
1. 總覽
在本研究室中,您將瞭解現代卷積架構,並運用自身的知識來實作簡單但有效的對話式「squeezenet」這種說法。
本研究室包含有關卷積類神經網路的必要理論說明,也是開發人員學習深度學習的好起點。
本研究室是「Keras on TPU」的第 4 部分這是 Gemini 版 Google Workspace 系列課程之一您可以依照下列順序執行這些操作,也可以獨立執行。
- TPU 速度資料管道:tf.data.Dataset 和 TFRecords
- 您的第一個 Keras 模型,具備遷移學習功能
- 搭配 Keras 和 TPU 使用卷積類神經網路
- [THIS LAB] 採用 Keras 和 TPU 的新型 convnets、squeezenet 和 Xception 模型

課程內容
- 掌握 Keras 功能樣式
- 為了使用擠檸檬架構建構模型
- 使用 TPU,以便快速訓練並疊代架構
- 如何使用 tf.data.dataset 實作資料擴增功能
- 為 TPU 微調預先訓練的大型模型 (Xception)
意見回饋
如果您在這個程式碼研究室中發現不尋常的狀況,請告訴我們。您可以透過 GitHub 問題提供意見 [feedback link]。
2. Google Colaboratory 快速入門
本研究室使用 Google 協作工具,因此您不需要進行任何設定。Colaboratory 是教育用的線上筆記本平台。提供免費 CPU、GPU 和 TPU 訓練。

您可以開啟這個範例筆記本並執行多個儲存格,熟悉 Colaboratory。
選取 TPU 後端

在 Colab 選單中,依序選取「執行階段」>「執行階段」請變更執行階段類型,然後選取「TPU」。在本程式碼研究室中,您將使用支援硬體加速訓練的強大 TPU (Tensor Processing Unit)。首次執行時,系統會自動連線至執行階段,你也可以使用「連線」選項。
執行筆記本
按一下儲存格並使用 Shift + Enter 鍵,即可逐一執行儲存格。您也可以透過「執行階段 >」全部執行
Table of contents

所有筆記本都有目錄。您可以使用左側的黑色箭頭開啟報表。
隱藏的儲存格

部分儲存格只會顯示標題。這是 Colab 專屬的筆記本功能。您可以按兩下這些程式碼,以查看裡面的程式碼,但不太有趣。通常支援或視覺化函式。您仍需執行這些儲存格,才能定義其中的函式。
驗證

Colab 有機會存取您的私人 Google Cloud Storage 值區,但您必須使用已授權的帳戶進行驗證。上方的程式碼片段會觸發驗證程序。
3. [INFO] 什麼是 Tensor Processing Unit (TPU)?
概述

這段程式碼會在 Keras 的 TPU 上訓練模型 (如果無法使用 TPU,則會改回使用 GPU 或 CPU):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
今天我們會使用 TPU,以互動速度 (每次訓練執行作業的分鐘數) 建構及最佳化花朵分類器。
選用 TPU 的理由
現代的 GPU 是以可程式化的「核心」為基礎,這個架構非常靈活有彈性,可處理 3D 轉譯、深度學習、實體模擬等各種工作。另一方面,TPU 則是將傳統向量處理器與一個專用矩陣相乘單元配對,在所有大型矩陣乘積佔據的主要任務 (例如類神經網路) 的任務上都表現出優異。

插圖:密集的類神經網路層以矩陣乘法運算為矩陣,會一次透過類神經網路處理一批八張圖像,請透過一行 x 資料欄的乘法驗證,確認這確實是圖片中所有像素值的加權總和。卷積層也可以用矩陣乘法表示,雖然情況有些許複雜 ( 請參閱 此處的第 1 節說明)。
硬體
MXU 和 VPU
TPU v2 核心是由矩陣乘積單元 (MXU) 組成,後者會執行矩陣乘法和向量處理器 (VPU),可執行啟動、softmax 等所有其他工作。VPU 會處理 float32 和 int32 運算。另一方面,MXU 會以混合精度 16-32 位元浮點格式運作。

混合精度浮點和 bfloat16
MXU 使用 bfloat16 輸入與 float32 輸出來計算矩陣乘積。中階累計作業是以 float32 精度計算。

類神經網路訓練通常足以應付低浮點精確度所產生的雜訊。在某些情況下,雜訊甚至能協助最佳化工具收縮。通常使用 16 位元浮點精確度來加速運算,但 float16 和 float32 格式有非常不同的範圍。將精確度從 float32 降為 float16,通常會產生過流和反向溢位。現有解決方案存在,但通常需要額外工作才能讓 float16 運作。
這就是 Google 在 TPU 中推出 bfloat16 格式的原因。bfloat16 是截斷的 float32,與 float32 完全相同的指數位元和範圍都一樣。這超出了 TPU 計算矩陣乘法的精度和 bfloat16 輸入內容,但使用 float32 輸出,通常都不需要變更程式碼,就能享有降低精確度的效能。
切割陣列
MXU 使用所謂的「脈搏陣列」在硬體中實作矩陣乘積資料元素流經一系列硬體運算單位的架構。(在醫學中,「脈衝」是指心臟收縮和血流,此處指向資料的流動)。
矩陣乘法的基本元素是介於一個矩陣的線條與另一個矩陣的欄之間的點積 (請參閱本節上方的插圖)。若為矩陣乘法 Y=X*W,則結果一個元素會是:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
在 GPU 上,要將這個內積積木成 GPU 的「核心」然後在「核心」並同時嘗試計算所產生矩陣的每個值。如果產生的矩陣是 128x128 大,就會需要 128x128=16K「核心」只有通常無法使用的功能最大的 GPU 約有 4,000 個核心。另一方面,TPU 在 MXU 中運算單元使用的硬體最低只有 bfloat16 x bfloat16 => float32,只有 bfloat16 x bfloat16 => float32 乘積才會達到此值。這些都太小,TPU 可以在 128x128 MXU 中實作 16K 的容器,並一次處理這個矩陣乘法。
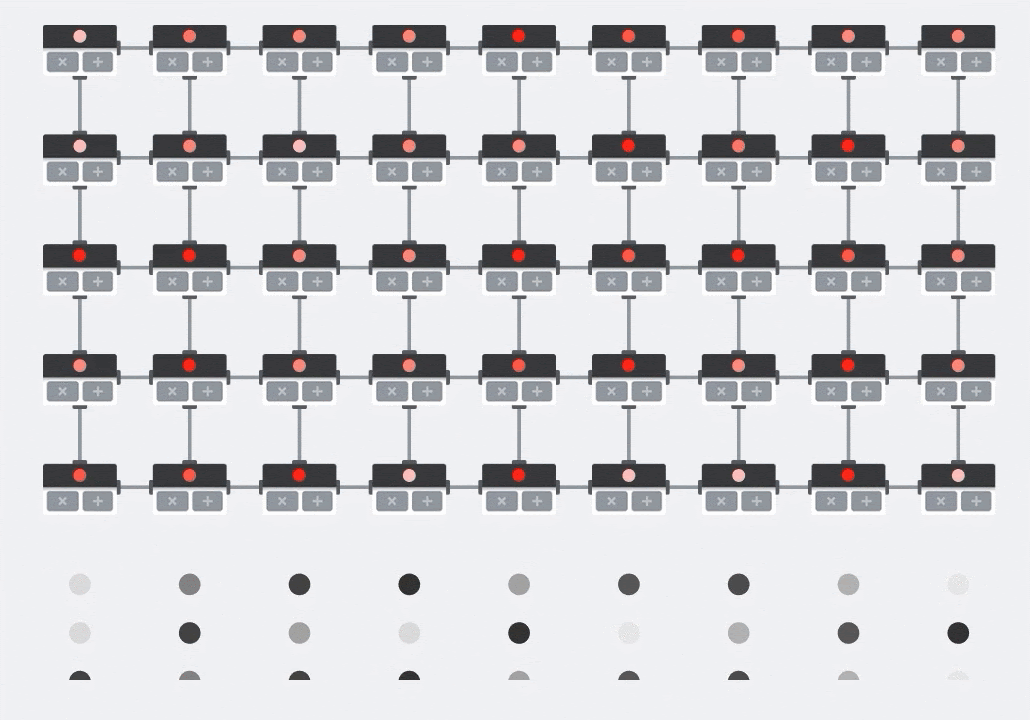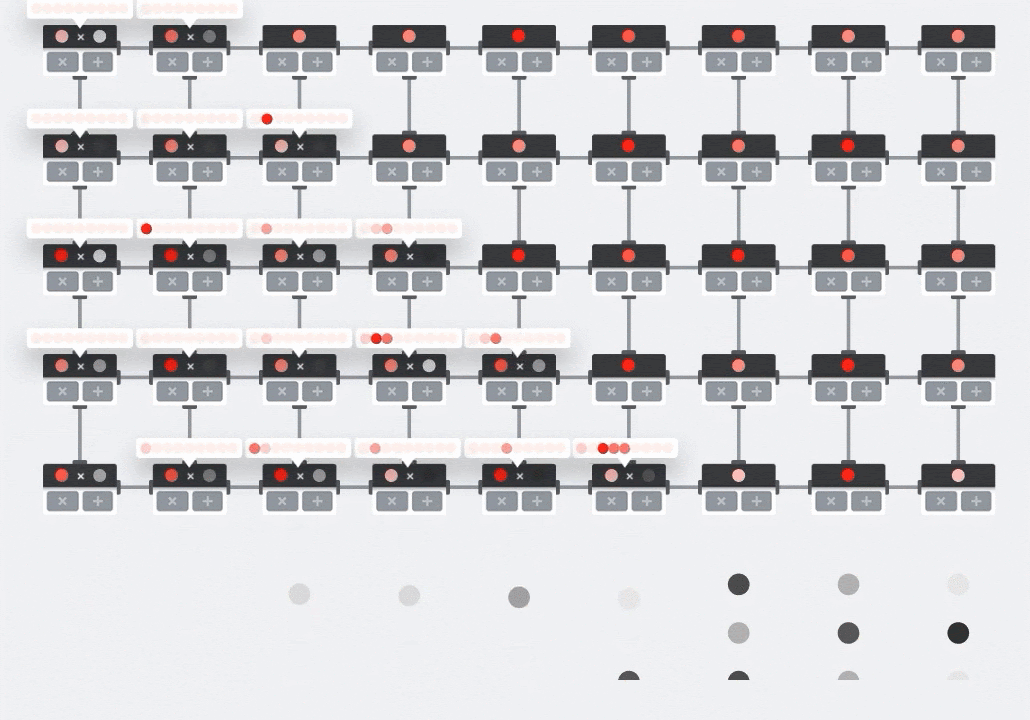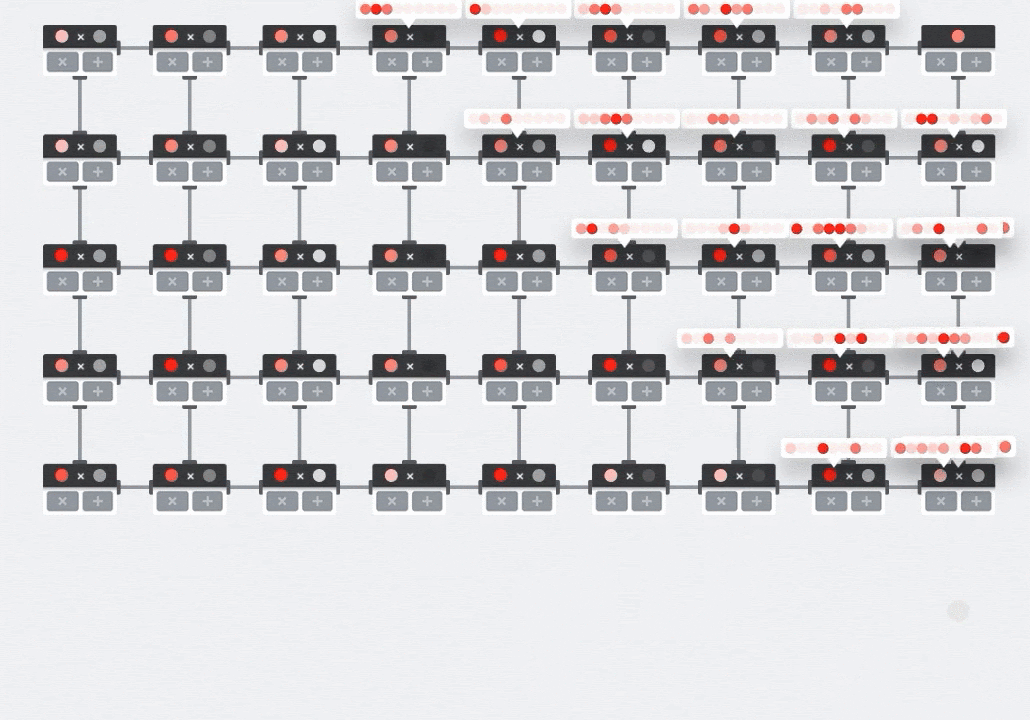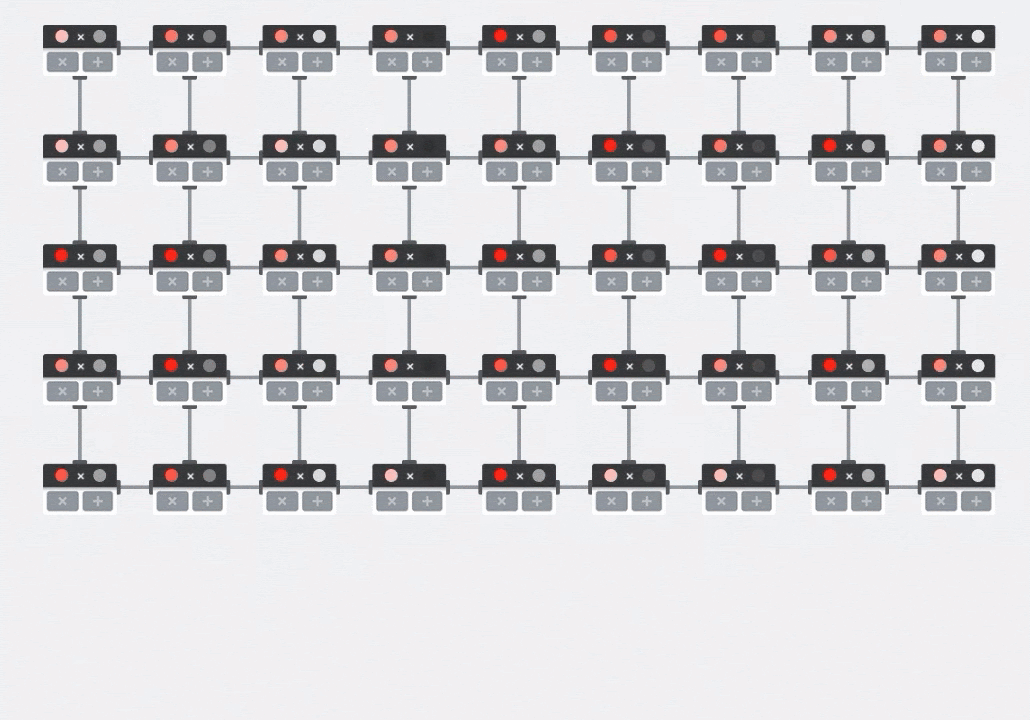
插圖:MXU 收縮壓陣列,運算元素為乘數。其中一個矩陣的值會載入至陣列 (紅點)。其他矩陣的值流經陣列 (灰點)。垂直線會將值向上傳播。水平線會傳播部分總和。這之後是使用者的練習,用來驗證資料通過陣列時,你得到的矩陣乘積結果來自右側。
此外,雖然內積是以 MXU 計算中度積,但在相鄰的運算單元之間,中繼總和其實只會流動。不需要儲存和擷取記憶體,甚至是註冊檔案。最終結果是 TPU 脈動陣列架構在計算矩陣乘法時,具有顯著密度和效能優勢;此外,在計算矩陣乘法時,TPU 的速度優勢也不可忽略。
Cloud TPU
如果您要求一個「Cloud TPU v2使用 Google Cloud Platform 時,您會得到一個具備 PCI 連接 TPU 電路板的虛擬機器 (VM)。TPU 電路板有四個雙核心 TPU 晶片。每個 TPU 核心都有一個 VPU (向量處理器) 和 128x128 MXU (MatriX 乘數)。此「Cloud TPU」接著,通常會透過網路連線至發出該執行個體的 VM整體畫面看起來會像這樣:

插圖:您的 VM 具有附加網路的「Cloud TPU」加速器。「Cloud TPU」這個 VM 本身就是 VM 配上 PCI 連接的 TPU 電路板,上面有四個雙核心 TPU 晶片。
TPU Pod
在 Google 的資料中心,TPU 會連線至高效能運算 (HPC) 互連網路,因此看起來就像一個極大的加速器。Google 會呼叫 Pod,且最多可包含 512 個 TPU v2 核心或 2048 個 TPU v3 核心。

插圖:TPU v3 Pod。透過 HPC 互連網路連線的 TPU 主機板和機架。
在訓練期間,系統會使用 all-reduce 演算法,在 TPU 核心之間交換梯度 ( 這是所有原因的詳細說明)。受訓練的模型可利用大型批量進行訓練,以充分運用硬體。

圖解:在 Google TPU 的 2-D 環面網狀 HPC 網路使用 all-red 演算法,在訓練期間同步處理梯度。
軟體
大型批量訓練
TPU 的理想批次大小為每個 TPU 核心 128 個資料項目,但硬體已能顯示每個 TPU 核心 8 個資料項目有良好的使用率。請記住,一個 Cloud TPU 有 8 個核心。
在這個程式碼研究室中,我們將使用 Keras API。在 Keras 中,您指定的批次是整個 TPU 的全域批次大小。批次將自動分割為 8 個,並在 TPU 的 8 核心上執行。

如需其他效能提示,請參閱 TPU 效能指南。如果是非常大型的批量,某些模型可能需要特別留意,詳情請參閱 LARSOptimizer。
後製:XLA
TensorFlow 程式會定義運算圖形。TPU 不會直接執行 Python 程式碼,而是執行 Tensorflow 程式定義的運算圖形。理論上,名為 XLA 的編譯器 (加速線性代數編譯器) 會將運算節點的 Tensorflow 圖形轉換為 TPU 機器程式碼。這個編譯器也會對程式碼和記憶體配置執行許多進階最佳化。系統會在工作傳送至 TPU 時自動編譯。您不需要在建構鏈結中明確加入 XLA。
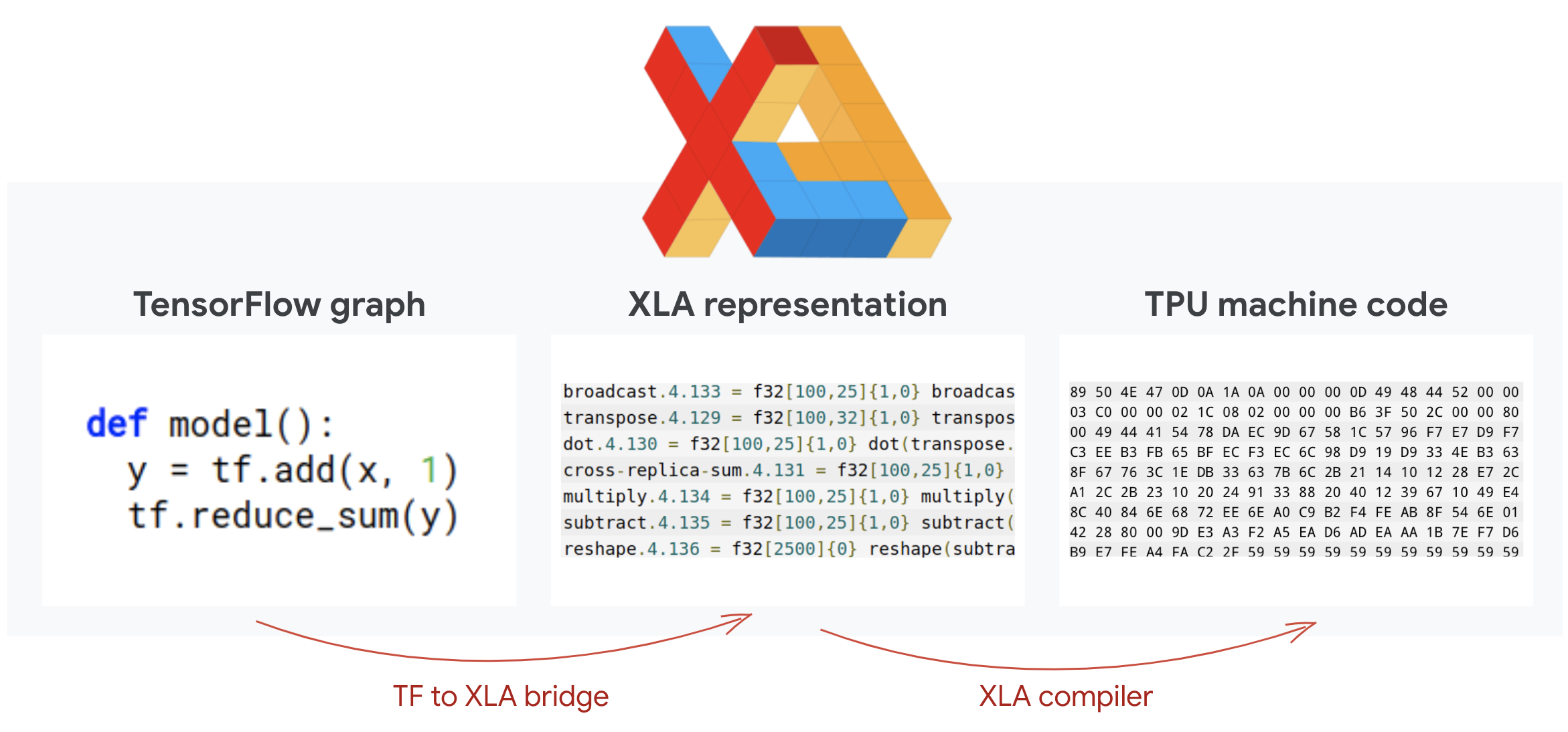
插圖:如要在 TPU 上執行,Tensorflow 程式定義的運算圖形會先轉譯為 XLA (加速線性代數編譯器) 表示法,再由 XLA 編譯成 TPU 機器碼。
在 Keras 中使用 TPU
自 Tensorflow 2.1 起,可透過 Keras API 支援 TPU。Keras 支援適用於 TPU 和 TPU Pod。以下是適用於 TPU、GPU 和 CPU 的範例:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
在這個程式碼片段中:
TPUClusterResolver().connect()會在網路中找到 TPU。這項服務可以在大多數 Google Cloud 系統 (AI 平台工作、Colaboratory、Kubeflow、透過「ctpu up」公用程式建立的深度學習 VM) 中運作,完全不需要參數。這些系統知道 TPU_NAME 環境變數的 TPU 位置。如要手動建立 TPU,請設定 TPU_NAME 環境。var 的變數數量。並在所用 VM 上執行,或是使用明確參數呼叫TPUClusterResolver:TPUClusterResolver(tp_uname, zone, project)TPUStrategy是實作發行方式的部分,並用「all-reduce」梯度同步處理演算法- 系統是透過範圍套用策略。模型必須在策略 scope() 內定義。
tpu_model.fit函式預期輸入用於 TPU 訓練的 tf.data.Dataset 物件。
常見 TPU 移植工作
- 在 TensorFlow 模型中載入資料的方法很多,但如果是 TPU,則必須使用
tf.data.DatasetAPI。 - TPU 速度飛快,且執行時擷取資料經常成為瓶頸。請參閱 TPU 效能指南,瞭解您可以使用哪些工具偵測資料瓶頸和其他效能提示。
- 系統會將 int8 或 int16 號碼視為 int32。TPU 不提供小於 32 位元的整數硬體運作。
- 不支援部分 Tensorflow 作業。查看清單。好消息是,這項限制僅適用於訓練程式碼,也就是前後通過模型的程式碼。您仍可在資料輸入管道中使用所有 TensorFlow 作業,因為 TensorFlow 將在 CPU 上執行。
- TPU 不支援
tf.py_func。
4. [資訊] 類神經網路分類器 101
概述
如果您知道下個段落中的所有以粗體顯示的字詞,則可進行下一個練習。如果您剛開始學習深度學習,歡迎繼續閱讀。
如果是以多層圖層建構的模型,Keras 便提供 Sequential API。舉例來說,使用三個稠密層的圖片分類器,可在 Keras 中編寫如下:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
稠密類神經網路
這是將圖片分類最簡單的類神經網路。由「神經元」組成的分層結構第一層會處理輸入資料,並將輸出內容提供給其他層。這稱為「密集」每個神經元都會連結至上一層的所有神經元

您可以將圖片全部的 RGB 值壓平成長向量,並將其做為輸入內容,提供給此類網路使用。這不是圖片辨識的最佳技術,但我們稍後會加以改進。
Neuron、啟動、RELU
「神經元」計算所有輸入內容的加權總和,然後加上名為「偏誤」的值並透過名為「啟用函式」將結果傳送給我們一開始不知道權重和偏誤。模擬程序將隨機進行,「學習」,運用大量已知資料訓練類神經網路
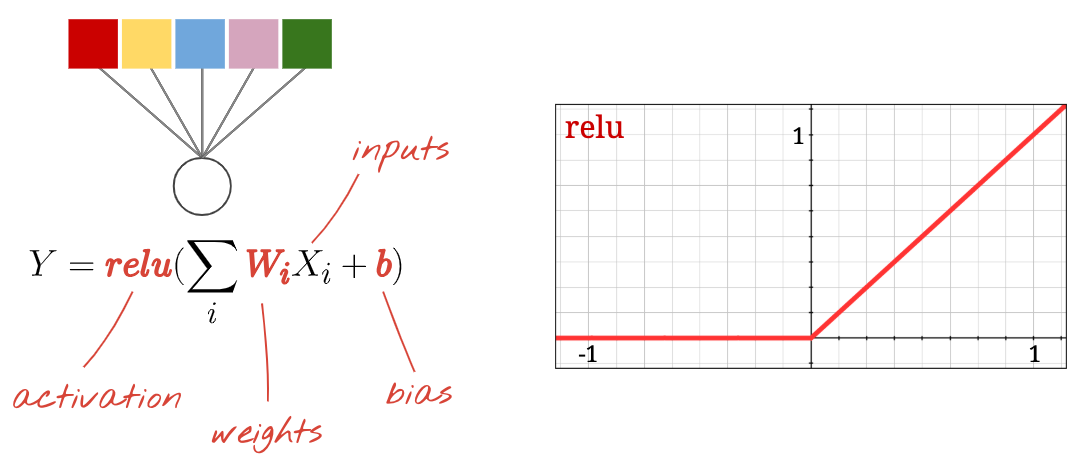
最常見的活化函數稱為 RELU,用於直線式線性單位。如上圖所示,這是非常簡單的函式。
啟用 Softmax
由於我們將花分為 5 種類別 (玫瑰、鬱金香、蒲公英、雛菊、向日葵),上方的網路以 5 個神經元層為結尾。而中間層中的神經元是透過傳統版 RELU 活化函式啟用。但在上一層中,我們想要計算 0 到 1 之間的數字,代表這朵花成為玫瑰、鬱金香等的可能性。我們會使用名為「softmax」的活化函式。
在向量上套用 softmax 時,系統會採用每個元素的指數,然後對向量進行正規化,一般會使用 L1 常式 (絕對值總和),讓各個值加總為 1,並解讀為機率。
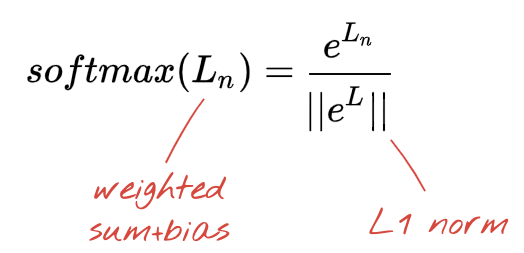

交叉熵損失
現在類神經網路根據輸入的圖片產生預測結果,因此需要測量圖片的品質,也就是網路提供給我們與正確答案之間的距離 (通常稱為「標籤」)。請記住,資料集中的所有圖片都有正確的標籤。
任何距離都可行,但就分類問題而言,我們稱為「交叉熵距離」是最有效的做法。我們將此錯誤稱為「損失」函式:
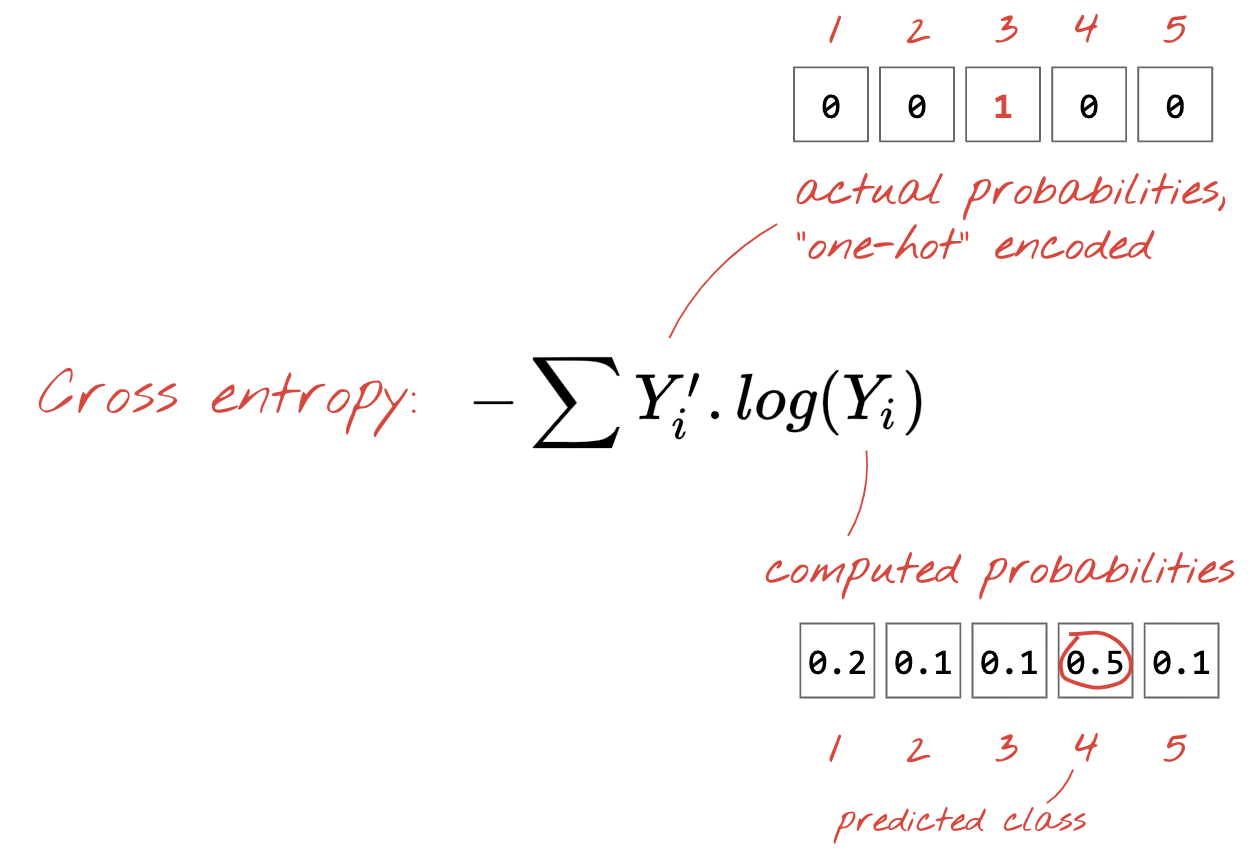
漸層下降
「訓練」類神經網路實際上是指使用訓練圖片和標籤來調整權重和偏誤,藉此盡量減少交叉熵損失函式。運作方式如下:
交叉熵是指權重、偏誤、訓練圖片像素及其已知類別的功能。
如果我們針對所有權重和所有偏誤,計算出交叉熵的部分導數,就會取得「梯度」,根據指定圖片、標籤以及權重和偏誤的現值計算。請記住,我們可以擁有數百萬個權重和偏誤,因此計算梯度聽起來好像是許多工作。幸好,Tensorflow 幫我們辦到。漸層的數學特性是指向「上方」。由於我們要前往十字區的低點,所以方向是相反的。我們會更新部分漸層的權重和偏誤。接著,我們會在訓練迴圈中使用下一批的訓練圖片和標籤,再次執行相同的操作。希望這個例子能創造出交叉熵,但不保證這個下限不會重複。
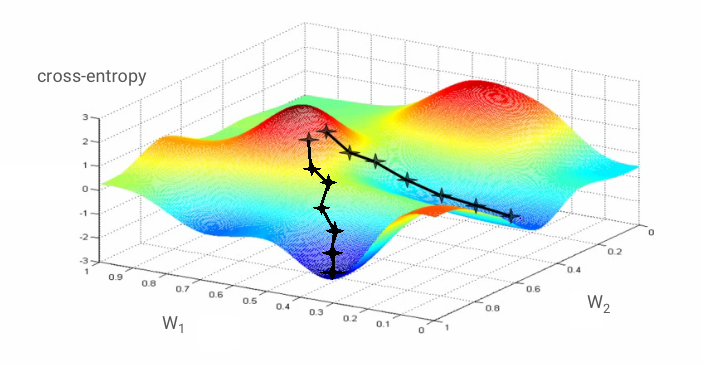
微批次和發展動能
您可以只用一張範例圖片計算漸層,並立即更新權重和偏誤,但以批次方式進行,例如,128 張圖片能夠產生較理想的漸層,更能充分代表不同範例圖片所施加的限制,因此可能更快地聚集在解決方案中。迷你批次的大小是可調整的參數,
這項技巧有時也稱為「隨機梯度下降」還有另一項更實用的優點:處理批次也意味著處理更大型的矩陣,且這些運算通常較容易在 GPU 和 TPU 上最佳化。
然而,收斂法還是有點混亂,而且即使漸層向量全為零,甚至會停止。這代表我們已經找到最低限度了?不一定。漸層元件可以是最小值或最大值。如果某個漸層向量有數百萬個元素,但全都是零,則每個零對應最小,且都不對應到最大點的機率極小。而且在許多維度的空間中很常見,我們不想停下來。
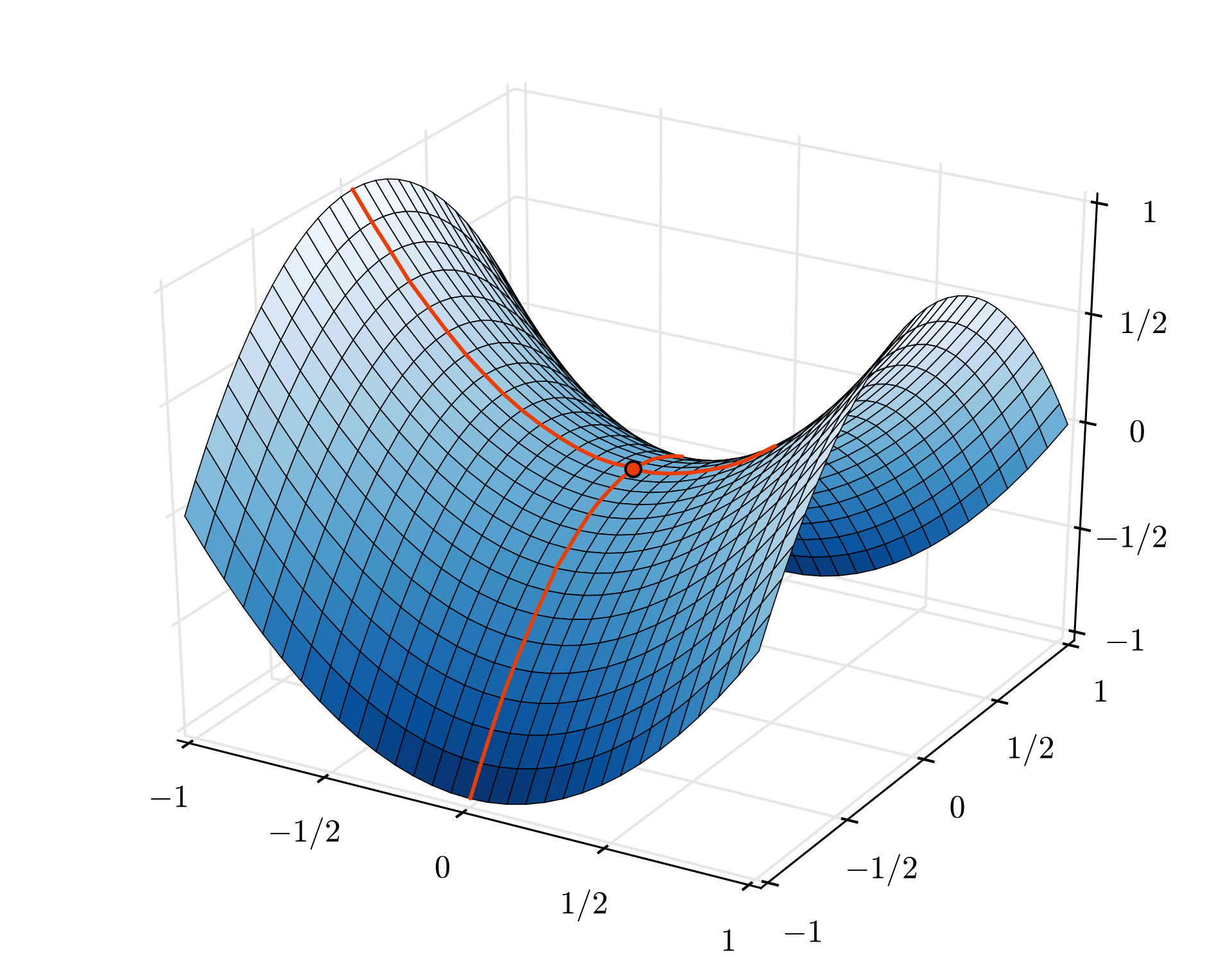
插圖:馬鞍縫。漸層為 0,但並非在所有方向的最小值。(圖片出處 Wikimedia: by Nicoguaro - Own Work, CC BY 3.0)
解決方法是為最佳化演算法增加成長動能,讓演算法能在不停歇的加速點前進。
詞彙
batch 或 mini-batch:一律對訓練資料和標籤進行訓練。這有助於演算法收斂。「批次」通常是資料張量的第一個維度。舉例來說,[100, 192, 192, 3] 的張量包含 100 張 192x192 像素和三個值 (RGB) 的 100 張圖片。
交叉熵損失:分類器中經常使用的特殊損失函式。
稠密層:神經元層,每個神經元都會連接至上一層的所有神經元。
features (特徵):類神經網路的輸入內容有時也稱為「特徵」。要準確判斷資料集的哪些部分 (或零件組合) 並提供給類神經網路以獲得準確的預測結果,就稱為「特徵工程」。
labels:「類別」的另一個名稱或是更正監督式分類問題的答案
學習率:在訓練迴圈的每個疊代中更新權重和偏誤的梯度比例。
logits:套用活化函式前一層神經元層的輸出內容稱為「logits」。字詞取自「邏輯函式」a.k.a.「sigmoid 函式」這個模型過去是最常使用的活化函數,「Logistic 函式前方的遠端輸出」已縮短為「logits」。
loss:比較類神經網路輸出內容與正確答案的錯誤函式
neuron:計算輸入內容的加權總和、加上偏誤,並透過活化函式提供結果。
one-hot 編碼:類別 3 之 3 會編碼為 5 個元素的向量,除了第三個 1 之外,其他所有零。
relu:固定線性單元。神經元經常使用的活化函數。
sigmoid:過去廣受歡迎的活化函數,在特殊情況下仍可派上用場。
softmax:一種特殊的活化函數,用於向量、增加最大元件與所有其他元件之間的差異,並將向量正規化為 1 的總和,讓該向量被解為機率向量。做為分類器中的最後一個步驟。
tensor:Tensor就像矩陣,不過可以任意數量的維度1 維張量是一種向量。2 維度張量就是矩陣。接著,就能使用有 3、4、5 或更多維度的張量。
5. [資訊] 卷積類神經網路
概述
如果您知道下個段落中的所有以粗體顯示的字詞,則可進行下一個練習。如果您剛開始使用卷積類神經網路,請繼續閱讀下文。
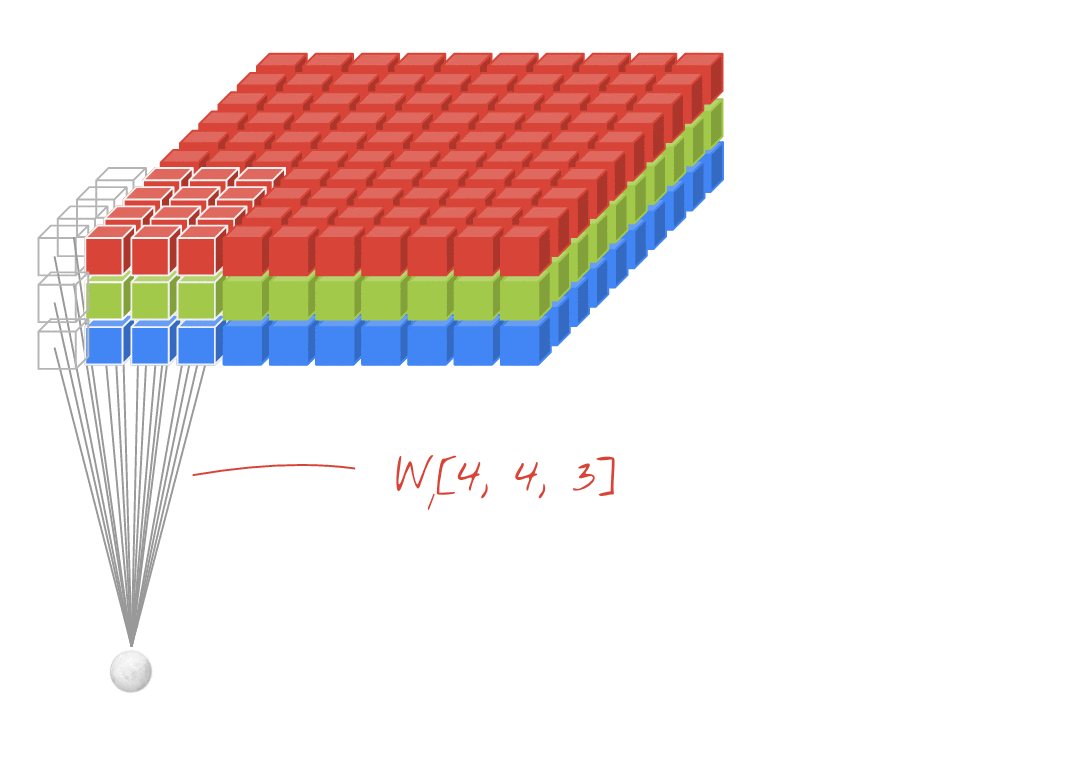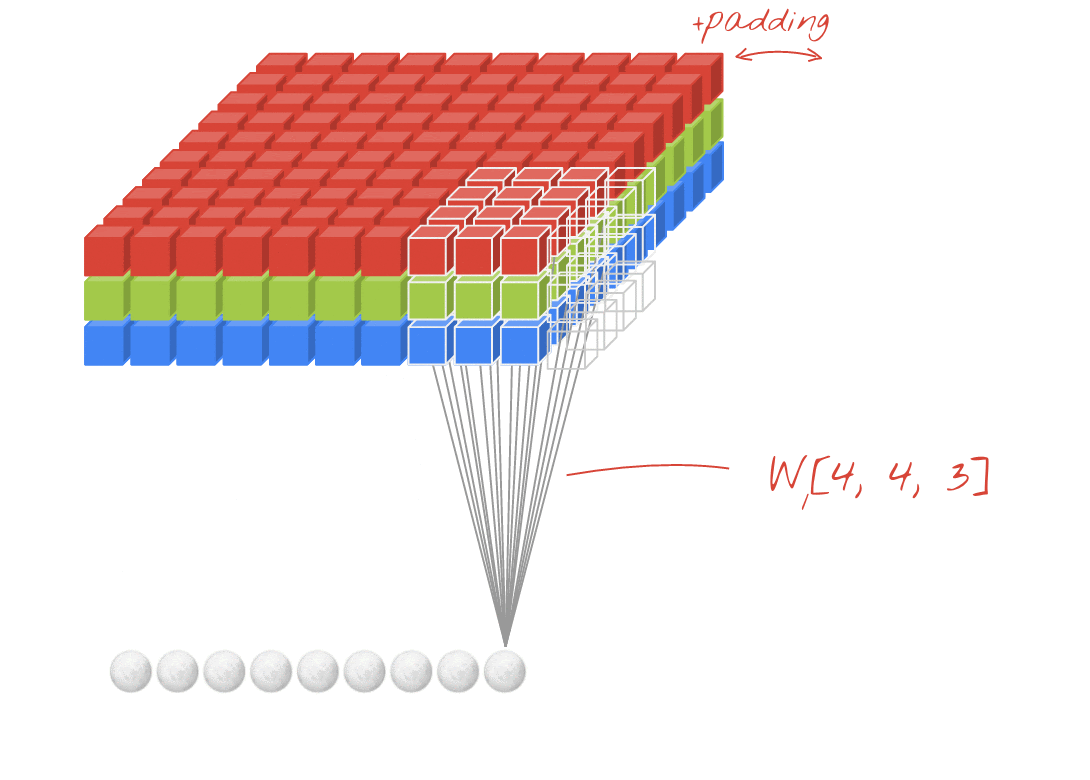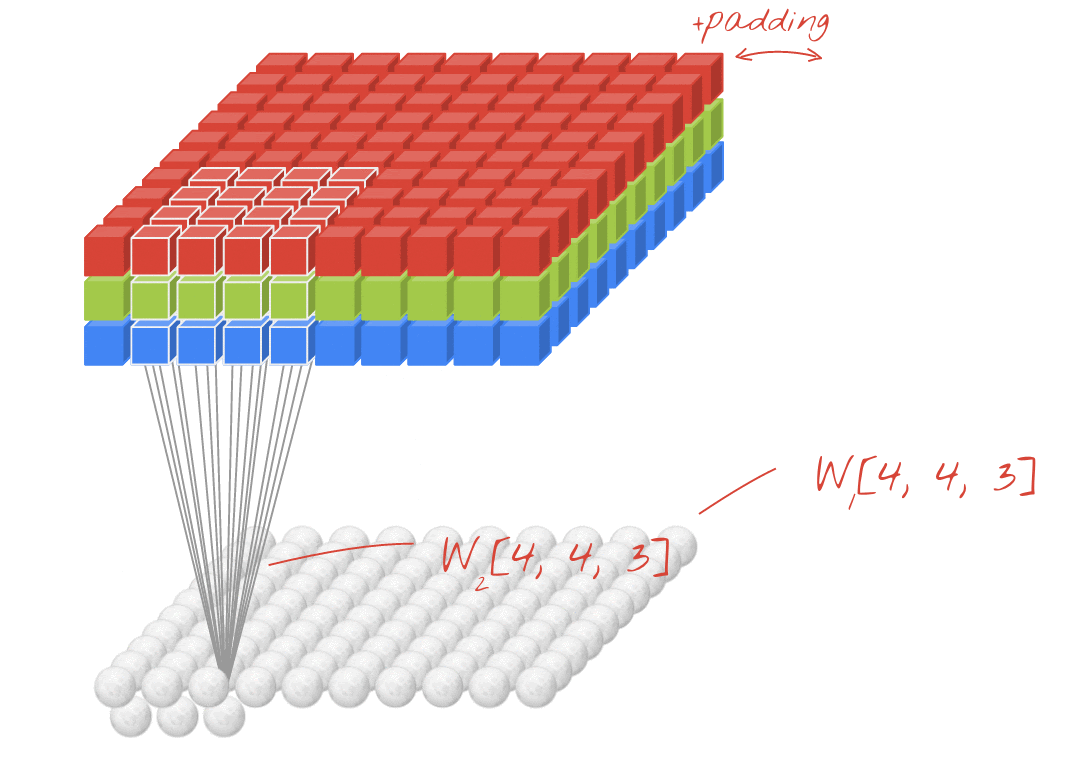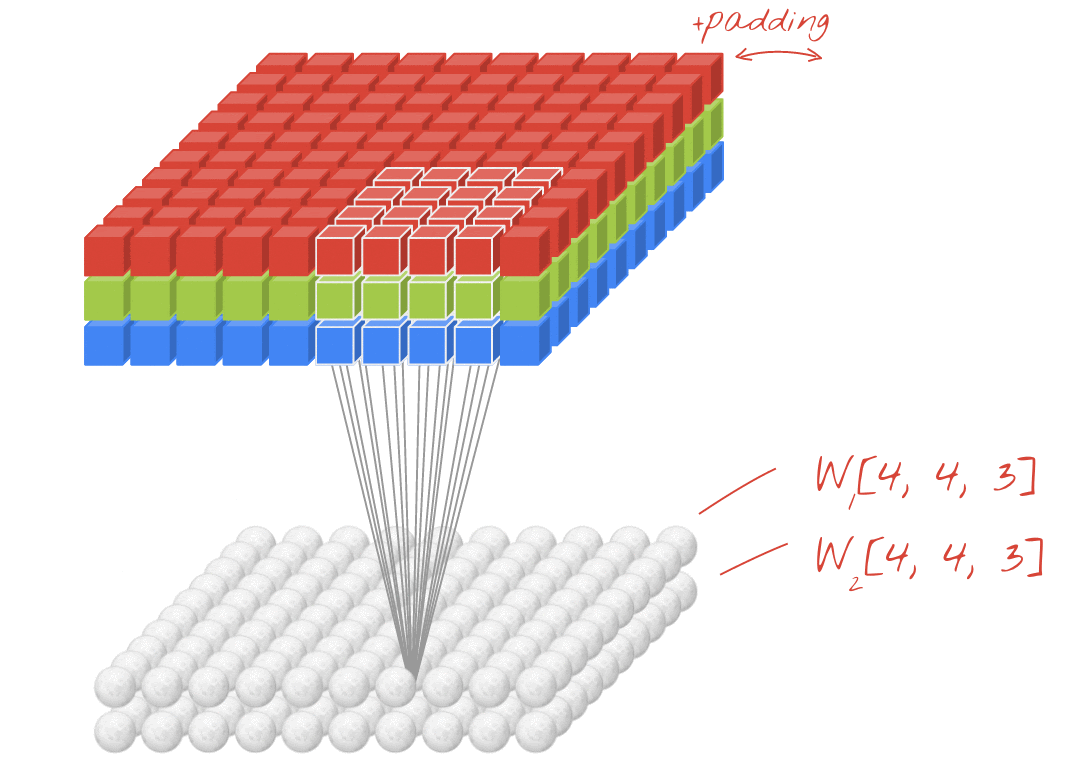
插圖:篩選圖片,以及兩個由 4x4x3=48 可學習權重組成的兩個連續濾鏡。
以下是簡易卷積類神經網路在 Keras 中的模樣:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
卷積神經網路基本知識
在卷積網路層中,一個「神經元」計算圖片上方小區域的像素加權總和。它會增加偏誤並透過活化函數提供總和,就像一般密集層中的神經元一樣。接著,系統會為整張圖片,以相同的權重重複執行這項作業。請記住,在稠密層中,每個神經元都有各自的權重。在這個例子中,的權重滑過圖片中左右兩側 (「卷積」)。輸出內容的值與圖片中的像素數量一樣多 (但邊緣需要一些邊框間距)。本身是篩選作業,使用 4x4x3=48 權重的篩選器。
但是 48 個權重是不夠的。為了增加更多的自由度,我們以一組新的權重重複同一項作業。這會產生一組新的篩選器輸出內容。命名為「channel」輸出圖片中的 R、G、B 管道表示輸出內容。
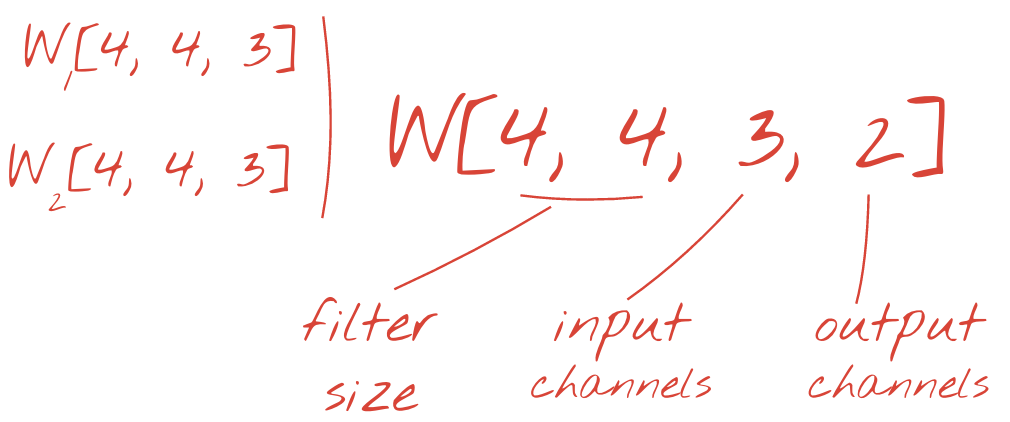
透過新增維度,即可將兩組或更多的權重加總為一個張量。這就是卷積層的權重張量的一般形狀。由於輸入和輸出通道的數量是參數,因此我們可以開始堆疊及鏈結卷積層。
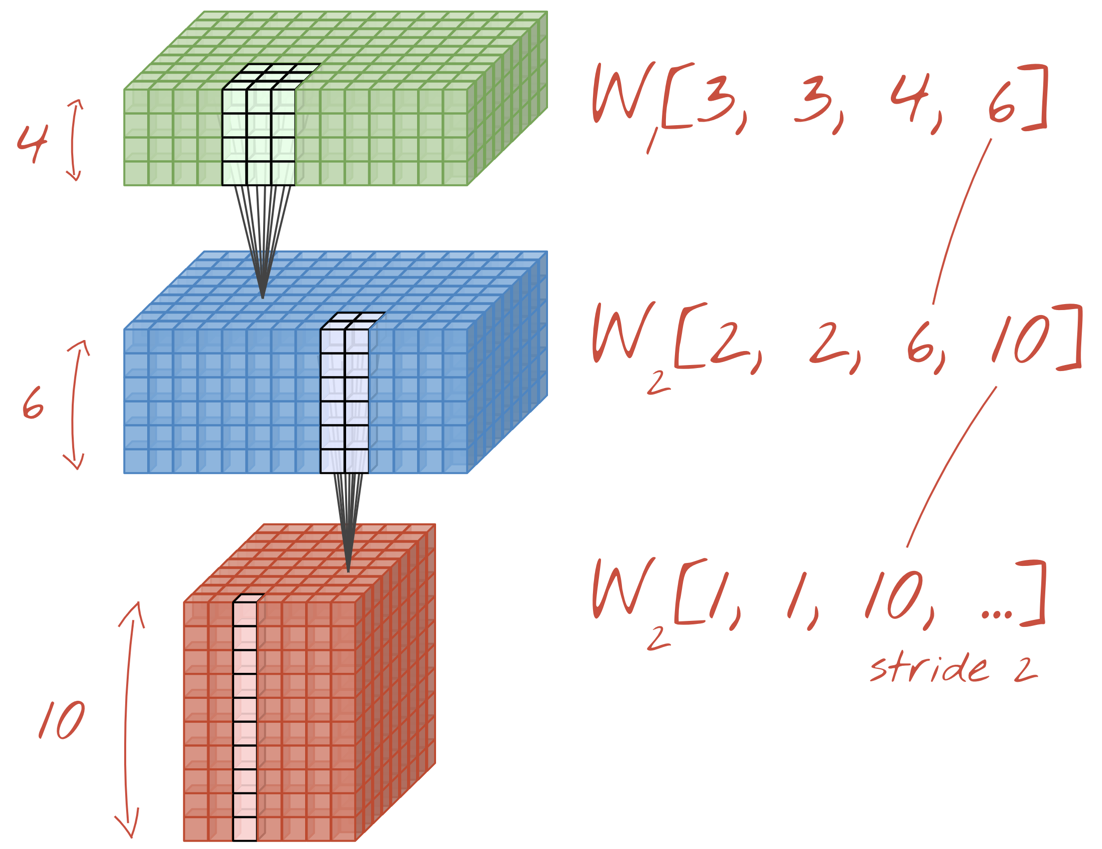
插圖:卷積類神經網路改變了「方塊」將資料匯出至其他「立方體」資料安全
碰撞卷積,最大集區
透過 2 或 3 序列執行卷積,我們也可縮小產生的資料方塊水平維度。有兩種常見方式:
- 網格卷積:相同滑步濾鏡,但步長大於 1
- 最大集區:套用 MAX 運算的滑動窗口 (通常在 2x2 修補程式中,每 2 個像素重複一次)

插圖:將運算視窗滑動 3 像素,輸出值就會較少。傾斜的捲積或最大集區 (最長可滑動 2 點的 2x2 視窗範圍) 可縮小水平維度的資料方塊。
卷積分類器
最後,我們會簡化最後一個資料立方體,並透過稠密的 softmax-activated 層提供資料,以附加分類頭。卷積分類器通常如下所示:

插圖:使用卷積層和 softmax 層的圖片分類器,並使用 3x3 和 1x1 篩選器。maxpool 圖層最多只能使用 2x2 個資料點的群組。分類頭以啟用 softmax 的稠密層。
在 Keras 中
上方圖中的捲積堆疊可在 Keras 中編寫,如下所示:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
6. [新資訊] 現代卷積架構
概述

插圖:卷積「模組」。目前哪一邊最適合?最大集區層後面接著 1x1 卷積層還是不同層的組合?請試用所有指令、串連結果,讓聯播網決定。右側是inception"運用這類模組的捲積架構。
在 Keras 中,如要建立可供資料流入/分出的模型,您必須使用「函式」模型樣式範例如下:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
其他超值秘訣
小 3 x 3 濾鏡

在這張插圖中,您會看到兩個連續 3x3 濾鏡的結果。試著追溯造成結果的資料點:這兩個連續的 3x3 篩選器會計算出一個 5x5 區域的任意組合。這與 5x5 濾波器會計算的組合並不完全相同,但值得嘗試,因為兩個連續 3x3 篩選器的費用比一個 5x5 篩選器便宜。
1x1 卷積?

在數學術語中,「1x1」卷積是常數的乘法,不是非常實用的概念。不過在卷積類神經網路中,篩選器會套用至資料立方體,而非只有 2D 圖片。因此「1x1」篩選器會計算 1x1 資料欄的加權總和 (請見圖解),當您在資料之間滑動時,會得到輸入管道的線性組合。這其實很有用。舉例來說,如果將管道視為個別篩選作業的結果,例如使用「pointy ears」的篩選器,就會比較「Whiskers」第三則代表「亮眼」接著是「1x1」卷積層會計算這些特徵的多個可能線性組合,您在尋找「貓」時相當實用。除此之外,1x1 層使用的權重更少。
7. 擠檸檬
「Squeezenet」紙。作者提出非常簡單的捲積模組設計建議,僅使用 1x1 和 3x3 卷積層。

插圖:以「火災模組」為基礎的擠檸檬架構。他們交錯 1x1 層,「擠壓」垂直維度傳入的資料,後面接著兩個「展開」的 1x1 和 3x3 卷積層又能降低資料的深度
實作
接著使用先前的筆記本,建立以擠壓網路為靈感的捲積類神經網路。您必須將模型程式碼變更為 Keras「函式樣式」。

Keras_Flowers_TPU (playground).ipynb
其他資訊
這在練習中定義了 squeezenet 模組的輔助函式時很有用:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
這次目標是達到 80% 的準確率。
建議做法
從單一卷積層開始,再透過「fire_modules」交替使用 MaxPooling2D(pool_size=2) 圖層。在網路中,您可以使用 2 至 4 個上限的集區層進行實驗,並且在最大池層之間建立連續 1、2 或 3 個連續的火焰模組。
在火焰模組中,參數通常應小於「展開」參數。這些參數實際上是篩選器的數量。通常介於 8 至 196 之間。您可以嘗試不同的架構,讓篩選器數量透過網路逐漸增加,或者是單純的架構 (所有啟動模組都具有相同數量的篩選器)。
範例如下:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
此時,您可能會發現自己的實驗成效不佳,而 80% 的準確度目標似乎是遠端的。該回答幾個較便宜的小技巧。
批次正規化
批次常態能協助處理遇到的收斂問題。在下一個研討會中,我們會詳細說明這項技巧,但目前請先將其當做黑盒「魔術」使用。將這一行新增至網路中的「每個卷積層」後,包括 Fire_module 函式中的層:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
由於我們的資料集很小,因此 Moumum 參數必須從預設值 0.99 降低為 0.9。暫時不用處理此詳細資料。
資料擴增
您可以使用簡單的轉換 (例如:飽和度變化的左方翻轉) 來擴增資料,藉此增加兩個百分點:


在 Tensorflow 中使用 tf.data.Dataset API 十分簡單。為資料定義新的轉換函式:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
然後用於最終資料轉換 (儲存格「訓練和驗證資料集」的函式「get_batched_dataset」):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
別忘了將資料擴增為選用,並加入必要程式碼,確保只有訓練資料集才會擴增。您不需要擴充驗證資料集。
現在,35 個週期的 80% 準確率應該在觸及範圍內。
解決方案
以下是解決方案筆記本。如果遇到問題,可以使用此功能。
Keras_Flowers_TPU_squeezenet.ipynb
涵蓋內容
- 🤔? Keras 的「功能風格」模型
- 🤓? Squeezenet 架構
- 🤓? 使用 tf.data.datset 擴增資料
請花點時間研讀這份檢查清單,
8. Xception 已微調
可分割卷積
最近,大家越來越常採用卷積層的捲積層,也就是可區分的捲積。我瞭解這個問題,但概念很簡單。這些範例在 Tensorflow 和 Keras 中實作為 tf.keras.layers.SeparableConv2D。
可分化的捲積也會對圖片執行濾鏡,但會針對輸入圖片的每個通道,使用一組不同的權重組合。它採用「1x1 卷積」,也就是一連串的內積類產品,得出篩選後的管道總和。每次都會使用新的權重,因此系統會視需要計算每個管道的加權重新組合。
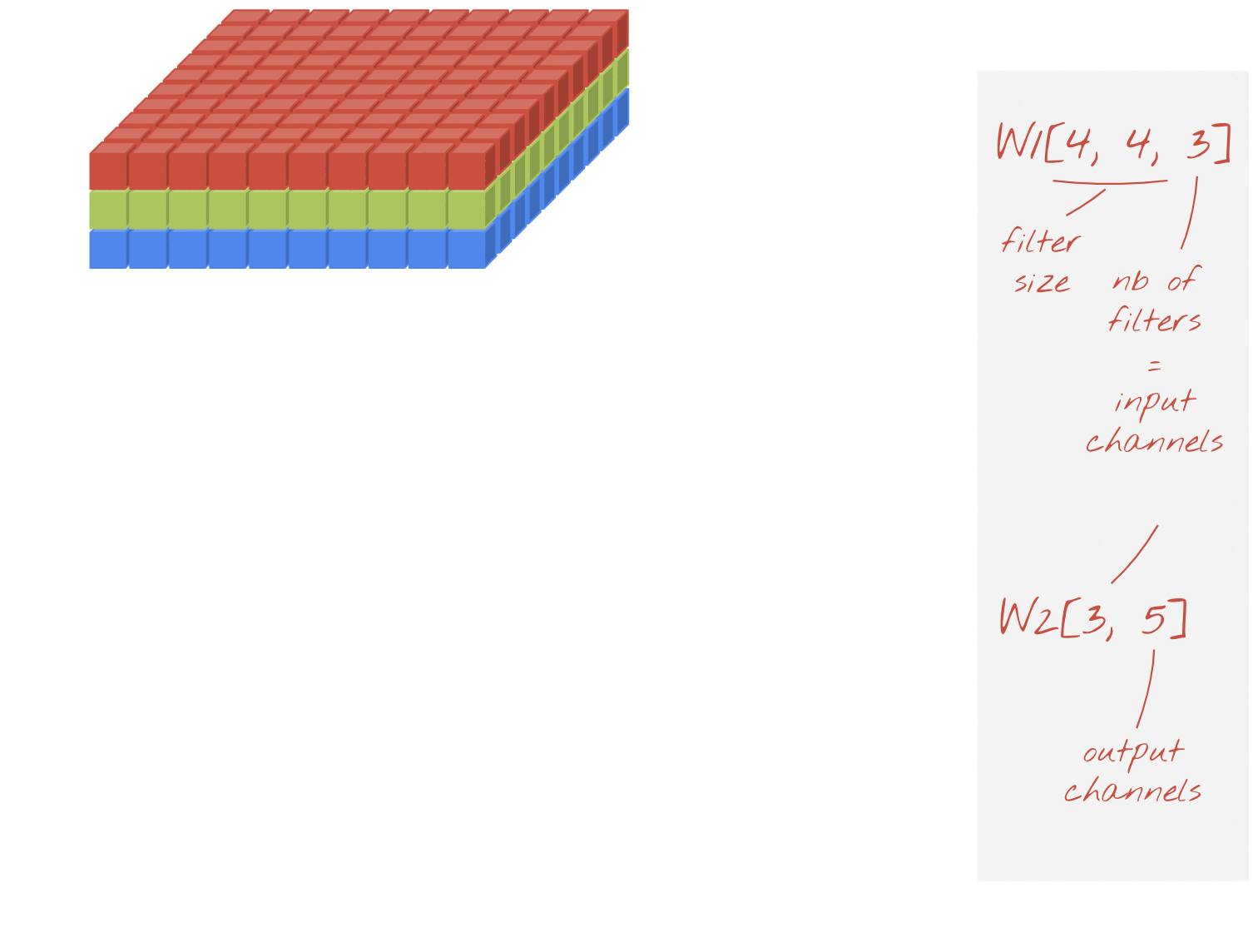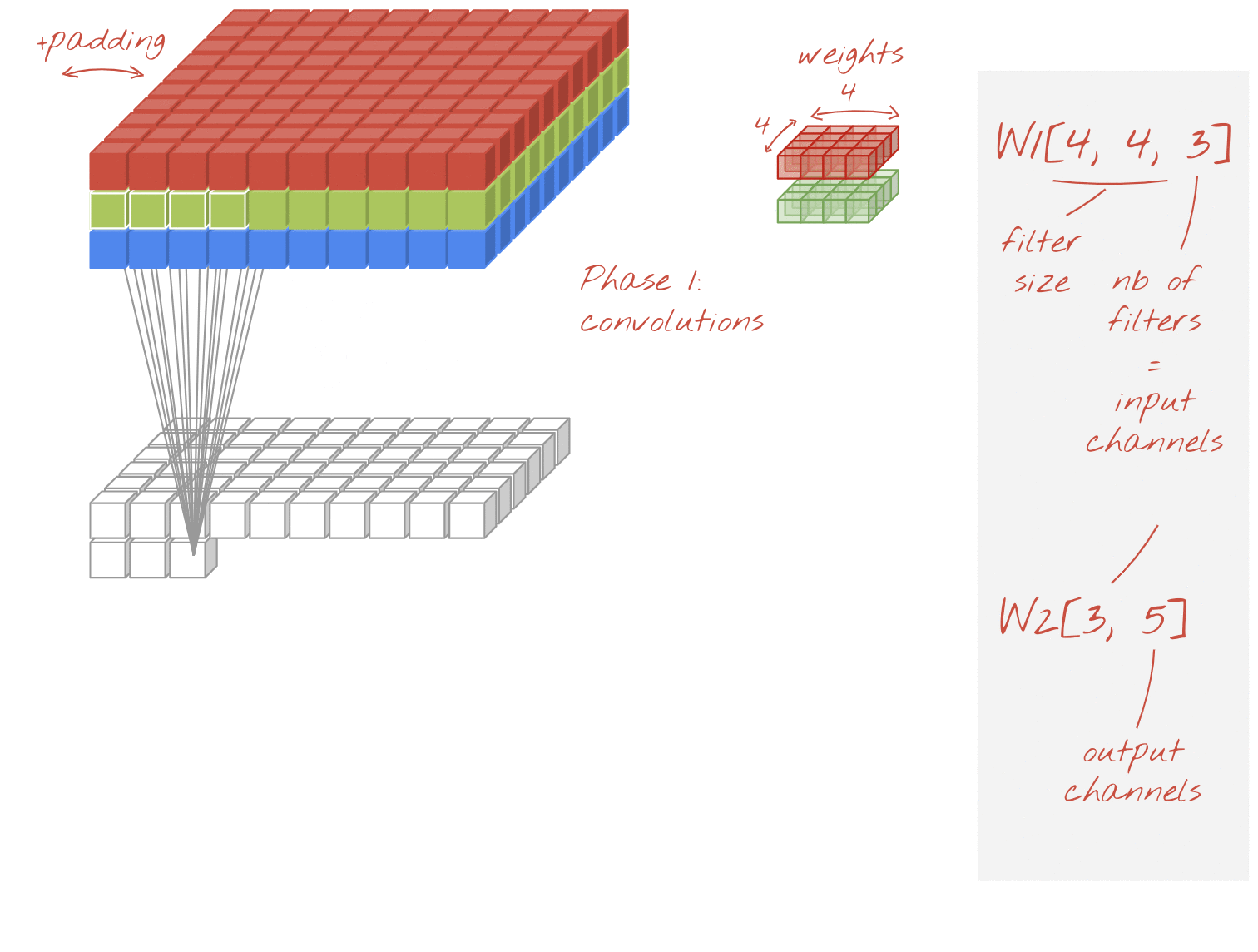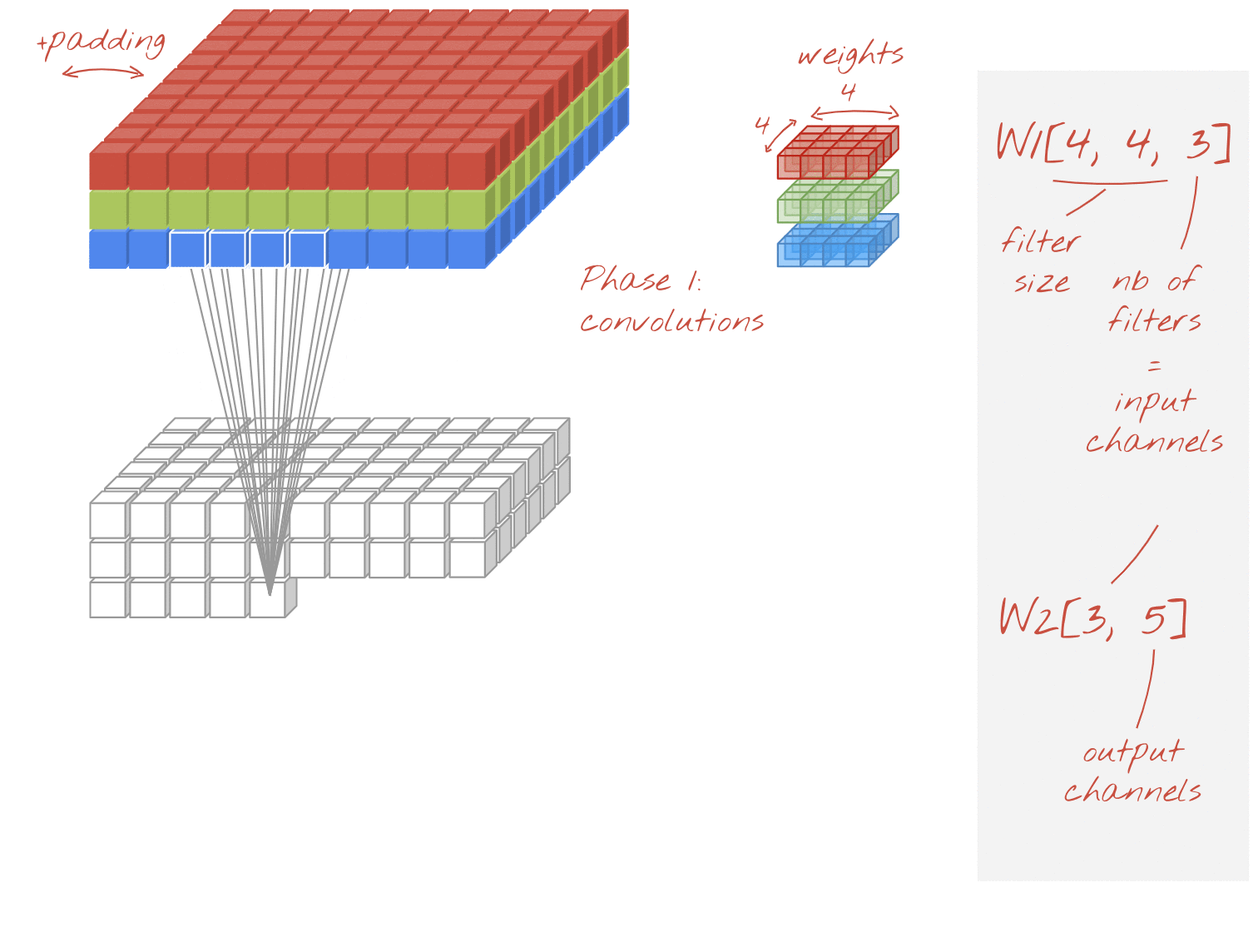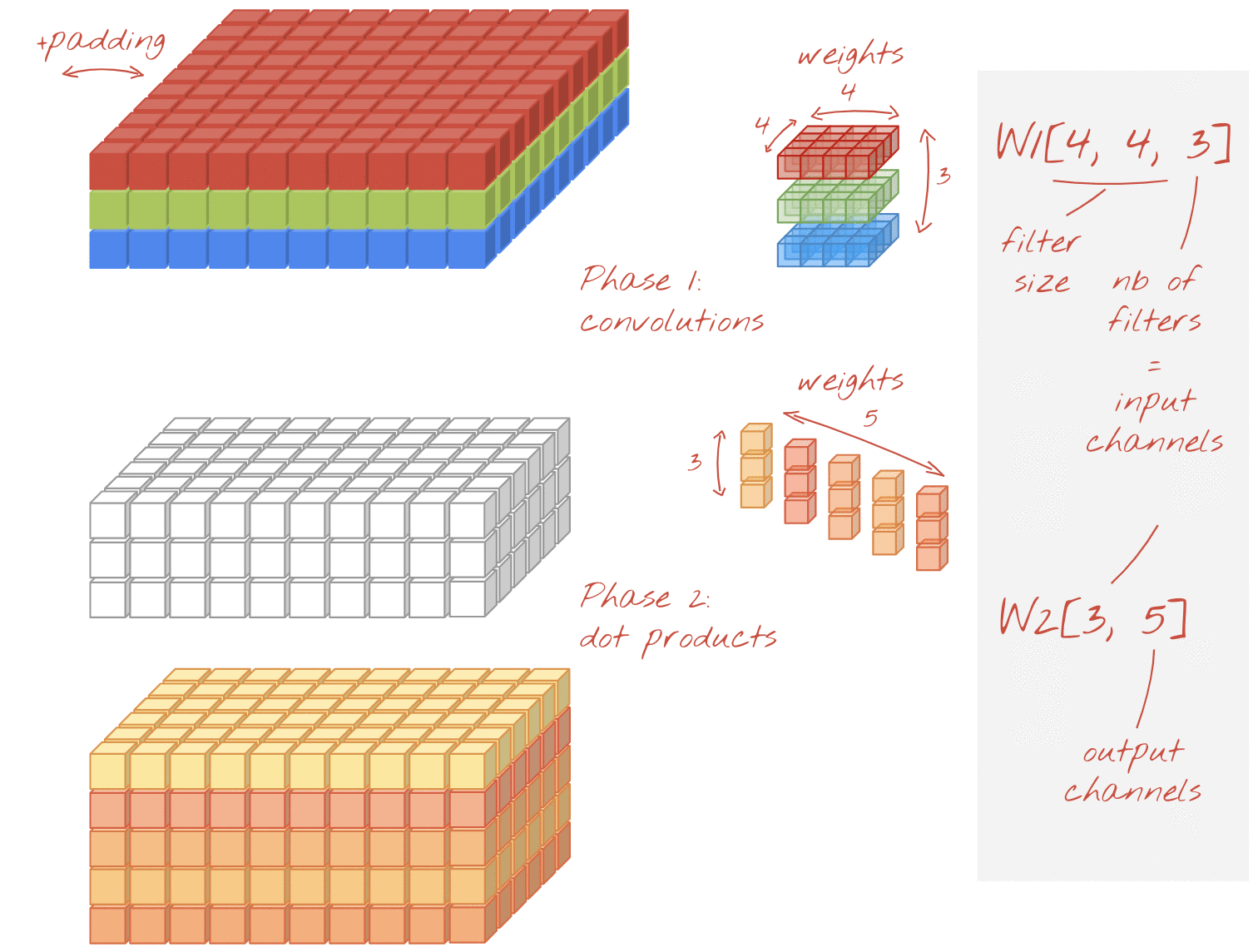
插圖:可分離的捲積,第 1 階段:每個管道都有獨立的篩選器,帶來卷積。第 2 階段:管道的線性重新組合。使用一組新的權重重複,直到達到所需的輸出通道數。第 1 階段也可以重複,每次都會使用新的權重,但實際上很少見。
最新的捲積網路架構 (MobileNetV2、Xception、EfficientNet) 採用可隔離的捲積。順帶一提,「MobileNetV2」是你之前用來遷移學習的工具。
這類模型的捲積成本比一般卷積便宜,且經研究發現同樣有效。以下是上述範例的權重計數:
卷積層:4 x 4 x 3 x 5 = 240
可分隔卷積層:4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
這可以做為練習,讓讀取器計算和套用每個卷積層以類似的方式縮放所需要的乘數多之乘數。可分割的捲積較小,且運算效能更佳。
實作
重新開始「遷移學習」遊樂場筆記本,但這次請選取 Xception 做為預先訓練模型Xception 只使用可分離的捲積。將所有權重設為「可訓練」屬性。我們將微調資料上預先訓練的權重,而非使用預先訓練的層。
Keras Flowers transfer learning (playground).ipynb
目標:準確度 >95% (這不,有可能發生了!)
這是最後的練習,還需要多做一些程式碼和數據資料學工作。
微調作業的其他資訊
tf.keras.application 中的標準預先訓練模型提供 Xception。*別忘了保留所有可訓練的重量。
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
如要在調整模型時取得良好結果,請留意學習率,並搭配適應期採用學習率時間表。如下所示:

從標準學習率開始,會影響模型預先訓練的權重。系統會逐步保留這些保留碼,直到模型分割資料後,能夠以合理方式修改這些內容。提高學習率後,您可以穩定或以指數方式下降的學習率。
在 Keras 中,學習率是透過回呼指定,您可以計算每個訓練週期的適當學習率。Keras 會針對每個訓練週期,將正確的學習率傳遞至最佳化工具。
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
解決方案
以下是解決方案筆記本。如果遇到問題,可以使用此功能。
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
涵蓋內容
- 🤔? 可分離卷積
- 🤓? 學習率時間表
- 😈? 微調預先訓練模型。
請花點時間研讀這份檢查清單,
9. 恭喜!
您已成功建立第一個現代化卷積類神經網路,並將該網路訓練至 90% 以上的準確率。有了 TPU,您就能在幾分鐘內完成連續訓練的疊代作業。以下為 4「Keras on TPU 程式碼研究室」課程總結:
- TPU 速度資料管道:tf.data.Dataset 和 TFRecords
- 您的第一個 Keras 模型,具備遷移學習功能
- 搭配 Keras 和 TPU 使用卷積類神經網路
- [THIS LAB] 採用 Keras 和 TPU 的新型 convnets、squeezenet 和 Xception 模型
TPU 實務
Cloud AI 平台提供 TPU 和 GPU:
最後,我們非常喜歡使用者的意見。如果您在研究室中發現任何錯誤,或認為需要改善,請告訴我們。您可以透過 GitHub 問題提供意見 [feedback link]。

|

