
1. บทนำ
เวิร์กโฟลว์เป็นกรณีการใช้งานทั่วไปในการวิเคราะห์ข้อมูล โดยจะเกี่ยวข้องกับการส่งผ่านข้อมูล การเปลี่ยนรูปแบบ และการวิเคราะห์ข้อมูลเพื่อค้นหาข้อมูลที่มีความหมาย เครื่องมือสำหรับจัดการเวิร์กโฟลว์ใน Google Cloud Platform คือ Cloud Composer ซึ่งเป็นเครื่องมือเวิร์กโฟลว์แบบโอเพนซอร์สยอดนิยมอย่าง Apache Airflow ในห้องทดลองนี้ คุณจะใช้ Cloud Composer เพื่อสร้างเวิร์กโฟลว์แบบง่ายๆ ที่สร้างคลัสเตอร์ Cloud Dataproc, วิเคราะห์โดยใช้ Cloud Dataproc และ Apache Hadoop จากนั้นจึงลบคลัสเตอร์ Cloud Dataproc ในภายหลัง
Cloud Composer คืออะไร
Cloud Composer คือบริการเวิร์กโฟลว์แบบเป็นกลุ่มที่มีการจัดการครบวงจร ซึ่งช่วยให้คุณเขียน กำหนดเวลา และตรวจสอบไปป์ไลน์ที่ครอบคลุมในระบบคลาวด์และศูนย์ข้อมูลภายในองค์กรได้ Cloud Composer สร้างขึ้นจากโปรเจ็กต์โอเพนซอร์ส Apache Airflow ยอดนิยมและดำเนินการโดยใช้ภาษาการเขียนโปรแกรม Python ทำให้ปราศจากการผูกมัดและใช้งานง่าย
การใช้ Cloud Composer แทนอินสแตนซ์ในเครื่องของ Apache Airflow จะช่วยให้ผู้ใช้ได้รับประโยชน์จาก Airflow ที่ดีที่สุดโดยไม่ต้องติดตั้งหรือมีค่าใช้จ่ายในการจัดการ
Apache Airflow คืออะไร
Apache Airflow เป็นเครื่องมือโอเพนซอร์สที่ใช้สำหรับเขียน กำหนดเวลา และตรวจสอบเวิร์กโฟลว์โดยใช้โปรแกรม คำศัพท์สำคัญ 2-3 คำที่ควรจดจำเกี่ยวกับ Airflow ที่คุณจะเห็นในห้องทดลองมีดังนี้
- DAG - DAG (กราฟแบบ Acyclic โดยตรง) คือคอลเล็กชันของงานที่มีการจัดระเบียบซึ่งคุณต้องการกำหนดเวลาและเรียกใช้ DAG หรือเรียกอีกอย่างว่าเวิร์กโฟลว์ จะมีการกำหนดไว้ในไฟล์ Python มาตรฐาน
- โอเปอเรเตอร์ - โอเปอเรเตอร์อธิบายงานเดียวในเวิร์กโฟลว์
Cloud Dataproc คืออะไร
Cloud Dataproc คือบริการ Apache Spark และ Apache Hadoop ที่มีการจัดการครบวงจรของ Google Cloud Platform Cloud Dataproc ผสานรวมกับบริการ GCP อื่นๆ ได้อย่างง่ายดาย ทำให้คุณมีแพลตฟอร์มที่มีประสิทธิภาพและสมบูรณ์สำหรับการประมวลผลข้อมูล การวิเคราะห์ และแมชชีนเลิร์นนิง
สิ่งที่คุณจะทำ
Codelab นี้จะแสดงวิธีสร้างและเรียกใช้เวิร์กโฟลว์ Apache Airflow ใน Cloud Composer เพื่อทำงานต่อไปนี้ให้เสร็จสมบูรณ์
- สร้างคลัสเตอร์ Cloud Dataproc
- เรียกใช้งานจำนวนคำของ Apache Hadoop บนคลัสเตอร์ และส่งผลลัพธ์ไปยัง Cloud Storage
- ลบคลัสเตอร์
สิ่งที่คุณจะได้เรียนรู้
- วิธีสร้างและเรียกใช้เวิร์กโฟลว์ Apache Airflow ใน Cloud Composer
- วิธีใช้ Cloud Composer และ Cloud Dataproc เพื่อเรียกใช้การวิเคราะห์บนชุดข้อมูล
- วิธีเข้าถึงสภาพแวดล้อม Cloud Composer ผ่านคอนโซล Google Cloud Platform, Cloud SDK และอินเทอร์เฟซเว็บ Airflow
สิ่งที่คุณต้องมี
- บัญชี GCP
- ความรู้พื้นฐานเกี่ยวกับ CLI
- ความเข้าใจเบื้องต้นเกี่ยวกับ Python
2. การตั้งค่า GCP
สร้างโปรเจ็กต์
เลือกหรือสร้างโปรเจ็กต์ Google Cloud Platform
จดรหัสโปรเจ็กต์ไว้ ซึ่งจะใช้ในขั้นตอนถัดไป
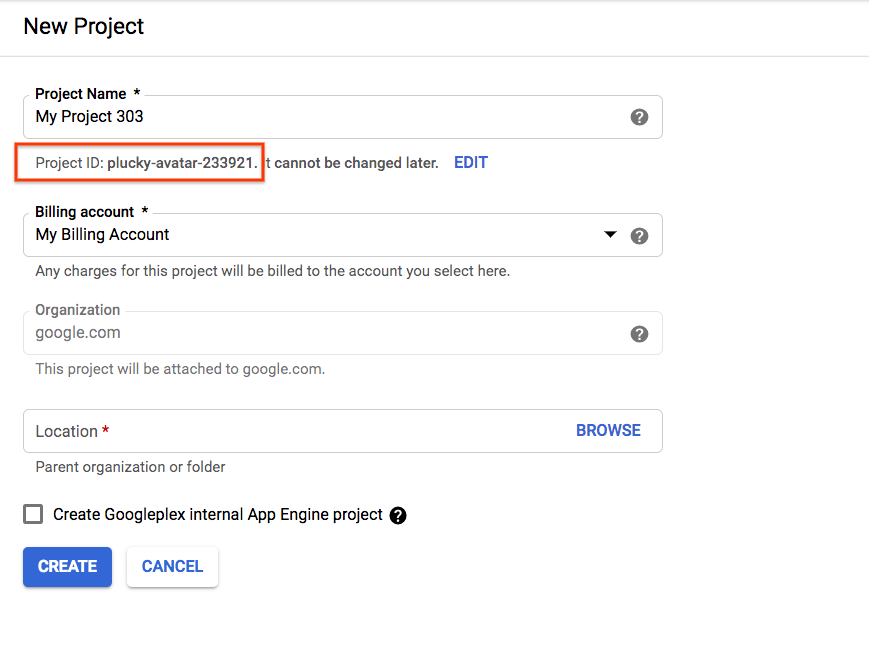
หากคุณกำลังสร้างโปรเจ็กต์ใหม่ รหัสโปรเจ็กต์จะอยู่ใต้ชื่อโปรเจ็กต์ในหน้าการสร้าง |
|
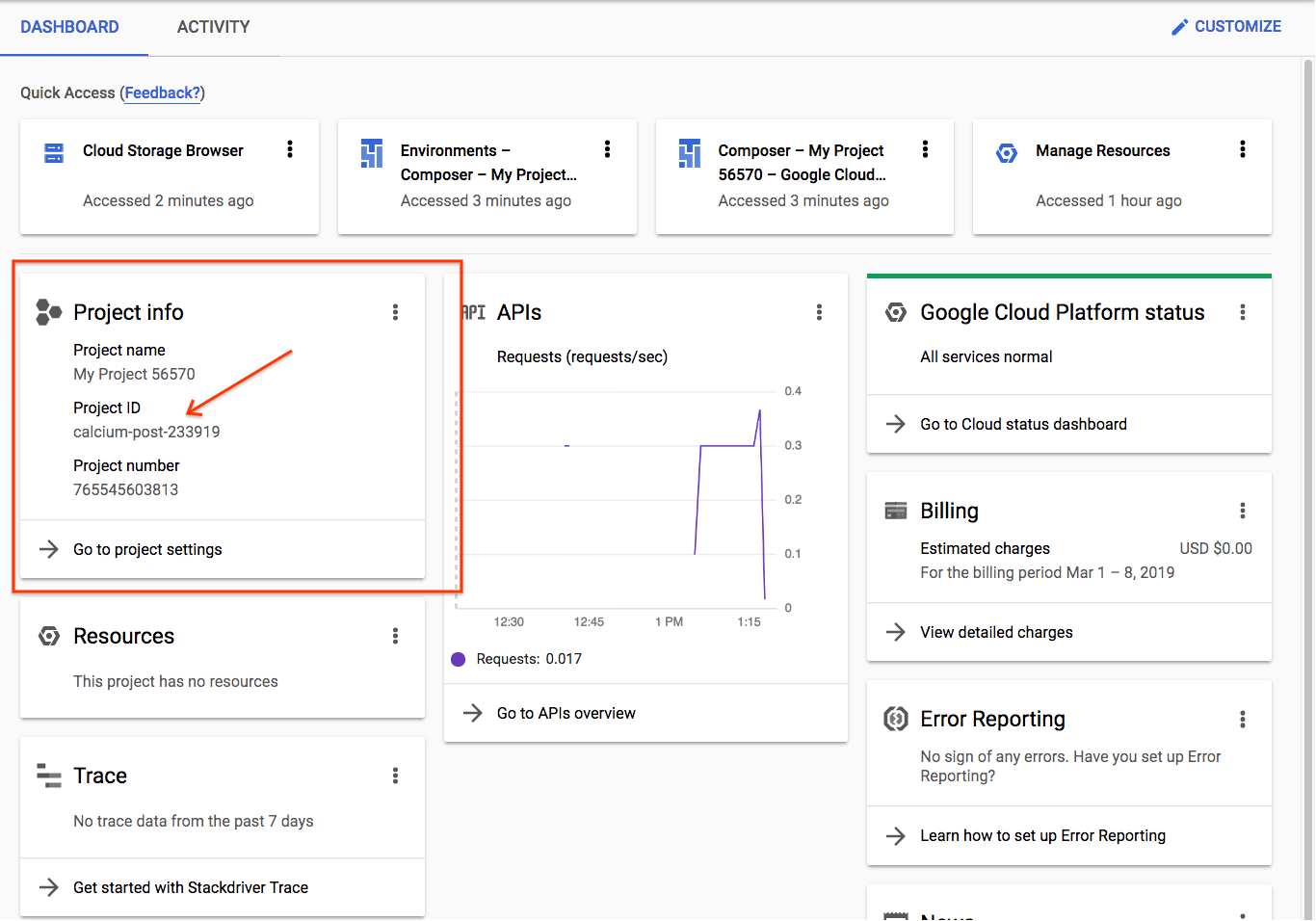
หากสร้างโปรเจ็กต์ไว้แล้ว คุณจะดูรหัสได้ในหน้าแรกของคอนโซลในการ์ดข้อมูลโปรเจ็กต์ |
|
เปิดใช้ API
เปิดใช้ Cloud Composer, Cloud Dataproc และ Cloud Storage API เมื่อเปิดใช้แล้ว สามารถเพิกเฉยต่อปุ่ม "ไปที่ข้อมูลเข้าสู่ระบบ" ได้ และดำเนินการต่อไปยังขั้นตอนถัดไปของบทแนะนำ |
|

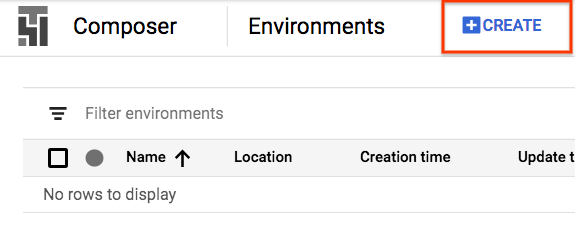
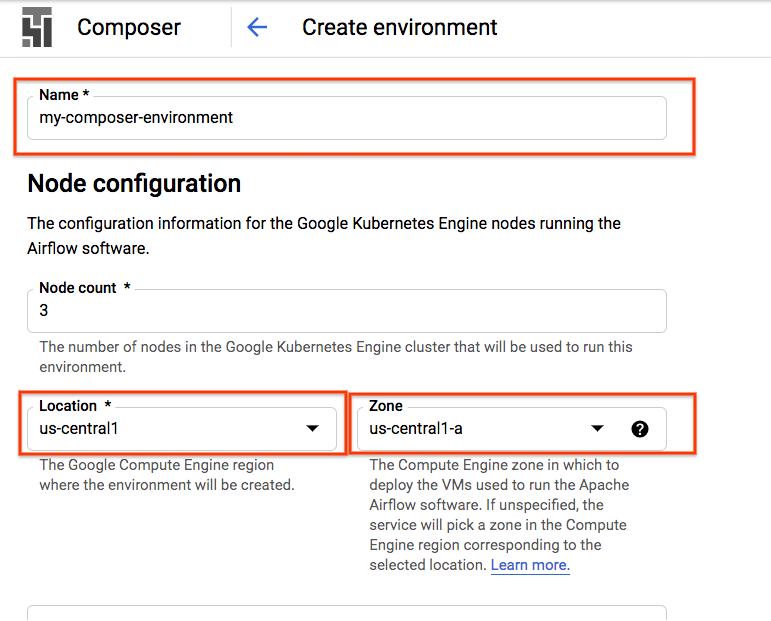
สร้างสภาพแวดล้อมคอมโพสเซอร์
สร้างสภาพแวดล้อม Cloud Composer ด้วยการกำหนดค่าต่อไปนี้
การกําหนดค่าอื่นๆ ทั้งหมดจะยังคงเป็นค่าเริ่มต้นได้ คลิก "สร้าง" ที่ด้านล่าง |
|
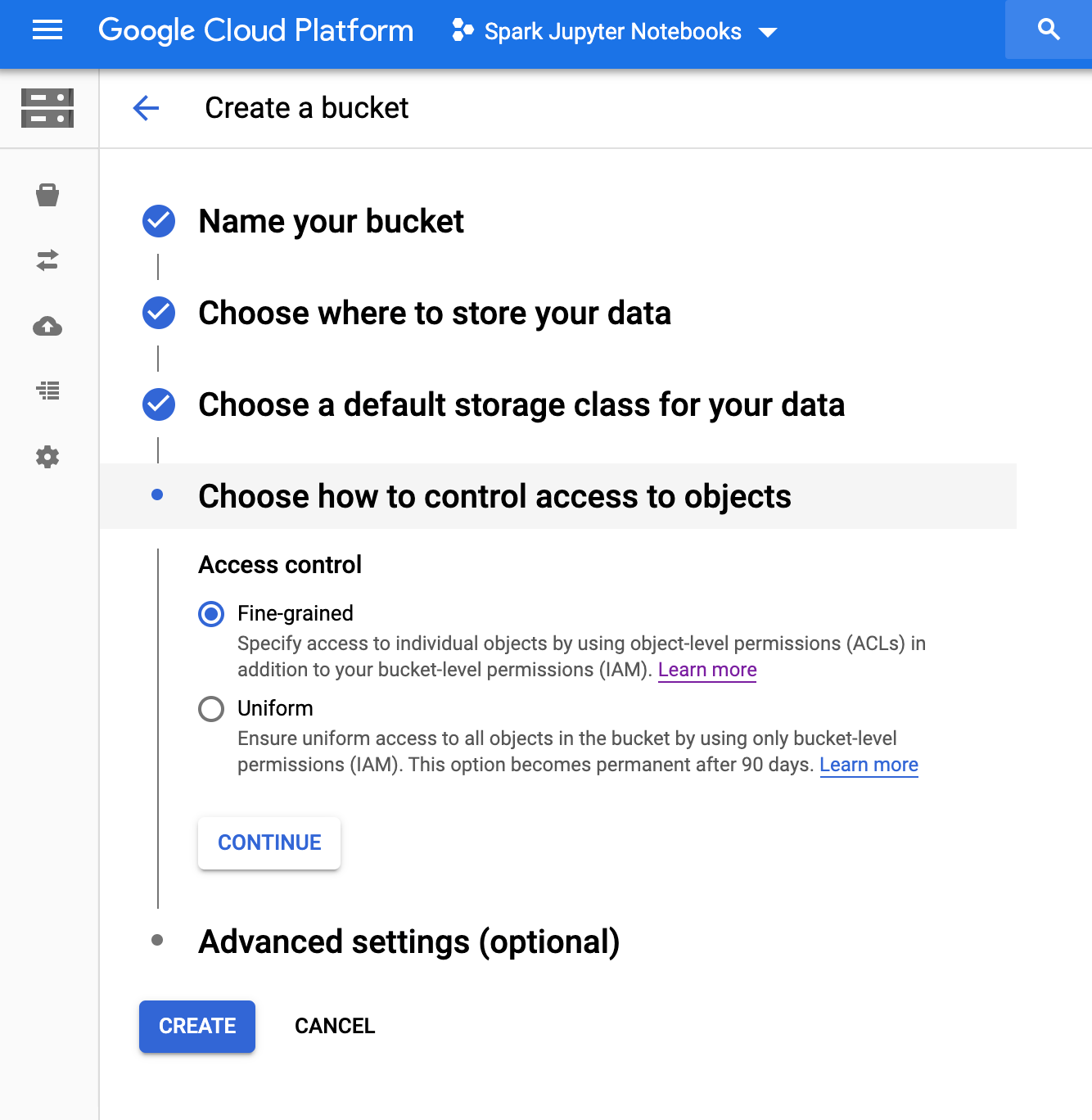
สร้างที่เก็บข้อมูล Cloud Storage
สร้างที่เก็บข้อมูล Cloud Storage ในโปรเจ็กต์ด้วยการกำหนดค่าต่อไปนี้
กด "สร้าง" เมื่อคุณพร้อม |
|
3. การตั้งค่า Apache Airflow
การดูข้อมูลสภาพแวดล้อมของคอมโพสเซอร์
ในคอนโซล GCP ให้เปิดหน้าสภาพแวดล้อม
คลิกชื่อของสภาพแวดล้อมเพื่อดูรายละเอียด
หน้ารายละเอียดสภาพแวดล้อมจะแสดงข้อมูล เช่น URL ของอินเทอร์เฟซเว็บ Airflow, รหัสคลัสเตอร์ของ Google Kubernetes Engine, ชื่อที่เก็บข้อมูล Cloud Storage และเส้นทางสำหรับโฟลเดอร์ /dags
ใน Airflow DAG (กราฟแบบ Acyclic โดยตรง) คือคอลเล็กชันของงานที่มีการจัดระเบียบซึ่งคุณต้องการกำหนดเวลาและเรียกใช้ DAG หรือเรียกอีกอย่างว่าเวิร์กโฟลว์ จะมีการกำหนดไว้ในไฟล์ Python มาตรฐาน Cloud Composer จะกำหนดเวลา DAG ในโฟลเดอร์ /dags เท่านั้น โฟลเดอร์ /dags อยู่ในที่เก็บข้อมูล Cloud Storage ที่ Cloud Composer สร้างขึ้นโดยอัตโนมัติเมื่อคุณสร้างสภาพแวดล้อม
การตั้งค่าตัวแปรสภาพแวดล้อม Apache Airflow
ตัวแปร Apache Airflow เป็นแนวคิดเฉพาะ Airflow ซึ่งแตกต่างจากตัวแปรสภาพแวดล้อม ในขั้นตอนนี้ คุณจะตั้งค่าตัวแปร Airflow 3 รายการ ได้แก่ gcp_project, gcs_bucket และ gce_zone
กำลังใช้ gcloud เพื่อตั้งค่าตัวแปร
ก่อนอื่น ให้เปิด Cloud Shell ซึ่งมี Cloud SDK ติดตั้งให้คุณได้อย่างสะดวก
ตั้งค่าตัวแปรสภาพแวดล้อม COMPOSER_INSTANCE เป็นชื่อของสภาพแวดล้อมคอมโพสเซอร์
COMPOSER_INSTANCE=my-composer-environment
หากต้องการตั้งค่าตัวแปร Airflow โดยใช้เครื่องมือบรรทัดคำสั่ง gcloud ให้ใช้คำสั่ง gcloud composer environments run กับคำสั่งย่อย variables คำสั่ง gcloud composer นี้จะเรียกใช้คำสั่งย่อย Airflow CLI variables คำสั่งย่อยจะส่งอาร์กิวเมนต์ไปยังเครื่องมือบรรทัดคำสั่ง gcloud
คุณจะต้องเรียกใช้คำสั่งนี้ 3 ครั้ง โดยแทนที่ตัวแปรด้วยตัวแปรที่เกี่ยวข้องกับโปรเจ็กต์ของคุณ
ตั้งค่า gcp_project โดยใช้คำสั่งต่อไปนี้ โดยแทนที่ <your-project-id> รหัสโปรเจ็กต์ที่คุณจดไว้ในขั้นตอนที่ 2
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
เอาต์พุตจะมีลักษณะดังนี้
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
ตั้งค่า gcs_bucket โดยใช้คำสั่งต่อไปนี้ โดยแทนที่ <your-bucket-name> ด้วยรหัสที่เก็บข้อมูลที่คุณจดไว้ในขั้นตอนที่ 2 หากคุณทำตามคำแนะนำของเรา ชื่อที่เก็บข้อมูลของคุณจะเหมือนกับรหัสโปรเจ็กต์ เอาต์พุตจะคล้ายกับคำสั่งก่อนหน้า
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
ตั้งค่า gce_zone โดยใช้คำสั่งต่อไปนี้ เอาต์พุตจะคล้ายกับคำสั่งก่อนหน้า
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(ไม่บังคับ) การใช้ gcloud เพื่อดูตัวแปร
หากต้องการดูค่าของตัวแปร ให้เรียกใช้คำสั่งย่อย Airflow CLI variables ด้วยอาร์กิวเมนต์ get หรือใช้ Airflow UI
เช่น
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
ซึ่งทำได้โดยใช้ตัวแปร 3 ตัวที่เพิ่งตั้งค่า ซึ่งได้แก่ gcp_project, gcs_bucket และ gce_zone
4. ตัวอย่างเวิร์กโฟลว์
มาดูโค้ดสำหรับ DAG ที่เราจะใช้ในขั้นตอนที่ 5 กัน ไม่ต้องกังวลเรื่องการดาวน์โหลดไฟล์ เพียงทำตามขั้นตอนต่อไปนี้
ที่นี่มีของมากมายให้คลายเครียด เรามาดูรายละเอียดกัน
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
เราเริ่มต้นด้วยการนำเข้า Airflow บางส่วน:
airflow.models- ช่วยให้เราเข้าถึงและสร้างข้อมูลในฐานข้อมูล Airflow ได้airflow.contrib.operators- ตำแหน่งที่โอเปอเรเตอร์จากชุมชนตั้งอยู่ ในกรณีนี้ เราต้องใช้dataproc_operatorเพื่อเข้าถึง Cloud Dataproc APIairflow.utils.trigger_rule- สำหรับเพิ่มกฎทริกเกอร์ในโอเปอเรเตอร์ กฎการเรียกใช้ช่วยให้ควบคุมได้อย่างละเอียดว่าโอเปอเรเตอร์ควรดำเนินการหรือไม่เมื่อเกี่ยวข้องกับสถานะของระดับบนสุด
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
แอตทริบิวต์นี้ระบุตำแหน่งไฟล์เอาต์พุตของเรา บรรทัดเด่นตรงนี้คือ models.Variable.get('gcs_bucket') ซึ่งจะจับค่าตัวแปร gcs_bucket จากฐานข้อมูล Airflow
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR- ตำแหน่งของไฟล์ .jar ที่เราจะเรียกใช้บนคลัสเตอร์ Cloud Dataproc ในที่สุด ซึ่งโฮสต์อยู่บน GCP สำหรับคุณอยู่แล้วinput_file- ตำแหน่งของไฟล์ที่มีข้อมูลซึ่งงาน Hadoop ของเราจะประมวลผลในที่สุด เราจะอัปโหลดข้อมูลไปยังตำแหน่งนั้นร่วมกันในขั้นตอนที่ 5wordcount_args- อาร์กิวเมนต์ที่เราจะส่งไปในไฟล์ jar
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
ซึ่งจะทำให้ออบเจ็กต์วันที่และเวลาเทียบเท่ากับเที่ยงคืนของวันก่อนหน้า ตัวอย่างเช่น หากเรียกใช้ในวันที่ 4 มีนาคม เวลา 11:00 น. ออบเจ็กต์วันที่และเวลาจะแสดงเป็น 00:00 ของวันที่ 3 มีนาคม เรื่องนี้เกี่ยวข้องกับวิธีที่ Airflow จัดการการจัดตารางเวลา ดูข้อมูลเพิ่มเติมเกี่ยวกับเรื่องนี้ได้ที่นี่
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
ควรระบุตัวแปร default_dag_args ในรูปแบบพจนานุกรมเมื่อมีการสร้าง DAG ใหม่:
'email_on_failure'- ระบุว่าควรส่งการแจ้งเตือนทางอีเมลเมื่องานล้มเหลวหรือไม่'email_on_retry'- ระบุว่าควรส่งการแจ้งเตือนทางอีเมลเมื่อมีการพยายามทำงานอีกครั้งหรือไม่'retries'- แสดงจำนวนครั้งที่ Airflow ควรดำเนินการซ้ำในกรณีที่ DAG ล้มเหลว'retry_delay'- แสดงระยะเวลาที่ Airflow ควรรอก่อนที่จะลองลองอีกครั้ง'project_id'- บอก DAG ว่าจะใช้รหัสโปรเจ็กต์ GCP ใดเพื่อเชื่อมโยง ซึ่งจำเป็นต้องใช้กับผู้ให้บริการ Dataproc ในภายหลัง
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
การใช้ with models.DAG จะบอกให้สคริปต์รวมทุกอย่างที่อยู่ด้านล่างไว้ใน DAG เดียวกัน นอกจากนี้ เรายังเห็นอาร์กิวเมนต์ 3 แบบที่ผ่านการตรวจสอบใน
- ชื่อแรกคือ สตริง คือชื่อที่จะกำหนด DAG ที่เรากำลังสร้าง ในกรณีนี้เราใช้
composer_hadoop_tutorial schedule_interval- ออบเจ็กต์datetime.timedeltaซึ่งเราตั้งไว้ที่ 1 วัน ซึ่งหมายความว่า DAG นี้จะพยายามดำเนินการวันละครั้งหลังจาก'start_date'ซึ่งตั้งค่าไว้ก่อนหน้าใน'default_dag_args'default_args- พจนานุกรมที่เราสร้างไว้ก่อนหน้านี้ ซึ่งมีอาร์กิวเมนต์เริ่มต้นสำหรับ DAG
สร้างคลัสเตอร์ Dataproc
ต่อไป เราจะสร้าง dataproc_operator.DataprocClusterCreateOperator ซึ่งจะสร้างคลัสเตอร์ Cloud Dataproc
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
ภายในโอเปอเรเตอร์นี้ เราพบอาร์กิวเมนต์สองสามรายการ ยกเว้นอาร์กิวเมนต์แรกที่เฉพาะเจาะจงสำหรับโอเปอเรเตอร์นี้
task_id- เช่นเดียวกับใน BashOperator นี่คือชื่อที่เรากำหนดให้กับโอเปอเรเตอร์ ซึ่งสามารถดูได้จาก Airflow UIcluster_name- ชื่อที่เรากำหนดคลัสเตอร์ Cloud Dataproc โดยตั้งชื่อว่าcomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(ดูกล่องข้อมูลสำหรับข้อมูลเพิ่มเติมที่ไม่บังคับ)num_workers- จำนวนผู้ปฏิบัติงานที่เราจัดสรรให้กับคลัสเตอร์ Cloud Dataproczone- ภูมิภาคทางภูมิศาสตร์ที่เราต้องการให้คลัสเตอร์อยู่ ตามที่บันทึกไว้ในฐานข้อมูล Airflow ซึ่งจะอ่านตัวแปร'gce_zone'ที่เราตั้งค่าไว้ในขั้นตอนที่ 3master_machine_type- ประเภทเครื่องที่เราต้องการจัดสรรให้กับต้นแบบ Cloud Dataprocworker_machine_type- ประเภทของเครื่องที่เราต้องการจัดสรรให้กับผู้ปฏิบัติงาน Cloud Dataproc
ส่งงาน Apache Hadoop
dataproc_operator.DataProcHadoopOperator ช่วยให้เราส่งงานไปยังคลัสเตอร์ Cloud Dataproc ได้
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
เรามีพารามิเตอร์หลายอย่าง ดังนี้
task_id- ชื่อที่เรากำหนดให้กับ DAG ส่วนนี้main_jar- ตำแหน่งของไฟล์ .jar ที่ต้องการให้ทำงานกับคลัสเตอร์cluster_name- ชื่อของคลัสเตอร์ที่จะเรียกใช้งาน ซึ่งคุณจะเห็นว่าเหมือนกับที่เราพบในโอเปอเรเตอร์ก่อนหน้าarguments- อาร์กิวเมนต์ที่ส่งผ่านเข้าไปในไฟล์ jar ในลักษณะเดียวกับที่คุณจะดำเนินการกับไฟล์ .jar จากบรรทัดคำสั่ง
ลบคลัสเตอร์
โอเปอเรเตอร์สุดท้ายที่เราจะสร้างคือ dataproc_operator.DataprocClusterDeleteOperator
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
โอเปอเรเตอร์นี้จะลบคลัสเตอร์ Cloud Dataproc ที่ระบุ เราเห็นอาร์กิวเมนต์ 3 อย่างที่นี่
task_id- เช่นเดียวกับใน BashOperator นี่คือชื่อที่เรากำหนดให้กับโอเปอเรเตอร์ ซึ่งสามารถดูได้จาก Airflow UIcluster_name- ชื่อที่เรากำหนดคลัสเตอร์ Cloud Dataproc ซึ่งเราได้ตั้งชื่อว่าcomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(ดูข้อมูลเพิ่มเติมในส่วน "สร้างคลัสเตอร์ Dataproc" ได้ที่ช่องข้อมูล)trigger_rule- เราพูดถึงกฎทริกเกอร์เป็นระยะเวลาสั้นๆ ระหว่างการนำเข้าเมื่อเริ่มต้นขั้นตอนนี้ แต่เรายังมีการดำเนินการอยู่ 1 รายการ โดยค่าเริ่มต้น โอเปอเรเตอร์ Airflow จะไม่ทำงานเว้นแต่โอเปอเรเตอร์อัปสตรีมทั้งหมดจะเสร็จสิ้น กฎทริกเกอร์ALL_DONEกำหนดให้โอเปอเรเตอร์อัปสตรีมทั้งหมดต้องทำงานให้เสร็จสมบูรณ์เท่านั้น ไม่ว่าโอเปอเรเตอร์จะสำเร็จหรือไม่ก็ตาม ซึ่งหมายความว่าแม้ว่างาน Hadoop จะล้มเหลว แต่เราก็ยังต้องการคลัสเตอร์ดังกล่าวอยู่
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
สุดท้าย เราต้องการให้โอเปอเรเตอร์เหล่านี้ทำงานตามลำดับที่กำหนด และสามารถระบุได้โดยใช้โอเปอเรเตอร์บิตชิฟท์ของ Python ในกรณีนี้ create_dataproc_cluster จะดำเนินการก่อนเสมอ ตามด้วย run_dataproc_hadoop และสุดท้ายคือ delete_dataproc_cluster
เมื่อนำทุกอย่างมารวมกัน โค้ดจะมีลักษณะเช่นนี้
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. อัปโหลดไฟล์ Airflow ไปยัง Cloud Storage
คัดลอก DAG ไปยังโฟลเดอร์ /dags ของคุณ
- ก่อนอื่น ให้เปิด Cloud Shell ซึ่งมี Cloud SDK ติดตั้งให้คุณได้อย่างสะดวก
- โคลนที่เก็บตัวอย่าง Python และเปลี่ยนเป็นไดเรกทอรี Composer/workflows
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- เรียกใช้คำสั่งต่อไปนี้เพื่อตั้งชื่อโฟลเดอร์ DAG เป็นตัวแปรสภาพแวดล้อม
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- เรียกใช้คำสั่ง
gsutilต่อไปนี้เพื่อคัดลอกโค้ดบทแนะนำไปวางที่โฟลเดอร์ /dags ของคุณ
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
เอาต์พุตจะมีลักษณะดังนี้
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. การใช้ Airflow UI
วิธีเข้าถึงอินเทอร์เฟซเว็บ Airflow โดยใช้คอนโซล GCP
|
|
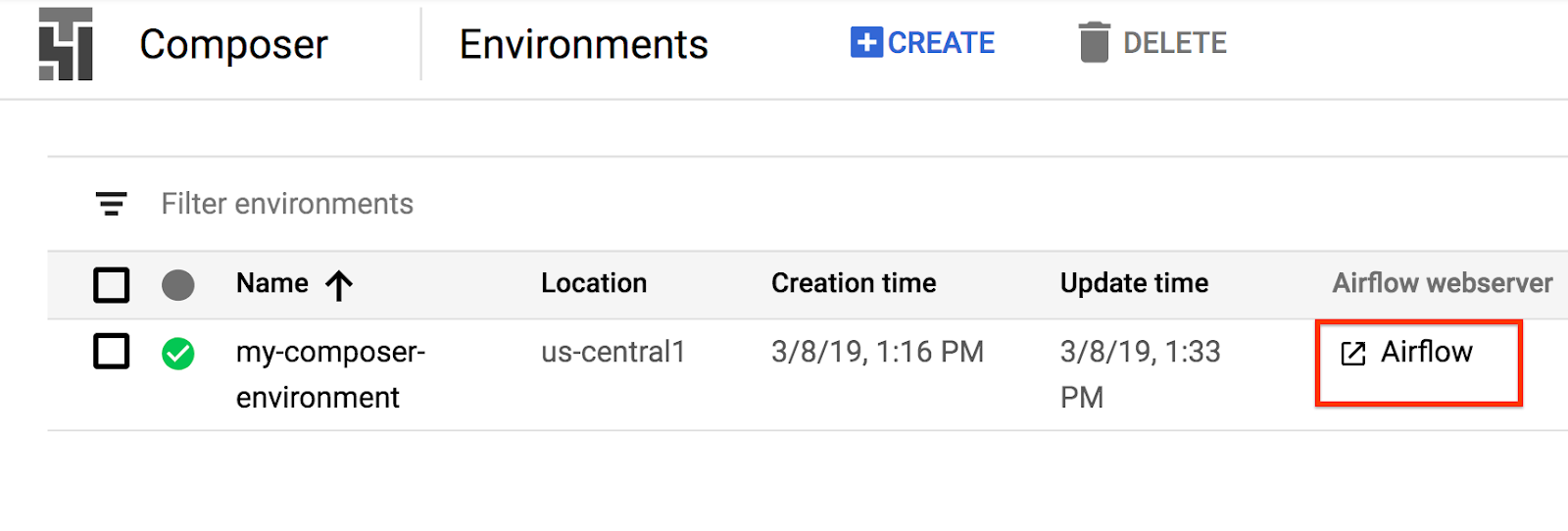
ดูข้อมูลเกี่ยวกับ UI ของ Airflow ได้ที่การเข้าถึงอินเทอร์เฟซเว็บ
ดูตัวแปร
ตัวแปรที่คุณตั้งค่าไว้ก่อนหน้านี้จะยังคงอยู่ในสภาพแวดล้อม คุณสามารถดูตัวแปรได้โดยเลือกผู้ดูแลระบบ > ตัวแปรจากแถบเมนูของ UI ใน Airflow

การสำรวจการเรียกใช้ DAG
เมื่อคุณอัปโหลดไฟล์ DAG ไปยังโฟลเดอร์ dags ใน Cloud Storage แล้ว Cloud Composer จะแยกวิเคราะห์ไฟล์นั้น หากไม่พบข้อผิดพลาด ชื่อของเวิร์กโฟลว์จะปรากฏในรายการ DAG และเวิร์กโฟลว์จะอยู่ในคิวเพื่อเรียกใช้ทันที หากต้องการดู DAG ให้คลิก DAG ที่ด้านบนของหน้า
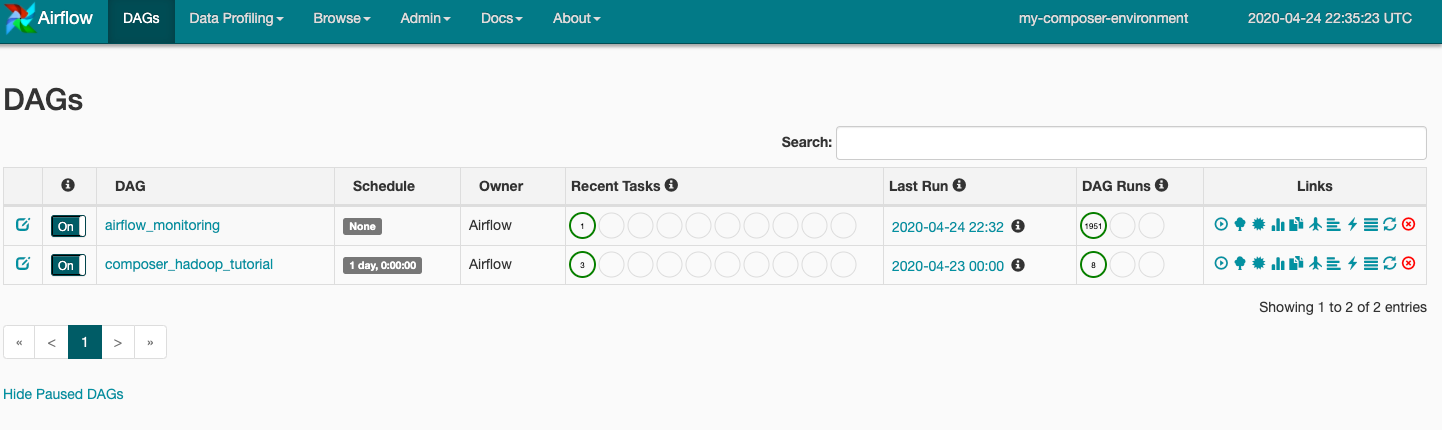
คลิก composer_hadoop_tutorial เพื่อเปิดหน้ารายละเอียด DAG หน้านี้จะมีการนำเสนองานเวิร์กโฟลว์และทรัพยากร Dependency แบบกราฟิก
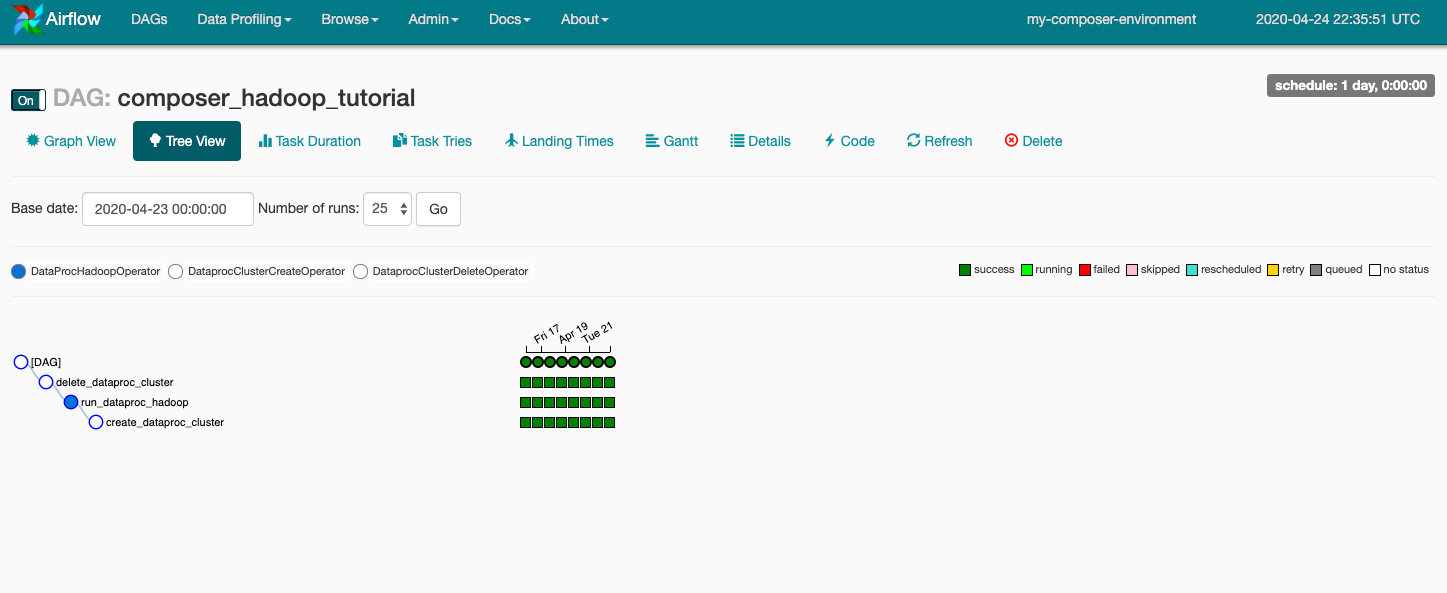
จากนั้นคลิกมุมมองกราฟในแถบเครื่องมือ แล้ววางเมาส์เหนือกราฟิกของแต่ละงานเพื่อดูสถานะ โปรดทราบว่าเส้นขอบรอบแต่ละงานจะระบุสถานะด้วย (เส้นขอบสีเขียว = กำลังทำงาน; สีแดง = ล้มเหลว ฯลฯ)
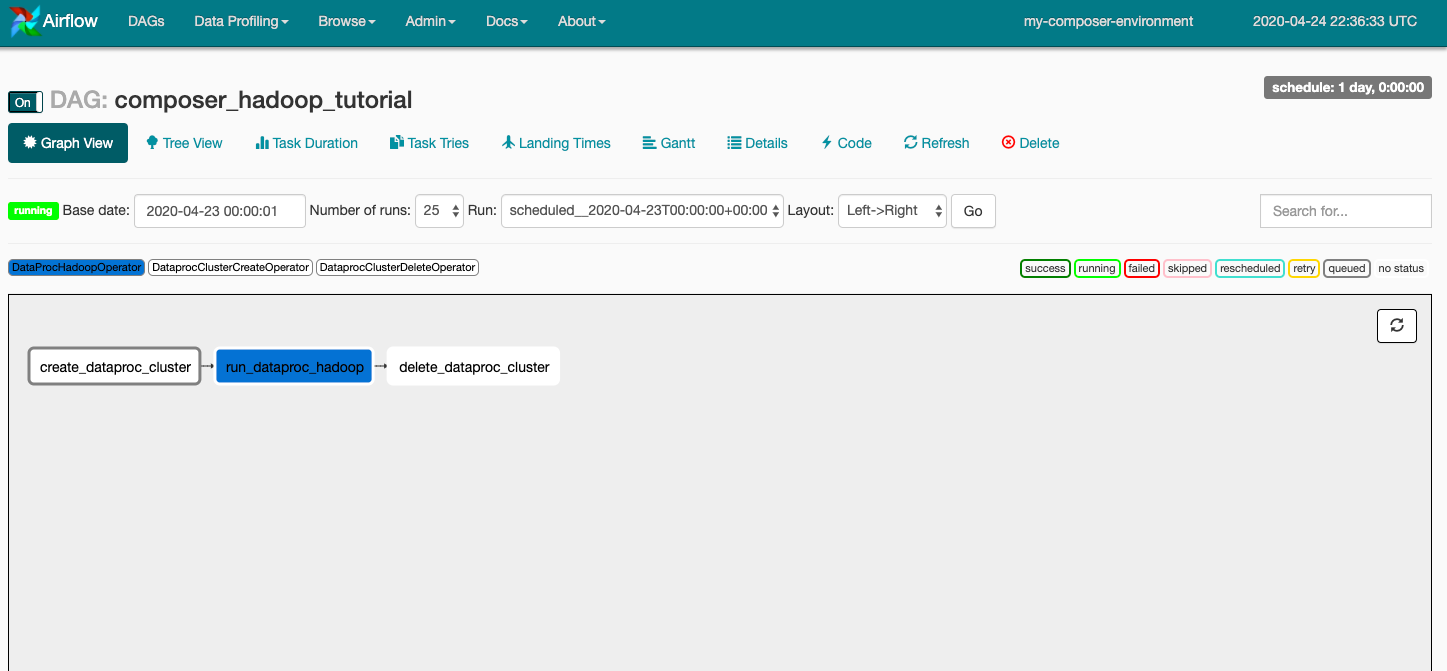
หากต้องการเรียกใช้เวิร์กโฟลว์อีกครั้งจากมุมมองกราฟ ให้ทำดังนี้
- ในมุมมองกราฟ UI ของ Airflow ให้คลิกกราฟิก
create_dataproc_cluster - คลิกล้างเพื่อรีเซ็ตงานทั้ง 3 รายการ แล้วคลิกตกลงเพื่อยืนยัน
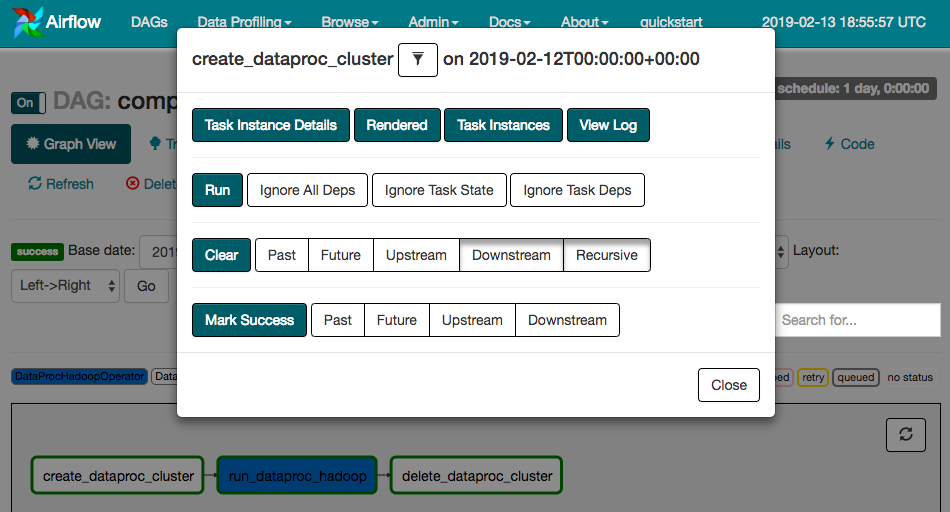
นอกจากนี้ คุณยังตรวจสอบสถานะและผลลัพธ์ของเวิร์กโฟลว์ composer-hadoop-tutorial ได้โดยไปที่หน้าคอนโซล GCP ต่อไปนี้
- คลัสเตอร์ Cloud Dataproc เพื่อตรวจสอบการสร้างและการลบคลัสเตอร์ โปรดทราบว่าคลัสเตอร์ที่สร้างโดยเวิร์กโฟลว์เป็นแบบชั่วคราว ซึ่งมีอยู่ในช่วงเวลาของเวิร์กโฟลว์เท่านั้นและจะถูกลบเป็นส่วนหนึ่งของงานเวิร์กโฟลว์ล่าสุด
- งาน Cloud Dataproc เพื่อดูหรือตรวจสอบงานจำนวนคำของ Apache Hadoop คลิกรหัสงานเพื่อดูเอาต์พุตบันทึกงาน
- เบราว์เซอร์ Cloud Storage เพื่อดูผลลัพธ์ของจำนวนคำในโฟลเดอร์
wordcountในที่เก็บข้อมูล Cloud Storage ที่คุณสร้างขึ้นสำหรับ Codelab นี้
7. ล้างข้อมูล
โปรดทำดังนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี GCP สำหรับทรัพยากรที่ใช้ใน Codelab นี้
- (ไม่บังคับ) หากต้องการบันทึกข้อมูล ให้ดาวน์โหลดข้อมูลจากที่เก็บข้อมูล Cloud Storage สำหรับสภาพแวดล้อม Cloud Composer และที่เก็บข้อมูลของพื้นที่เก็บข้อมูลที่คุณสร้างขึ้นสำหรับ Codelab นี้
- ลบที่เก็บข้อมูล Cloud Storage ที่คุณสร้างไว้สำหรับ Codelab นี้
- ลบที่เก็บข้อมูล Cloud Storage สำหรับสภาพแวดล้อม
- ลบสภาพแวดล้อม Cloud Composer โปรดทราบว่าการลบสภาพแวดล้อมจะไม่ลบที่เก็บข้อมูลของพื้นที่เก็บข้อมูลสำหรับสภาพแวดล้อมนั้น
นอกจากนี้ คุณยังเลือกลบโปรเจ็กต์ได้ด้วย โดยทำดังนี้
- ในคอนโซล GCP ให้ไปที่หน้าโปรเจ็กต์
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในช่อง ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเครื่องเพื่อลบโปรเจ็กต์