
1. Introdução
O Spanner é um serviço de banco de dados totalmente gerenciado, escalonável horizontalmente e distribuído globalmente, ideal para cargas de trabalho relacionais e não relacionais.
Com a interface do Cassandra do Spanner, você aproveita a infraestrutura totalmente gerenciada, escalonável e altamente disponível do Spanner usando ferramentas e sintaxe conhecidas do Cassandra.
O que você vai aprender
- Como configurar uma instância e um banco de dados do Spanner.
- Como converter seu esquema e modelo de dados do Cassandra.
- Como exportar em massa seus dados históricos do Cassandra para o Spanner.
- Como direcionar seu aplicativo para o Spanner em vez do Cassandra.
O que é necessário
- Um projeto na nuvem do Google Cloud conectado a uma conta de faturamento.
- Acesso a uma máquina com a CLI
gcloudinstalada e configurada ou use o Google Cloud Shell. - Um navegador da Web, como o Chrome ou o Firefox.
2. Configuração e requisitos
Criar um projeto do GCP
Faça login no console do Google Cloud e crie um novo projeto ou reutilize um existente. Se você ainda não tem uma conta do Gmail ou do Google Workspace, crie uma.

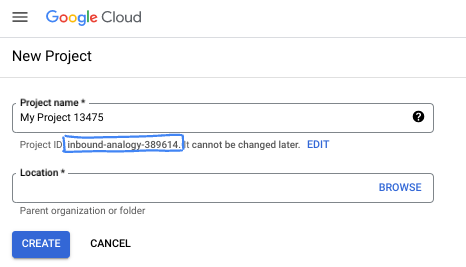
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
Configuração de faturamento
Em seguida, siga o guia do usuário para gerenciar o faturamento e ative o faturamento no console do Cloud. Novos usuários do Google Cloud estão qualificados para o programa de US$300 de avaliação sem custos. Para evitar cobranças além deste tutorial, desligue a instância do Spanner ao final do codelab seguindo a "Etapa 9: limpeza".
Iniciar o Cloud Shell
Embora o Google Cloud possa ser operado remotamente do seu laptop, neste codelab vamos usar o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:

O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
A seguir
Em seguida, você vai implantar o cluster do Cassandra.
3. Implantar cluster do Cassandra (origem)
Neste codelab, vamos configurar um cluster do Cassandra de nó único no Compute Engine.
1. Criar uma VM do GCE para o Cassandra
Para criar uma instância, use o comando gcloud compute instances create do Cloud Shell provisionado anteriormente.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Instalar o Cassandra
Navegue até VM Instances na página Navigation menu seguindo as instruções abaixo:  .
.
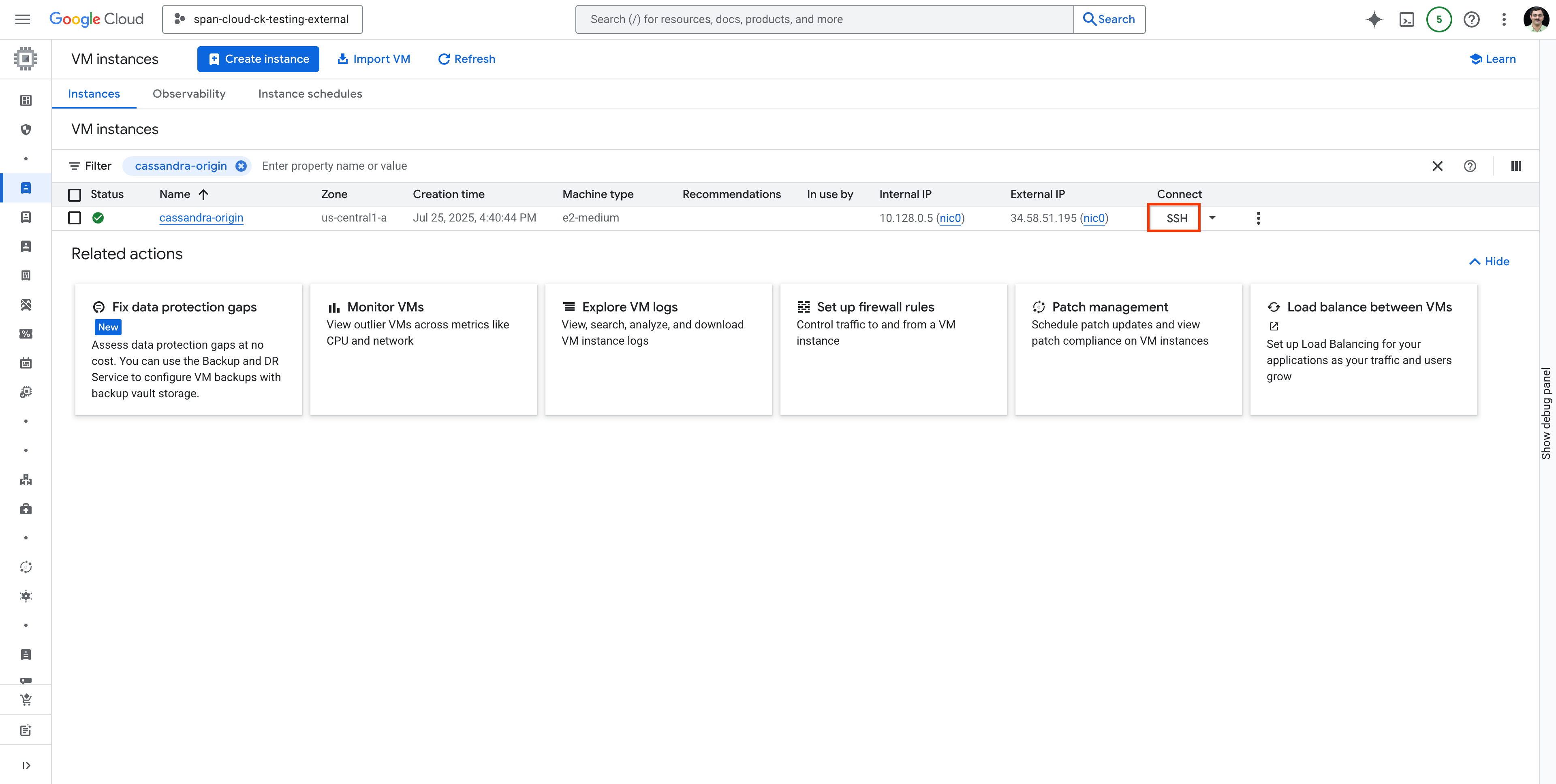
Pesquise a VM cassandra-origin e conecte-se a ela usando SSH, conforme mostrado:
 .
.
Execute os comandos a seguir para instalar o Cassandra na VM que você criou e em que fez login por SSH.
Instalar o Java (dependência do Cassandra)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Adicionar o repositório do Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Instalar o Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
Defina o endereço de escuta para o serviço do Cassandra.
Aqui, usamos o endereço IP interno da VM do Cassandra para aumentar a segurança.
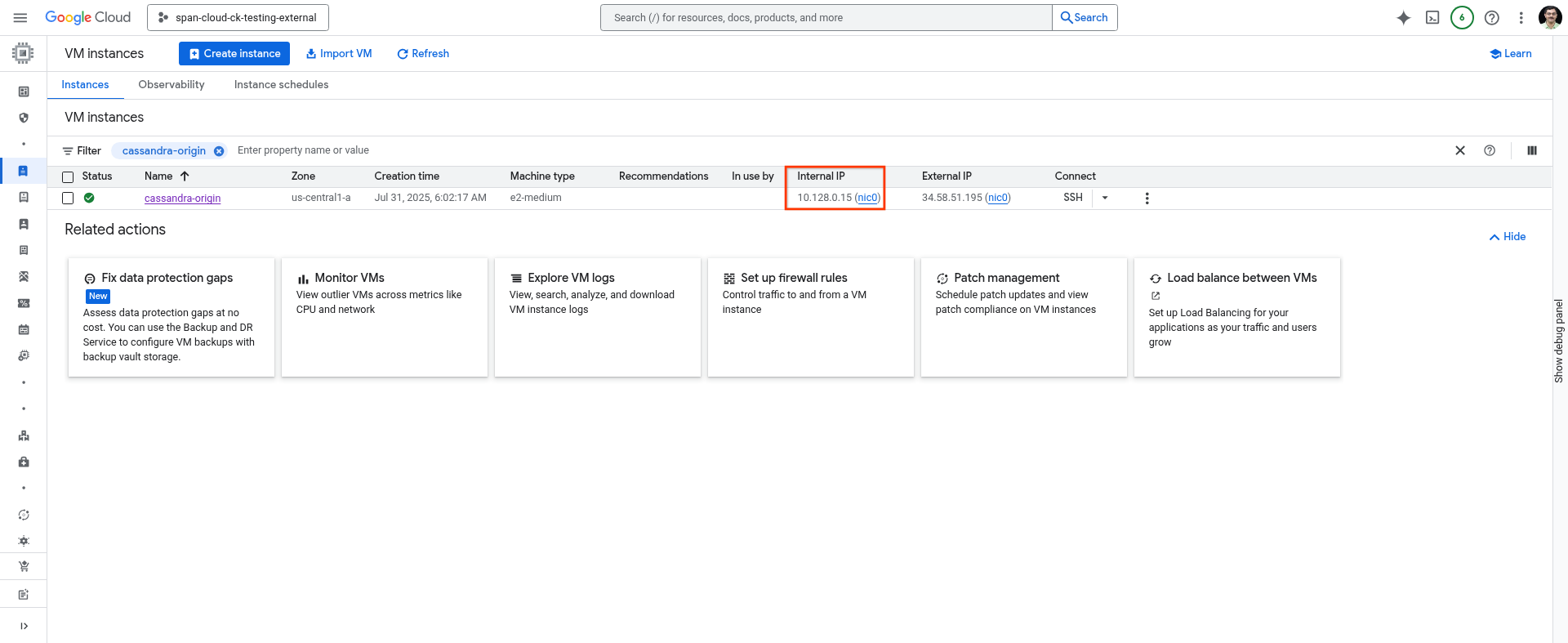
Anote o endereço IP da máquina host.
Use o seguinte comando no Cloud Shell ou acesse a página VM Instances do console do Cloud.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
OU
 .
.
Atualize o endereço no arquivo de configuração
Use o editor de sua escolha para atualizar o arquivo de configuração do Cassandra.
sudo vim /etc/cassandra/cassandra.yaml
mude rpc_address: para o endereço IP da VM, salve e feche o arquivo.
Ativar o serviço do Cassandra na VM
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Criar um keyspace e uma tabela {create-keyspace-and-table}
Vamos usar um exemplo de tabela "users" e criar um keyspace chamado "analytics".
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
No cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Deixe a sessão SSH aberta ou anote o endereço IP dessa VM (hostname -I).
A seguir
Em seguida, configure uma instância e um banco de dados do Cloud Spanner.
4. Criar uma instância do Spanner (destino)
No Spanner, uma instância é um cluster de recursos de computação e armazenamento que hospeda um ou mais bancos de dados do Spanner. Você vai precisar de pelo menos uma instância para hospedar um banco de dados do Spanner para este codelab.
Verificar a versão do SDK do gcloud
Antes de criar uma instância, verifique se o SDK gcloud no Google Cloud Shell foi atualizado para a versão necessária (qualquer versão maior que SDK gcloud 531.0.0). Para encontrar a versão do SDK gcloud, siga o comando abaixo.
$ gcloud version | grep Google
Confira um exemplo de saída:
Google Cloud SDK 489.0.0
Se a versão que você está usando for anterior à 531.0.0 (489.0.0 no exemplo anterior), faça upgrade do SDK Google Cloud executando o seguinte comando:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Ativar a API Spanner
No Cloud Shell, verifique se o ID do projeto está configurado. Use o primeiro comando abaixo para encontrar o ID do projeto configurado no momento. Se o resultado não for o esperado, o segundo comando abaixo vai definir o correto.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Configure sua região padrão como us-central1. Mude para outra região compatível com as configurações regionais do Spanner.
gcloud config set compute/region us-central1
Ative a API Spanner:
gcloud services enable spanner.googleapis.com
Criar a instância do Spanner
Nesta seção, você vai criar uma instância de teste sem custo financeiro ou uma instância provisionada. Neste codelab, o ID da instância do adaptador do Spanner Cassandra usado é cassandra-adapter-demo, definido como a variável SPANNER_INSTANCE_ID usando a linha de comando export. Se quiser, escolha seu próprio nome de ID da instância.
Criar uma instância de teste sem custo financeiro do Spanner
Uma instância de teste sem custo financeiro de 90 dias do Spanner está disponível para qualquer pessoa com uma Conta do Google que tenha o Cloud Billing ativado no projeto. Você não vai receber cobranças a menos que faça upgrade da instância de teste sem custo financeiro para uma instância paga. O adaptador do Spanner para Cassandra é compatível com a instância de teste sem custo financeiro. Se você se qualificar, crie uma instância de teste sem custos financeiros abrindo o Cloud Shell e executando este comando:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Saída de comando:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Migrar o esquema e o modelo de dados do Cassandra para o Spanner
A fase inicial e crucial da transição de dados de um banco de dados do Cassandra para o Spanner envolve a transformação do esquema do Cassandra existente para se alinhar aos requisitos estruturais e de tipo de dados do Spanner.
Para simplificar esse processo complexo de migração de esquema, use uma das duas ferramentas de código aberto valiosas fornecidas pelo Spanner:
- Ferramenta de migração do Spanner: ajuda a migrar o esquema conectando-se a um banco de dados do Cassandra e migrando o esquema para o Spanner. Essa ferramenta está disponível como parte do
gcloud cli. - Ferramenta de esquema do Spanner Cassandra: ajuda a converter uma DDL exportada do Cassandra para o Spanner. Você pode usar qualquer uma dessas duas ferramentas para o codelab. Neste codelab, vamos usar a ferramenta de migração do Spanner para migrar o esquema.
Ferramenta de migração do Spanner
A ferramenta de migração do Spanner ajuda a migrar esquemas de várias fontes de dados, como MySQL, Postgres, Cassandra etc.
Para este codelab, vamos usar a CLI dessa ferramenta, mas recomendamos muito que você conheça e use a versão baseada na interface, que também ajuda a fazer modificações no esquema do Spanner antes da aplicação.
Se o spanner-migration-tool for executado no Cloud Shell, talvez ele não tenha acesso ao endereço IP interno da VM do Cassandra. Por isso, recomendamos executar o mesmo na VM em que você instalou o Cassandra.
Execute o seguinte na VM em que você instalou o Cassandra.
Instalar a ferramenta de migração do Spanner
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Se você tiver problemas com a instalação, consulte installing-spanner-migration-tool para ver as etapas detalhadas.
Atualizar credenciais do gcloud
gcloud auth login
gcloud auth application-default login
Migrar esquema
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Verificar DDL do Spanner
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
No final da migração do esquema, a saída desse comando será:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Opcional) Confira a DDL convertida
Você pode conferir o DDL convertido e reaplicá-lo no Spanner (se precisar de mais mudanças).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
A saída desse comando seria
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(Opcional) Consulte o relatório de conversão
cat `ls -t cassandra_*report.txt | head -n 1`
O relatório de conversão destaca os problemas que você precisa ter em mente. Por exemplo, se houver uma incompatibilidade na precisão máxima de uma coluna entre a origem e o Spanner, ela será destacada aqui.
6. Exportar dados históricos em massa
Para fazer a migração em massa, você precisa:
- Provisione ou reutilize um bucket do GCS.
- Fazer upload do arquivo de configuração do driver do Cassandra para o bucket
- Inicie a migração em massa.
Embora seja possível iniciar a migração em massa no Cloud Shell ou na VM recém-provisionada, recomendamos usar a VM neste codelab, já que algumas etapas, como a criação de um arquivo de configuração, mantêm os arquivos no armazenamento local.
Provisione um bucket do GCS.
Ao final desta etapa, você terá provisionado um bucket do GCS e exportado o caminho dele em uma variável chamada CASSANDRA_BUCKET_NAME. Se você quiser reutilizar um bucket, basta exportar o caminho.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Criar e fazer upload do arquivo de configuração do driver
Aqui, fazemos upload de um arquivo de configuração muito básico do driver do Cassandra. Consulte este link para conferir o formato completo do arquivo.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Executar migração em massa
Este é um comando de exemplo para executar a migração em massa dos seus dados para o Spanner. Para casos de uso reais de produção, é necessário ajustar o tipo de máquina e a contagem de acordo com a escala e a capacidade de processamento desejadas. Acesse README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration para conferir a lista completa de opções.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
Isso vai gerar uma saída como esta: Observe o id gerado e use-o para consultar o status do job do Dataflow.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Execute o comando abaixo para verificar o status do job e aguarde até que ele mude para JOB_STATE_DONE.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Inicialmente, o job vai estar em um estado de fila, como
currentState: JOB_STATE_QUEUED
Enquanto o job está na fila/em execução, recomendamos que você acesse a página Dataflow/Jobs na interface do console do Cloud para monitorar o job.
Quando isso for feito, o estado do job vai mudar para:
currentState: JOB_STATE_DONE
7. Apontar o aplicativo para o Spanner (transição)
Depois de validar meticulosamente a precisão e a integridade dos seus dados após a fase de migração, a etapa principal é fazer a transição do foco operacional do aplicativo do sistema Cassandra legado para o banco de dados do Spanner recém-preenchido. Esse período de transição crítica é geralmente chamado de "cutover".
A fase de transição marca o momento em que o tráfego de aplicativos ativos é redirecionado do cluster original do Cassandra e conectado diretamente à infraestrutura robusta e escalonável do Spanner. Essa transição demonstra a facilidade com que os aplicativos podem aproveitar o poder do Spanner, especialmente ao usar a interface do Cassandra.
Com a interface do Spanner Cassandra, o processo de transição é simplificado. Isso envolve principalmente a configuração dos aplicativos cliente para usar o cliente nativo do Spanner Cassandra em todas as interações de dados. Em vez de se comunicar com o banco de dados Cassandra (origem), seus aplicativos vão começar a ler e gravar dados diretamente no Spanner (destino). Essa mudança fundamental na conectividade normalmente é alcançada com o uso do SpannerCqlSessionBuilder, um componente essencial da biblioteca de cliente do Cassandra do Spanner que facilita o estabelecimento de conexões com sua instância do Spanner. Isso redireciona todo o fluxo de tráfego de dados do aplicativo para o Spanner.
Para aplicativos Java que já usam a biblioteca cassandra-java-driver, a integração do cliente Java do Spanner Cassandra exige apenas pequenas mudanças na inicialização do CqlSession.
Como receber a dependência google-cloud-spanner-cassandra
Para começar a usar o cliente do Spanner Cassandra, primeiro incorpore a dependência dele ao seu projeto. Os artefatos google-cloud-spanner-cassandra são publicados na Central da Maven, no ID do grupo com.google.cloud. Adicione a seguinte dependência à seção <dependencies> do seu projeto Java. Confira um exemplo simplificado de como incluir a dependência google-cloud-spanner-cassandra:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Mudar a configuração de conexão para se conectar ao Spanner
Depois de adicionar a dependência necessária, a próxima etapa é mudar a configuração de conexão para se conectar ao banco de dados do Spanner.
Um aplicativo típico que interage com um cluster do Cassandra geralmente usa um código semelhante ao seguinte para estabelecer uma conexão:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Para redirecionar essa conexão ao Spanner, modifique a lógica de criação de CqlSession. Em vez de usar diretamente o CqlSessionBuilder padrão do cassandra-java-driver, você vai usar o SpannerCqlSession.builder() fornecido pelo cliente do Spanner Cassandra. Confira um exemplo ilustrativo de como modificar o código de conexão:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
Ao instanciar o CqlSession usando SpannerCqlSession.builder() e fornecer o databaseUri correto, seu aplicativo vai estabelecer uma conexão pelo cliente do Spanner Cassandra com o banco de dados de destino do Spanner. Essa mudança fundamental garante que todas as operações de leitura e gravação subsequentes realizadas pelo aplicativo sejam direcionadas e atendidas pelo Spanner, concluindo efetivamente a transição inicial. Neste ponto, o aplicativo vai continuar funcionando conforme o esperado, agora com a escalonabilidade e a confiabilidade do Spanner.
Por dentro: como o cliente do Spanner Cassandra opera
O cliente do Spanner Cassandra atua como um proxy TCP local, interceptando os bytes brutos do protocolo Cassandra enviados por um driver ou uma ferramenta de cliente. Em seguida, ele encapsula esses bytes com os metadados necessários em mensagens gRPC para comunicação com o Spanner. As respostas do Spanner são traduzidas de volta para o formato de fio do Cassandra e enviadas ao driver ou ferramenta de origem.
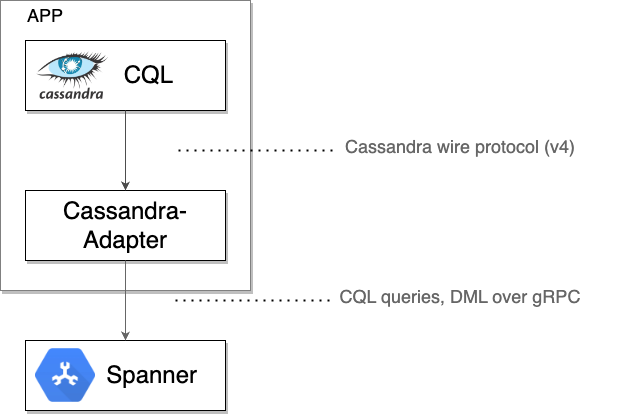
Quando tiver certeza de que o Spanner está atendendo todo o tráfego corretamente, você poderá:
- Desative o cluster original do Cassandra.
8. Limpeza (opcional)
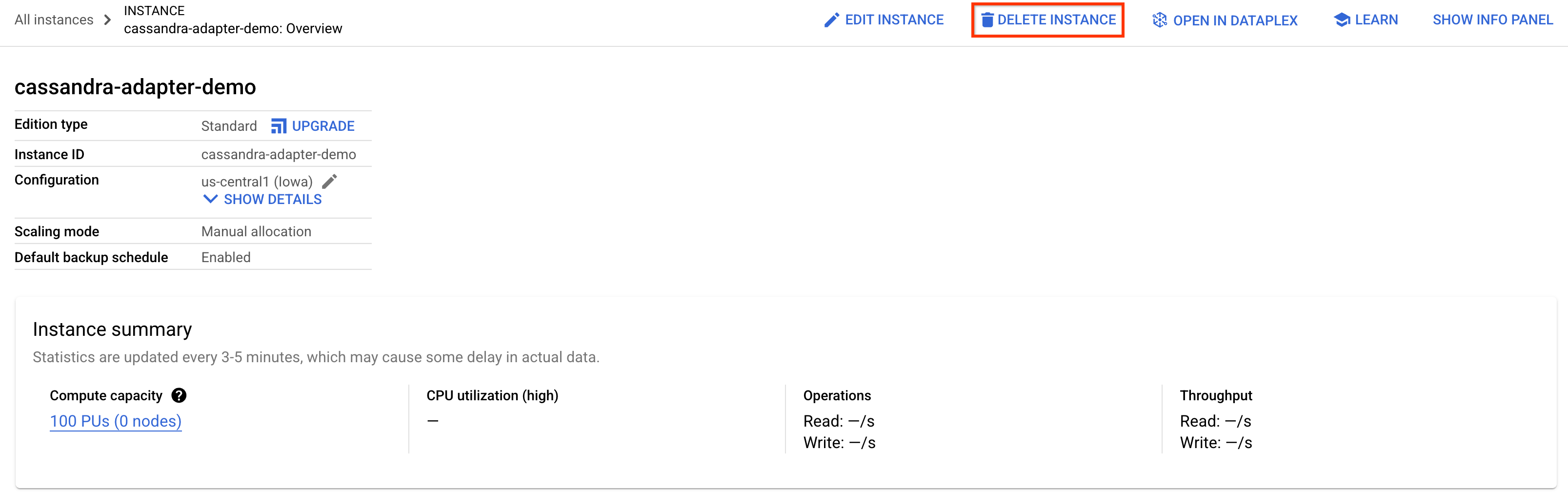
Para liberar espaço, basta acessar a seção Spanner do console do Cloud e excluir a instância cassandra-adapter-demo que criamos no codelab.
Excluir o banco de dados do Cassandra (se instalado localmente ou persistido)
Se você instalou o Cassandra fora de uma VM do Compute Engine criada aqui, siga as etapas adequadas para remover os dados ou desinstalar o Cassandra.
9. Parabéns!
A seguir
- Saiba mais sobre o Spanner.
- Saiba mais sobre a interface do Cassandra.