
1. はじめに
Spanner は、リレーショナル ワークロードと非リレーショナル ワークロードの両方に適した、水平スケーリングが可能なグローバルに分散されたフルマネージド データベース サービスです。
Spanner の Cassandra インターフェースを使用すると、使い慣れた Cassandra ツールと構文を使用して、Spanner のフルマネージドで、スケーラブルかつ高可用性のインフラストラクチャを活用できます。
学習内容
- Spanner のインスタンスとデータベースを設定する方法。
- Cassandra のスキーマとデータモデルを変換する方法。
- Cassandra から Spanner に過去のデータを一括でエクスポートする方法。
- Cassandra ではなく Spanner を参照するようにアプリケーションを設定する方法。
必要なもの
- 請求先アカウントに接続されている Google Cloud プロジェクト。
gcloudCLI がインストールされ、構成されているマシンにアクセスするか、Google Cloud Shell を使用します。- ウェブブラウザ(Chrome、Firefox など)
2. 設定と要件
GCP プロジェクトを作成する
Google Cloud コンソールにログインして、新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。



- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
お支払い情報の設定
次に、請求の管理に関するユーザーガイドに沿って、Cloud コンソールで課金を有効にする必要があります。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。このチュートリアルを終了した後に課金が発生しないようにするには、Codelab の最後にある「ステップ 9: クリーンアップ」の手順に沿って、Spanner インスタンスをシャットダウンします。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud コンソールで、右上のツールバーにある Cloud Shell アイコンをクリックします。

プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
次のステップ
次に、Cassandra クラスタをデプロイします。
3. Cassandra クラスタをデプロイする(Origin)
この Codelab では、Compute Engine にシングルノードの Cassandra クラスタを設定します。
1. Cassandra 用の GCE VM を作成する
インスタンスを作成するには、前にプロビジョニングした Cloud Shell の gcloud compute instances create コマンドを使用します。
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Cassandra をインストールする
以下の手順に沿って、Navigation menu ページから VM Instances に移動します。![[VM インスタンス] に移動](https://codelabs.developers.google.cn/static/codelabs/spanner-cassandra-adapter-getting-started/img/Kiyxmqs4MRyJMqo.png?hl=ja)
cassandra-origin VM を検索し、次のように SSH を使用して VM に接続します。
 。
。
次のコマンドを実行して、作成して SSH 接続した VM に Cassandra をインストールします。
Java をインストールする(Cassandra の依存関係)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Cassandra リポジトリを追加する
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Cassandra をインストールする
sudo apt-get update
sudo apt-get install -y cassandra
Cassandra サービスのリッスン アドレスを設定します。
ここでは、セキュリティを強化するために Cassandra VM の内部 IP アドレスを使用します。
ホストマシンの IP アドレスをメモします
Cloud Shell で次のコマンドを使用するか、Cloud コンソールの VM Instances ページから取得できます。
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
または
 。
。
構成ファイルのアドレスを更新する
任意のエディタを使用して Cassandra 構成ファイルを更新できます。
sudo vim /etc/cassandra/cassandra.yaml
rpc_address: を VM の IP アドレスに変更し、ファイルを保存して閉じます。
VM で Cassandra サービスを有効にする
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. キースペースとテーブルを作成する {create-keyspace-and-table}
「users」テーブルの例を使用して、「analytics」というキースペースを作成します。
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
cqlsh 内:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
SSH セッションを開いたままにするか、この VM の IP アドレス(hostname -I)をメモします。
次のステップ
次に、Cloud Spanner のインスタンスとデータベースを設定します。
4. Spanner インスタンス(ターゲット)を作成する
Spanner では、インスタンスは、1 つ以上の Spanner データベースをホストするコンピューティング リソースとストレージ リソースのクラスタです。この Codelab で Spanner データベースをホストするには、少なくとも 1 つのインスタンスが必要です。
gcloud SDK のバージョンを確認する
インスタンスを作成する前に、Google Cloud Shell の gcloud SDK が必要なバージョン(gcloud SDK 531.0.0 より大きいバージョン)に更新されていることを確認してください。gcloud SDK のバージョンは、次のコマンドで確認できます。
$ gcloud version | grep Google
出力例を次に示します。
Google Cloud SDK 489.0.0
使用しているバージョンが、必要な 531.0.0 バージョン(前の例の 489.0.0)より前の場合は、次のコマンドを実行して Google Cloud SDK をアップグレードする必要があります。
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Spanner API を有効にする
Cloud Shell で、プロジェクト ID が設定されていることを確認します。現在構成されているプロジェクト ID を確認するには、次の最初のコマンドを使用します。結果が想定どおりでない場合は、次の 2 番目のコマンドで正しいものを設定します。
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
デフォルト リージョンを us-central1 に構成します。これは、Spanner のリージョン構成でサポートされている別のリージョンに変更できます。
gcloud config set compute/region us-central1
Spanner API を有効にします。
gcloud services enable spanner.googleapis.com
Spanner インスタンスを作成する
このセクションでは、無料トライアル インスタンスまたはプロビジョニングされたインスタンスを作成します。この Codelab では、Spanner Cassandra アダプタ インスタンス ID として cassandra-adapter-demo を使用します。これは、export コマンドラインを使用して SPANNER_INSTANCE_ID 変数として設定されます。必要に応じて、独自のインスタンス ID 名を選択できます。
無料トライアルの Spanner インスタンスを作成する
Spanner の 90 日間の無料トライアル インスタンスは、プロジェクトで Cloud Billing が有効になっている Google アカウントをお持ちのすべての方にご利用いただけます。無料トライアル インスタンスを有料インスタンスにアップグレードしない限り、課金されることはありません。Spanner Cassandra アダプタは、無料トライアル インスタンスでサポートされています。対象となる場合は、Cloud Shell を開いて次のコマンドを実行し、無料トライアル インスタンスを作成します。
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
コマンド出力:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Cassandra スキーマとデータモデルを Spanner に移行する
Cassandra データベースから Spanner にデータを移行する最初の重要なフェーズでは、既存の Cassandra スキーマを変換して、Spanner の構造とデータ型の要件に合わせます。
この複雑なスキーマ移行プロセスを効率化するには、Spanner が提供する 2 つの有用なオープンソース ツールのいずれかを使用します。
- Spanner 移行ツール: このツールは、既存の Cassandra データベースに接続してスキーマを Spanner に移行することで、スキーマの移行を支援します。このツールは
gcloud cliの一部として利用できます。 - Spanner Cassandra スキーマ変換ツール: このツールは、Cassandra からエクスポートされた DDL を Spanner に変換するのに役立ちます。この Codelab では、これらの 2 つのツールのいずれかを使用できます。この Codelab では、Spanner 移行ツールを使用してスキーマを移行します。
Spanner 移行ツール
Spanner 移行ツールは、MySQL、Postgres、Cassandra などのさまざまなデータソースからスキーマを移行するのに役立ちます。
この Codelab では、このツールの CLI を使用しますが、ツールの UI ベースのバージョンを試して使用することを強くおすすめします。このバージョンでは、Spanner スキーマが適用される前に変更を加えることもできます。
spanner-migration-tool が Cloud Shell で実行されている場合、Cassandra VM の内部 IP アドレスにアクセスできない可能性があります。そのため、Cassandra をインストールした VM で同じコマンドを実行することをおすすめします。
Cassandra をインストールした VM で次のコマンドを実行します。
Spanner 移行ツールをインストールする
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
インストールで問題が発生した場合は、installing-spanner-migration-tool で詳細な手順をご覧ください。
Gcloud 認証情報を更新する
gcloud auth login
gcloud auth application-default login
スキーマを移行
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Spanner DDL を検証する
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
スキーマ移行の最後に、このコマンドの出力は次のようになります。
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(省略可)変換された DDL を確認する
変換された DDL を確認し、Spanner に再適用できます(追加の変更が必要な場合)。
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
このコマンドの出力は次のようになります。
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(省略可)コンバージョン レポートを確認する
cat `ls -t cassandra_*report.txt | head -n 1`
変換レポートには、注意すべき問題がハイライト表示されます。たとえば、ソースと Spanner の間で列の最大精度が一致しない場合、ここでハイライト表示されます。
6. 履歴データを一括でエクスポートする
一括移行を行うには、次の操作を行う必要があります。
- 既存の GCS バケットをプロビジョニングまたは再利用します。
- Cassandra ドライバ構成ファイルをバケットにアップロードする
- 一括移行を開始します。
一括移行は Cloud Shell または新しくプロビジョニングされた VM から起動できますが、この Codelab では VM を使用することをおすすめします。構成ファイルの作成などの一部の手順では、ローカル ストレージにファイルが保持されるためです。
GCS バケットをプロビジョニングします。
このステップの最後に、GCS バケットをプロビジョニングし、そのパスを CASSANDRA_BUCKET_NAME という名前の変数にエクスポートします。既存のバケットを再利用する場合は、パスをエクスポートして続行できます。
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
ドライバ構成ファイルを作成してアップロードする
ここでは、非常に基本的な Cassandra ドライバ構成ファイルをアップロードします。ファイルの完全な形式については、こちらをご覧ください。
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
一括移行を実行する
これは、データを Spanner に一括移行するためのサンプル コマンドです。実際の本番環境のユースケースでは、目的のスケールとスループットに応じてマシンタイプと数を調整する必要があります。オプションの一覧については、README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration をご覧ください。
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
次のような出力が生成されます。生成された id をメモし、同じものを使用して Dataflow ジョブのステータスをクエリします。
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
次のコマンドを実行してジョブのステータスを確認し、ステータスが JOB_STATE_DONE に変わるまで待ちます。
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
最初は、ジョブは次のようにキューに登録された状態になります。
currentState: JOB_STATE_QUEUED
ジョブがキューに登録されている間や実行中は、Cloud Console UI の Dataflow/Jobs ページでジョブをモニタリングすることを強くおすすめします。
完了すると、ジョブの状態は次のように変わります。
currentState: JOB_STATE_DONE
7. アプリケーションが Spanner を参照するように設定する(カットオーバー)
移行フェーズ後にデータの精度と完全性を綿密に検証したら、アプリケーションの運用上の焦点を以前の Cassandra システムから新しく作成された Spanner データベースに移行することが重要なステップとなります。この重要な移行期間は、一般に「カットオーバー」と呼ばれます。
カットオーバー フェーズは、ライブ アプリケーション トラフィックが元の Cassandra クラスタからリダイレクトされ、堅牢でスケーラブルな Spanner インフラストラクチャに直接接続される瞬間を示します。この移行は、特に Spanner Cassandra インターフェースを使用する場合に、アプリケーションが Spanner の機能を簡単に活用できることを示しています。
Spanner Cassandra インターフェースを使用すると、切り替えプロセスが効率化されます。主に、すべてのデータ操作にネイティブの Spanner Cassandra クライアントを使用するようにクライアント アプリケーションを構成します。アプリケーションは、Cassandra(移行元)データベースと通信する代わりに、Spanner(移行先)に直接データを読み書きするようシームレスに切り替わります。この接続の根本的な変更は通常、SpannerCqlSessionBuilder を使用して実現されます。これは、Spanner インスタンスへの接続の確立を容易にする Spanner Cassandra クライアント ライブラリの重要なコンポーネントです。これにより、アプリケーションのデータ トラフィック フロー全体が Spanner に効果的に再ルーティングされます。
すでに cassandra-java-driver ライブラリを使用している Java アプリケーションの場合、Spanner Cassandra Java クライアントの統合には、CqlSession の初期化に対するわずかな変更のみが必要です。
google-cloud-spanner-cassandra 依存関係を取得する
Spanner Cassandra クライアントの使用を開始するには、まずその依存関係をプロジェクトに組み込む必要があります。google-cloud-spanner-cassandra アーティファクトは、グループ ID com.google.cloud の Maven Central に公開されています。Java プロジェクトの既存の <dependencies> セクションに次の新しい依存関係を追加します。google-cloud-spanner-cassandra 依存関係を含める方法の簡単な例を次に示します。
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Spanner に接続するように接続構成を変更する
必要な依存関係を追加したら、次のステップとして、Cloud Spanner データベースに接続するように接続構成を変更します。
Cassandra クラスタとやり取りする一般的なアプリケーションでは、次のコードのようなコードを使用して接続を確立することがよくあります。
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
この接続を Spanner にリダイレクトするには、CqlSession 作成ロジックを変更する必要があります。cassandra-java-driver から標準の CqlSessionBuilder を直接使用する代わりに、Spanner Cassandra Client が提供する SpannerCqlSession.builder() を使用します。接続コードを変更する方法の例を次に示します。
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
SpannerCqlSession.builder() を使用して CqlSession をインスタンス化し、正しい databaseUri を指定すると、アプリケーションは Spanner Cassandra クライアントを介して移行先の Spanner データベースに接続を確立します。この重要な変更により、アプリケーションによって実行される後続のすべての読み取りオペレーションと書き込みオペレーションが Spanner に転送され、Spanner によって処理されるようになり、初期カットオーバーが効果的に完了します。この時点で、アプリケーションは引き続き想定どおりに機能し、Spanner の拡張性と信頼性を活用します。
仕組み: Spanner Cassandra クライアントの動作
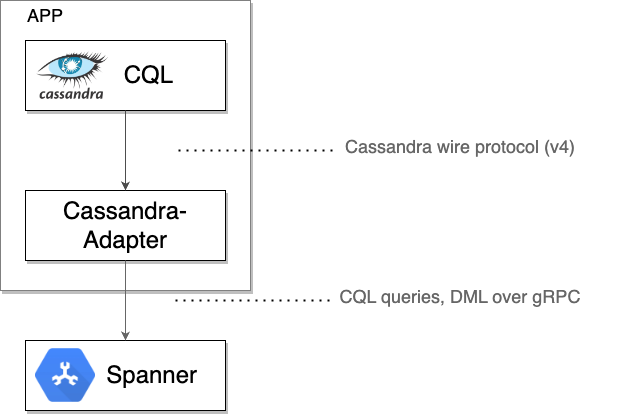
Spanner Cassandra クライアントはローカル TCP プロキシとして機能し、ドライバまたはクライアント ツールから送信された未加工の Cassandra プロトコル バイトをインターセプトします。次に、これらのバイトと必要なメタデータを gRPC メッセージにラップして、Spanner との通信を行います。Spanner からのレスポンスは Cassandra ワイヤー形式に変換され、元のドライバまたはツールに返送されます。
Spanner がすべてのトラフィックを正しく処理していることを確認したら、最終的に次の操作を行うことができます。
- 元の Cassandra クラスタを廃止します。
8. クリーンアップ(省略可)
クリーンアップするには、Cloud Console の Spanner セクションに移動して、Codelab で作成した cassandra-adapter-demo インスタンスを削除します。

Cassandra データベースを削除する(ローカルにインストールされている場合、または永続化されている場合)
ここで作成した Compute Engine VM の外部に Cassandra をインストールした場合は、適切な手順に沿ってデータを削除するか、Cassandra をアンインストールします。
9. 完了
次のステップ
- Spanner の詳細を確認する。
- Cassandra インターフェースの詳細を確認する。