
1. Introduzione
Spanner è un servizio di database completamente gestito, scalabile orizzontalmente e distribuito a livello globale, ideale per carichi di lavoro relazionali e non relazionali.
L'interfaccia Cassandra di Spanner ti consente di sfruttare l'infrastruttura completamente gestita, scalabile e ad alta affidabilità di Spanner utilizzando la sintassi e gli strumenti Cassandra che conosci.
Obiettivi didattici
- Come configurare un'istanza e un database Spanner.
- Come convertire lo schema e il modello dati di Cassandra.
- Come esportare in blocco i dati storici da Cassandra a Spanner.
- Come indirizzare l'applicazione a Spanner anziché a Cassandra.
Che cosa ti serve
- Un progetto cloud Google Cloud collegato a un account di fatturazione.
- Accesso a una macchina con la CLI
gcloudinstallata e configurata oppure utilizza Google Cloud Shell. - Un browser web, ad esempio Chrome o Firefox.
2. Configurazione e requisiti
Crea un progetto Google Cloud
Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

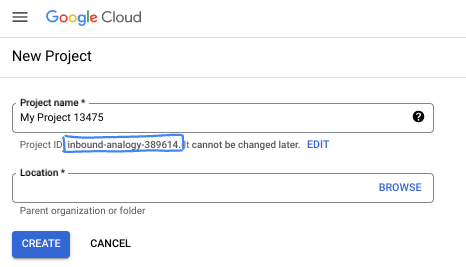
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
Configurazione di fatturazione
Successivamente, dovrai seguire la guida utente per la gestione della fatturazione e attivare la fatturazione in Cloud Console. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$. Per evitare addebiti oltre a questo tutorial, puoi arrestare l'istanza Spanner alla fine del codelab seguendo la sezione "Passaggio 9: pulizia".
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
Prossimo
Ora esegui il deployment del cluster Cassandra.
3. Esegui il deployment del cluster Cassandra (origine)
Per questo codelab, configureremo un cluster Cassandra a un solo nodo su Compute Engine.
1. Crea una VM GCE per Cassandra
Per creare un'istanza, utilizza il comando gcloud compute instances create dalla shell Cloud di cui è stato eseguito il provisioning in precedenza.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Installare Cassandra
Vai a VM Instances dalla pagina Navigation menu seguendo le istruzioni riportate di seguito:  .
.
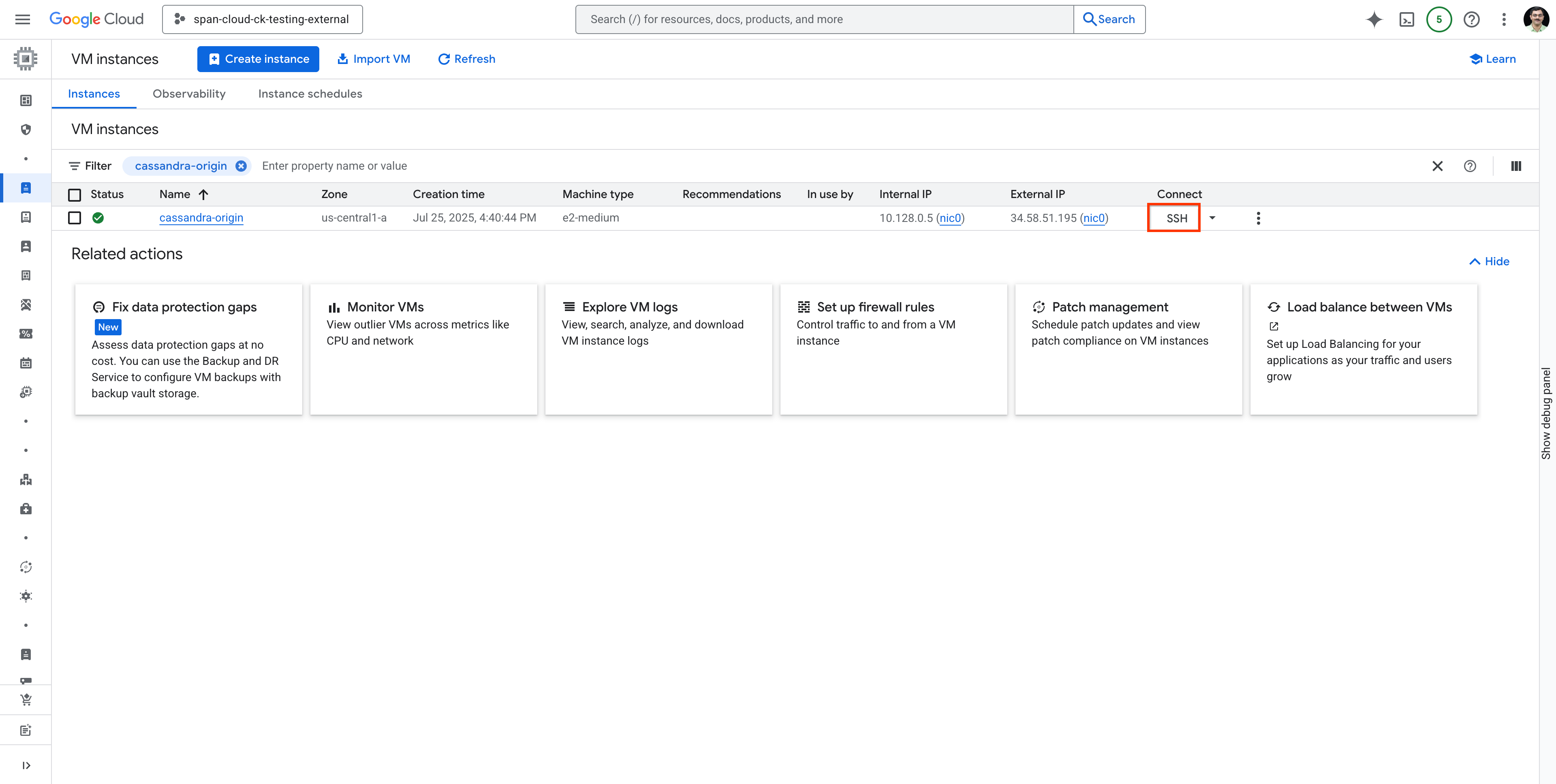
Cerca la VM cassandra-origin e connettiti alla VM utilizzando SSH come mostrato:
 .
.
Esegui questi comandi per installare Cassandra sulla VM che hai creato e a cui hai eseguito l'accesso tramite SSH.
Installa Java (dipendenza di Cassandra)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Aggiungere il repository Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Installare Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
Imposta l'indirizzo di ascolto per il servizio Cassandra.
Qui utilizziamo l'indirizzo IP interno della VM Cassandra per una maggiore sicurezza.
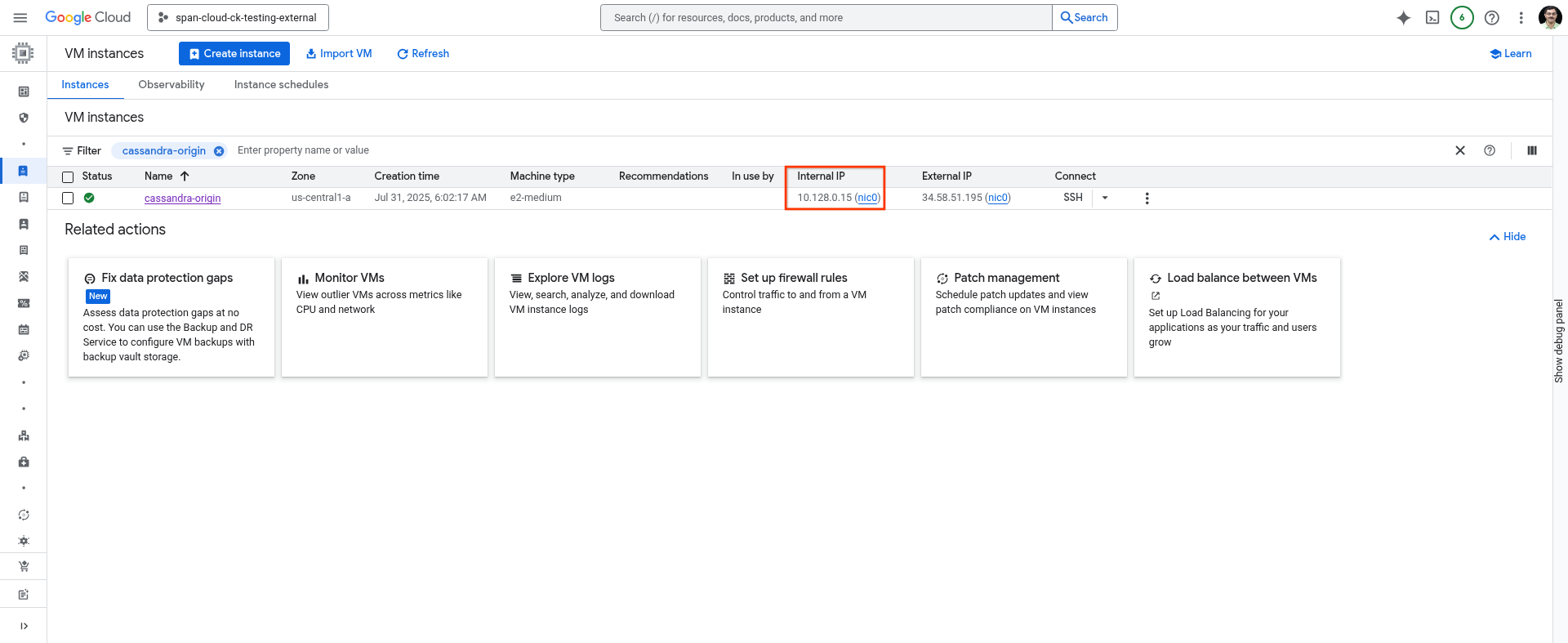
Prendi nota dell'indirizzo IP della macchina host.
Puoi utilizzare il seguente comando in Cloud Shell o recuperarlo dalla pagina VM Instances della console Cloud.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
OPPURE
 .
.
Aggiorna l'indirizzo nel file di configurazione
Puoi utilizzare l'editor che preferisci per aggiornare il file di configurazione di Cassandra.
sudo vim /etc/cassandra/cassandra.yaml
modifica rpc_address: con l'indirizzo IP della VM, salva e chiudi il file.
Attiva il servizio Cassandra sulla VM
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Crea uno spazio delle chiavi e una tabella {create-keyspace-and-table}
Utilizzeremo un esempio di tabella "users" e creeremo uno spazio delle chiavi chiamato "analytics".
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
All'interno di cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Lascia aperta la sessione SSH o annota l'indirizzo IP di questa VM (hostname -I).
Prossimo
Il passaggio successivo consiste nel configurare un database e un'istanza Cloud Spanner.
4. Crea un'istanza di Spanner (destinazione)
In Spanner, un'istanza è un cluster di risorse di computing e archiviazione che ospita uno o più database Spanner. Per questo codelab, avrai bisogno di almeno un'istanza per ospitare un database Spanner.
Controllare la versione dell'SDK gcloud
Prima di creare un'istanza, assicurati che gcloud SDK in Google Cloud Shell sia stato aggiornato alla versione richiesta, ovvero una versione successiva a gcloud SDK 531.0.0. Per trovare la versione di gcloud SDK, esegui il comando riportato di seguito.
$ gcloud version | grep Google
Ecco un output di esempio:
Google Cloud SDK 489.0.0
Se la versione che stai utilizzando è precedente alla versione 531.0.0 richiesta (489.0.0 nell'esempio precedente), devi eseguire l'upgrade di Google Cloud SDK eseguendo il seguente comando:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Abilita l'API Spanner
In Cloud Shell, assicurati che l'ID progetto sia configurato. Utilizza il primo comando riportato di seguito per trovare l'ID progetto attualmente configurato. Se il risultato non è quello previsto, il secondo comando riportato di seguito imposta quello corretto.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Configura la regione predefinita su us-central1. Puoi modificarla con un'altra regione supportata dalle configurazioni regionali di Spanner.
gcloud config set compute/region us-central1
Abilita l'API Spanner:
gcloud services enable spanner.googleapis.com
Crea l'istanza Spanner
In questa sezione creerai un'istanza di prova senza costi o un'istanza di cui è stato eseguito il provisioning. In questo codelab, l'ID istanza dell'adattatore Spanner Cassandra utilizzato è cassandra-adapter-demo, impostato come variabile SPANNER_INSTANCE_ID utilizzando la riga di comando export. Se vuoi, puoi scegliere un nome per l'ID istanza.
Crea un'istanza Spanner di prova senza costi
Un'istanza di prova senza costi di Spanner di 90 giorni è disponibile per chiunque abbia un Account Google con la fatturazione Cloud abilitata nel proprio progetto. Non ti verrà addebitato alcun costo a meno che tu non scelga di eseguire l'upgrade dell'istanza di prova senza costi a un'istanza a pagamento. Spanner Cassandra Adapter è supportato nell'istanza di prova senza costi. Se hai l'idoneità, crea un'istanza di prova senza costi aprendo Cloud Shell ed eseguendo questo comando:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Output comando:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Migrare lo schema e il modello dei dati di Cassandra in Spanner
La fase iniziale e cruciale della transizione dei dati da un database Cassandra a Spanner prevede la trasformazione dello schema Cassandra esistente per allinearlo ai requisiti strutturali e di tipo di dati di Spanner.
Per semplificare questo complesso processo di migrazione dello schema, utilizza uno dei due preziosi strumenti open source forniti da Spanner:
- Strumento di migrazione Spanner: questo strumento ti aiuta a eseguire la migrazione dello schema connettendosi a un database Cassandra esistente e migrando lo schema a Spanner. Questo strumento è disponibile nell'ambito di
gcloud cli. - Strumento per lo schema Spanner Cassandra: questo strumento ti aiuta a convertire un DDL esportato da Cassandra a Spanner. Puoi utilizzare uno qualsiasi di questi due strumenti per il codelab. In questo codelab, utilizzeremo lo strumento di migrazione di Spanner per eseguire la migrazione dello schema.
Strumento di migrazione di Spanner
Lo strumento di migrazione Spanner consente di eseguire la migrazione dello schema da varie origini dati come MySQL, Postgres, Cassandra e così via.
Sebbene ai fini di questo codelab utilizzeremo la CLI di questo strumento, ti consigliamo vivamente di esplorare e utilizzare la versione basata sulla UI dello strumento, che ti aiuta anche ad apportare modifiche allo schema Spanner prima che venga applicato.
Tieni presente che se spanner-migration-tool viene eseguito su Cloud Shell, potrebbe non avere accesso all'indirizzo IP interno della tua VM Cassandra. Pertanto, ti consigliamo di eseguire lo stesso comando sulla VM in cui hai installato Cassandra.
Esegui il seguente comando sulla VM in cui hai installato Cassandra.
Installa lo strumento di migrazione Spanner
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Se riscontri problemi con l'installazione, consulta installing-spanner-migration-tool per i passaggi dettagliati.
Aggiorna le credenziali gcloud
gcloud auth login
gcloud auth application-default login
Migrazione dello schema
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Verifica il DDL di Spanner
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
Al termine della migrazione dello schema, l'output di questo comando dovrebbe essere:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Facoltativo) Visualizza il DDL convertito
Puoi visualizzare il DDL convertito e riapplicarlo in Spanner (se hai bisogno di ulteriori modifiche).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
L'output di questo comando sarà
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(Facoltativo) Visualizza il report sulle conversioni
cat `ls -t cassandra_*report.txt | head -n 1`
Il report sulle conversioni evidenzia i problemi da tenere presente. Ad esempio, se c'è una mancata corrispondenza nella precisione massima di una colonna tra l'origine e Spanner, verrà evidenziata qui.
6. Esportare collettivamente i dati storici
Per eseguire la migrazione collettiva, devi:
- Esegui il provisioning o riutilizza un bucket GCS esistente.
- Carica il file di configurazione del driver Cassandra nel bucket
- Avvia la migrazione collettiva.
Anche se puoi avviare la migrazione collettiva da Cloud Shell o dalla VM appena sottoposta a provisioning, ti consigliamo di utilizzare la VM per questo codelab, poiché alcuni passaggi, come la creazione di un file di configurazione, manterranno i file nell'archiviazione locale.
Esegui il provisioning di un bucket GCS.
Al termine di questo passaggio, dovresti aver eseguito il provisioning di un bucket GCS ed esportato il relativo percorso in una variabile denominata CASSANDRA_BUCKET_NAME. Se vuoi riutilizzare un bucket esistente, puoi procedere esportando il percorso.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Creare e caricare il file di configurazione del driver
Qui carichiamo un file di configurazione del driver Cassandra molto semplice. Per il formato completo del file, consulta questo articolo.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Eseguire la migrazione collettiva
Questo è un comando di esempio per eseguire la migrazione collettiva dei dati a Spanner. Per i casi d'uso di produzione effettivi, dovrai modificare il tipo di macchina e il conteggio in base alla scalabilità e al throughput desiderati. Visita README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration per l'elenco completo delle opzioni.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
Verrà generato un output simile al seguente. Prendi nota del id generato e utilizzalo per eseguire query sullo stato del job Dataflow.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Esegui il comando riportato di seguito per controllare lo stato del job e attendi che lo stato diventi JOB_STATE_DONE.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Inizialmente, il job sarà in stato di coda, ad esempio
currentState: JOB_STATE_QUEUED
Mentre il job è in coda/in esecuzione, ti consigliamo vivamente di esplorare la pagina Dataflow/Jobs nella UI della console Google Cloud per monitorarlo.
Al termine, lo stato del job cambierà in:
currentState: JOB_STATE_DONE
7. Punta l'applicazione a Spanner (cutover)
Dopo aver convalidato meticolosamente l'accuratezza e l'integrità dei dati dopo la fase di migrazione, il passaggio fondamentale è trasferire l'attenzione operativa della tua applicazione dal sistema Cassandra legacy al database Spanner appena compilato. Questo periodo di transizione critico è comunemente chiamato "cutover".
La fase di cutover segna il momento in cui il traffico dell'applicazione live viene reindirizzato dal cluster Cassandra originale e connesso direttamente all'infrastruttura Spanner robusta e scalabile. Questa transizione dimostra la facilità con cui le applicazioni possono sfruttare la potenza di Spanner, soprattutto quando utilizzano l'interfaccia Spanner Cassandra.
Con l'interfaccia Spanner Cassandra, il processo di cutover è semplificato. Consiste principalmente nel configurare le applicazioni client in modo che utilizzino il client Spanner Cassandra nativo per tutte le interazioni con i dati. Anziché comunicare con il database Cassandra (origine), le tue applicazioni inizieranno a leggere e scrivere dati direttamente in Spanner (destinazione). Questo cambiamento fondamentale nella connettività viene in genere ottenuto tramite l'utilizzo di SpannerCqlSessionBuilder, un componente chiave della libreria client Spanner Cassandra che facilita la creazione di connessioni all'istanza Spanner. In questo modo, l'intero flusso di traffico dati della tua applicazione viene reindirizzato a Spanner.
Per le applicazioni Java che utilizzano già la libreria cassandra-java-driver, l'integrazione del client Java di Spanner Cassandra richiede solo piccole modifiche all'inizializzazione di CqlSession.
Ottenere la dipendenza google-cloud-spanner-cassandra
Per iniziare a utilizzare il client Spanner Cassandra, devi prima incorporare la sua dipendenza nel progetto. Gli artefatti google-cloud-spanner-cassandra vengono pubblicati in Maven Central, con l'ID gruppo com.google.cloud. Aggiungi la nuova dipendenza riportata di seguito nella sezione <dependencies> esistente del tuo progetto Java. Ecco un esempio semplificato di come includere la dipendenza google-cloud-spanner-cassandra:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Modifica la configurazione della connessione per connetterti a Spanner
Dopo aver aggiunto la dipendenza necessaria, il passaggio successivo consiste nel modificare la configurazione della connessione per connettersi al database Spanner.
Una tipica applicazione che interagisce con un cluster Cassandra spesso utilizza un codice simile al seguente per stabilire una connessione:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Per reindirizzare questa connessione a Spanner, devi modificare la logica di creazione di CqlSession. Anziché utilizzare direttamente l'elemento CqlSessionBuilder standard di cassandra-java-driver, utilizzerai SpannerCqlSession.builder() fornito dal client Spanner Cassandra. Ecco un esempio illustrativo di come modificare il codice di collegamento:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
Se crei un'istanza di CqlSession utilizzando SpannerCqlSession.builder() e fornisci il databaseUri corretto, la tua applicazione stabilirà una connessione tramite il client Spanner Cassandra al database Spanner di destinazione. Questa modifica fondamentale garantisce che tutte le successive operazioni di lettura e scrittura eseguite dalla tua applicazione vengano indirizzate e gestite da Spanner, completando di fatto il cutover iniziale. A questo punto, l'applicazione dovrebbe continuare a funzionare come previsto, ora con la scalabilità e l'affidabilità di Spanner.
Dietro le quinte: come funziona il client Spanner Cassandra
Il client Spanner Cassandra funge da proxy TCP locale, intercettando i byte del protocollo Cassandra non elaborati inviati da un driver o da uno strumento client. Quindi, esegue il wrapping di questi byte insieme ai metadati necessari nei messaggi gRPC per la comunicazione con Spanner. Le risposte di Spanner vengono ritradotte nel formato di trasmissione Cassandra e inviate al driver o allo strumento di origine.
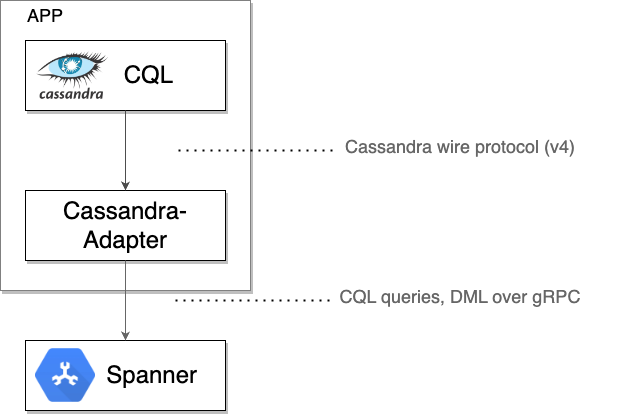
Una volta verificato che Spanner gestisce correttamente tutto il traffico, puoi:
- Dismetti il cluster Cassandra originale.
8. Pulizia (facoltativo)
Per liberare spazio, vai alla sezione Spanner della console Google Cloud ed elimina l'istanza cassandra-adapter-demo che abbiamo creato nel codelab.
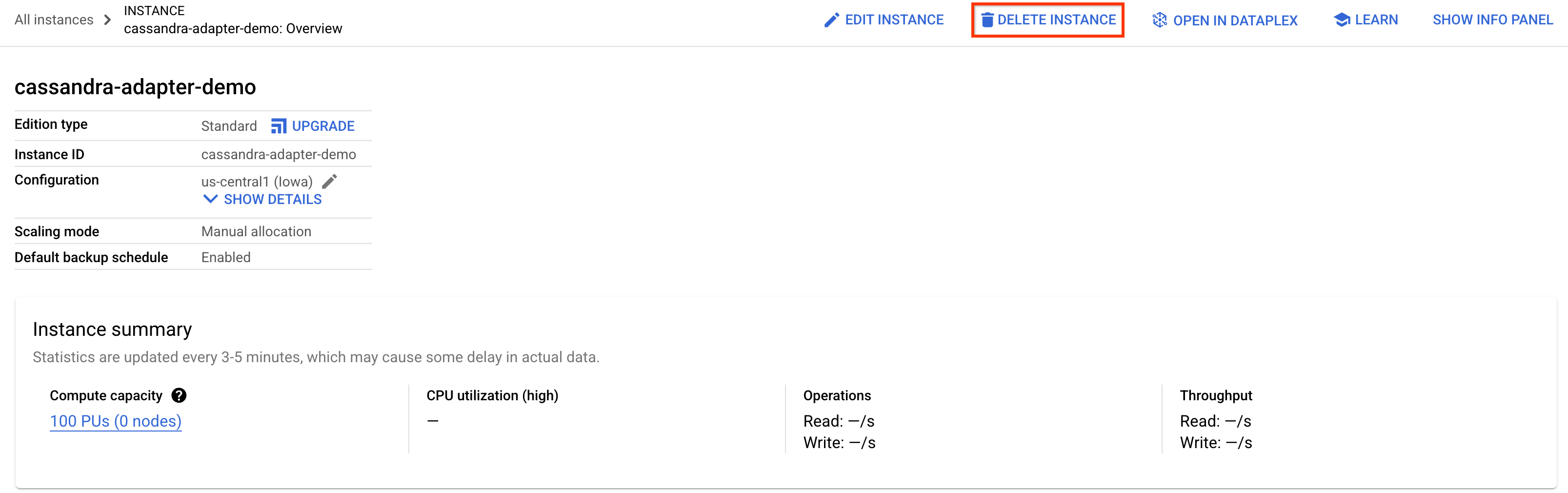
Elimina il database Cassandra (se installato localmente o reso persistente)
Se hai installato Cassandra al di fuori di una VM Compute Engine creata qui, segui i passaggi appropriati per rimuovere i dati o disinstallare Cassandra.
9. Complimenti!
Passaggi successivi
- Scopri di più su Spanner.
- Scopri di più sull'interfaccia Cassandra.