
1. Wprowadzenie
Spanner to usługa baz danych w pełni zarządzana, skalowalna w poziomie i rozmieszczona globalnie, która doskonale sprawdza się w przypadku obciążeń relacyjnych i nierelacyjnych.
Interfejs Cassandra usługi Spanner umożliwia korzystanie z w pełni zarządzanej, skalowalnej i wysoce dostępnej infrastruktury Spanner przy użyciu znanych narzędzi i składni Cassandra.
Czego się nauczysz
- Jak skonfigurować instancję i bazę danych Spanner.
- Jak przekonwertować schemat i model danych Cassandra.
- Jak zbiorczo eksportować dane historyczne z Cassandry do Spannera.
- Jak przekierować aplikację do Spannera zamiast do Cassandry.
Czego potrzebujesz
- Projekt Google Cloud połączony z kontem rozliczeniowym.
- Dostęp do maszyny z zainstalowanym i skonfigurowanym interfejsem
gcloudwiersza poleceń lub użyj Google Cloud Shell. - przeglądarka, np. Chrome lub Firefox;
2. Konfiguracja i wymagania
Tworzenie projektu GCP
Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
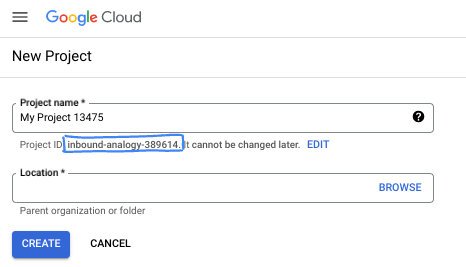
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
Konfiguracja płatności
Następnie musisz postępować zgodnie z przewodnikiem użytkownika dotyczącym zarządzania płatnościami i włączyć płatności w konsoli Google Cloud. Nowi użytkownicy Google Cloud mogą skorzystać z programu bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD. Aby uniknąć naliczania opłat po ukończeniu tego samouczka, możesz wyłączyć instancję Spanner na końcu ćwiczenia, wykonując czynności opisane w sekcji „Krok 9. Czyszczenie”.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:

Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym ćwiczeniu w Codelabs możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Następny krok
Następnie wdrożysz klaster Cassandra.
3. Wdrażanie klastra Cassandra (źródło)
W tym ćwiczeniu skonfigurujemy 1-węzłowy klaster Cassandra w Compute Engine.
1. Tworzenie maszyny wirtualnej GCE na potrzeby Cassandra
Aby utworzyć instancję, użyj polecenia gcloud compute instances create z wcześniej udostępnionego Cloud Shell.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Instalowanie systemu Cassandra
Otwórz VM Instances ze strony Navigation menu, postępując zgodnie z instrukcjami poniżej:  .
.
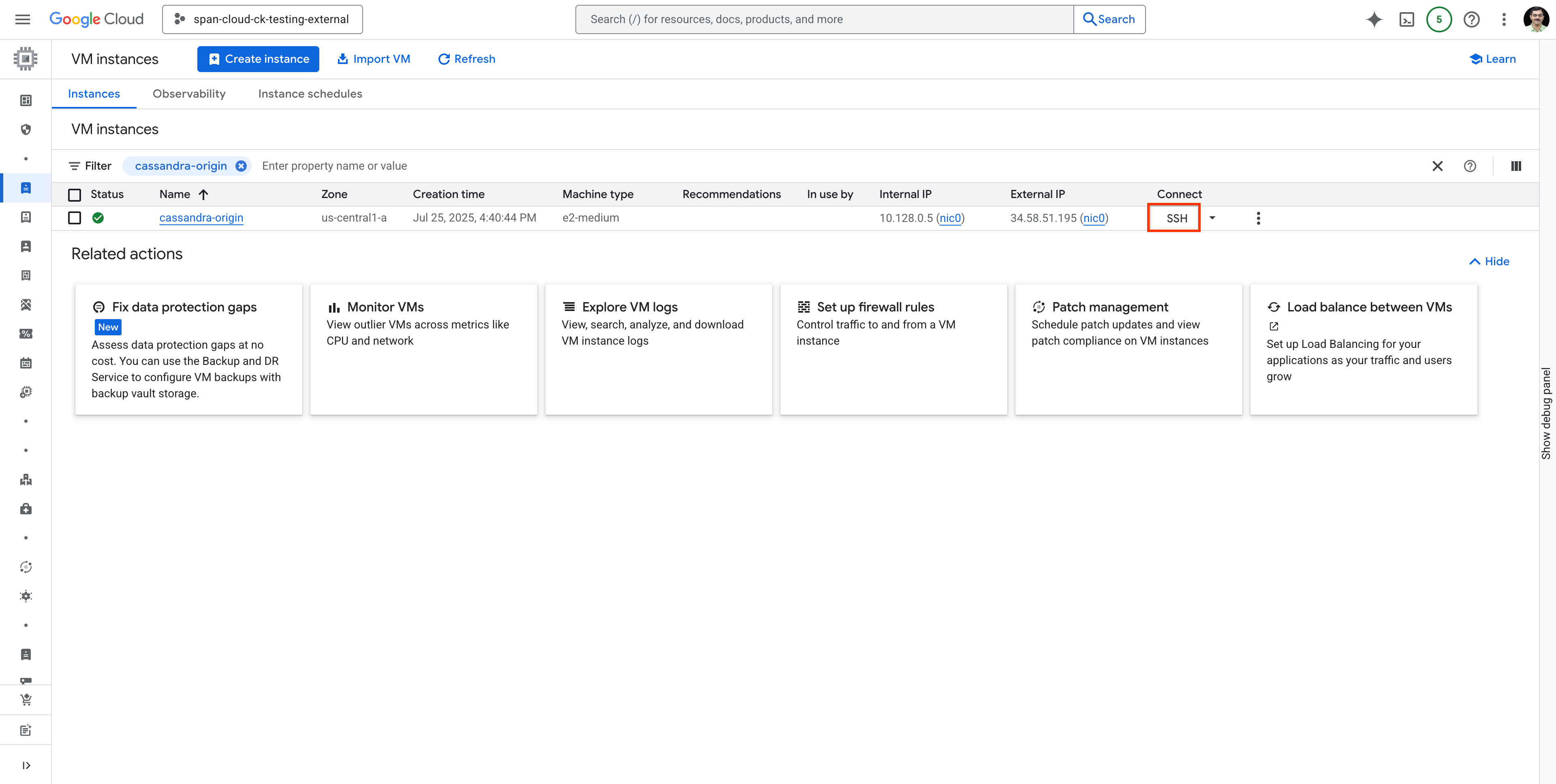
Wyszukaj maszynę wirtualną cassandra-origin i połącz się z nią za pomocą SSH w sposób pokazany poniżej:
 .
.
Uruchom te polecenia, aby zainstalować Cassandrę na utworzonej maszynie wirtualnej, do której masz dostęp przez SSH.
Instalowanie Javy (zależność Cassandra)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Dodawanie repozytorium Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Instalowanie systemu Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
Ustaw adres nasłuchiwania usługi Cassandra.
Dla większego bezpieczeństwa używamy tu wewnętrznego adresu IP maszyny wirtualnej Cassandra.
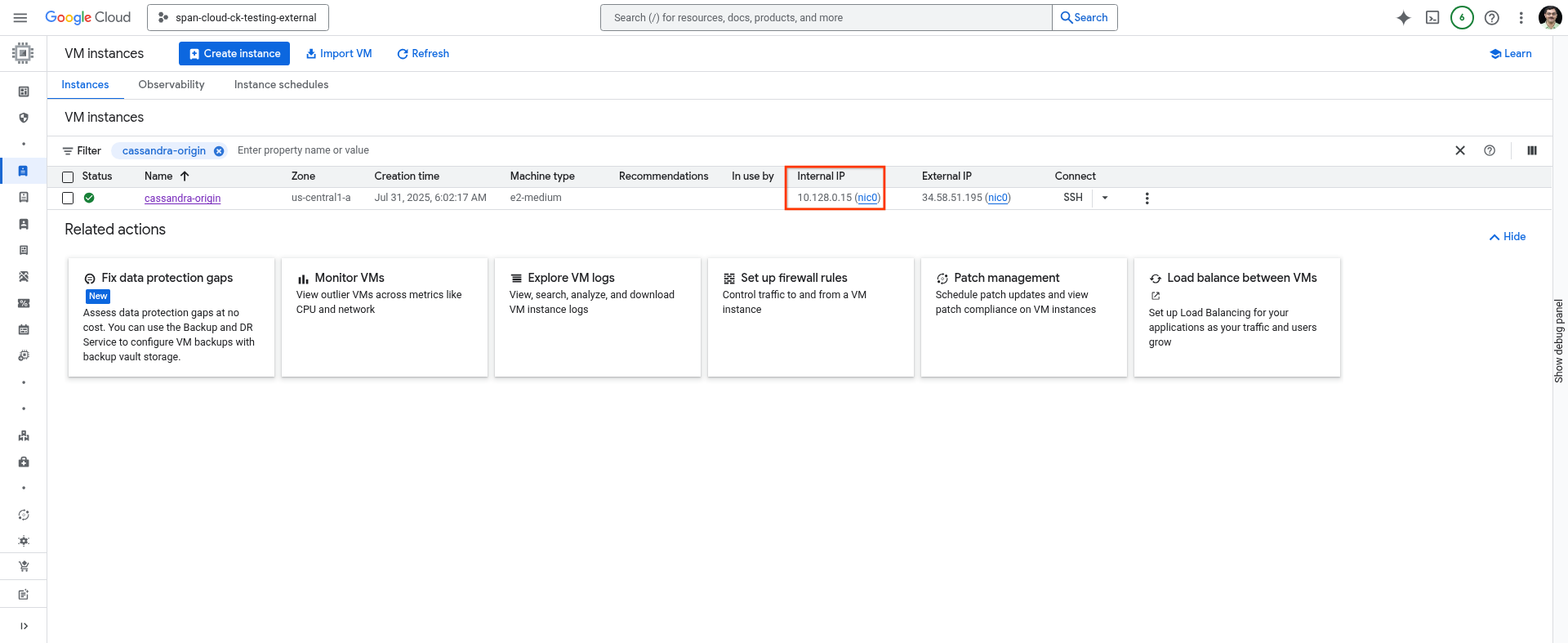
Zapisz adres IP komputera hosta.
Możesz użyć tego polecenia w Cloud Shell lub pobrać je ze strony VM Instances w konsoli Cloud.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
LUB
 .
.
Aktualizowanie adresu w pliku konfiguracji
Możesz użyć wybranego edytora, aby zaktualizować plik konfiguracyjny Cassandra.
sudo vim /etc/cassandra/cassandra.yaml
zmień rpc_address: na adres IP maszyny wirtualnej, zapisz i zamknij plik.
Włączanie usługi Cassandra na maszynie wirtualnej
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Tworzenie przestrzeni kluczy i tabeli {create-keyspace-and-table}
Użyjemy przykładowej tabeli „users” i utworzymy przestrzeń kluczy o nazwie „analytics”.
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
W cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Pozostaw sesję SSH otwartą lub zapisz adres IP tej maszyny wirtualnej (hostname -I).
Następny krok
Następnie skonfigurujesz instancję i bazę danych Cloud Spanner.
4. Tworzenie instancji usługi Spanner (miejsce docelowe)
W Spanner instancja to klaster zasobów obliczeniowych i pamięci masowej, który hostuje co najmniej jedną bazę danych Spanner. Aby przeprowadzić te ćwiczenia, musisz mieć co najmniej 1 instancję do hostowania bazy danych Spanner.
Sprawdzanie wersji pakietu SDK gcloud
Zanim utworzysz instancję, upewnij się, że pakiet gcloud SDK w Google Cloud Shell został zaktualizowany do wymaganej wersji – dowolnej wersji nowszej niż gcloud SDK 531.0.0. Aby sprawdzić wersję pakietu SDK gcloud, wykonaj to polecenie.
$ gcloud version | grep Google
Przykładowe dane wyjściowe:
Google Cloud SDK 489.0.0
Jeśli używana wersja jest starsza niż wymagana wersja 531.0.0 (489.0.0 w poprzednim przykładzie), musisz uaktualnić pakiet Google Cloud SDK, wykonując to polecenie:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Włączanie interfejsu Spanner API
W Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany. Użyj pierwszego polecenia poniżej, aby znaleźć aktualnie skonfigurowany identyfikator projektu. Jeśli wynik jest nieoczekiwany, drugie polecenie poniżej ustawia prawidłowy.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Skonfiguruj domyślny region na us-central1. Możesz zmienić ten region na inny obsługiwany przez konfiguracje regionalne Spanner.
gcloud config set compute/region us-central1
Włącz interfejs Spanner API:
gcloud services enable spanner.googleapis.com
Tworzenie instancji usługi Spanner
W tej sekcji utworzysz bezpłatną instancję próbną lub instancję z zarezerwowanymi zasobami. W tym ćwiczeniu używany jest identyfikator instancji adaptera Spanner Cassandra cassandra-adapter-demo, który jest ustawiony jako zmienna SPANNER_INSTANCE_ID za pomocą wiersza poleceń export. Opcjonalnie możesz wybrać własną nazwę identyfikatora instancji.
Tworzenie instancji próbnej Spanner
90-dniowa bezpłatna instancja próbna Spanner jest dostępna dla każdego, kto ma konto Google i włączone Rozliczenia usługi Google Cloud w projekcie. Nie pobierzemy żadnych opłat, dopóki nie przejdziesz z bezpłatnej wersji próbnej na wersję płatną. Adapter Spanner Cassandra jest obsługiwany w instancji bezpłatnej wersji próbnej. Jeśli kwalifikujesz się do skorzystania z bezpłatnej wersji próbnej, utwórz instancję próbną, otwierając Cloud Shell i uruchamiając to polecenie:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Wynik polecenia:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Migracja schematu i modelu danych Cassandra do Spanner
Początkowy i kluczowy etap przenoszenia danych z bazy danych Cassandra do Spannera obejmuje przekształcenie istniejącego schematu Cassandry w taki sposób, aby był zgodny z wymaganiami Spannera dotyczącymi struktury i typu danych.
Aby uprościć ten złożony proces migracji schematu, użyj jednego z 2 przydatnych narzędzi open source udostępnianych przez Spanner:
- Narzędzie do migracji usługi Spanner: to narzędzie pomaga przenieść schemat, łącząc się z istniejącą bazą danych Cassandra i przenosząc schemat do usługi Spanner. To narzędzie jest dostępne w ramach
gcloud cli. - Narzędzie do schematu Cassandra w Spannerze: to narzędzie pomaga przekonwertować wyeksportowany język DDL z Cassandry na Spanner. W tym ćwiczeniu możesz użyć dowolnego z tych dwóch narzędzi. W tym ćwiczeniu użyjemy narzędzia do migracji usługi Spanner, aby przenieść schemat.
Narzędzie do migracji do Spannera
Narzędzie do migracji usługi Spanner pomaga przenosić schematy z różnych źródeł danych, takich jak MySQL, Postgres czy Cassandra.
Na potrzeby tego ćwiczenia w Codelabs użyjemy interfejsu wiersza poleceń tego narzędzia, ale zdecydowanie zalecamy zapoznanie się z wersją narzędzia opartą na interfejsie użytkownika i korzystanie z niej. Umożliwia ona też wprowadzanie zmian w schemacie Spanner przed jego zastosowaniem.
Pamiętaj, że jeśli polecenie spanner-migration-tool jest uruchamiane w Cloud Shell, może nie mieć dostępu do wewnętrznego adresu IP maszyny wirtualnej Cassandra. Dlatego zalecamy uruchomienie go na maszynie wirtualnej, na której zainstalowano Cassandrę.
Wykonaj te czynności na maszynie wirtualnej, na której zainstalowano system Cassandra.
Instalowanie narzędzia Spanner Migration Tool
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Jeśli napotkasz problemy z instalacją, zapoznaj się ze szczegółowymi instrukcjami w artykule installing-spanner-migration-tool.
Odświeżanie danych logowania gcloud
gcloud auth login
gcloud auth application-default login
Migracja schematu
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Weryfikowanie języka DDL w usłudze Spanner
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
Po zakończeniu migracji schematu dane wyjściowe tego polecenia powinny wyglądać tak:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Opcjonalnie) Wyświetl przekonwertowany kod DDL
Możesz wyświetlić przekonwertowany język DDL i ponownie zastosować go w usłudze Spanner (jeśli potrzebujesz dodatkowych zmian).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
Wynikiem tego polecenia będzie
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(Opcjonalnie) Wyświetlanie raportu o konwersjach
cat `ls -t cassandra_*report.txt | head -n 1`
Raport o konwersjach zawiera informacje o problemach, na które warto zwrócić uwagę. Jeśli na przykład wystąpi niezgodność maksymalnej precyzji kolumny między źródłem a Spannerem, zostanie ona tutaj wyróżniona.
6. Zbiorcze eksportowanie danych historycznych
Aby przeprowadzić migrację zbiorczą:
- Utwórz nowy zasobnik GCS lub użyj istniejącego.
- Prześlij plik konfiguracyjny sterownika Cassandra do zasobnika.
- Uruchom migrację zbiorczą.
Migrację zbiorczą możesz uruchomić w Cloud Shell lub na nowo utworzonej maszynie wirtualnej, ale w tym samouczku zalecamy użycie maszyny wirtualnej, ponieważ niektóre czynności, takie jak utworzenie pliku konfiguracyjnego, spowodują zapisanie plików w pamięci lokalnej.
Udostępnij zasobnik GCS.
Po wykonaniu tego kroku powinien być już dostępny zasobnik GCS, a jego ścieżka powinna być wyeksportowana w zmiennej o nazwie CASSANDRA_BUCKET_NAME. Jeśli chcesz ponownie użyć istniejącego zasobnika, możesz po prostu wyeksportować ścieżkę.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Tworzenie i przesyłanie pliku konfiguracji sterownika
Przesyłamy tutaj bardzo prosty plik konfiguracji sterownika Cassandra. Pełny format pliku znajdziesz tutaj.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Uruchamianie migracji zbiorczej
To przykładowe polecenie służące do przeprowadzenia migracji zbiorczej danych do Spannera. W przypadku rzeczywistych zastosowań produkcyjnych musisz dostosować typ maszyny i liczbę instancji do żądanej skali i przepustowości. Pełną listę opcji znajdziesz w pliku README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
Wygeneruje to dane wyjściowe podobne do tych poniżej. Zanotuj wygenerowany identyfikator id i użyj go do sprawdzenia stanu zadania przepływu danych.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Uruchom to polecenie, aby sprawdzić stan zadania, i poczekaj, aż zmieni się na JOB_STATE_DONE.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Początkowo zadanie będzie w stanie oczekiwania, np.
currentState: JOB_STATE_QUEUED
Gdy zadanie jest w kolejce lub jest wykonywane, zdecydowanie zalecamy sprawdzenie strony Dataflow/Jobs w interfejsie Cloud Console, aby monitorować zadanie.
Po zakończeniu stan zadania zmieni się na:
currentState: JOB_STATE_DONE
7. Skierowanie aplikacji na Spannera (przełączenie)
Po dokładnym sprawdzeniu dokładności i integralności danych po fazie migracji kluczowym krokiem jest przeniesienie operacyjnego działania aplikacji z dotychczasowego systemu Cassandra na nowo wypełnioną bazę danych Spanner. Ten krytyczny okres przejściowy jest zwykle nazywany „przełączeniem”.
Faza przełączenia to moment, w którym ruch aplikacji na żywo jest przekierowywany z pierwotnego klastra Cassandra i bezpośrednio łączony z solidną i skalowalną infrastrukturą Spanner. Ta zmiana pokazuje, jak łatwo aplikacje mogą wykorzystywać możliwości Spannera, zwłaszcza gdy korzystają z interfejsu Spanner Cassandra.
Dzięki interfejsowi Spanner Cassandra proces przełączania jest uproszczony. Polega to głównie na skonfigurowaniu aplikacji klienckich tak, aby do wszystkich interakcji z danymi używały natywnego klienta Spanner Cassandra. Zamiast komunikować się z bazą danych Cassandra (źródłową), aplikacje zaczną bezproblemowo odczytywać i zapisywać dane bezpośrednio w Spannerze (docelowym). Ta zasadnicza zmiana w zakresie łączności jest zwykle osiągana dzięki użyciu SpannerCqlSessionBuilder, kluczowego komponentu biblioteki klienta Spanner Cassandra, który ułatwia nawiązywanie połączeń z instancją Spanner. Spowoduje to przekierowanie całego ruchu danych aplikacji do usługi Spanner.
W przypadku aplikacji w języku Java, które korzystają już z biblioteki cassandra-java-driver, integracja klienta Spanner Cassandra Java wymaga tylko niewielkich zmian w inicjowaniu CqlSession.
Pobieranie zależności google-cloud-spanner-cassandra
Aby zacząć korzystać z klienta Spanner Cassandra, musisz najpierw uwzględnić jego zależność w projekcie. Artefakty google-cloud-spanner-cassandra są publikowane w Maven Central pod identyfikatorem grupy com.google.cloud. Dodaj tę nową zależność w sekcji <dependencies> w projekcie Java. Oto uproszczony przykład, jak uwzględnić zależność google-cloud-spanner-cassandra:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Zmiana konfiguracji połączenia w celu połączenia się ze Spannerem
Po dodaniu niezbędnej zależności następnym krokiem jest zmiana konfiguracji połączenia, aby połączyć się z bazą danych Spanner.
Typowa aplikacja wchodząca w interakcję z klastrem Cassandra często używa kodu podobnego do tego, który służy do nawiązywania połączenia:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Aby przekierować to połączenie do Spannera, musisz zmodyfikować logikę tworzenia CqlSession. Zamiast bezpośrednio używać standardowej funkcji CqlSessionBuilder z cassandra-java-driver, będziesz korzystać z funkcji SpannerCqlSession.builder() udostępnianej przez klienta Spanner Cassandra. Oto przykład, który obrazuje, jak zmodyfikować kod połączenia:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
Po utworzeniu instancji CqlSession za pomocą SpannerCqlSession.builder() i podaniu prawidłowego databaseUri aplikacja nawiąże połączenie z docelową bazą danych Spanner za pomocą klienta Cassandra w Spannerze. Ta kluczowa zmiana sprawi, że wszystkie kolejne operacje odczytu i zapisu wykonywane przez aplikację będą kierowane do Spannera i obsługiwane przez niego, co skutecznie zakończy początkowe przełączenie. Na tym etapie aplikacja powinna nadal działać zgodnie z oczekiwaniami, ale teraz będzie korzystać ze skalowalności i niezawodności usługi Spanner.
Dla zaawansowanych: jak działa klient Cassandra usługi Spanner
Klient Spanner Cassandra działa jako lokalny serwer proxy TCP, przechwytując surowe bajty protokołu Cassandra wysyłane przez sterownik lub narzędzie klienta. Następnie opakowuje te bajty wraz z niezbędnymi metadanymi w wiadomości gRPC, aby komunikować się ze Spannerem. Odpowiedzi z usługi Spanner są ponownie tłumaczone na format transmisji Cassandra i wysyłane z powrotem do sterownika lub narzędzia, które wysłało żądanie.
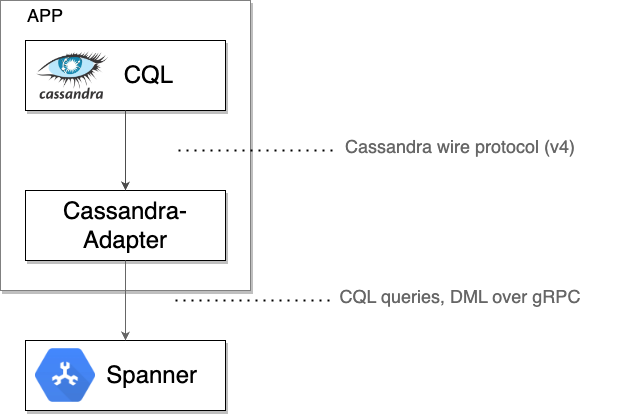
Gdy będziesz mieć pewność, że Spanner prawidłowo obsługuje cały ruch, możesz:
- Wycofaj pierwotny klaster Cassandra.
8. Czyszczenie (opcjonalnie)
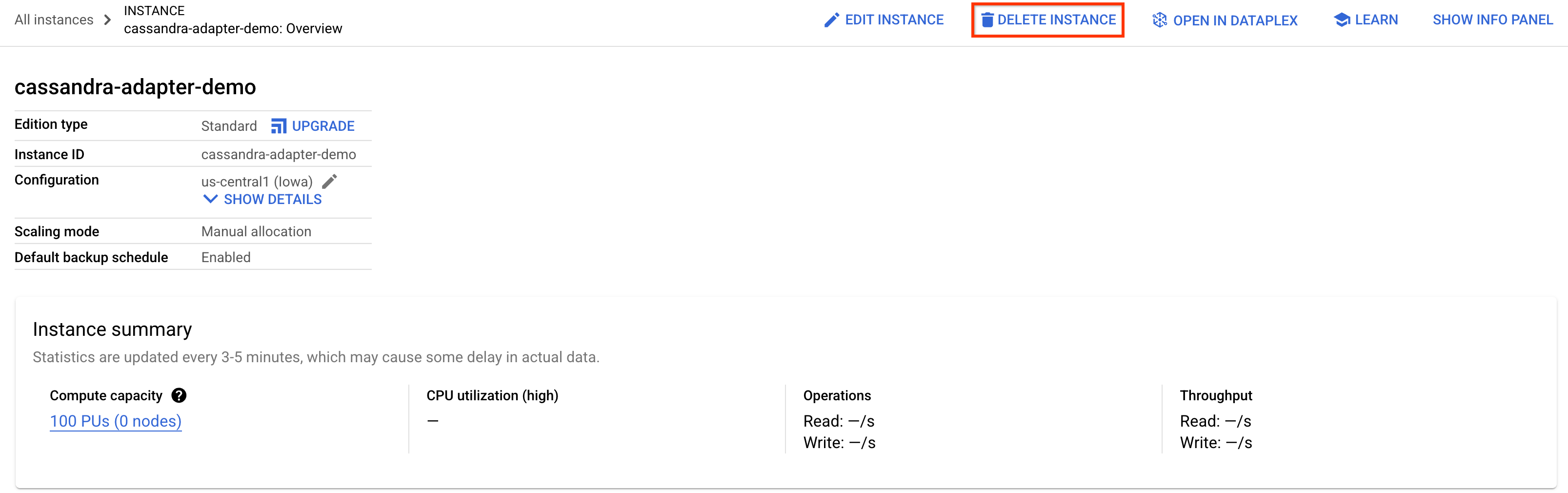
Aby zwolnić miejsce, otwórz sekcję Spanner w konsoli Cloud i usuń instancję cassandra-adapter-demo utworzoną w ramach tego laboratorium.
Usuń bazę danych Cassandra (jeśli jest zainstalowana lokalnie lub utrwalona).
Jeśli Cassandra została zainstalowana poza maszyną wirtualną Compute Engine utworzoną w tym miejscu, wykonaj odpowiednie czynności, aby usunąć dane lub odinstalować Cassandrę.
9. Gratulacje!
Co dalej?
- Dowiedz się więcej o Spannerze.
- Dowiedz się więcej o interfejsie Cassandra.