
۱. مقدمه
Spanner یک سرویس پایگاه داده توزیعشده جهانی، کاملاً مدیریتشده، مقیاسپذیر افقی و مناسب برای بارهای کاری رابطهای و غیررابطهای است.
رابط کاربری کاساندرای اسپنر به شما امکان میدهد با استفاده از ابزارها و سینتکس آشنای کاساندرا، از زیرساخت کاملاً مدیریتشده، مقیاسپذیر و با قابلیت دسترسی بالا اسپنر بهرهمند شوید.
آنچه یاد خواهید گرفت
- نحوه راهاندازی یک نمونه و پایگاه داده Spanner.
- چگونه طرحواره و مدل داده کاساندرا خود را تبدیل کنید.
- چگونه دادههای تاریخی خود را به صورت عمده از کاساندرا به اسپنر صادر کنیم.
- چگونه برنامه خود را به جای کاساندرا به Spanner ارجاع دهید.
آنچه نیاز دارید
- یک پروژه گوگل کلود که به یک حساب صورتحساب متصل است.
- دسترسی به دستگاهی که
gcloudCLI در آن نصب و پیکربندی شده است، یا استفاده از Google Cloud Shell . - یک مرورگر وب، مانند کروم یا فایرفاکس .
۲. تنظیمات و الزامات
ایجاد یک پروژه GCP
وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

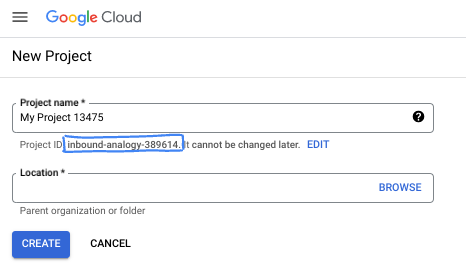
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
تنظیم صورتحساب
در مرحله بعد، باید راهنمای کاربری مدیریت صورتحساب را دنبال کنید و صورتحساب را در کنسول ابری فعال کنید. کاربران جدید گوگل کلود واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند. برای جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید نمونه Spanner را در انتهای codelab با دنبال کردن «مرحله ۹ پاکسازی» خاموش کنید.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:

آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
بعدی
در مرحله بعد، خوشه کاساندرا را مستقر خواهید کرد.
۳. استقرار خوشه کاساندرا (Origin)
برای این آزمایشگاه کد، یک کلاستر کاساندرا تک گرهای روی Compute Engine راهاندازی خواهیم کرد.
۱. یک ماشین مجازی GCE برای کاساندرا ایجاد کنید
برای ایجاد یک نمونه، از دستور gcloud compute instances create از پوسته ابری که قبلاً ارائه شده است، استفاده کنید.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
۲. کاساندرا را نصب کنید
با دنبال کردن دستورالعملهای زیر، از صفحه Navigation menu به VM Instances بروید:  .
.
ماشین مجازی cassandra-origin را جستجو کنید و مطابق شکل زیر با استفاده از SSH به آن متصل شوید:
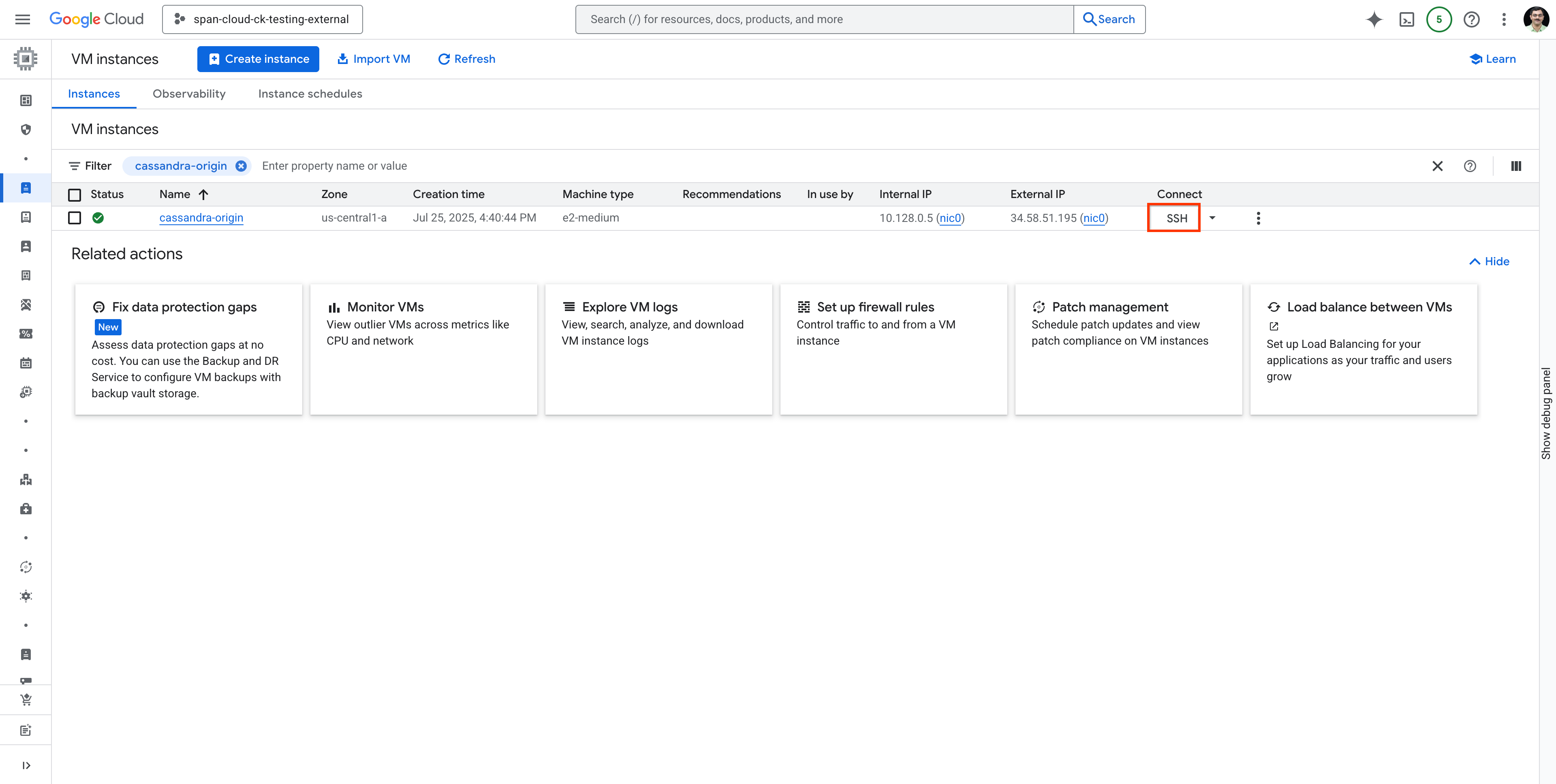 .
.
دستورات زیر را برای نصب کاساندرا روی ماشین مجازی که ایجاد کرده و به آن sshed کردهاید، اجرا کنید.
نصب جاوا (وابستگی به کاساندرا)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
مخزن کاساندرا را اضافه کنید
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
نصب کاساندرا
sudo apt-get update
sudo apt-get install -y cassandra
آدرس شنود را برای سرویس کاساندرا تنظیم کنید.
در اینجا ما از آدرس IP داخلی ماشین مجازی کاساندرا برای امنیت بیشتر استفاده میکنیم.
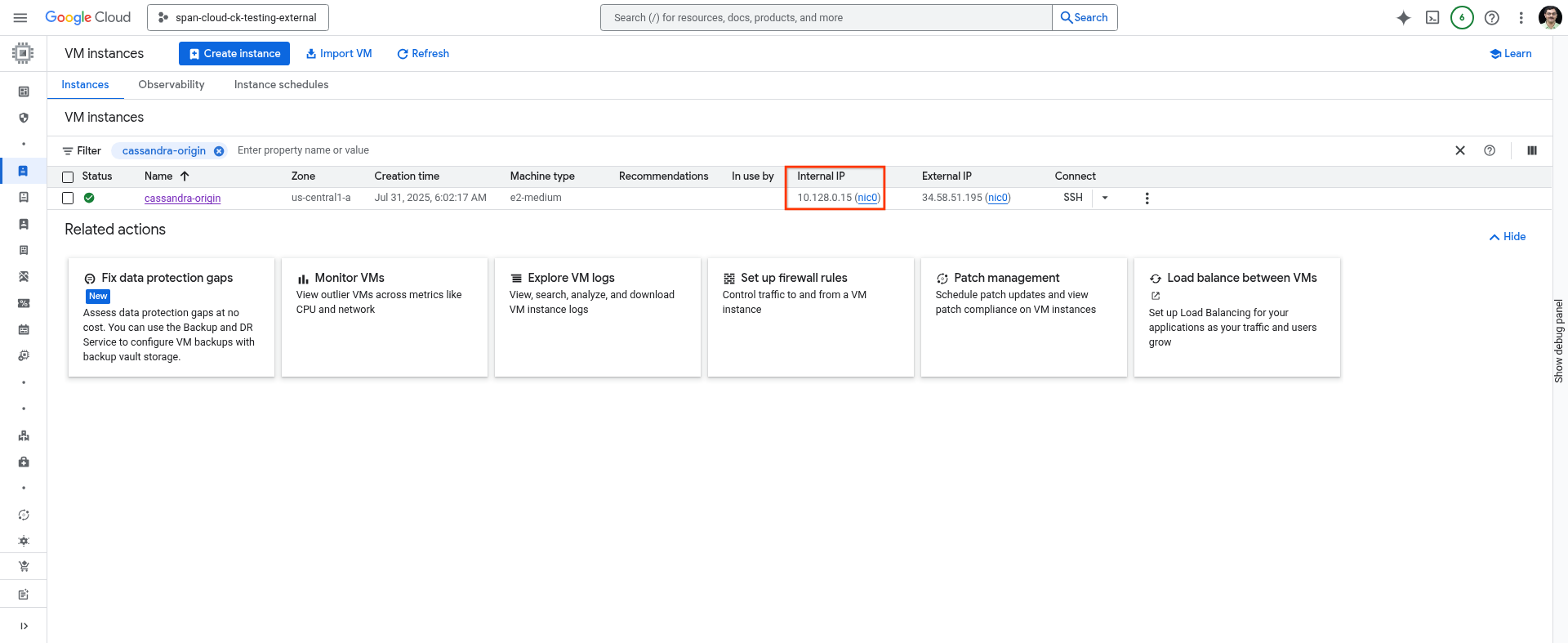
آدرس IP دستگاه میزبان خود را یادداشت کنید
میتوانید از دستور زیر در پوسته ابری استفاده کنید، یا آن را از صفحه VM Instances کنسول ابری دریافت کنید.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
یا
 .
.
آدرس را در فایل پیکربندی بهروزرسانی کنید
شما میتوانید از ویرایشگر دلخواه خود برای بهروزرسانی فایل پیکربندی کاساندرا استفاده کنید.
sudo vim /etc/cassandra/cassandra.yaml
rpc_address: را به آدرس IP ماشین مجازی تغییر دهید، فایل را ذخیره کرده و ببندید.
فعال کردن سرویس کاساندرا روی ماشین مجازی
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
۳. ایجاد یک فضای کلید و جدول {create-keyspace-and-table}
ما از یک مثال جدول «users» استفاده خواهیم کرد و یک فضای کلید به نام «analytics» ایجاد خواهیم کرد.
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
داخل cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
جلسه SSH را باز بگذارید یا آدرس IP این ماشین مجازی ( hostname -I ) را یادداشت کنید.
بعدی
در مرحله بعد، یک نمونه و پایگاه داده Cloud Spanner راهاندازی خواهید کرد.
۴. یک نمونه Spanner (Target) ایجاد کنید
در Spanner، یک نمونه (instance) خوشهای از منابع محاسباتی و ذخیرهسازی است که میزبان یک یا چند پایگاه داده Spanner است. برای میزبانی یک پایگاه داده Spanner در این codelab، حداقل به یک نمونه نیاز دارید.
نسخه SDK جی کلود را بررسی کنید
قبل از ایجاد یک نمونه، مطمئن شوید که gcloud SDK در پوسته Google Cloud به نسخه مورد نیاز بهروزرسانی شده است - هر نسخهای بزرگتر از gcloud SDK 531.0.0 . میتوانید نسخه gcloud SDK خود را با دنبال کردن دستور زیر پیدا کنید.
$ gcloud version | grep Google
در اینجا یک مثال خروجی آورده شده است:
Google Cloud SDK 489.0.0
اگر نسخهای که استفاده میکنید قدیمیتر از نسخه مورد نیاز ۵۳۱.۰.۰ است (در مثال قبلی 489.0.0 )، باید Google Cloud SDK خود را با اجرای دستور زیر ارتقا دهید:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
فعال کردن Spanner API
در داخل Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است. از اولین دستور زیر برای یافتن شناسه پروژه پیکربندی شده فعلی استفاده کنید. اگر نتیجه مورد انتظار نبود، دستور دوم زیر شناسه صحیح را تنظیم میکند.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
منطقه پیشفرض خود را روی us-central1 پیکربندی کنید. میتوانید این را به منطقه دیگری که توسط تنظیمات منطقهای Spanner پشتیبانی میشود، تغییر دهید.
gcloud config set compute/region us-central1
فعال کردن Spanner API:
gcloud services enable spanner.googleapis.com
نمونه Spanner را ایجاد کنید
در این بخش، شما یک نمونه آزمایشی رایگان یا یک نمونه آماده ایجاد خواهید کرد. در طول این کد، شناسه نمونه Spanner Cassandra Adapter مورد استفاده cassandra-adapter-demo است که با استفاده از خط فرمان export به عنوان متغیر SPANNER_INSTANCE_ID تنظیم میشود. به صورت اختیاری، میتوانید نام شناسه نمونه خود را انتخاب کنید.
یک نمونه آزمایشی رایگان از Spanner ایجاد کنید
یک نسخه آزمایشی رایگان ۹۰ روزه Spanner برای هر کسی که دارای حساب گوگل است و Cloud Billing را در پروژه خود فعال کرده است، در دسترس است. تا زمانی که نسخه آزمایشی رایگان خود را به نسخه پولی ارتقا ندهید، هزینهای از شما دریافت نمیشود. Spanner Cassandra Adapter در نسخه آزمایشی رایگان پشتیبانی میشود. در صورت واجد شرایط بودن، با باز کردن Cloud Shell و اجرای این دستور، یک نسخه آزمایشی رایگان ایجاد کنید:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
خروجی دستور:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
۵. طرحواره و مدل داده کاساندرا را به Spanner منتقل کنید
مرحله اولیه و حیاتی انتقال دادهها از پایگاه داده کاساندرا به اسپنر شامل تبدیل طرحواره کاساندرای موجود برای همسو شدن با الزامات ساختاری و نوع داده اسپنر است.
برای سادهسازی این فرآیند پیچیدهی انتقال طرحواره، از هر یک از دو ابزار متنباز ارزشمند ارائه شده توسط Spanner استفاده کنید:
- ابزار مهاجرت Spanner : این ابزار با اتصال به یک پایگاه داده موجود Cassandra و انتقال طرحواره به Spanner به شما کمک میکند تا طرحواره را منتقل کنید. این ابزار به عنوان بخشی از
gcloud cliدر دسترس است. - ابزار Spanner Cassandra Schema : این ابزار به شما کمک میکند تا یک DDL اکسپورت شده از Cassandra را به Spanner تبدیل کنید. میتوانید از هر یک از این دو ابزار برای codelab استفاده کنید. در این codelab، ما از ابزار مهاجرت Spanner برای مهاجرت schema استفاده خواهیم کرد.
ابزار مهاجرت آچار
ابزار مهاجرت Spanner به انتقال طرحواره از منابع داده مختلف مانند MySQL، Postgres، Cassandra و غیره کمک میکند.
اگرچه برای اهداف این آزمایشگاه کد، ما از رابط خط فرمان (CLI) این ابزار استفاده خواهیم کرد، اکیداً توصیه میکنیم نسخه مبتنی بر رابط کاربری این ابزار را بررسی و استفاده کنید، که به شما کمک میکند قبل از اعمال، طرحواره Spanner خود را اصلاح کنید.
توجه داشته باشید که اگر spanner-migration-tool روی Cloud Shell اجرا شود، ممکن است به آدرس IP داخلی ماشین مجازی Cassandra شما دسترسی نداشته باشد. از این رو، توصیه میکنیم همین ابزار را روی ماشین مجازی که Cassandra را در آن نصب کردهاید، اجرا کنید.
دستور زیر را روی ماشین مجازی که کاساندرا را در آن نصب کردهاید، اجرا کنید.
ابزار مهاجرت Spanner را نصب کنید
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
اگر در نصب با مشکلی مواجه شدید، برای جزئیات بیشتر به installation-spanner-migration-tool مراجعه کنید.
اعتبارنامههای Gcloud را بهروزرسانی کنید
gcloud auth login
gcloud auth application-default login
طرحواره مهاجرت
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
تأیید DDL مربوط به Spanner
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
در پایان انتقال طرحواره، خروجی این دستور باید به صورت زیر باشد:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(اختیاری) DDL تبدیلشده را ببینید
میتوانید DDL تبدیلشده را ببینید و دوباره آن را در Spanner اعمال کنید (اگر به تغییرات بیشتری نیاز دارید)
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
خروجی این دستور به صورت زیر خواهد بود:
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(اختیاری) گزارش تبدیل را ببینید
cat `ls -t cassandra_*report.txt | head -n 1`
گزارش تبدیل، مواردی را که باید در نظر داشته باشید، برجسته میکند. برای مثال، اگر در حداکثر دقت یک ستون بین منبع و Spanner اختلافی وجود داشته باشد، در اینجا برجسته خواهد شد.
۶. دادههای تاریخی خود را به صورت انبوه صادر کنید
برای انجام مهاجرت فلهای، باید:
- یک سطل GCS موجود را تهیه یا دوباره استفاده کنید.
- فایل پیکربندی درایور کاساندرا را در سطل بارگذاری کنید
- مهاجرت انبوه را آغاز کنید.
اگرچه میتوانید مهاجرت عمده را یا از Cloud Shell یا از ماشین مجازی تازه آمادهشده آغاز کنید، اما توصیه میکنیم برای این آزمایشگاه کد از ماشین مجازی استفاده کنید زیرا برخی از مراحل مانند ایجاد فایل پیکربندی، فایلها را در فضای ذخیرهسازی محلی حفظ میکند.
یک سطل GCS تهیه کنید.
در پایان این مرحله، شما باید یک سطل GCS تهیه کرده باشید و مسیر آن را در متغیری به نام CASSANDRA_BUCKET_NAME صادر کرده باشید. اگر میخواهید از یک سطل موجود دوباره استفاده کنید، میتوانید با صادر کردن مسیر، ادامه دهید.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
فایل پیکربندی درایور را ایجاد و آپلود کنید
در اینجا ما یک فایل پیکربندی درایور کاساندرا بسیار ساده را آپلود میکنیم. لطفاً برای مشاهدهی قالب کامل فایل به این لینک مراجعه کنید.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
اجرای مهاجرت انبوه
این یک دستور نمونه برای اجرای مهاجرت انبوه دادههای شما به Spanner است. برای موارد استفاده واقعی در محیط عملیاتی، باید نوع و تعداد ماشین را بر اساس مقیاس و توان عملیاتی مورد نظر خود تنظیم کنید. لطفاً برای مشاهده لیست کامل گزینهها، به README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration مراجعه کنید.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
این خروجی مانند زیر تولید میکند. id که تولید میشود را یادداشت کنید و از همان برای پرسوجو از وضعیت کار جریان داده استفاده کنید.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
دستور زیر را برای بررسی وضعیت job اجرا کنید و منتظر بمانید تا وضعیت به JOB_STATE_DONE تغییر کند.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
در ابتدا، کار در حالت صفبندی شده مانند زیر خواهد بود:
currentState: JOB_STATE_QUEUED
در حالی که کار در صف انتظار/در حال اجرا است، اکیداً توصیه میکنیم برای نظارت بر کار، صفحه Dataflow/Jobs را در رابط کاربری Cloud Console بررسی کنید.
پس از انجام این کار، وضعیت کار به صورت زیر تغییر خواهد کرد:
currentState: JOB_STATE_DONE
۷. درخواست خود را به Spanner (Cutover) ارجاع دهید
پس از تأیید دقیق صحت و یکپارچگی دادههای شما پس از مرحله مهاجرت، گام اساسی، انتقال تمرکز عملیاتی برنامه شما از سیستم قدیمی کاساندرا به پایگاه داده جدید Spanner است. این دوره انتقال حیاتی معمولاً به عنوان " گذار " شناخته میشود.
مرحلهی گذار، لحظهای را نشان میدهد که ترافیک برنامههای کاربردی فعال از خوشهی اصلی کاساندرا هدایت شده و مستقیماً به زیرساخت قوی و مقیاسپذیر اسپنر متصل میشود. این گذار، سهولت بهرهبرداری برنامهها از قدرت اسپنر، بهویژه هنگام استفاده از رابط کاساندرای اسپنر را نشان میدهد.
با رابط کاربری Spanner Cassandra، فرآیند برش سادهسازی شده است. این فرآیند در درجه اول شامل پیکربندی برنامههای کلاینت شما برای استفاده از کلاینت بومی Spanner Cassandra برای تمام تعاملات داده است. به جای برقراری ارتباط با پایگاه داده Cassandra (مبدا)، برنامههای شما به طور یکپارچه شروع به خواندن و نوشتن دادهها مستقیماً در Spanner (هدف) میکنند. این تغییر اساسی در اتصال معمولاً از طریق استفاده از SpannerCqlSessionBuilder ، یک جزء کلیدی از کتابخانه Spanner Cassandra Client که ایجاد اتصالات به نمونه Spanner شما را تسهیل میکند، حاصل میشود. این امر به طور مؤثر کل جریان ترافیک داده برنامه شما را به Spanner تغییر مسیر میدهد.
برای برنامههای جاوا که از قبل از کتابخانه cassandra-java-driver استفاده میکنند، یکپارچهسازی Spanner Cassandra Java Client تنها به تغییرات جزئی در مقداردهی اولیه CqlSession نیاز دارد.
دریافت وابستگی google-cloud-spanner-cassandra
برای شروع استفاده از کلاینت Spanner Cassandra، ابتدا باید وابستگی آن را در پروژه خود بگنجانید. مصنوعات google-cloud-spanner-cassandra در Maven Central، تحت شناسه گروه com.google.cloud منتشر شدهاند. وابستگی جدید زیر را در بخش <dependencies> موجود در پروژه جاوا خود اضافه کنید. در اینجا یک مثال ساده از نحوه گنجاندن وابستگی google-cloud-spanner-cassandra آورده شده است:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
پیکربندی اتصال را برای اتصال به Spanner تغییر دهید
پس از افزودن وابستگیهای لازم، مرحله بعدی تغییر پیکربندی اتصال برای اتصال به پایگاه داده Spanner است.
یک برنامهی معمولی که با یک کلاستر کاساندرا در تعامل است، اغلب از کدی مشابه کد زیر برای ایجاد اتصال استفاده میکند:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
برای هدایت این اتصال به Spanner، باید منطق ایجاد CqlSession خود را تغییر دهید. به جای استفاده مستقیم از CqlSessionBuilder استاندارد از cassandra-java-driver ، از SpannerCqlSession.builder() ارائه شده توسط Spanner Cassandra Client استفاده خواهید کرد. در اینجا یک مثال توضیحی از نحوه تغییر کد اتصال شما آورده شده است:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
با نمونهسازی CqlSession با استفاده از SpannerCqlSession.builder() و ارائه databaseUri صحیح، برنامه شما اکنون از طریق Spanner Cassandra Client به پایگاه داده Spanner هدف شما متصل میشود. این تغییر اساسی تضمین میکند که تمام عملیات خواندن و نوشتن بعدی که توسط برنامه شما انجام میشود، به Spanner هدایت و توسط آن ارائه میشود و به طور مؤثر برش اولیه را تکمیل میکند. در این مرحله، برنامه شما باید طبق انتظار به عملکرد خود ادامه دهد، که اکنون با مقیاسپذیری و قابلیت اطمینان Spanner پشتیبانی میشود.
زیر کاپوت: نحوه عملکرد کلاینت Spanner Cassandra
کلاینت کاساندرای اسپنر به عنوان یک پروکسی TCP محلی عمل میکند و بایتهای خام پروتکل کاساندرای ارسال شده توسط یک درایور یا ابزار کلاینت را رهگیری میکند. سپس این بایتها را به همراه فرادادههای لازم در پیامهای gRPC برای ارتباط با اسپنر قرار میدهد. پاسخهای اسپنر دوباره به قالب سیمی کاساندرا ترجمه شده و به درایور یا ابزار مبدا ارسال میشوند.
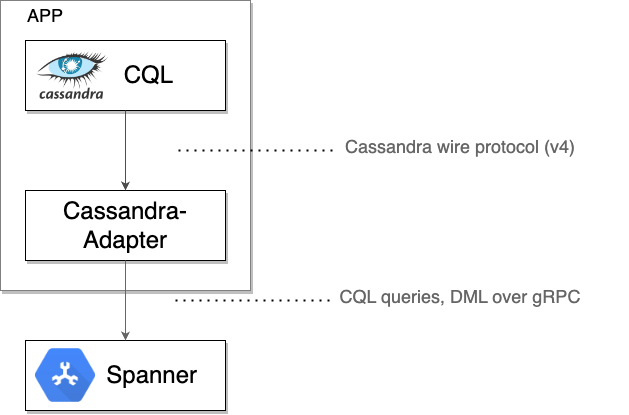
وقتی مطمئن شدید که Spanner به درستی به تمام ترافیک سرویس میدهد، در نهایت میتوانید:
- خوشه اصلی کاساندرا را از رده خارج کنید.
۸. تمیز کردن (اختیاری)
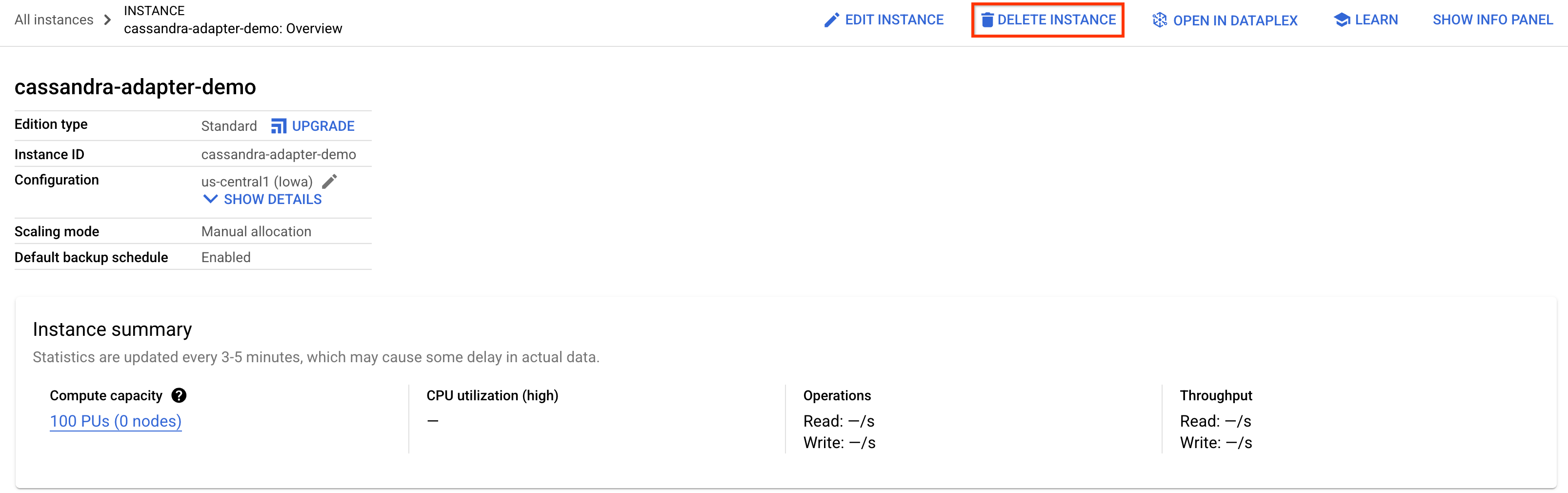
برای پاکسازی، کافیست به بخش Spanner در Cloud Console بروید و نمونه cassandra-adapter-demo را که در codelab ایجاد کردیم، حذف کنید.
حذف پایگاه داده کاساندرا (در صورت نصب محلی یا در صورت نیاز)
اگر کاساندرا را خارج از یک ماشین مجازی Compute Engine که در اینجا ایجاد شده است نصب کردهاید، مراحل مناسب را برای حذف دادهها یا حذف نصب کاساندرا دنبال کنید.
۹. تبریک میگویم!
بعدش چی؟
- درباره اسپنر بیشتر بدانید.
- درباره رابط کاربری کاساندرا بیشتر بدانید.