
1. Введение
Spanner — это полностью управляемая, горизонтально масштабируемая, глобально распределенная база данных, отлично подходящая как для реляционных, так и для нереляционных рабочих нагрузок.
Интерфейс Spanner для работы с Cassandra позволяет использовать преимущества полностью управляемой, масштабируемой и высокодоступной инфраструктуры Spanner, применяя привычные инструменты и синтаксис Cassandra.
Что вы узнаете
- Как настроить экземпляр Spanner и базу данных.
- Как преобразовать схему и модель данных Cassandra.
- Как выполнить массовый экспорт исторических данных из Cassandra в Spanner.
- Как перенаправить ваше приложение на Spanner вместо Cassandra.
Что вам понадобится
- Проект Google Cloud, подключенный к платежному аккаунту.
- Для доступа к компьютеру с установленным и настроенным интерфейсом командной строки
gcloudCLI или для использования Google Cloud Shell . - Веб-браузер, например Chrome или Firefox .
2. Настройка и требования
Создайте проект GCP
Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
Настройка выставления счетов
Далее вам необходимо следовать руководству пользователя по управлению выставлением счетов и включить выставление счетов в консоли Cloud . Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США . Чтобы избежать дополнительных расходов после завершения этого руководства, вы можете выключить экземпляр Spanner в конце выполнения задания, следуя шагу 9 «Очистка».
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:

Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть примерно следующее:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
Далее
Далее вы развернете кластер Cassandra.
3. Развертывание кластера Cassandra (Origin)
В рамках этого практического занятия мы настроим одноузловой кластер Cassandra на платформе Compute Engine.
1. Создайте виртуальную машину GCE для Cassandra.
Для создания экземпляра используйте команду gcloud compute instances create из предварительно подготовленной оболочки облака.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Установите Cassandra.
Перейдите в раздел VM Instances из Navigation menu , следуя приведенным ниже инструкциям:  .
.
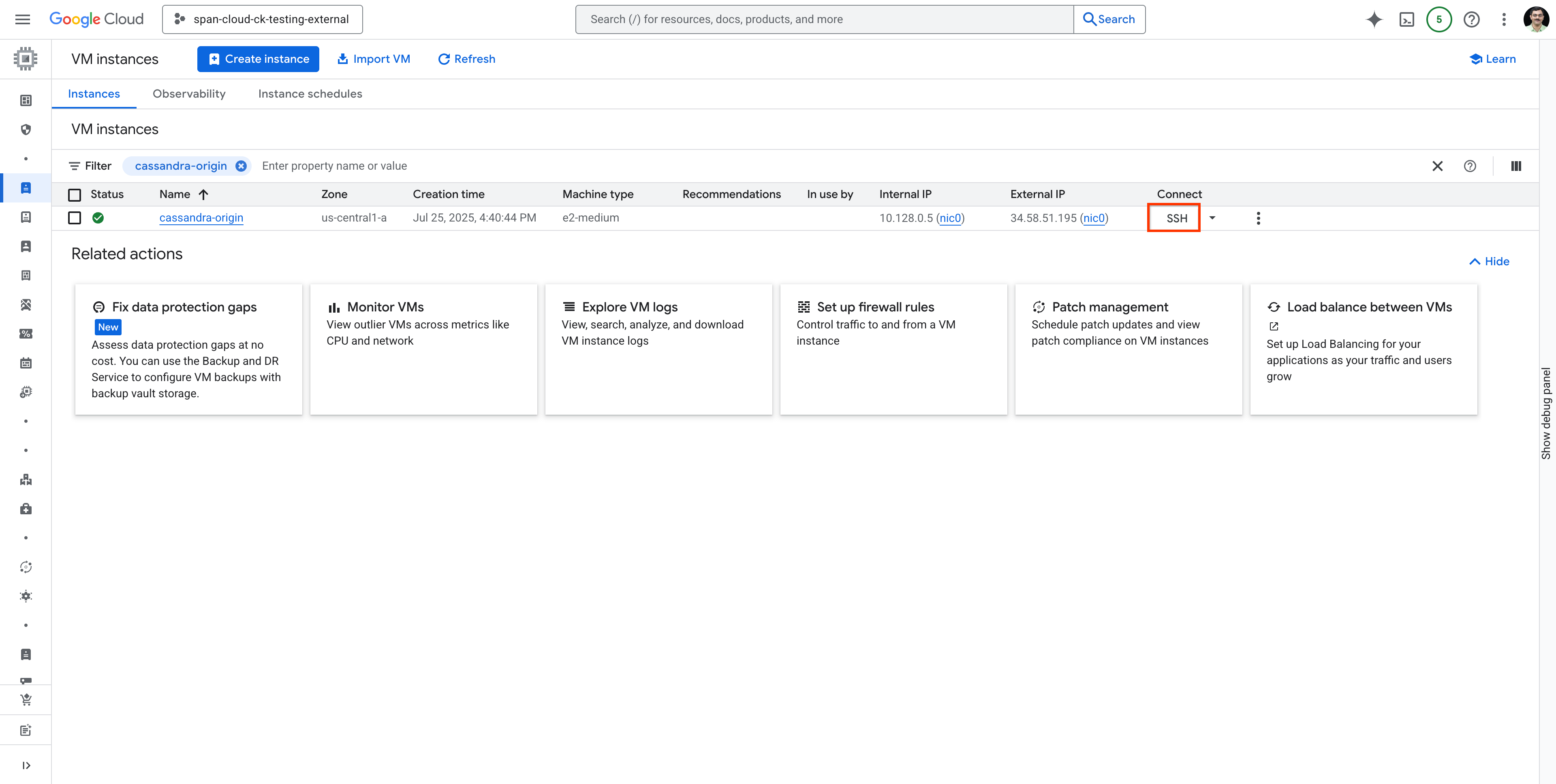
Найдите виртуальную машину cassandra-origin и подключитесь к ней по SSH, как показано ниже:
 .
.
Выполните следующие команды, чтобы установить Cassandra на созданную вами виртуальную машину и подключиться к ней по SSH.
Установите Java (зависимость от Cassandra).
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Добавить репозиторий Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Установите Cassandra.
sudo apt-get update
sudo apt-get install -y cassandra
Укажите адрес прослушивания для службы Cassandra.
Здесь для повышения безопасности мы используем внутренний IP-адрес виртуальной машины Cassandra.
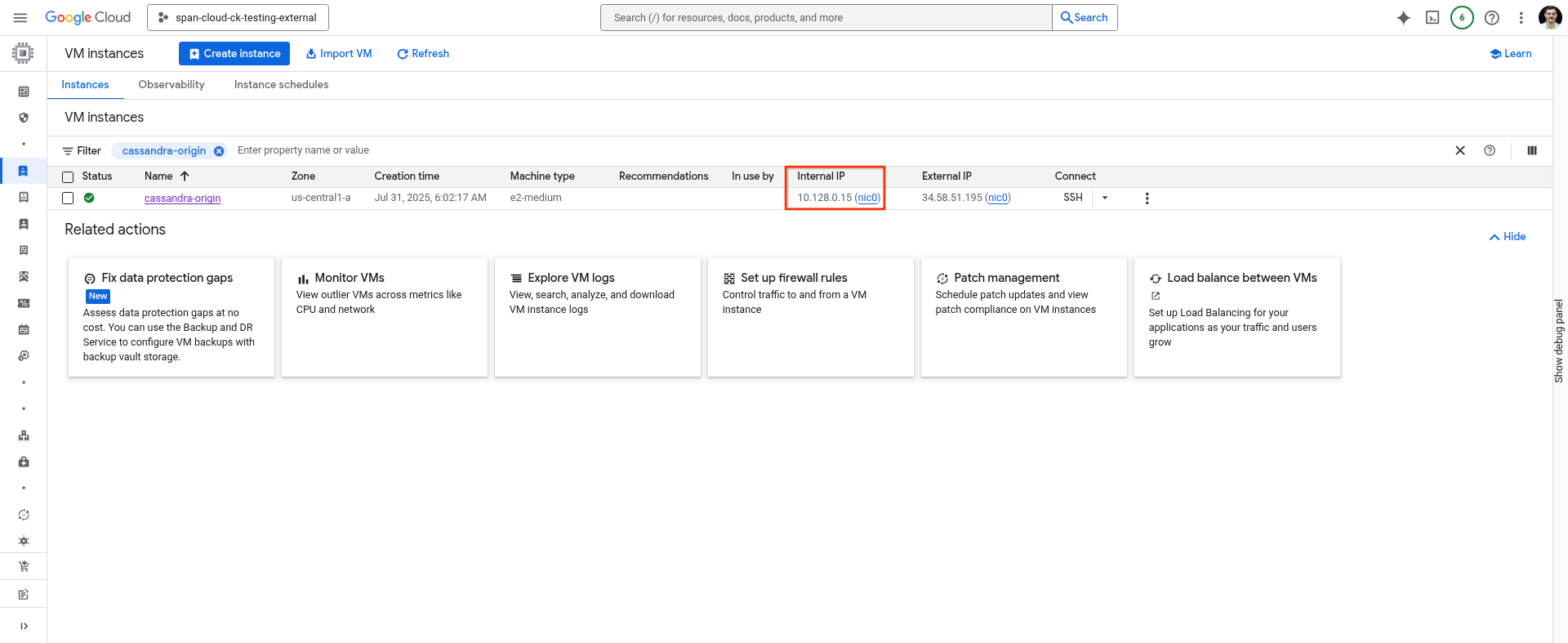
Запишите IP-адрес вашего компьютера.
Вы можете использовать следующую команду либо в облачной оболочке, либо получить её на странице VM Instances в облачной консоли.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
ИЛИ
 .
.
Обновите адрес в конфигурационном файле.
Для обновления конфигурационного файла Cassandra вы можете использовать любой редактор по вашему выбору.
sudo vim /etc/cassandra/cassandra.yaml
Измените rpc_address: на IP-адрес виртуальной машины, сохраните и закройте файл.
Включите службу Cassandra на виртуальной машине.
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Создайте пространство ключей и таблицу {create-keyspace-and-table}
Мы воспользуемся примером таблицы "users" и создадим пространство ключей под названием "analytics".
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
Внутри cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Оставьте SSH-сессию открытой или запишите IP-адрес этой виртуальной машины ( hostname -I ).
Далее
Далее вам предстоит настроить экземпляр Cloud Spanner и базу данных.
4. Создайте экземпляр Spanner (Target).
В Spanner экземпляр — это кластер вычислительных и дисковых ресурсов, на котором размещена одна или несколько баз данных Spanner. Для выполнения этого практического задания вам потребуется как минимум один экземпляр для размещения базы данных Spanner.
Проверьте версию SDK gcloud.
Перед созданием экземпляра убедитесь, что SDK gcloud в Google Cloud Shell обновлен до необходимой версии — любой версии выше gcloud SDK 531.0.0 . Версию вашего SDK gcloud можно узнать, выполнив следующую команду.
$ gcloud version | grep Google
Вот пример выходных данных:
Google Cloud SDK 489.0.0
Если используемая вами версия старше требуемой 531.0.0 ( 489.0.0 в предыдущем примере), вам необходимо обновить Google Cloud SDK, выполнив следующую команду:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Включите API Spanner
Внутри Cloud Shell убедитесь, что идентификатор вашего проекта настроен. Используйте первую команду ниже, чтобы найти текущий настроенный идентификатор проекта. Если результат не соответствует ожиданиям, вторая команда ниже установит правильный идентификатор.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Установите регион по умолчанию на us-central1 . При желании вы можете изменить его на другой регион, поддерживаемый региональными настройками Spanner.
gcloud config set compute/region us-central1
Включите API Spanner:
gcloud services enable spanner.googleapis.com
Создайте экземпляр Spanner.
В этом разделе вы создадите либо бесплатный пробный экземпляр , либо выделенный экземпляр . В этом практическом занятии в качестве идентификатора экземпляра адаптера Spanner Cassandra используется cassandra-adapter-demo , который задается как переменная SPANNER_INSTANCE_ID с помощью команды export . При желании вы можете выбрать собственное имя идентификатора экземпляра.
Создайте бесплатный пробный экземпляр Spanner.
Бесплатная 90-дневная пробная версия Spanner доступна всем пользователям с учетной записью Google, у которых включена функция Cloud Billing в проекте. Плата взимается только в том случае, если вы решите перейти с бесплатной пробной версии на платную. В бесплатной пробной версии поддерживается адаптер Spanner Cassandra. Если вы соответствуете условиям, создайте бесплатную пробную версию, открыв Cloud Shell и выполнив следующую команду:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Вывод команды:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Перенесите схему и модель данных Cassandra в Spanner.
Начальный и решающий этап переноса данных из базы данных Cassandra в Spanner включает в себя преобразование существующей схемы Cassandra в соответствии со структурными требованиями и требованиями к типам данных Spanner.
Для упрощения этого сложного процесса миграции схемы используйте один из двух полезных инструментов с открытым исходным кодом, предоставляемых Spanner:
- Инструмент миграции Spanner : Этот инструмент помогает перенести схему, подключившись к существующей базе данных Cassandra и перенеся схему в Spanner. Этот инструмент доступен как часть
gcloud cli. - Инструмент Spanner Cassandra Schema Tool : Этот инструмент помогает преобразовать экспортированный DDL-скрипт из Cassandra в Spanner. Для выполнения этого практического задания вы можете использовать любой из этих двух инструментов. В данном задании мы будем использовать инструмент Spanner Migration Tool для миграции схемы.
Инструмент миграции Spanner
Инструмент миграции Spanner помогает переносить схемы данных из различных источников, таких как MySQL, Postgres, Cassandra и др.
Хотя для целей данного практического занятия мы будем использовать интерфейс командной строки этого инструмента, мы настоятельно рекомендуем изучить и использовать версию с пользовательским интерфейсом, которая также поможет вам вносить изменения в схему Spanner перед ее применением.
Обратите внимание, что если spanner-migration-tool запускается в Cloud Shell, он может не иметь доступа к внутреннему IP-адресу вашей виртуальной машины Cassandra. Поэтому мы рекомендуем запускать его на той виртуальной машине, где вы установили Cassandra.
Выполните следующие действия на виртуальной машине, где вы установили Cassandra.
Установите инструмент миграции Spanner.
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Если у вас возникнут проблемы с установкой, обратитесь к инструкции по установке инструмента миграции Spanner (installing-spanner-migration-tool) для получения подробных указаний.
Обновить учетные данные Gcloud
gcloud auth login
gcloud auth application-default login
Миграция схемы
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Проверьте DDL гаечного ключа.
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
По завершении миграции схемы результат выполнения этой команды должен быть следующим:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Необязательно) См. преобразованный DDL
Вы можете просмотреть преобразованный DDL-скрипт и повторно применить его в Spanner (если вам потребуются дополнительные изменения).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
Результатом выполнения этой команды будет следующее:
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(Необязательно) См. отчет о преобразовании
cat `ls -t cassandra_*report.txt | head -n 1`
В отчете о преобразовании выделены проблемы, которые следует учитывать. Например, если существует несоответствие максимальной точности столбца между исходными данными и данными Spanner, это будет отмечено здесь.
6. Массовый экспорт исторических данных.
Для выполнения массовой миграции вам потребуется:
- Создайте или повторно используйте существующий сегмент GCS.
- Загрузите файл конфигурации драйвера Cassandra в хранилище.
- Запустить массовую миграцию.
Хотя вы можете запустить массовую миграцию как из Cloud Shell, так и из недавно созданной виртуальной машины, мы рекомендуем использовать виртуальную машину для этого практического занятия, поскольку некоторые шаги, такие как создание файла конфигурации, приведут к сохранению файлов в локальном хранилище.
Создайте хранилище GCS.
В конце этого шага вы должны были создать корзину GCS и экспортировать ее путь в переменную с именем CASSANDRA_BUCKET_NAME . Если вы хотите повторно использовать существующую корзину, просто экспортируйте путь.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Создайте и загрузите файл конфигурации драйвера.
Здесь мы загружаем очень простой файл конфигурации драйвера Cassandra. Полный формат файла см. здесь .
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Выполнить массовую миграцию
Это пример команды для выполнения массовой миграции ваших данных в Spanner. Для реальных сценариев использования в производственной среде вам потребуется изменить тип машины и количество в соответствии с желаемым масштабом и пропускной способностью. Полный список параметров см. в файле README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration .
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
В результате будет сгенерирован вывод, подобный следующему. Запомните сгенерированный id и используйте его для запроса статуса задания потока данных.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Выполните указанную ниже команду, чтобы проверить статус задания, и дождитесь, пока статус изменится на JOB_STATE_DONE .
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Изначально задание будет находиться в состоянии очереди, например:
currentState: JOB_STATE_QUEUED
Пока задание находится в очереди/выполняется, мы настоятельно рекомендуем вам изучить страницу Dataflow/Jobs в пользовательском интерфейсе Cloud Console, чтобы отслеживать его выполнение.
После завершения выполнения состояние задачи изменится следующим образом:
currentState: JOB_STATE_DONE
7. Направьте ваше приложение на Spanner (переход на новую систему).
После тщательной проверки точности и целостности ваших данных на этапе миграции, ключевым шагом является переход от операционной деятельности вашего приложения с устаревшей системы Cassandra к новой базе данных Spanner. Этот критически важный переходный период обычно называют « переключением ».
Этап переключения знаменует собой момент, когда трафик работающих приложений перенаправляется с исходного кластера Cassandra на прямое подключение к надежной и масштабируемой инфраструктуре Spanner. Этот переход демонстрирует простоту использования приложениями возможностей Spanner, особенно при использовании интерфейса Spanner Cassandra.
Благодаря интерфейсу Spanner Cassandra процесс перехода значительно упрощается. В первую очередь он заключается в настройке клиентских приложений для использования собственного клиента Spanner Cassandra для всего взаимодействия с данными. Вместо связи с вашей базой данных Cassandra (исходной), ваши приложения начнут беспрепятственно читать и записывать данные непосредственно в Spanner (целевую базу данных). Этот фундаментальный сдвиг в способах подключения обычно достигается с помощью SpannerCqlSessionBuilder , ключевого компонента библиотеки Spanner Cassandra Client, который упрощает установление соединений с вашим экземпляром Spanner. Это фактически перенаправляет весь поток данных вашего приложения в Spanner.
Для Java-приложений, уже использующих библиотеку cassandra-java-driver , интеграция Spanner Cassandra Java Client требует лишь незначительных изменений в инициализации CqlSession .
Получение зависимости google-cloud-spanner-cassandra
Для начала использования клиента Spanner Cassandra необходимо добавить его зависимость в ваш проект. Артефакты google-cloud-spanner-cassandra опубликованы в Maven Central в группе с ID com.google.cloud . Добавьте следующую новую зависимость в существующий раздел <dependencies> вашего Java-проекта. Вот упрощенный пример того, как можно включить зависимость google-cloud-spanner-cassandra :
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Измените конфигурацию подключения для соединения с Spanner.
После добавления необходимых зависимостей следующим шагом будет изменение конфигурации подключения для соединения с базой данных Spanner.
Типичное приложение, взаимодействующее с кластером Cassandra, часто использует код, аналогичный приведенному ниже, для установления соединения:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Чтобы перенаправить это соединение на Spanner, вам необходимо изменить логику создания CqlSession . Вместо прямого использования стандартного CqlSessionBuilder из cassandra-java-driver , вы будете использовать SpannerCqlSession.builder() , предоставляемый клиентом Spanner Cassandra. Вот наглядный пример того, как изменить код подключения:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
Создав экземпляр CqlSession с помощью SpannerCqlSession.builder() и указав правильный databaseUri , ваше приложение теперь установит соединение через клиент Spanner Cassandra с целевой базой данных Spanner. Это ключевое изменение гарантирует, что все последующие операции чтения и записи, выполняемые вашим приложением, будут направляться в Spanner и обслуживаться им, фактически завершая первоначальный переход. На этом этапе ваше приложение должно продолжать функционировать как ожидается, теперь благодаря масштабируемости и надежности Spanner.
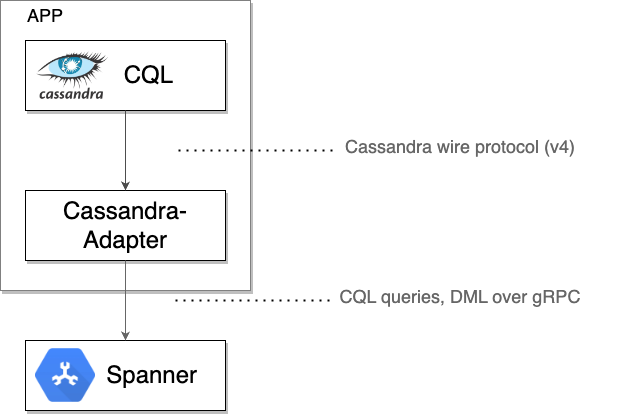
«Под капотом»: как работает клиент Spanner Cassandra.
Клиент Spanner Cassandra действует как локальный TCP-прокси, перехватывая необработанные байты протокола Cassandra, отправляемые драйвером или клиентским инструментом. Затем он упаковывает эти байты вместе с необходимыми метаданными в сообщения gRPC для связи со Spanner. Ответы от Spanner преобразуются обратно в формат протокола Cassandra и отправляются обратно исходному драйверу или инструменту.
Как только вы убедитесь, что Spanner корректно обрабатывает весь трафик, вы сможете в конечном итоге:
- Вывести из эксплуатации исходный кластер Cassandra.
8. Уборка (необязательно)
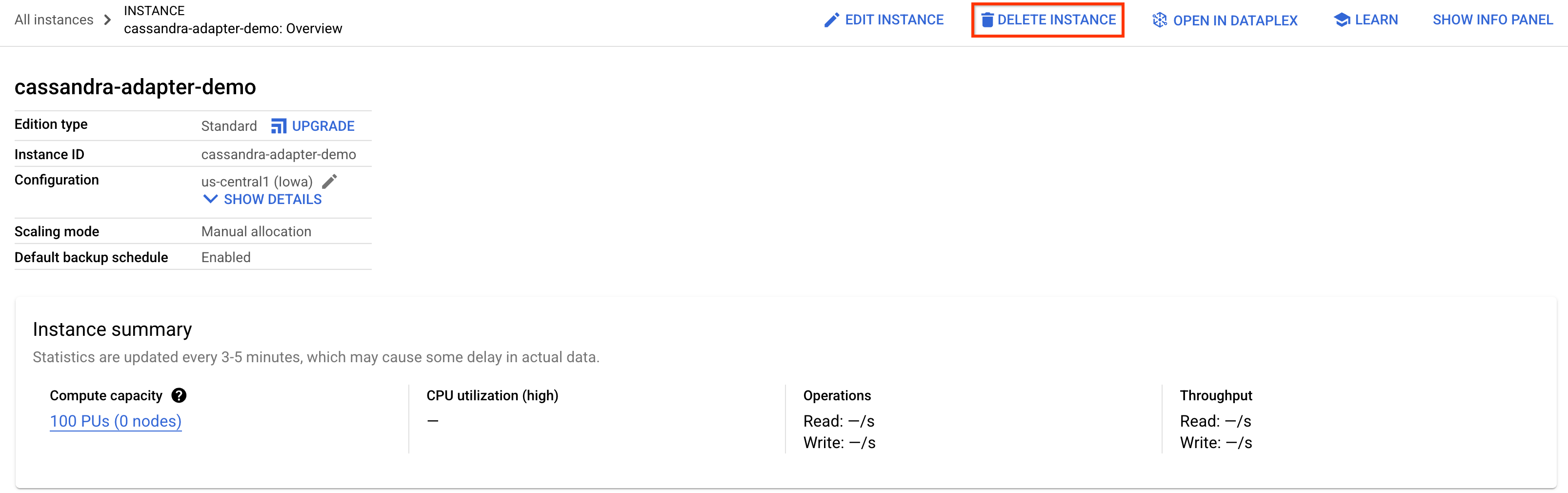
Для очистки просто перейдите в раздел Spanner в Cloud Console и удалите экземпляр cassandra-adapter-demo который мы создали в практическом задании.
Удалите базу данных Cassandra (если она установлена локально или сохранена).
Если вы установили Cassandra вне виртуальной машины Compute Engine, созданной здесь, выполните соответствующие действия для удаления данных или деинсталляции Cassandra.
9. Поздравляем!
Что дальше?
- Узнайте больше о Spanner .
- Узнайте больше об интерфейсе Cassandra .