
1. Wprowadzenie
Przepływy pracy to typowy przypadek użycia w analizie danych – obejmują one pozyskiwanie, przekształcanie i analizowanie danych w celu znalezienia w nich istotnych informacji. Narzędziem do administrowania przepływami pracy w Google Cloud Platform jest Cloud Composer – hostowana wersja popularnego narzędzia open source do zarządzania przepływami pracy Apache Airflow. W tym module za pomocą usługi Cloud Composer utworzysz prosty przepływ pracy, który utworzy klaster Cloud Dataproc, przeanalizuje go przy użyciu Cloud Dataproc i Apache Hadoop, a potem usunie klaster Cloud Dataproc.
Co to jest Cloud Composer?
Cloud Composer to w pełni zarządzana usługa administrowania przepływami pracy, która umożliwia tworzenie, planowanie i monitorowanie potoków obejmujących chmury i lokalne centra danych. Cloud Composer to usługa, która powstała na podstawie popularnego projektu open source Apache Airflow i jest obsługiwana w języku programowania Python. Nie wymaga blokady i jest łatwa w obsłudze.
Dzięki użyciu Cloud Composer zamiast lokalnej instancji Apache Airflow użytkownicy mogą korzystać z najlepszych funkcji Airflow bez dodatkowych kosztów związanych z instalacją czy zarządzaniem.
Co to jest Apache Airflow?
Apache Airflow to narzędzie typu open source służące do programowego tworzenia, planowania i monitorowania przepływów pracy. W trakcie modułu warto pamiętać o kilku kluczowych terminach związanych z Airflow:
- DAG – DAG (kierowany acykliczny wykres) to zbiór uporządkowanych zadań, które chcesz zaplanować i uruchomić. DAG-i, zwane też przepływami pracy, są zdefiniowane w standardowych plikach w Pythonie.
- Operator – operator opisujący pojedyncze zadanie w przepływie pracy.
Co to jest Cloud Dataproc?
Cloud Dataproc to w pełni zarządzana usługa Apache Spark i Apache Hadoop w Google Cloud Platform. Cloud Dataproc łatwo integruje się z innymi usługami GCP, co zapewnia wydajną i kompleksową platformę do przetwarzania danych, analizy i uczenia maszynowego.
Czynności wykonane
Z tego ćwiczenia w Codelabs dowiesz się, jak utworzyć i uruchomić przepływ pracy Apache Airflow w Cloud Composer, który wykonuje te zadania:
- Tworzy klaster Cloud Dataproc
- Uruchamia w klastrze zadanie liczby słów Apache Hadoop i przesyła jego wyniki do Cloud Storage
- Usuwa klaster
Czego się nauczysz
- Jak utworzyć i uruchomić przepływ pracy Apache Airflow w Cloud Composer
- Jak przeprowadzać analizy w zbiorze danych za pomocą usług Cloud Composer i Cloud Dataproc
- Jak uzyskać dostęp do środowiska Cloud Composer za pomocą konsoli Google Cloud Platform, pakietu SDK Cloud i interfejsu internetowego Airflow
Czego potrzebujesz
- Konto GCP
- Podstawowa wiedza o interfejsie wiersza poleceń
- Podstawowa znajomość języka Python
2. Konfigurowanie GCP
Tworzenie projektu
Wybierz lub utwórz projekt Google Cloud Platform.
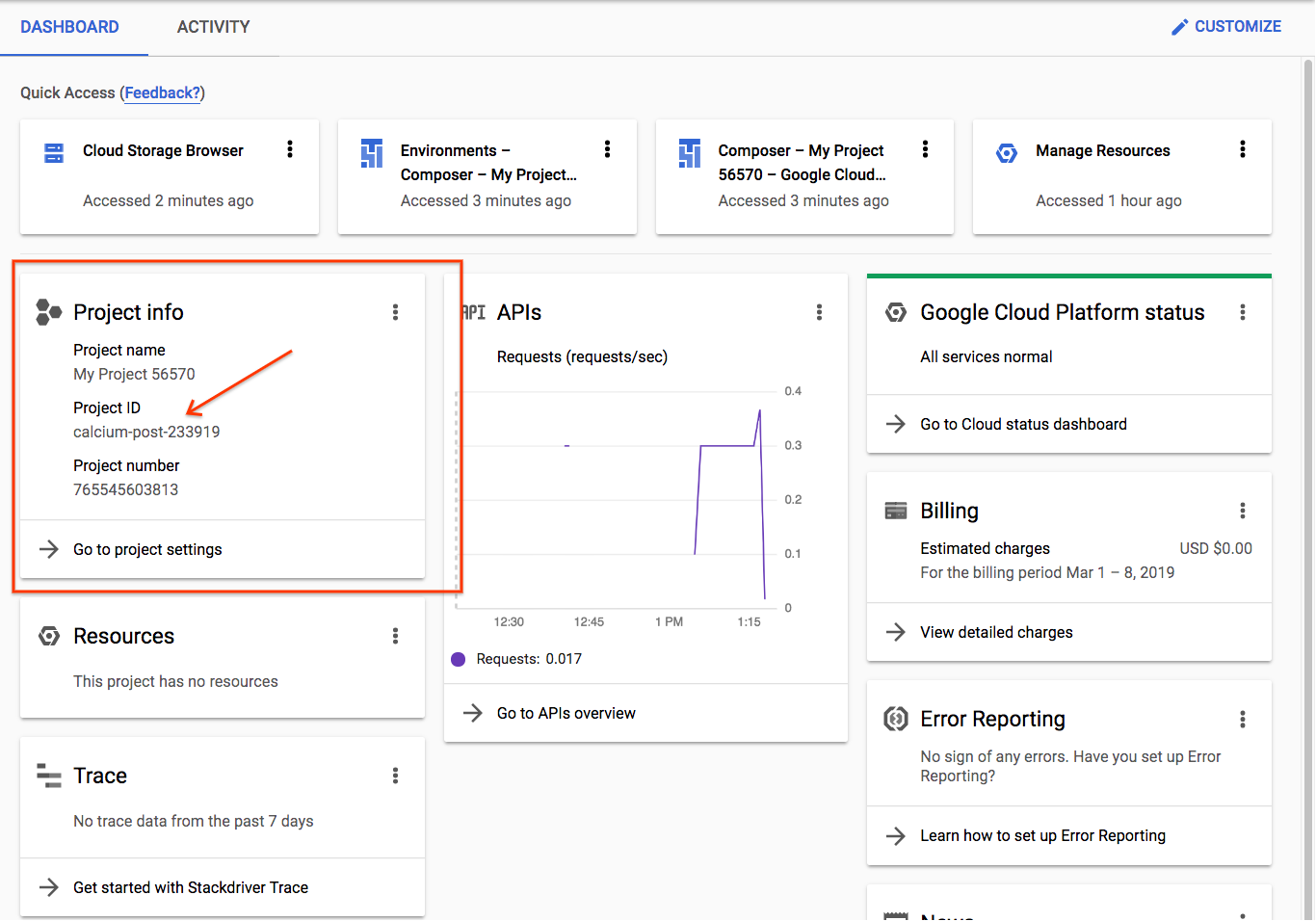
Zapisz identyfikator projektu. Użyjesz go w kolejnych krokach.
Jeśli tworzysz nowy projekt, jego identyfikator znajduje się tuż pod jego nazwą na stronie tworzenia. |
|
Jeśli masz już utworzony projekt, identyfikator znajdziesz na stronie głównej konsoli na karcie Informacje o projekcie. |
|

Włączanie interfejsów API
Włącz interfejsy API Cloud Composer, Cloud Dataproc i Cloud Storage. Po ich włączeniu możesz zignorować przycisk „Otwórz dane logowania”. i przejdź do następnego kroku samouczka. |
|


Tworzenie środowiska Composer
Utwórz środowisko Cloud Composer o tej konfiguracji:
Wszystkie inne konfiguracje mogą pozostać domyślne. Kliknij „Utwórz”. na dole. |
|

Tworzenie zasobnika Cloud Storage
Utwórz w projekcie zasobnik Cloud Storage o tej konfiguracji:
Kliknij „Utwórz”. gdy wszystko będzie gotowe |
|

3. Konfigurowanie Apache Airflow
Wyświetlanie informacji o środowisku Composer
W konsoli GCP otwórz stronę Środowiska.
Kliknij nazwę środowiska, aby wyświetlić jego szczegóły.
Strona Szczegóły środowiska zawiera informacje takie jak URL interfejsu internetowego Airflow, identyfikator klastra Google Kubernetes Engine, nazwa zasobnika Cloud Storage i ścieżka do folderu /dags.
W Airflow DAG (kierowany acykliczny wykres) to zbiór uporządkowanych zadań, które chcesz zaplanować i uruchomić. DAG-i, zwane też przepływami pracy, są zdefiniowane w standardowych plikach Pythona. Cloud Composer planuje tylko DAG-i w folderze /dags. Folder /dags znajduje się w zasobniku Cloud Storage, który Cloud Composer tworzy automatycznie podczas tworzenia środowiska.
Ustawianie zmiennych środowiskowych Apache Airflow
Zmienne Apache Airflow to specyficzna koncepcja Airflow, która różni się od zmiennych środowiskowych. W tym kroku skonfigurujesz te 3 zmienne Airflow: gcp_project, gcs_bucket i gce_zone.
Użycie parametru gcloud do ustawiania zmiennych
Najpierw otwórz Cloud Shell, do której masz wygodny zainstalowany pakiet SDK Cloud.
Ustaw zmienną środowiskową COMPOSER_INSTANCE na nazwę środowiska Composer
COMPOSER_INSTANCE=my-composer-environment
Aby ustawić zmienne Airflow za pomocą narzędzia wiersza poleceń gcloud, użyj polecenia gcloud composer environments run z poleceniem podrzędnym variables. To polecenie gcloud composer wykonuje podrzędne polecenie interfejsu wiersza poleceń Airflow variables. Polecenie podrzędne przekazuje argumenty do narzędzia wiersza poleceń gcloud.
Uruchom to polecenie 3 razy, zastępując zmienne tymi, które są istotne dla Twojego projektu.
Ustaw gcp_project za pomocą tego polecenia, zastępując fragment <identyfikator-projektu> identyfikatorem projektu zapisanym w kroku 2.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
Dane wyjściowe będą wyglądać mniej więcej tak
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
Ustaw gcs_bucket za pomocą tego polecenia, zastępując <your-bucket-name> identyfikatorem zasobnika zanotowanymi w kroku 2. Jeśli jest on zgodny z naszym zaleceniem, nazwa zasobnika jest taka sama jak identyfikator projektu. Dane wyjściowe będą podobne jak w przypadku poprzedniego polecenia.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
Ustaw gce_zone za pomocą tego polecenia. Dane wyjściowe będą podobne do poprzednich poleceń.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(Opcjonalnie) Używanie funkcji gcloud do wyświetlania zmiennej
Aby zobaczyć wartość zmiennej, uruchom podrzędne polecenie interfejsu wiersza poleceń Airflow variables z argumentem get lub użyj interfejsu Airflow.
Na przykład:
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
Możesz to zrobić za pomocą dowolnej z 3 ustawionych właśnie zmiennych: gcp_project, gcs_bucket lub gce_zone.
4. Przykładowy przepływ pracy
Spójrzmy na kod DAG-a, którego użyjemy w kroku 5. Nie martw się jeszcze o pobieranie plików – postępuj zgodnie z instrukcjami poniżej.
Jest tu sporo rzeczy do rozpakowania, więc omówimy nieco ten temat.
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
Zaczynamy od importów z Airflow:
airflow.models– umożliwia nam uzyskiwanie dostępu do danych w bazie danych Airflow i ich tworzenie.airflow.contrib.operators– gdzie mieszkają operatorzy ze społeczności. W tym przypadku potrzebujesz dostępu do interfejsu Cloud Dataproc API:dataproc_operator.airflow.utils.trigger_rule– służy do dodawania reguł aktywujących do naszych operatorów. Reguły reguły umożliwiają szczegółową kontrolę nad tym, czy operator powinien być wykonywany w odniesieniu do stanu elementów nadrzędnych.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
Określa lokalizację pliku wyjściowego. Warto zauważyć tutaj wiersz models.Variable.get('gcs_bucket'), który pobierze wartość zmiennej gcs_bucket z bazy danych Airflow.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR– lokalizacja pliku .jar, który ostatecznie uruchomimy w klastrze Cloud Dataproc. Jest już dla Ciebie hostowany w GCP.input_file– lokalizacja pliku zawierającego dane, które zadanie Hadoop będzie w przyszłości obliczać. Dane zostaną przesłane do tej lokalizacji razem w kroku 5.wordcount_args– argumenty, które przekażemy do pliku jar.
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
Otrzymasz odpowiednik obiektu daty i godziny reprezentującego północ poprzedniego dnia. Jeśli na przykład polecenie zostanie wykonane 4 marca o 11:00, obiekt datetime będzie wskazywał godzinę 00:00 3 marca. Ma to związek ze sposobem, w jaki Airflow obsługuje planowanie. Więcej informacji na ten temat znajdziesz tutaj.
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
Zmienna default_dag_args w postaci słownika należy podawać za każdym razem, gdy tworzony jest nowy DAG:
'email_on_failure'– wskazuje, czy mają być wysyłane alerty e-mail w przypadku niepowodzenia zadania.'email_on_retry'– wskazuje, czy mają być wysyłane alerty e-mail po ponownym wykonaniu zadania.'retries'– wskazuje, ile ponownych prób ma wykonać Airflow w przypadku awarii DAG-a.'retry_delay'– wskazuje, jak długo Airflow ma czekać przed ponowną próbą.'project_id'– informuje DAG-a, z którym identyfikatorem projektu GCP ma być powiązany, który będzie potrzebny później operatorowi Dataproc.
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
Użycie dyrektywy with models.DAG powoduje, że skrypt ma umieścić wszystkie elementy znajdujące się poniżej w tym samym DAG-u. Widzimy również 3 przekazywane argumenty:
- Pierwszy z nich to ciąg znaków. To nazwa, która nadaje DAG-owi, który tworzymy. W tym przypadku używamy
composer_hadoop_tutorial. schedule_interval– obiektdatetime.timedelta, który w tym miejscu został ustawiony na 1 dzień. Oznacza to, że ten DAG będzie próbował uruchamiać się raz dziennie po ustawieniu'start_date', które zostało ustawione wcześniej w'default_dag_args'default_args– utworzony wcześniej słownik zawierający domyślne argumenty DAG-a.
Tworzenie klastra Dataproc
Następnie utworzymy dataproc_operator.DataprocClusterCreateOperator, który utworzy klaster Cloud Dataproc.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
W tym operatorze widocznych jest kilka argumentów, z których wszystkie oprócz pierwszego są związane z tym operatorem:
task_id– tak jak w przypadku BashOperator, jest to nazwa przypisana do operatora i widoczna w interfejsie Airflow.cluster_name– nazwa, którą przypisujemy klastrowi Cloud Dataproc. Nazwaliśmy jącomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(dodatkowe informacje znajdziesz w polu informacyjnym)num_workers– liczba instancji roboczych, które są przydzielone do klastra Cloud Dataproczone– region geograficzny, w którym ma działać klaster, zapisany w bazie danych Airflow. Spowoduje to odczytanie zmiennej'gce_zone'ustawionej w kroku 3master_machine_type– typ maszyny, którą chcesz przydzielić do mastera Cloud Dataprocworker_machine_type– typ maszyny, którą chcesz przydzielić do instancji roboczej Cloud Dataproc
Przesyłanie zadania Apache Hadoop
dataproc_operator.DataProcHadoopOperator umożliwia nam przesłanie zadania do klastra Cloud Dataproc.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
Udostępniamy kilka parametrów:
task_id– nazwa przypisana do tego elementu DAG-amain_jar– lokalizacja pliku .jar, który ma być uruchamiany w klastrze.cluster_name– nazwa klastra, w którego przypadku chcesz uruchomić zadanie. Zauważysz, że jest taka sama jak w poprzednim operatorze.arguments– argumenty, które są przekazywane do pliku jar w taki sam sposób jak w przypadku wykonywania pliku jar z poziomu wiersza poleceń.
Usuwanie klastra
Ostatni operator, który utworzymy, to dataproc_operator.DataprocClusterDeleteOperator.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
Jak wskazuje nazwa, ten operator usuwa dany klaster Cloud Dataproc. Występują tu 3 argumenty:
task_id– tak jak w przypadku BashOperator, jest to nazwa przypisana do operatora i widoczna w interfejsie Airflow.cluster_name– nazwa, którą przypisujemy klastrowi Cloud Dataproc. Teraz nazywamy gocomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(opcjonalne dodatkowe informacje znajdziesz w polu informacji po „Utwórz klaster Dataproc”).trigger_rule– na początku tego kroku omówiliśmy krótko reguły aktywatorów, ale oto chodzi o działanie. Domyślnie operator Airflow nie jest wykonywany, dopóki wszystkie jego operatory nadrzędne nie zostaną ukończone. Reguła aktywatoraALL_DONEwymaga tylko wykonania wszystkich operatorów nadrzędnych niezależnie od tego, czy zostały one wykonane. W tym przypadku oznacza to, że nawet jeśli zadanie Hadoop się nie uda, nadal chcemy zniszczyć klaster.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Na koniec chcemy, aby operatory te były wykonywane w określonej kolejności, i możemy to wskazać za pomocą operatorów przesunięcia bitowego w języku Python. W tym przypadku jako pierwszy zostanie wykonany kod create_dataproc_cluster, potem run_dataproc_hadoop, a na koniec delete_dataproc_cluster.
Po połączeniu tego kod wygląda tak:
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. Przesyłanie plików Airflow do Cloud Storage
Skopiuj DAG-a do folderu /dags
- Najpierw otwórz Cloud Shell, do której masz wygodny zainstalowany pakiet SDK Cloud.
- Sklonuj repozytorium przykładów Pythona i przejdź do katalogu kompozytor/przepływy pracy
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- Uruchom to polecenie, aby ustawić nazwę folderu DAG-ów na zmienną środowiskową
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- Uruchom to polecenie
gsutil, aby skopiować kod samouczka do miejsca tworzenia folderu /dags
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
Dane wyjściowe będą wyglądać mniej więcej tak:
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. Za pomocą interfejsu Airflow
Aby uzyskać dostęp do interfejsu internetowego Airflow za pomocą konsoli GCP:
|
|
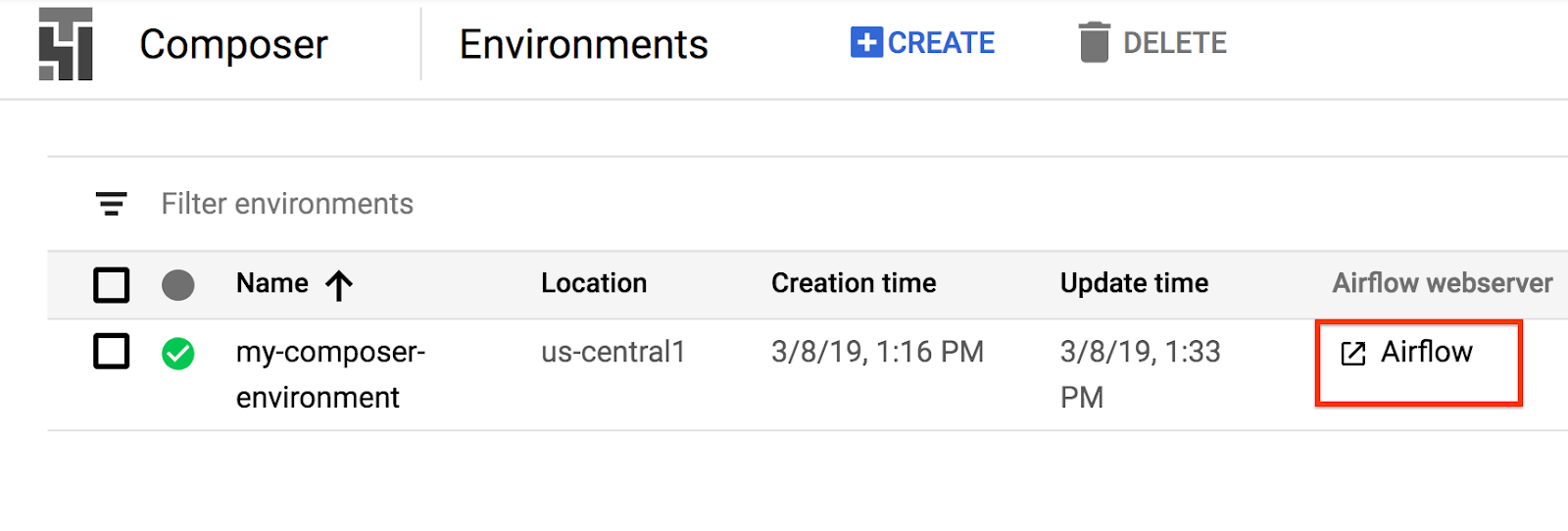
Informacje o interfejsie Airflow znajdziesz w artykule Uzyskiwanie dostępu do interfejsu internetowego.
Wyświetl zmienne
Ustawione wcześniej zmienne są zachowywane w Twoim środowisku. Zmienne możesz wyświetlić, wybierając Administracja > Zmienne na pasku menu interfejsu Airflow.

Informacje o uruchomieniach DAG-ów
Gdy przesyłasz plik DAG do folderu dags w Cloud Storage, Cloud Composer analizuje plik. Jeśli nie zostaną znalezione żadne błędy, nazwa przepływu pracy pojawi się na liście DAG-a, a przepływ pracy zostanie umieszczony w kolejce do natychmiastowego uruchomienia. Aby wyświetlić DAG-i, kliknij DAG-i u góry strony.
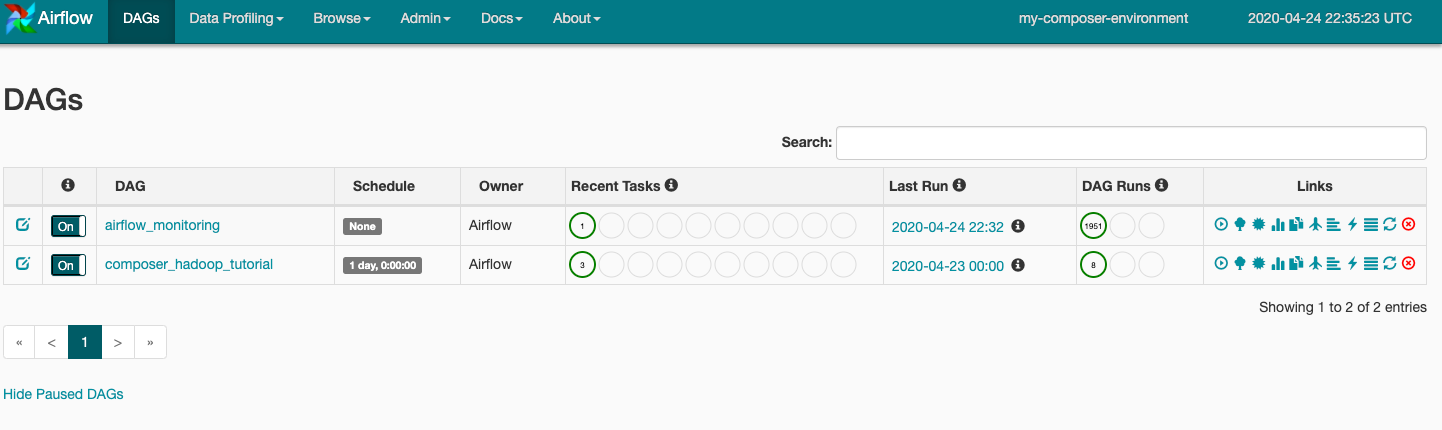
Kliknij composer_hadoop_tutorial, aby otworzyć stronę z informacjami o DAG-u. Ta strona zawiera graficzne przedstawienie zadań i zależności przepływu pracy.

Teraz na pasku narzędzi kliknij Widok wykresu i najedź myszą na grafikę każdego zadania, by zobaczyć jego stan. Pamiętaj, że obramowanie wokół każdego zadania wskazuje też jego stan (zielone obramowanie = uruchomione, czerwone = niepowodzenie itd.).
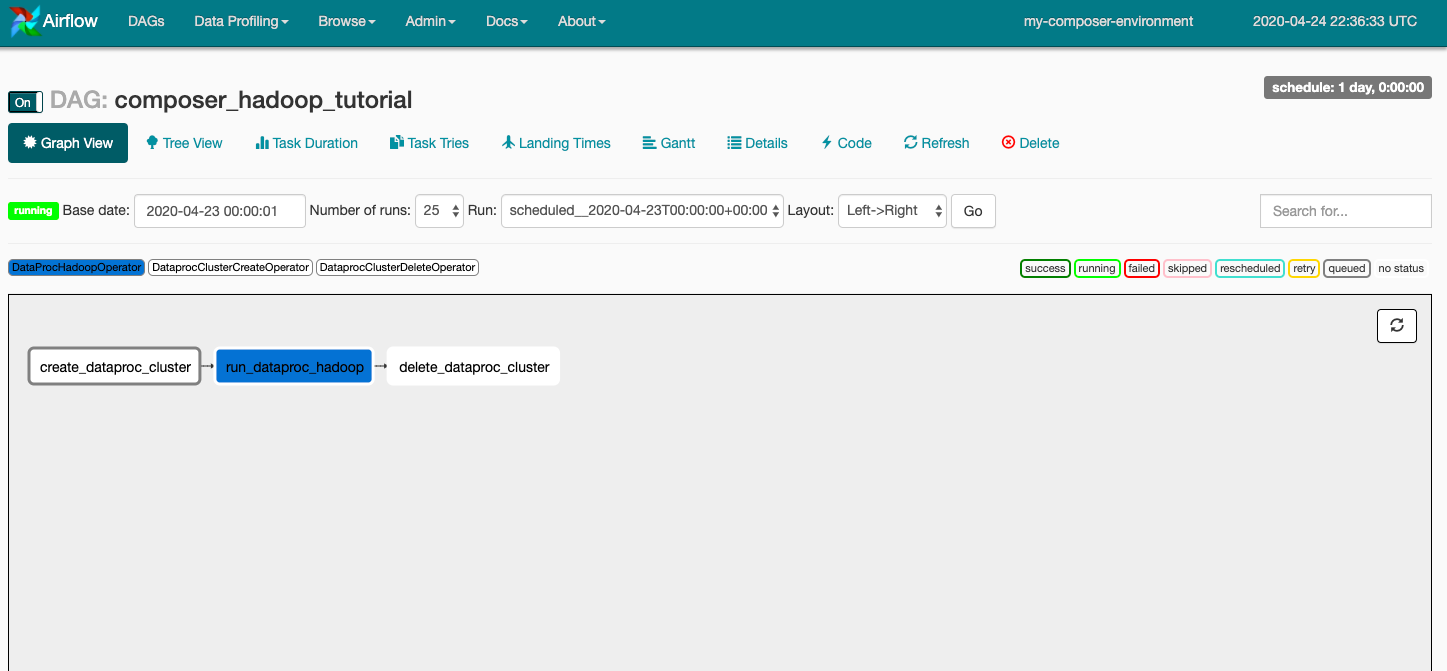
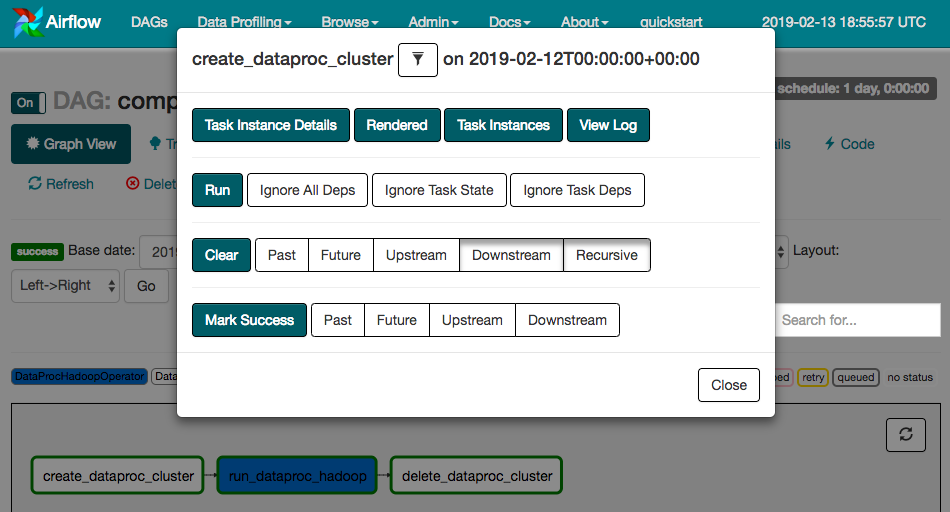
Aby ponownie uruchomić przepływ pracy w widoku wykresu:
- W widoku wykresu interfejsu Airflow kliknij ikonę
create_dataproc_cluster. - Kliknij Wyczyść, aby zresetować te 3 zadania, a następnie kliknij OK, aby potwierdzić tę czynność.
Stan i wyniki przepływu pracy w composer-hadoop-tutorial możesz też sprawdzić na tych stronach konsoli GCP:
- Klastry Cloud Dataproc do monitorowania tworzenia i usuwania klastrów. Pamiętaj, że klaster utworzony przez przepływ pracy jest tymczasowy: istnieje tylko przez czas trwania przepływu pracy i jest usuwany w ramach ostatniego zadania przepływu pracy.
- Zadania Cloud Dataproc umożliwiające wyświetlanie lub monitorowanie zadania Apache Hadoop Wordcount. Kliknij identyfikator zadania, aby wyświetlić dane wyjściowe logu zadania.
- Przeglądarka Cloud Storage, aby wyświetlić wyniki liczby słów w folderze
wordcountw zasobniku Cloud Storage utworzonym w ramach tego ćwiczenia.
7. Czyszczenie
Aby uniknąć obciążenia konta GCP opłatami za zasoby zużyte w tym ćwiczeniu z programowania:
- (Opcjonalnie) Aby zapisać swoje dane, pobierz je z zasobnika Cloud Storage środowiska Cloud Composer i zasobnika na dane utworzonego w ramach tego ćwiczenia z programowania.
- Usuń zasobnik Cloud Storage utworzony na potrzeby tego ćwiczenia z programowania.
- Usuń zasobnik Cloud Storage dla środowiska.
- Usuń środowisko Cloud Composer. Pamiętaj, że usunięcie środowiska nie powoduje usunięcia jego zasobnika na dane.
Możesz też opcjonalnie usunąć projekt:
- W konsoli GCP otwórz stronę Projekty.
- Na liście projektów wybierz projekt do usunięcia, a następnie kliknij Usuń.
- W polu wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.