر مثيل Spanner
- كيفية تحميل البيانات إلى Spanner باستخدام Dataflow
- كيفية الوصول إلى بيانات Spanner من BigQuery
- كيفية استخدام Spanner Data Boost لتجنُّب التأثير في مثيل Spanner عند إجراء طلبات بحث تحليلية من BigQuery
10. استطلاع
إخراج: