
1. 概览
TPU 的速度非常快。训练数据流必须与其训练速度保持同步。在本实验中,您将学习如何使用 tf.data.Dataset API 从 GCS 加载数据,以便为 TPU 馈送数据。
本实验是“TPU 上的 Keras”的第 1 部分系列视频您可以按以下顺序执行这些操作,也可以单独执行这些操作。
- [本实验] TPU 速度数据流水线:tf.data.Dataset 和 TFRecords
- 您的第一个具有迁移学习功能的 Keras 模型
- 包含 Keras 和 TPU 的卷积神经网络
- 现代卷积神经网络、squeezenet、Xception,以及 Keras 和 TPU

学习内容
- 使用 tf.data.Dataset API 加载训练数据
- 使用 TFRecord 格式从 GCS 高效加载训练数据
反馈
如果您发现此 Codelab 中存在错误,请告诉我们。您可以通过 GitHub 问题 [反馈链接] 提供反馈。
2. Google Colaboratory 快速入门
此实验使用 Google 协作工具,无需您进行任何设置。Colaboratory 是一个用于教学的在线笔记本平台。它提供免费的 CPU、GPU 和 TPU 训练。

您可以打开此示例笔记本并运行几个单元,以熟悉 Colaboratory。
选择 TPU 后端

在 Colab 菜单中,选择运行时 >更改运行时类型,然后选择 TPU。在此 Codelab 中,您将使用一个支持硬件加速训练的强大 TPU(张量处理单元)。首次执行时会自动连接到运行时,您也可以使用“Connect”按钮。
笔记本执行

通过点击单元格并使用 Shift-ENTER 一次执行一个单元格。您还可以使用 Runtime >运行全部
目录

所有笔记本都有一个目录。您可以使用左侧的黑色箭头将其打开。
隐藏单元格

部分单元格将仅显示标题。这是 Colab 特有的笔记本功能。您可以双击它们来查看其中的代码,但通常不是很有趣。通常是支持函数或可视化函数。您仍然需要运行这些单元才能定义其中的函数。
Authentication

如果您使用已获授权的账号进行身份验证,则 Colab 可以访问您不公开的 Google Cloud Storage 存储分区。上面的代码段将触发身份验证过程。
3. [INFO] 什么是张量处理单元 (TPU)?
简述

使用 Keras 在 TPU 上训练模型的代码(如果 TPU 不可用,则回退到 GPU 或 CPU):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
我们今天将使用 TPU 以交互速度(每次训练运行的分钟数)构建和优化花卉分类器。
为什么选择 TPU?
现代 GPU 是围绕可编程“核心”组织的,这是一种非常灵活的架构,可处理各种任务,如 3D 渲染、深度学习、物理模拟等。另一方面,TPU 可将经典矢量处理器与专用矩阵乘法单元配对,并擅长处理大型矩阵乘法占主导的任何任务,例如神经网络。

插图:以矩阵乘法表示的密集神经网络层,通过神经网络同时处理一批 8 张图片。请执行一行 x 列乘法运算,以验证这是否确实对图片的所有像素值进行加权和。卷积层也可以表示为矩阵乘法,尽管它有点复杂( 此处的说明,第 1 部分)。
硬件
MXU 和 VPU
TPU v2 核心由一个矩阵乘法单元 (MXU) 组成,该单元针对所有其他任务(例如激活、softmax 等)运行矩阵乘法和矢量处理单元 (VPU)。VPU 负责处理 float32 和 int32 计算。另一方面,MXU 以混合精度 16-32 位浮点格式运行。

混合精度浮点数和 bfloat16
MXU 使用 bfloat16 输入和 float32 输出计算矩阵乘法。中间累积以 float32 精度执行。

神经网络训练通常能够抵抗因浮点精度降低而引入的噪声。在某些情况下,噪声甚至有助于优化器收敛。16 位浮点精度一直以来都用于加快计算速度,但 float16 和 float32 格式却截然不同。将精度从 float32 降低至 float16,通常会导致上溢和下溢。虽然存在解决方案,但通常需要执行额外的操作才能使 float16 正常运行。
因此,Google 在 TPU 中引入了 bfloat16 格式。bfloat16 是截断的 float32,其指数位和范围与 float32 完全相同。再加上 TPU 会计算与 bfloat16 输入(但 float32 输出)混合精度的矩阵乘法,这意味着通常无需更改代码即可从降低精度的性能提升中受益。
脉冲阵列
MXU 使用所谓的“脉动阵列”在硬件中实现矩阵乘法数据元素流经硬件计算单元数组的架构。(在医学中,“收缩性”是指心脏收缩和血流,这里指的是数据的流动。)
矩阵乘法的基本元素是两个矩阵中的一条直线与另一个矩阵的列之间的点积(请参阅本节顶部的图示)。对于矩阵乘法 Y=X*W,结果中的一个元素将是:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
在 GPU 上,可以将这个点积编程为 GPU“核心”然后在尽可能多的“核心”上执行来尝试同时计算所生成矩阵的每个值。如果生成的矩阵为 128x128 大,则需要 128x128=16000 个“核心”这通常是不可行的最大的 GPU 大约有 4000 个核心。另一方面,TPU 使用 MXU 中的计算单元的最低要求硬件:仅使用 bfloat16 x bfloat16 => float32 个乘积累加器,没有任何其他用途。这些矩阵非常小,因此 TPU 可以在 128x128 MXU 中实现 16K 并一次性处理此矩阵乘法。
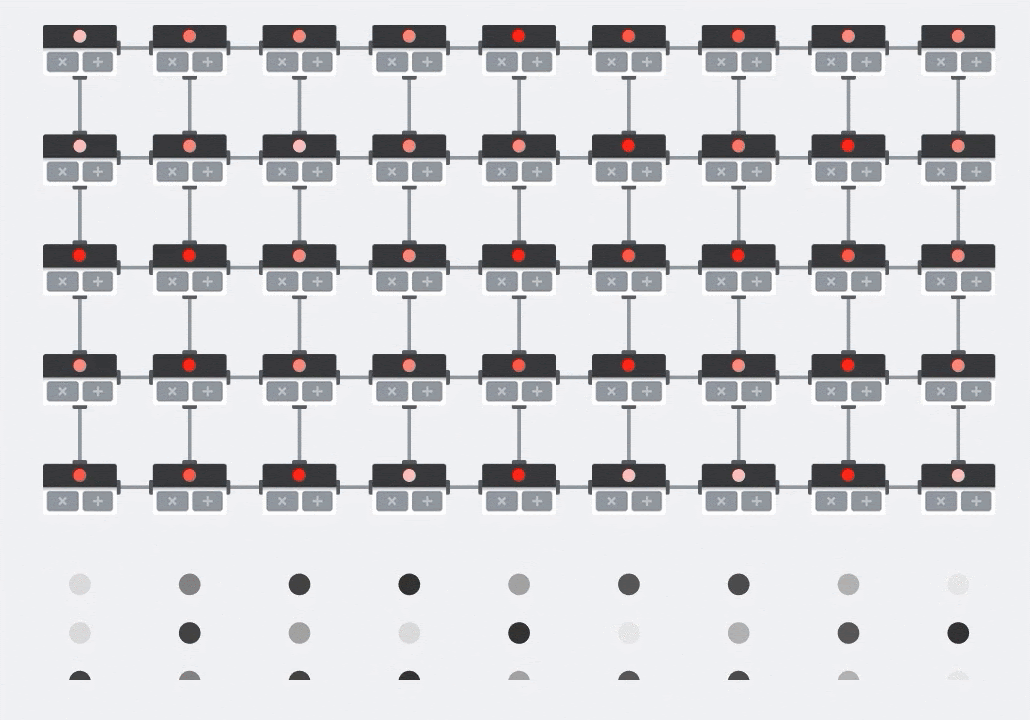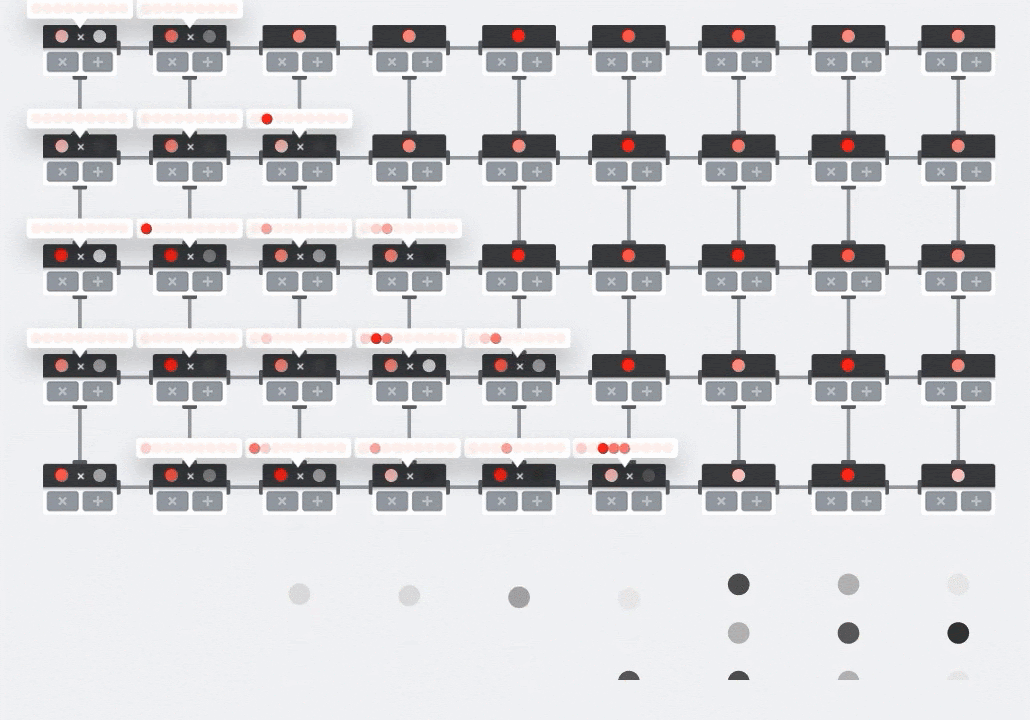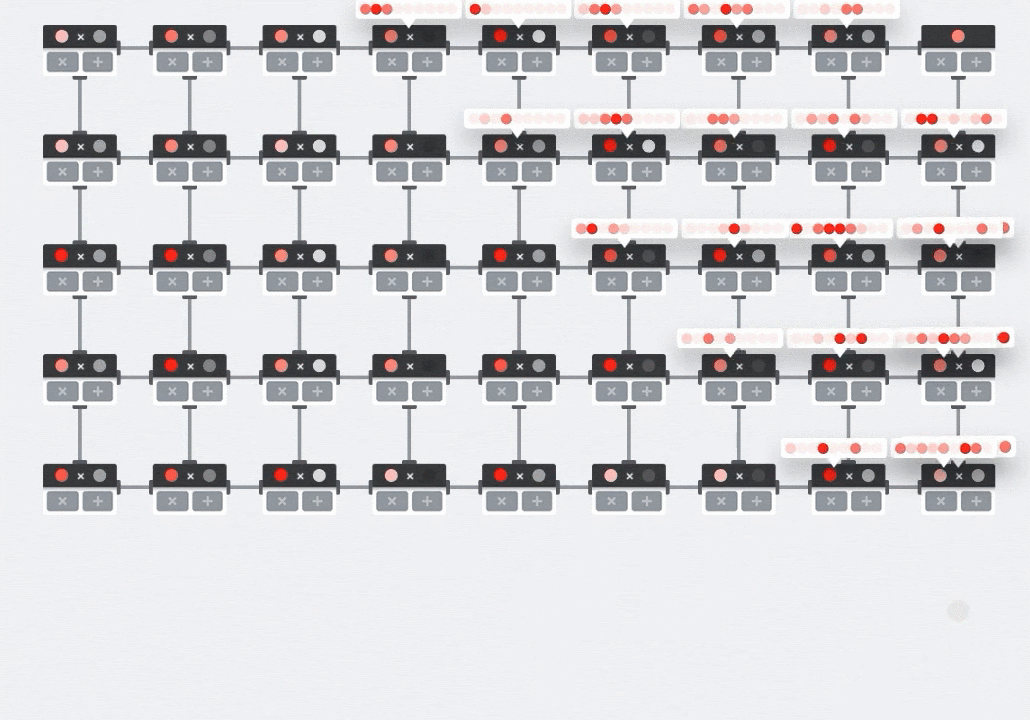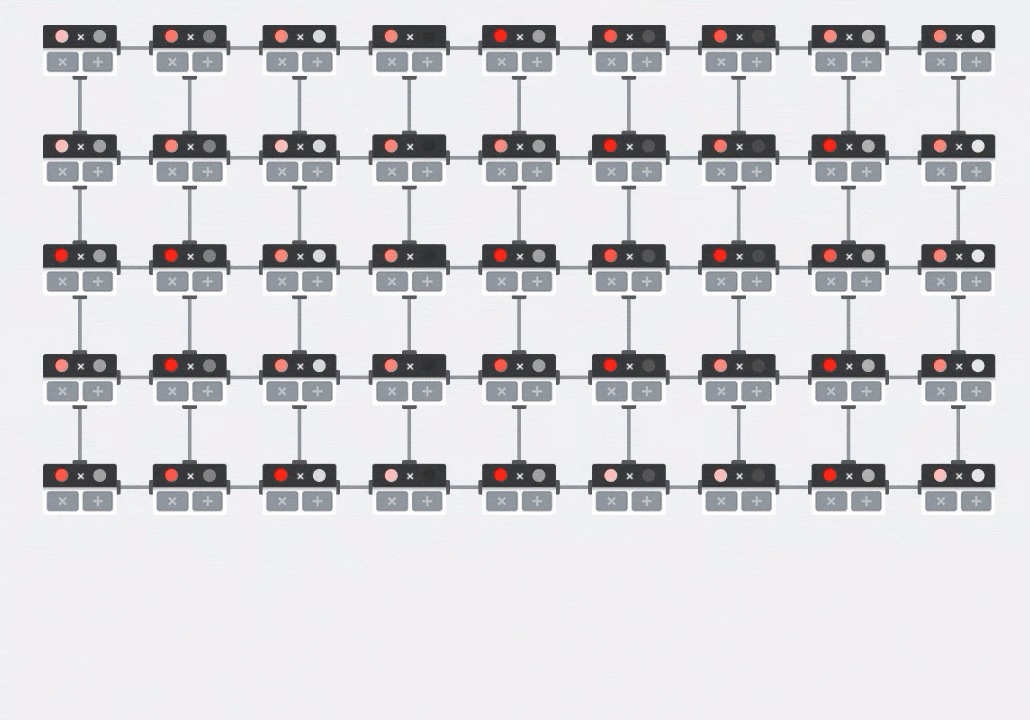
插图:MXU 收缩阵列。计算元素是乘加累加器。一个矩阵的值被加载到数组中(红点)。另一个矩阵的值流过该数组(灰点)。垂直线会将值向上传播。水平线会传播部分总和。留给用户做练习,以便验证当数据流过数组时,您会得到右侧矩阵乘法的结果。
除此之外,虽然点积是根据 MXU 计算的,但中间求和只是在相邻的计算单元之间流动。它们不需要在内存甚至寄存器文件中存储和检索。最终结果是,在计算矩阵乘法时,TPU 脉动阵列架构具有明显的密度和功率优势,并且在计算矩阵乘法时,也比 GPU 具有明显的速度优势。
Cloud TPU
当您请求一个“Cloud TPU v2"在 Google Cloud Platform 上,您会得到一个配有 PCI 连接 TPU 板的虚拟机 (VM)。TPU 板有四个双核 TPU 芯片。每个 TPU 核心都有一个 VPU(矢量处理单元)和 128x128 MXU(矩阵乘法单元)。这个“Cloud TPU”通常通过网络连接到请求它的虚拟机。因此,整个过程如下所示:

图解:具有网络连接的“Cloud TPU”的虚拟机加速器"Cloud TPU"它由一个虚拟机组成,虚拟机配有 PCI 连接的 TPU 板,板上装有四个双核 TPU 芯片。
TPU Pod
在 Google 的数据中心中,TPU 连接到高性能计算 (HPC) 互连,这使得它们看起来就像一个超大加速器。Google 将其称为 Pod,它们最多可包含 512 个 TPU v2 核心或 2048 个 TPU v3 核心。

图解:TPU v3 Pod。通过 HPC 互连连接的 TPU 板和机架。
在训练期间,梯度通过全归约算法在 TPU 核心之间交换(此处充分说明了全归约)。正在训练的模型可以通过针对大批量大小进行训练来充分利用硬件。

图解:在 Google TPU 的二维环形网状网 HPC 网络上使用全约化算法在训练期间同步梯度。
软件
大批量训练
理想的 TPU 批次大小是每个 TPU 核心 128 个数据项,但硬件已经可以显示出每个 TPU 核心 8 个数据项的良好利用率。请注意,一个 Cloud TPU 有 8 个核心。
在此 Codelab 中,我们将使用 Keras API。在 Keras 中,您指定的批次是整个 TPU 的全局批次大小。您的批次将自动拆分为 8 个,并在 TPU 的 8 个核心上运行。

如需了解其他性能提示,请参阅 TPU 性能指南。对于非常大的批次大小,某些模型可能需要特别注意,请参阅 LARSOptimizer 了解详情。
幕后探秘:XLA
TensorFlow 程序定义计算图。TPU 不会直接运行 Python 代码,而是运行由 Tensorflow 程序定义的计算图。在后台,一个名为 XLA(加速线性代数编译器)的编译器将计算节点的 Tensorflow 图转换为 TPU 机器代码。此编译器还可以对您的代码和内存布局执行许多高级优化。编译会在工作发送到 TPU 时自动进行。您无需在 build 链中明确包含 XLA。

图解:为了在 TPU 上运行,您的 Tensorflow 程序定义的计算图会先转换为 XLA(加速线性代数编译器)表示法,然后再由 XLA 编译成 TPU 机器代码。
在 Keras 中使用 TPU
从 Tensorflow 2.1 开始,可通过 Keras API 支持 TPU。Keras 支持适用于 TPU 和 TPU Pod。下面是一个适用于 TPU、GPU 和 CPU 的示例:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
在此代码段中:
TPUClusterResolver().connect()用于查找网络上的 TPU。它无需参数即可在大多数 Google Cloud 系统(AI Platform 作业、Colaboratory、Kubeflow、通过“ctpu up”实用程序创建的深度学习虚拟机)上运行。由于 TPU_NAME 环境变量,这些系统知道其 TPU 的位置。如果您手动创建 TPU,请设置 TPU_NAME env。变量或者使用显式参数TPUClusterResolver(tp_uname, zone, project)调用TPUClusterResolverTPUStrategy是实现分布和“all-reduce”的部分梯度同步算法。- 系统会通过范围应用策略。必须在策略 scope() 中定义模型。
tpu_model.fit函数需要 tf.data.Dataset 对象作为 TPU 训练的输入。
常见的 TPU 移植任务
- 虽然在 Tensorflow 模型中加载数据的方法有很多,但对于 TPU,必须使用
tf.data.DatasetAPI。 - TPU 速度非常快,在 TPU 上运行时,数据提取常常成为瓶颈。TPU 性能指南中提供了一些工具,可用于检测数据瓶颈和其他性能提示。
- int8 或 int16 数字被视为 int32。TPU 没有在少于 32 位上运行的整数硬件。
- 不支持某些 TensorFlow 操作。点击此处查看列表。好消息是,此限制仅适用于训练代码,即前向和后向传递模型。您仍然可以在数据输入流水线中使用所有 TensorFlow 操作,因为它们将在 CPU 上执行。
- TPU 不支持
tf.py_func。
4. 正在加载数据






我们将使用花卉图片数据集。我们的目标是学习如何将其分类为 5 种花卉类型。数据加载使用 tf.data.Dataset API 执行。首先,让我们了解一下该 API。
实践活动
请打开以下笔记本,执行单元格 (Shift-ENTER),然后按照显示“必须完成的工作”提示操作标签。

Fun with tf.data.Dataset (playground).ipynb
其他信息
关于“鲜花”数据集
该数据集整理到 5 个文件夹中。每个文件夹都包含其中一种鲜花。这些文件夹的名称为“向日葵”、“雏菊”、“蒲公英”、“郁金香”和“玫瑰”。数据托管在 Google Cloud Storage 上的公开存储分区中。摘录:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
为什么使用 tf.data.Dataset?
Keras 和 Tensorflow 都接受数据集在其所有训练和评估函数中。将数据加载到数据集中后,该 API 会提供对神经网络训练数据有用的所有常用功能:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
您可以参阅这篇文章,了解性能提示和数据集最佳做法。如需查看参考文档,请点击此处。
tf.data.Dataset 基础知识
数据通常位于多个文件中,此处为图片。您可以通过调用以下内容来创建文件名数据集:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
您随后“映射”为每个文件名添加一个函数,该函数通常会将文件加载和解码为内存中的实际数据:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
如需迭代数据集,请执行以下操作:
for data in my_dataset:
print(data)
元组数据集
在监督式学习中,训练数据集通常由成对的训练数据和正确答案组成。为此,解码函数可以返回元组。然后,您将得到一个包含元组和元组的数据集。在您对其进行迭代时,系统会返回该数据集。返回的值是可供模型使用的 TensorFlow 张量。您可以对其调用 .numpy() 来查看原始值:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
总结:逐个加载图片很慢!
在迭代此数据集时,您会发现每秒可以加载 1-2 张图片。太慢了!我们用于训练的硬件加速器可以承受这一速率的数倍。请继续阅读下一部分,了解如何实现这一目标。
解决方案
以下是解决方案笔记本。如果您遇到困难,可以使用它。
Fun with tf.data.Dataset (solution).ipynb
所学内容
- 🤔? tf.data.Dataset.list_files
- ✨ tf.data.Dataset.map
- 🤔? 输入元组的数据集
- 😀? 迭代数据集
请花点时间回想一下这份核对清单。
5. 快速加载数据
我们将在本实验中使用的张量处理单元 (TPU) 硬件加速器非常快。他们面临的挑战往往是足够快地为他们提供数据,让他们保持忙碌。Google Cloud Storage (GCS) 能够维持极高的吞吐量,但与所有云端存储系统一样,发起连接会花费一些网络往返费用。因此,以数千个单独的文件存储数据并不理想。我们将在数量较少的文件中对它们进行批处理,并利用 tf.data.Dataset 的强大功能从多个文件中并行读取数据。
通读
以下笔记本中的代码用于加载图片文件,将其调整为通用大小,然后将其存储在 16 个 TFRecord 文件中。请快速通读。您无需执行此 Codelab,因为我们将为 Codelab 的其余部分提供正确的 TFRecord 格式的数据。
Flower pictures to TFRecords.ipynb
可实现最佳 GCS 吞吐量的理想数据布局
TFRecord 文件格式
Tensorflow 首选的用于存储数据的文件格式是基于 protobuf 的 TFRecord 格式。您也可以使用其他序列化格式,但您可以通过编写以下代码,直接从 TFRecord 文件中加载数据集:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
为了获得最佳性能,建议您使用以下更复杂的代码,一次从多个 TFRecord 文件中读取数据。这段代码会并行读取 N 个文件,并忽略数据顺序以提高读取速度。
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
TFRecord 备忘单
TFRecord 中可以存储三种类型的数据:字节字符串(字节列表)、64 位整数和 32 位浮点。它们始终以列表形式存储,单个数据元素将是大小为 1 的列表。您可以使用以下辅助函数将数据存储在 TFRecord 中。
写入字节字符串
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
写入整数
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
编写浮点数
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
编写 TFRecord,具体方法是使用上面的帮助程序
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
如需从 TFRecord 中读取数据,您必须先声明所存储记录的布局。在声明中,您可以按固定长度列表或可变长度列表的形式访问任何命名字段:
从 TFRecord 中读取数据
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
有用的代码段:
读取单个数据元素
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
读取固定大小的元素列表
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
读取数量不定的数据项
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
VarLenFeature 会返回一个稀疏向量,并且在解码 TFRecord 后需要执行一个额外步骤:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
TFRecord 中也可能包含可选字段。如果您在读取某个字段时指定了默认值,则当该字段缺失时,系统将返回默认值而不是错误。
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
所学内容
- 🤔? 将数据文件分片,以便从 GCS 快速访问
- 😓? 如何编写 TFRecords。(您已忘记语法?没关系,请将此页面添加为备忘单的书签)
- 🤔? 使用 TFRecordDataset 从 TFRecord 加载数据集
请花点时间回想一下这份核对清单。
6. 恭喜!
您现在可以向 TPU 馈送数据。请继续完成下一个实验
- [本实验] TPU 速度数据流水线:tf.data.Dataset 和 TFRecords
- 您的第一个具有迁移学习功能的 Keras 模型
- 包含 Keras 和 TPU 的卷积神经网络
- 现代卷积神经网络、squeezenet、Xception,以及 Keras 和 TPU
TPU 使用实例
Cloud AI Platform 上提供 TPU 和 GPU:
- 在 Deep Learning VM 上
- 在 AI Platform Notebooks 中
- 在 AI Platform Training 作业中
最后,欢迎您提供反馈。如果您发现此实验中存在错误,或者您认为需要改进,请告诉我们。您可以通过 GitHub 问题 [反馈链接] 提供反馈。

|
|

