
1. Introducción
Spanner es un servicio de base de datos completamente administrado, con escalabilidad horizontal y distribuido a nivel global que es ideal para cargas de trabajo relacionales y no relacionales.
La interfaz de Cassandra de Spanner te permite aprovechar la infraestructura completamente administrada, escalable y con alta disponibilidad de Spanner con herramientas y sintaxis conocidas de Cassandra.
Qué aprenderás
- Cómo configurar una instancia y una base de datos de Spanner
- Cómo convertir tu esquema y modelo de datos de Cassandra
- Cómo exportar de forma masiva tus datos históricos de Cassandra a Spanner
- Cómo dirigir tu aplicación a Spanner en lugar de Cassandra
Requisitos
- Es un proyecto de Google Cloud que está conectado a una cuenta de facturación.
- Acceso a una máquina con la CLI de
gcloudinstalada y configurada, o bien usa Google Cloud Shell. - Un navegador web, como Chrome o Firefox
2. Configuración y requisitos
Crea un proyecto de GCP
Accede a la consola de Google Cloud y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
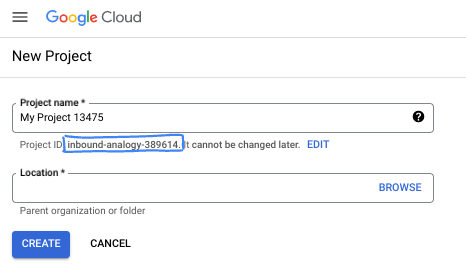
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
Configuración de facturación
A continuación, deberás seguir la guía del usuario para administrar la facturación y habilitar la facturación en la consola de Cloud. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de USD 300. Para evitar que se te facture más allá de este instructivo, puedes cerrar la instancia de Spanner al final del codelab. Para ello, sigue los pasos que se indican en el “Paso 9: Realiza una limpieza”.
Inicie Cloud Shell
Si bien Google Cloud se puede operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En la consola de Google Cloud, haz clic en el ícono de Cloud Shell en la barra de herramientas de la parte superior derecha:

El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Cuál es el próximo paso
A continuación, implementarás el clúster de Cassandra.
3. Implementa el clúster de Cassandra (origen)
En este codelab, configuraremos un clúster de Cassandra de un solo nodo en Compute Engine.
1. Crea una VM de GCE para Cassandra
Para crear una instancia, usa el comando gcloud compute instances create de Cloud Shell aprovisionado anteriormente.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Instala Cassandra
Navega a VM Instances desde la página Navigation menu siguiendo las instrucciones que se indican a continuación:  .
.
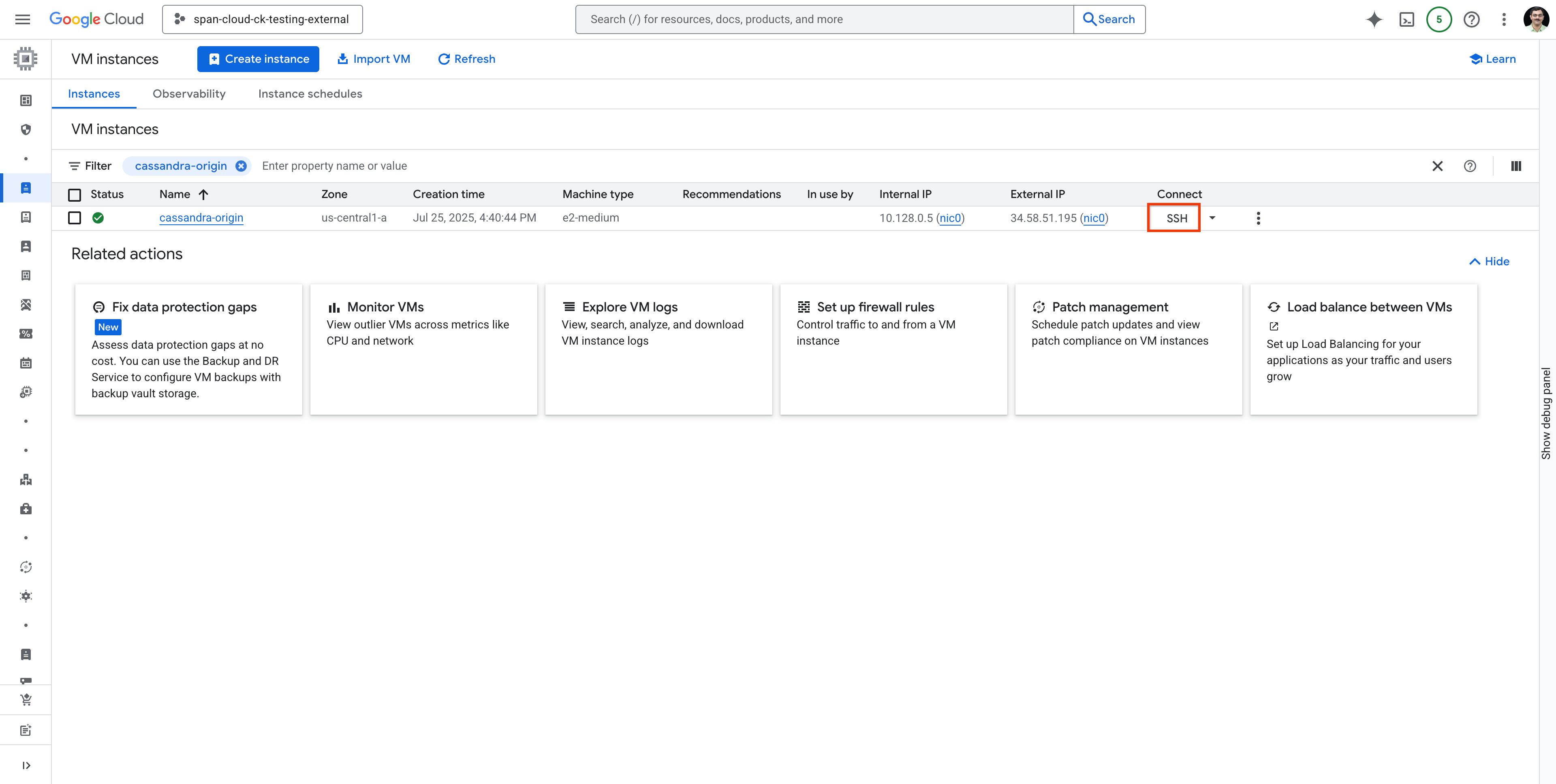
Busca la VM cassandra-origin y conéctate a ella con SSH, como se muestra a continuación:
 .
.
Ejecuta los siguientes comandos para instalar Cassandra en la VM que creaste y a la que accediste con SSH.
Instala Java (dependencia de Cassandra)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Agrega el repositorio de Cassandra
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Instala Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
Establece la dirección de escucha para el servicio de Cassandra.
Aquí usamos la dirección IP interna de la VM de Cassandra para mayor seguridad.
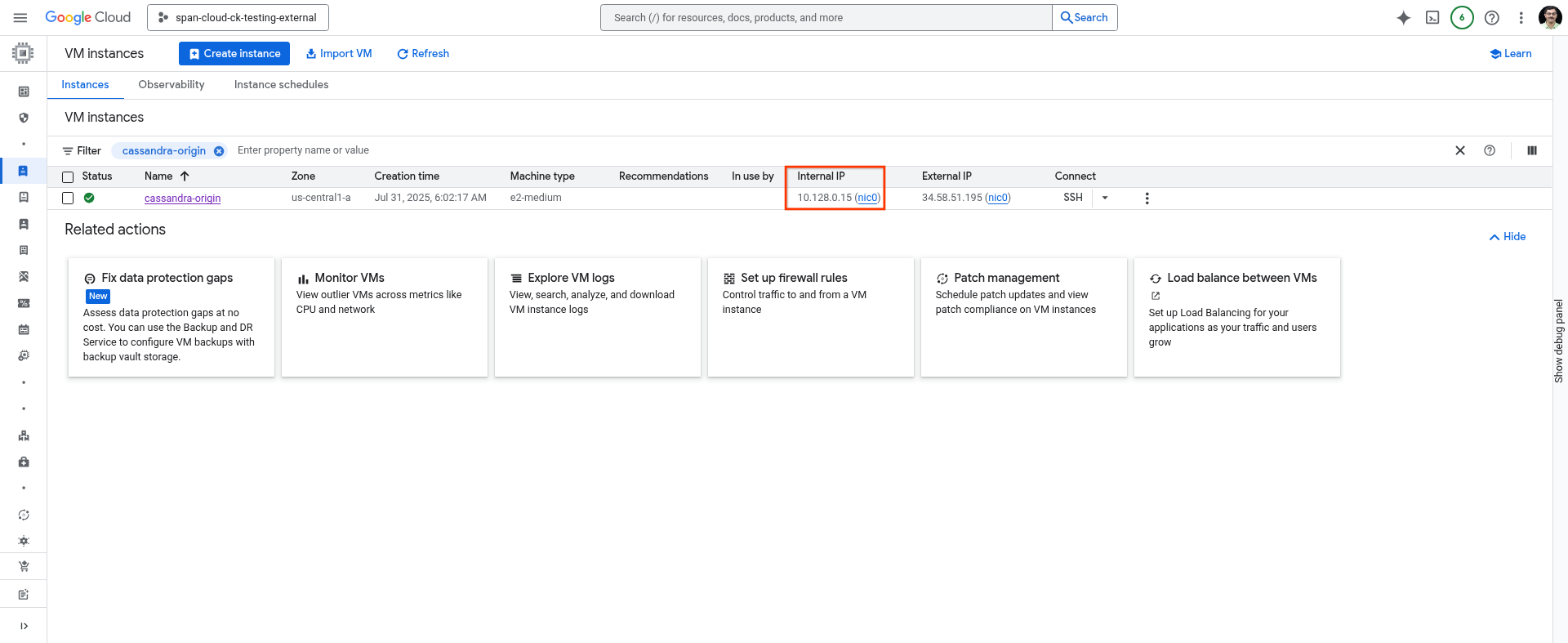
Anota la dirección IP de tu máquina host.
Puedes usar el siguiente comando en Cloud Shell o obtenerlo de la página VM Instances de Cloud Console.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
O
 .
.
Actualiza la dirección en el archivo de configuración
Puedes usar el editor que prefieras para actualizar el archivo de configuración de Cassandra.
sudo vim /etc/cassandra/cassandra.yaml
Cambia rpc_address: por la dirección IP de la VM, guarda y cierra el archivo.
Habilita el servicio de Cassandra en la VM
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Crea un espacio de claves y una tabla {create-keyspace-and-table}
Usaremos un ejemplo de tabla "users" y crearemos un espacio de claves llamado "analytics".
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
Dentro de cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Deja abierta la sesión de SSH o anota la dirección IP de esta VM (hostname -I).
Cuál es el próximo paso
A continuación, configurarás una instancia y una base de datos de Cloud Spanner.
4. Crea una instancia de Spanner (destino)
En Spanner, una instancia es un clúster de recursos de procesamiento y almacenamiento que aloja una o más bases de datos de Spanner. Necesitarás al menos 1 instancia para alojar una base de datos de Spanner para este codelab.
Verifica la versión del SDK de gcloud
Antes de crear una instancia, asegúrate de que el SDK de gcloud en Google Cloud Shell se haya actualizado a la versión requerida (cualquier versión posterior a gcloud SDK 531.0.0). Para encontrar la versión del SDK de gcloud, sigue el comando que se muestra a continuación.
$ gcloud version | grep Google
Este es un ejemplo del resultado:
Google Cloud SDK 489.0.0
Si la versión que usas es anterior a la versión 531.0.0 requerida (489.0.0 en el ejemplo anterior), debes actualizar tu SDK de Google Cloud ejecutando el siguiente comando:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Habilita la API de Spanner
En Cloud Shell, asegúrate de que tu ID del proyecto esté configurado. Usa el primer comando que se muestra a continuación para encontrar el ID del proyecto configurado actualmente. Si el resultado no es el esperado, el segundo comando que se muestra a continuación establece el correcto.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Configura tu región predeterminada como us-central1. Puedes cambiarla a otra región compatible con las configuraciones regionales de Spanner.
gcloud config set compute/region us-central1
Habilita la API de Spanner:
gcloud services enable spanner.googleapis.com
Crea la instancia de Spanner
En esta sección, crearás una instancia de prueba gratuita o una instancia aprovisionada. A lo largo de este codelab, el ID de instancia del adaptador de Cassandra de Spanner que se usa es cassandra-adapter-demo, establecido como la variable SPANNER_INSTANCE_ID con la línea de comandos export. De manera opcional, puedes elegir el nombre de ID de tu instancia.
Crea una instancia de Spanner de prueba gratuita
Cualquier persona con una Cuenta de Google que tenga habilitada la Facturación de Cloud en su proyecto puede acceder a una instancia de prueba gratuita de Spanner durante 90 días. No se te cobrará a menos que elijas actualizar tu instancia de prueba gratuita a una instancia pagada. El adaptador de Spanner para Cassandra es compatible con la instancia de prueba gratuita. Si cumples con los requisitos, abre Cloud Shell y ejecuta este comando para crear una instancia de prueba gratuita:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Resultado del comando:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Migra el esquema y el modelo de datos de Cassandra a Spanner
La fase inicial y crucial de la transición de datos de una base de datos de Cassandra a Spanner implica transformar el esquema de Cassandra existente para que se alinee con los requisitos estructurales y de tipo de datos de Spanner.
Para optimizar este complejo proceso de migración de esquemas, usa cualquiera de las dos valiosas herramientas de código abierto que proporciona Spanner:
- Herramienta de migración de Spanner: Esta herramienta te ayuda a migrar el esquema conectándose a una base de datos de Cassandra existente y migrando el esquema a Spanner. Esta herramienta está disponible como parte de
gcloud cli. - Herramienta de esquema de Spanner Cassandra: Esta herramienta te ayuda a convertir un DDL exportado de Cassandra a Spanner. Podrías usar cualquiera de estas dos herramientas para el codelab. En este codelab, usaremos la herramienta de migración de Spanner para migrar el esquema.
Herramienta de migración de Spanner
La herramienta de migración de Spanner ayuda a migrar esquemas desde varias fuentes de datos, como MySQL, Postgres, Cassandra, etcétera.
Si bien, para los fines de este codelab, usaremos la CLI de esta herramienta, te recomendamos que explores y uses la versión basada en la IU, que también te ayuda a realizar modificaciones en tu esquema de Spanner antes de que se aplique.
Ten en cuenta que, si se ejecuta spanner-migration-tool en Cloud Shell, es posible que no tenga acceso a la dirección IP interna de tu VM de Cassandra. Por lo tanto, te recomendamos que ejecutes el mismo comando en la VM en la que instalaste Cassandra.
Ejecuta lo siguiente en la VM en la que instalaste Cassandra.
Instala la herramienta de migración de Spanner
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Si tienes problemas con la instalación, consulta installing-spanner-migration-tool para ver los pasos detallados.
Actualiza las credenciales de gcloud
gcloud auth login
gcloud auth application-default login
Migrar esquema
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Verifica el DDL de Spanner
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
Al final de la migración del esquema, el resultado de este comando debería ser el siguiente:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Opcional) Consulta el DDL convertido
Puedes ver el DDL convertido y volver a aplicarlo en Spanner (si necesitas realizar cambios adicionales).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
El resultado de este comando sería el siguiente:
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
Consulta el informe de conversiones (opcional)
cat `ls -t cassandra_*report.txt | head -n 1`
El informe de conversión destaca los problemas que debes tener en cuenta. Por ejemplo, si hay una discrepancia en la precisión máxima de una columna entre la fuente y Spanner, se destacará aquí.
6. Exporta de forma masiva tus datos históricos
Para realizar la migración masiva, deberás hacer lo siguiente:
- Aprovisiona o reutiliza un bucket existente de GCS.
- Sube el archivo de configuración del controlador de Cassandra al bucket
- Inicia la migración masiva.
Si bien puedes iniciar la migración masiva desde Cloud Shell o la VM aprovisionada recientemente, te recomendamos que uses la VM para este codelab, ya que algunos de los pasos, como la creación de un archivo de configuración, conservarán los archivos en el almacenamiento local.
Aprovisiona un bucket de GCS.
Al final de este paso, deberías haber aprovisionado un bucket de GCS y exportado su ruta en una variable llamada CASSANDRA_BUCKET_NAME. Si deseas reutilizar un bucket existente, puedes continuar con la exportación de la ruta de acceso.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Crea y sube el archivo de configuración del conductor
Aquí subimos un archivo de configuración del controlador de Cassandra muy básico. Consulta este vínculo para ver el formato completo del archivo.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Ejecuta la migración masiva
Este es un comando de muestra para ejecutar la migración masiva de tus datos a Spanner. Para los casos de uso de producción reales, deberás ajustar el tipo y la cantidad de máquinas según la escala y la capacidad de procesamiento deseadas. Visita README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration para ver la lista completa de opciones.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
Esto generará un resultado como el siguiente. Ten en cuenta el id que se genera y usa el mismo para consultar el estado del trabajo de Dataflow.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Ejecuta el siguiente comando para verificar el estado del trabajo y espera hasta que cambie a JOB_STATE_DONE.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Inicialmente, el trabajo estará en estado de cola, como se muestra a continuación:
currentState: JOB_STATE_QUEUED
Mientras el trabajo está en cola o en ejecución, te recomendamos que explores la página Dataflow/Jobs en la IU de Cloud Console para supervisar el trabajo.
Una vez que se complete el trabajo, su estado cambiará a lo siguiente:
currentState: JOB_STATE_DONE
7. Dirige tu aplicación a Spanner (migración)
Después de validar meticulosamente la precisión y la integridad de tus datos tras la fase de migración, el paso fundamental es cambiar el enfoque operativo de tu aplicación del sistema heredado de Cassandra a la base de datos de Spanner recién completada. Este período de transición crítico se conoce comúnmente como "corte".
La fase de corte marca el momento en que el tráfico de la aplicación activa se redirecciona desde el clúster original de Cassandra y se conecta directamente a la infraestructura robusta y escalable de Spanner. Esta transición demuestra la facilidad con la que las aplicaciones pueden aprovechar la potencia de Spanner, en especial cuando se utiliza la interfaz de Spanner Cassandra.
Con la interfaz de Cassandra de Spanner, el proceso de corte se optimiza. Principalmente, implica configurar tus aplicaciones cliente para que utilicen el cliente nativo de Spanner Cassandra para toda la interacción de datos. En lugar de comunicarse con tu base de datos de Cassandra (origen), tus aplicaciones comenzarán a leer y escribir datos directamente en Spanner (destino) sin problemas. Este cambio fundamental en la conectividad se logra, por lo general, a través del uso de SpannerCqlSessionBuilder, un componente clave de la biblioteca cliente de Spanner Cassandra que facilita el establecimiento de conexiones a tu instancia de Spanner. Esto redirige de manera eficaz todo el flujo de tráfico de datos de tu aplicación a Spanner.
En el caso de las aplicaciones de Java que ya usan la biblioteca cassandra-java-driver, la integración del cliente de Java de Spanner Cassandra solo requiere cambios menores en la inicialización de CqlSession.
Cómo obtener la dependencia de google-cloud-spanner-cassandra
Para comenzar a usar el cliente de Spanner Cassandra, primero debes incorporar su dependencia en tu proyecto. Los artefactos de google-cloud-spanner-cassandra se publican en Maven Central, con el ID de grupo com.google.cloud. Agrega la siguiente dependencia nueva en la sección <dependencies> existente de tu proyecto de Java. A continuación, se muestra un ejemplo simplificado de cómo incluirías la dependencia de google-cloud-spanner-cassandra:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Cambia la configuración de conexión para conectarte a Spanner
Una vez que agregues la dependencia necesaria, el siguiente paso es cambiar la configuración de conexión para conectarte a la base de datos de Spanner.
Una aplicación típica que interactúa con un clúster de Cassandra suele emplear código similar al siguiente para establecer una conexión:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Para redireccionar esta conexión a Spanner, debes modificar la lógica de creación de CqlSession. En lugar de usar directamente el CqlSessionBuilder estándar de cassandra-java-driver, utilizarás el SpannerCqlSession.builder() proporcionado por el cliente de Spanner Cassandra. A continuación, se incluye un ejemplo ilustrativo de cómo modificar tu código de conexión:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
Si creas una instancia de CqlSession con SpannerCqlSession.builder() y proporcionas el databaseUri correcto, tu aplicación ahora establecerá una conexión a través del cliente de Spanner Cassandra con tu base de datos de Spanner de destino. Este cambio fundamental garantiza que todas las operaciones de lectura y escritura posteriores que realice tu aplicación se dirijan a Spanner y se publiquen desde allí, lo que completa de manera efectiva la migración inicial. En este punto, tu aplicación debería seguir funcionando como se espera, ahora con la potencia de la escalabilidad y la confiabilidad de Spanner.
Bajo el capó: Cómo funciona el cliente de Cassandra de Spanner
El cliente de Cassandra de Spanner actúa como un proxy TCP local que intercepta los bytes sin procesar del protocolo de Cassandra que envía un controlador o una herramienta de cliente. Luego, une estos bytes con los metadatos necesarios en mensajes de gRPC para la comunicación con Spanner. Las respuestas de Spanner se vuelven a traducir al formato de transferencia de Cassandra y se envían al controlador o la herramienta de origen.
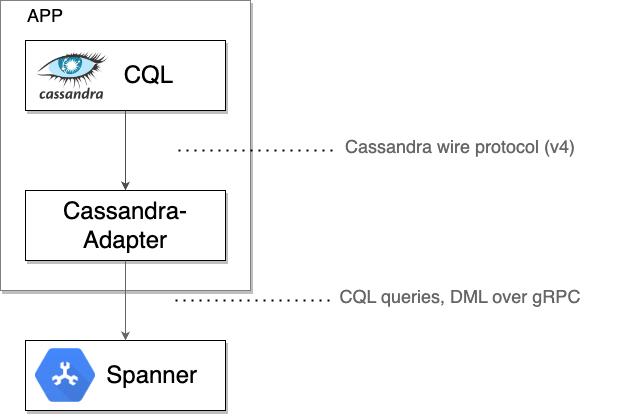
Una vez que te asegures de que Spanner procesa todo el tráfico correctamente, puedes hacer lo siguiente:
- Retira el clúster original de Cassandra.
8. Limpieza (opcional)
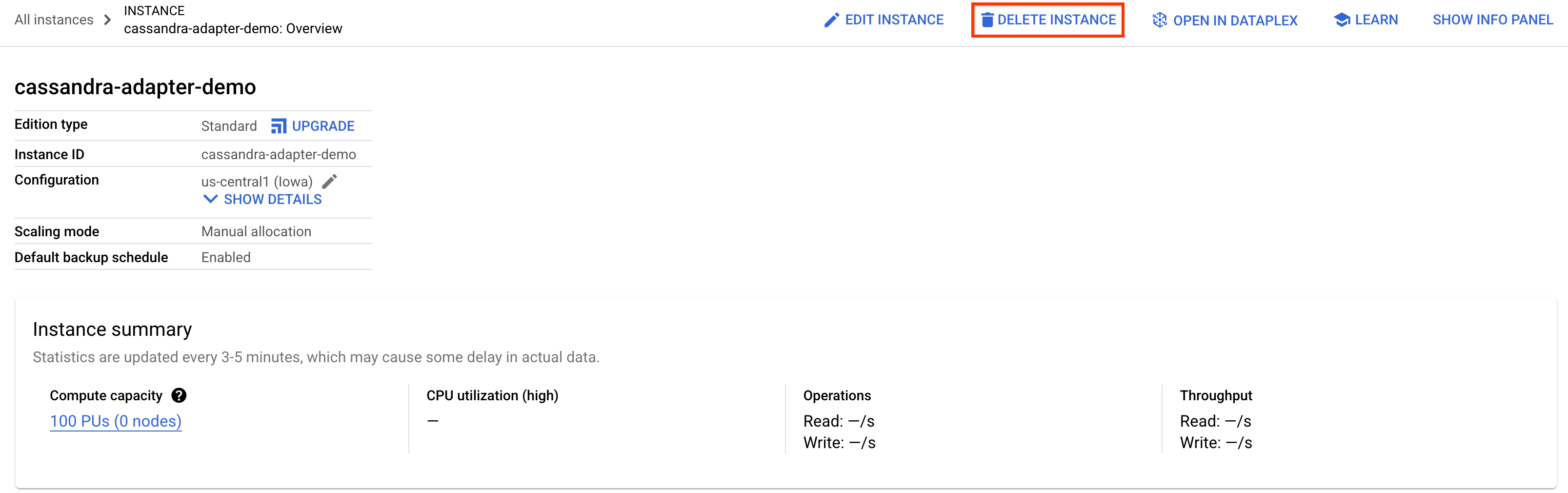
Para limpiar, ve a la sección de Spanner de la consola de Cloud y borra la instancia cassandra-adapter-demo que creamos en el codelab.
Borra la base de datos de Cassandra (si está instalada de forma local o persistente)
Si instalaste Cassandra fuera de una VM de Compute Engine creada aquí, sigue los pasos correspondientes para quitar los datos o desinstalar Cassandra.
9. ¡Felicitaciones!
Próximos pasos
- Obtén más información sobre Spanner.
- Obtén más información sobre la interfaz de Cassandra.