
1. Introduction
Spanner est un service de base de données entièrement géré, distribué à l'échelle mondiale et à évolutivité horizontale, qui convient parfaitement aux charges de travail relationnelles et non relationnelles.
L'interface Cassandra de Spanner vous permet de profiter de l'infrastructure entièrement gérée, évolutive et à haute disponibilité de Spanner à l'aide des outils et de la syntaxe Cassandra que vous connaissez.
Points abordés
- Comment configurer une instance et une base de données Spanner.
- Découvrez comment convertir votre schéma et votre modèle de données Cassandra.
- Découvrez comment exporter en masse vos données historiques de Cassandra vers Spanner.
- Comment rediriger votre application vers Spanner au lieu de Cassandra.
Prérequis
- Projet Google Cloud associé à un compte de facturation.
- Accès à une machine sur laquelle la CLI
gcloudest installée et configurée, ou utilisation de Google Cloud Shell. - Un navigateur Web (Chrome ou Firefox, par exemple).
2. Préparation
Créer un projet GCP
Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

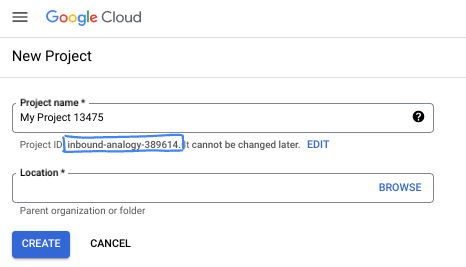
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
Configuration de facturation
Ensuite, vous devrez suivre le guide de l'utilisateur pour gérer la facturation et activer la facturation dans la console Cloud. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300$. Pour éviter que des frais ne vous soient facturés après ce tutoriel, vous pouvez arrêter l'instance Spanner à la fin de l'atelier en suivant l'étape 9 "Effectuer un nettoyage".
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils en haut à droite :

Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
Étape suivante
Vous allez ensuite déployer le cluster Cassandra.
3. Déployer un cluster Cassandra (Origin)
Pour cet atelier de programmation, nous allons configurer un cluster Cassandra à nœud unique sur Compute Engine.
1. Créer une VM GCE pour Cassandra
Pour créer une instance, utilisez la commande gcloud compute instances create à partir de Cloud Shell provisionné précédemment.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Installer Cassandra
Accédez à VM Instances depuis la page Navigation menu en suivant les instructions ci-dessous :  .
.
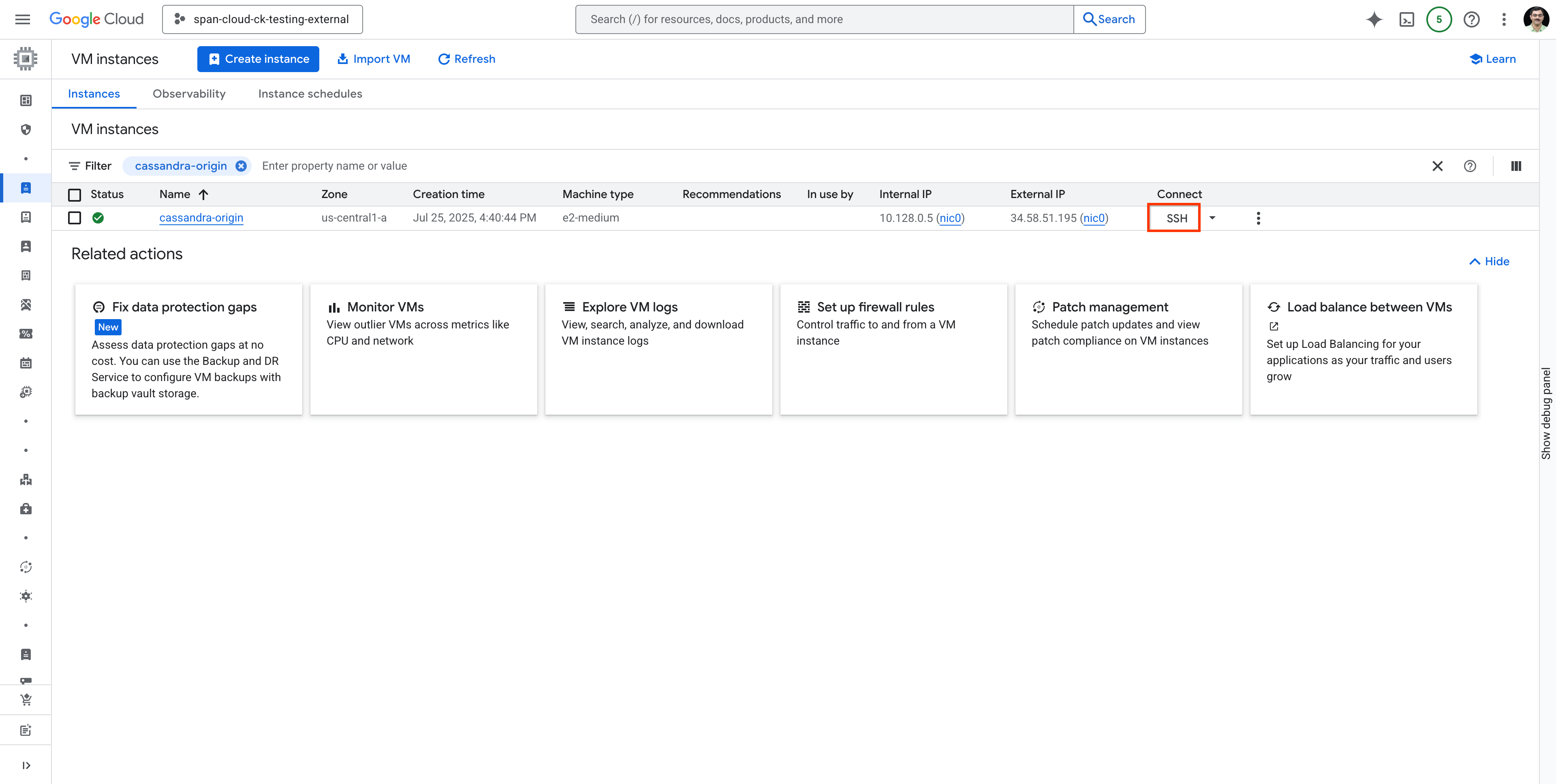
Recherchez la VM cassandra-origin et connectez-vous à celle-ci à l'aide de SSH, comme indiqué :
 .
.
Exécutez les commandes suivantes pour installer Cassandra sur la VM que vous avez créée et à laquelle vous vous êtes connecté via SSH.
Installer Java (dépendance Cassandra)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Ajouter le dépôt Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Installer Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
Définissez l'adresse d'écoute pour le service Cassandra.
Ici, nous utilisons l'adresse IP interne de la VM Cassandra pour plus de sécurité.
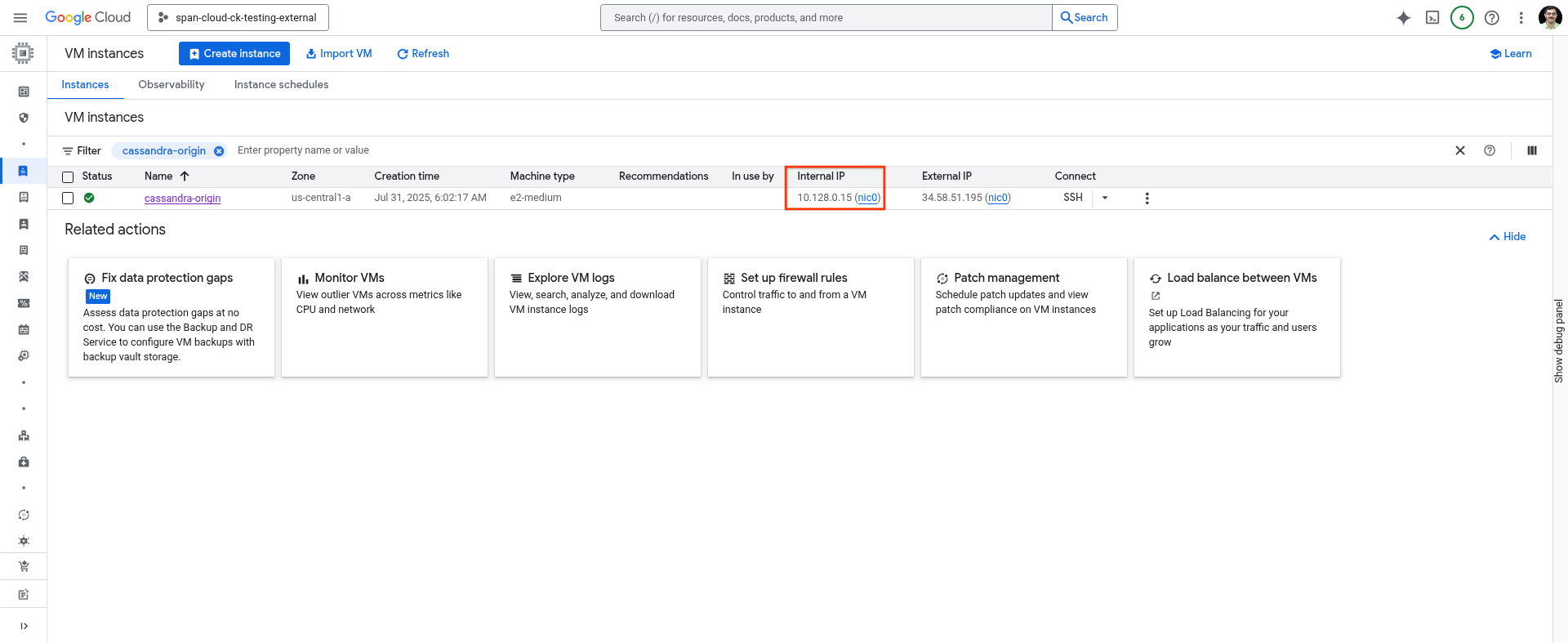
Notez l'adresse IP de votre machine hôte.
Vous pouvez utiliser la commande suivante dans Cloud Shell ou l'obtenir sur la page VM Instances de la console Cloud.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
OU
 .
.
Mettre à jour l'adresse dans le fichier de configuration
Vous pouvez utiliser l'éditeur de votre choix pour mettre à jour le fichier de configuration Cassandra.
sudo vim /etc/cassandra/cassandra.yaml
Remplacez rpc_address: par l'adresse IP de la VM, puis enregistrez et fermez le fichier.
Activer le service Cassandra sur la VM
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Créer un espace de clés et une table {create-keyspace-and-table}
Nous allons utiliser un exemple de table "users" et créer un espace de clés appelé "analytics".
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
Dans cqlsh :
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Laissez la session SSH ouverte ou notez l'adresse IP de cette VM (hostname -I).
Étape suivante
Vous allez ensuite configurer une instance et une base de données Cloud Spanner.
4. Créer une instance Spanner (cible)
Dans Spanner, une instance est un cluster de ressources de calcul et de stockage qui héberge une ou plusieurs bases de données Spanner. Pour cet atelier de programmation, vous aurez besoin d'au moins une instance pour héberger une base de données Spanner.
Vérifier la version du SDK gcloud
Avant de créer une instance, assurez-vous que le SDK gcloud dans Google Cloud Shell a été mis à jour vers la version requise (toute version supérieure à SDK gcloud 531.0.0). Vous pouvez trouver la version de votre SDK gcloud en exécutant la commande ci-dessous.
$ gcloud version | grep Google
Voici un exemple de résultat :
Google Cloud SDK 489.0.0
Si la version que vous utilisez est antérieure à la version 531.0.0 requise (489.0.0 dans l'exemple précédent), vous devez mettre à niveau votre SDK Google Cloud en exécutant la commande suivante :
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Activer l'API Spanner
Dans Cloud Shell, assurez-vous que l'ID de votre projet est configuré. Utilisez la première commande ci-dessous pour trouver l'ID de projet actuellement configuré. Si le résultat n'est pas celui attendu, la deuxième commande ci-dessous définit le bon.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Configurez votre région par défaut sur us-central1. N'hésitez pas à la remplacer par une autre région compatible avec les configurations régionales de Spanner.
gcloud config set compute/region us-central1
Activez l'API Spanner :
gcloud services enable spanner.googleapis.com
Créer l'instance Spanner
Dans cette section, vous allez créer une instance d'essai sans frais ou une instance provisionnée. Tout au long de cet atelier de programmation, l'ID d'instance de l'adaptateur Spanner Cassandra utilisé est cassandra-adapter-demo, défini comme variable SPANNER_INSTANCE_ID à l'aide de la ligne de commande export. Vous pouvez également choisir le nom de votre propre ID d'instance.
Créer une instance Spanner en essai sans frais
L'instance d'essai sans frais de 90 jours de Spanner est disponible pour toute personne disposant d'un compte Google et ayant activé Cloud Billing sur son projet. Des frais ne vous seront facturés que si vous choisissez de mettre à niveau votre instance d'essai sans frais vers une instance payante. L'adaptateur Spanner Cassandra est compatible avec l'instance d'essai sans frais. Si vous êtes éligible, créez une instance d'essai sans frais en ouvrant Cloud Shell et en exécutant cette commande :
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Résultat de la commande :
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Migrer le schéma et le modèle de données Cassandra vers Spanner
La phase initiale et cruciale de la migration des données d'une base de données Cassandra vers Spanner consiste à transformer le schéma Cassandra existant pour l'adapter aux exigences de Spanner en termes de structure et de types de données.
Pour simplifier ce processus complexe de migration de schéma, utilisez l'un des deux outils Open Source utiles fournis par Spanner :
- Outil de migration Spanner : cet outil vous aide à migrer le schéma en vous connectant à une base de données Cassandra existante et en migrant le schéma vers Spanner. Cet outil est disponible dans
gcloud cli. - Outil de schéma Spanner Cassandra : cet outil vous aide à convertir un DDL exporté de Cassandra vers Spanner. Vous pouvez utiliser l'un de ces deux outils pour l'atelier de programmation. Dans cet atelier de programmation, nous utiliserons l'outil de migration Spanner pour migrer le schéma.
Outil de migration Spanner
L'outil de migration Spanner permet de migrer des schémas à partir de diverses sources de données telles que MySQL, Postgres, Cassandra, etc.
Bien que nous utilisions l'interface de ligne de commande de cet outil pour cet atelier de programmation, nous vous recommandons vivement d'explorer et d'utiliser la version de l'outil basée sur l'interface utilisateur, qui vous aide également à modifier votre schéma Spanner avant son application.
Notez que si la commande spanner-migration-tool est exécutée sur Cloud Shell, elle n'aura peut-être pas accès à l'adresse IP interne de votre VM Cassandra. Nous vous recommandons donc de l'exécuter sur la VM sur laquelle vous avez installé Cassandra.
Exécutez la commande suivante sur la VM sur laquelle vous avez installé Cassandra.
Installer l'outil de migration Spanner
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Si vous rencontrez des problèmes lors de l'installation, consultez installing-spanner-migration-tool pour obtenir des instructions détaillées.
Actualiser les identifiants Gcloud
gcloud auth login
gcloud auth application-default login
Migrer un schéma
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Valider le LDD Spanner
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
À la fin de la migration du schéma, le résultat de cette commande devrait être le suivant :
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Facultatif) Afficher le DDL converti
Vous pouvez consulter le LDD converti et le réappliquer sur Spanner (si vous avez besoin d'apporter d'autres modifications).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
Le résultat de cette commande serait
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(Facultatif) Consultez le rapport sur les conversions.
cat `ls -t cassandra_*report.txt | head -n 1`
Le rapport sur les conversions met en évidence les problèmes à prendre en compte. Par exemple, si la précision maximale d'une colonne ne correspond pas entre la source et Spanner, elle sera mise en évidence ici.
6. Exporter vos données historiques de manière groupée
Pour effectuer la migration groupée, vous devez :
- Provisionnez ou réutilisez un bucket GCS existant.
- Importer le fichier de configuration du pilote Cassandra dans le bucket
- Lancez la migration groupée.
Vous pouvez lancer la migration groupée depuis Cloud Shell ou la VM nouvellement provisionnée. Toutefois, nous vous recommandons d'utiliser la VM pour cet atelier de programmation, car certaines étapes, comme la création d'un fichier de configuration, conservent les fichiers dans le stockage local.
Provisionnez un bucket GCS.
À la fin de cette étape, vous devriez avoir provisionné un bucket GCS et exporté son chemin d'accès dans une variable nommée CASSANDRA_BUCKET_NAME. Si vous souhaitez réutiliser un bucket existant, vous pouvez simplement exporter le chemin d'accès.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Créer et importer un fichier de configuration du pilote
Ici, nous importons un fichier de configuration de pilote Cassandra très basique. Pour connaître le format complet du fichier, veuillez consulter cette page.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Exécuter une migration groupée
Voici un exemple de commande permettant d'exécuter la migration groupée de vos données vers Spanner. Pour les cas d'utilisation réels en production, vous devrez ajuster le type et le nombre de machines en fonction de l'échelle et du débit souhaités. Pour obtenir la liste complète des options, veuillez consulter README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
Vous obtiendrez un résultat semblable à celui-ci. Notez le id généré et utilisez-le pour interroger l'état du job Dataflow.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Exécutez la commande ci-dessous pour vérifier l'état du job et attendez qu'il passe à JOB_STATE_DONE.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Au départ, le job sera en file d'attente, comme
currentState: JOB_STATE_QUEUED
Pendant que le job est mis en file d'attente ou en cours d'exécution, nous vous recommandons vivement d'explorer la page Dataflow/Jobs de l'interface utilisateur de la console Cloud pour le surveiller.
Une fois l'opération terminée, l'état du job passe à :
currentState: JOB_STATE_DONE
7. Faire pointer votre application vers Spanner (bascule)
Après avoir validé méticuleusement l'exactitude et l'intégrité de vos données après la phase de migration, l'étape cruciale consiste à transférer l'orientation opérationnelle de votre application de votre ancien système Cassandra vers la base de données Spanner nouvellement remplie. Cette période de transition critique est généralement appelée "transition".
La phase de transition marque le moment où le trafic des applications en direct est redirigé depuis le cluster Cassandra d'origine et directement connecté à l'infrastructure Spanner robuste et évolutive. Cette transition montre la facilité avec laquelle les applications peuvent exploiter la puissance de Spanner, en particulier lorsqu'elles utilisent l'interface Spanner Cassandra.
L'interface Spanner Cassandra simplifie le processus de transition. Il s'agit principalement de configurer vos applications clientes pour qu'elles utilisent le client Cassandra Spanner natif pour toutes les interactions avec les données. Au lieu de communiquer avec votre base de données Cassandra (source), vos applications commenceront à lire et à écrire des données directement dans Spanner (cible), et ce de manière fluide. Ce changement fondamental de connectivité est généralement obtenu grâce à l'utilisation de SpannerCqlSessionBuilder, un composant clé de la bibliothèque cliente Spanner Cassandra qui facilite l'établissement de connexions à votre instance Spanner. Cela redirige efficacement l'ensemble du flux de trafic de données de votre application vers Spanner.
Pour les applications Java qui utilisent déjà la bibliothèque cassandra-java-driver, l'intégration du client Java Spanner Cassandra ne nécessite que des modifications mineures de l'initialisation CqlSession.
Obtenir la dépendance google-cloud-spanner-cassandra
Pour commencer à utiliser le client Spanner Cassandra, vous devez d'abord intégrer sa dépendance à votre projet. Les artefacts google-cloud-spanner-cassandra sont publiés dans Maven Central, sous l'ID de groupe com.google.cloud. Ajoutez la nouvelle dépendance suivante sous la section <dependencies> existante de votre projet Java. Voici un exemple simplifié montrant comment inclure la dépendance google-cloud-spanner-cassandra :
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Modifier la configuration de la connexion pour se connecter à Spanner
Une fois que vous avez ajouté la dépendance nécessaire, l'étape suivante consiste à modifier la configuration de votre connexion pour vous connecter à la base de données Spanner.
Une application standard interagissant avec un cluster Cassandra utilise souvent un code semblable à celui-ci pour établir une connexion :
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Pour rediriger cette connexion vers Spanner, vous devez modifier la logique de création de votre CqlSession. Au lieu d'utiliser directement le CqlSessionBuilder standard de cassandra-java-driver, vous utiliserez le SpannerCqlSession.builder() fourni par le client Spanner Cassandra. Voici un exemple illustrant la modification de votre code de connexion :
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
En instanciant CqlSession à l'aide de SpannerCqlSession.builder() et en fournissant le databaseUri approprié, votre application établira désormais une connexion à votre base de données Spanner cible via le client Spanner Cassandra. Ce changement essentiel garantit que toutes les opérations de lecture et d'écriture ultérieures effectuées par votre application seront dirigées vers Spanner et traitées par celui-ci, ce qui achèvera la migration initiale. À ce stade, votre application devrait continuer à fonctionner comme prévu, désormais grâce à l'évolutivité et à la fiabilité de Spanner.
Fonctionnement interne du client Spanner Cassandra
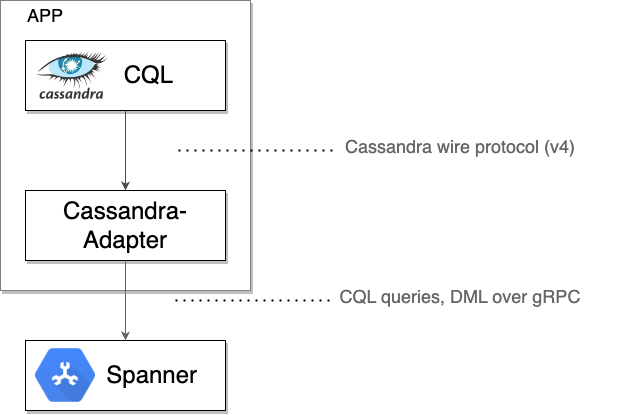
Le client Spanner Cassandra agit en tant que proxy TCP local, interceptant les octets bruts du protocole Cassandra envoyés par un pilote ou un outil client. Il encapsule ensuite ces octets avec les métadonnées nécessaires dans des messages gRPC pour communiquer avec Spanner. Les réponses de Spanner sont retraduites au format filaire Cassandra et renvoyées au pilote ou à l'outil d'origine.
Une fois que vous êtes sûr que Spanner diffuse correctement tout le trafic, vous pouvez éventuellement :
- Mettez hors service le cluster Cassandra d'origine.
8. Nettoyage (facultatif)
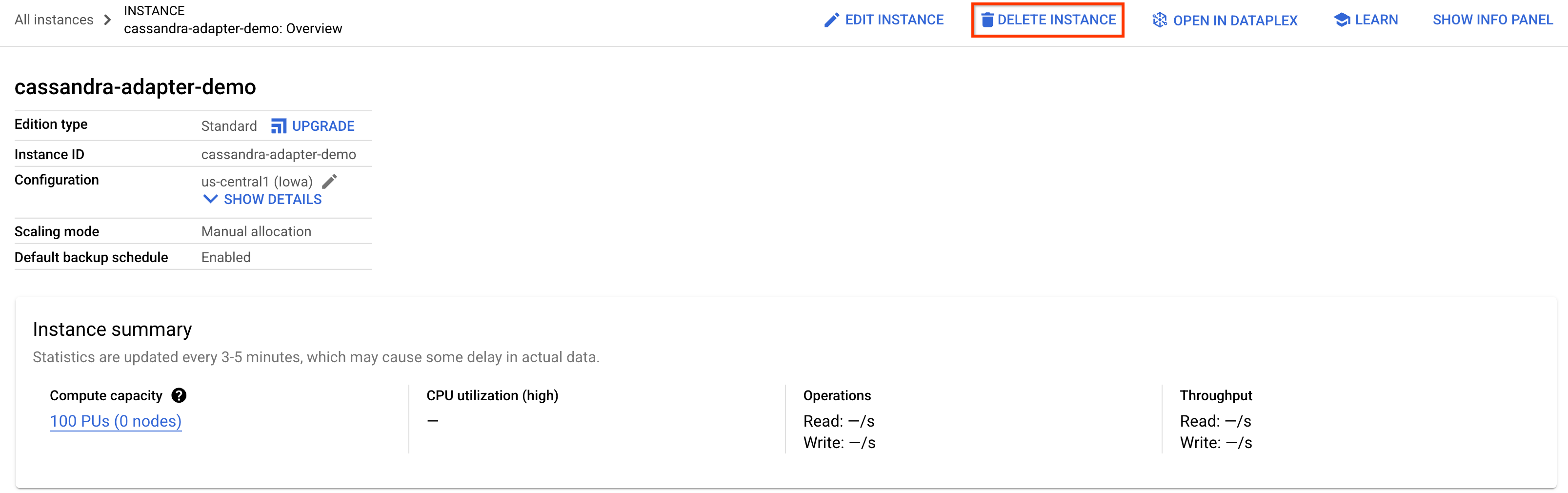
Pour effectuer le nettoyage, accédez à la section Spanner de la console Cloud et supprimez l'instance cassandra-adapter-demo que nous avons créée dans l'atelier de programmation.
Supprimer la base de données Cassandra (si elle est installée localement ou persistante)
Si vous avez installé Cassandra en dehors d'une VM Compute Engine créée ici, suivez les étapes appropriées pour supprimer les données ou désinstaller Cassandra.
9. Félicitations !
Étape suivante
- En savoir plus sur Spanner
- En savoir plus sur l'interface Cassandra