
1. はじめに
ワークフローはデータ分析における一般的なユースケースです。データの取り込み、変換、分析を行い、データから有益な情報を見つけ出します。Google Cloud Platform では、ワークフローをオーケストレートするためのツールとして Cloud Composer が用意されています。これは、よく利用されているオープンソース ワークフロー ツール Apache Airflow のホスト型バージョンです。このラボでは、Cloud Composer を使用して簡単なワークフローを作成します。Cloud Dataproc クラスタの作成、Cloud Dataproc と Apache Hadoop による分析、Cloud Dataproc クラスタの削除は、Cloud Composer を使用して行います。
Cloud Composer とは
Cloud Composer は、フルマネージドなワークフロー オーケストレーション サービスです。クラウドとオンプレミス データセンターにまたがるパイプラインの作成、スケジューリング、モニタリングを実現します。Cloud Composer は、広く利用されている Apache Airflow のオープンソース プロジェクト上に構築され、Python プログラミング言語を使用して運用されています。特定のベンダーに縛られることがなく、簡単に使用できます。
Apache Airflow のローカル インスタンスの代わりに Cloud Composer を使用することで、ユーザーはインストールや管理のオーバーヘッドなしに Airflow の長所を活用できます。
Apache Airflow とは
Apache Airflow は、ワークフローの作成、スケジューリング、モニタリングをプログラムで行うために使用されるオープンソース ツールです。このラボ全体を通して、Airflow に関連して覚えておくべき重要な用語がいくつかあります。
- DAG - DAG(有向非巡回グラフ)は、スケジュールを設定して実行する整理されたタスクの集まりです。ワークフローとも呼ばれる DAG は標準の Python ファイルで定義される
- オペレーター - ワークフロー内の単一のタスクを記述します
Cloud Dataproc とは何ですか?
Cloud Dataproc は、Google Cloud Platform のフルマネージド Apache Spark および Apache Hadoop サービスです。Cloud Dataproc は他の GCP サービスと簡単に統合できるため、データ処理、分析、ML のための高度で包括的なプラットフォームとして使用できます。
演習内容
この Codelab では、次のタスクを完了する Apache Airflow ワークフローを Cloud Composer で作成して実行する方法について説明します。
- Cloud Dataproc クラスタを作成する
- Apache Hadoop ワードカウント ジョブをクラスタで実行し、その結果を Cloud Storage に出力する
- クラスタを削除します。
学習内容
- Cloud Composer で Apache Airflow ワークフローを作成して実行する方法
- Cloud Composer と Cloud Dataproc を使用してデータセットで分析を実行する方法
- Google Cloud Platform コンソール、Cloud SDK、Airflow ウェブ インターフェースを介して Cloud Composer 環境にアクセスする方法
必要なもの
- GCP アカウント
- CLI の基本的な知識
- Python の基本的な理解
2. GCP の設定
プロジェクトを作成する
Google Cloud Platform プロジェクトを選択または作成します。
プロジェクト ID をメモしておきます。この ID は後のステップで使用します。
新しいプロジェクトを作成する場合、プロジェクト ID は作成ページのプロジェクト名のすぐ下に表示されます。 |
|
すでにプロジェクトを作成している場合は、コンソールのホームページのプロジェクト情報カードで ID を確認できます。 |
|


API を有効にする
Cloud Composer、Cloud Dataproc、Cloud Storage API を有効にします。これらの API が有効になったら、[認証情報に進む] ボタンは無視してかまいません。チュートリアルの次のステップに進みます |
|


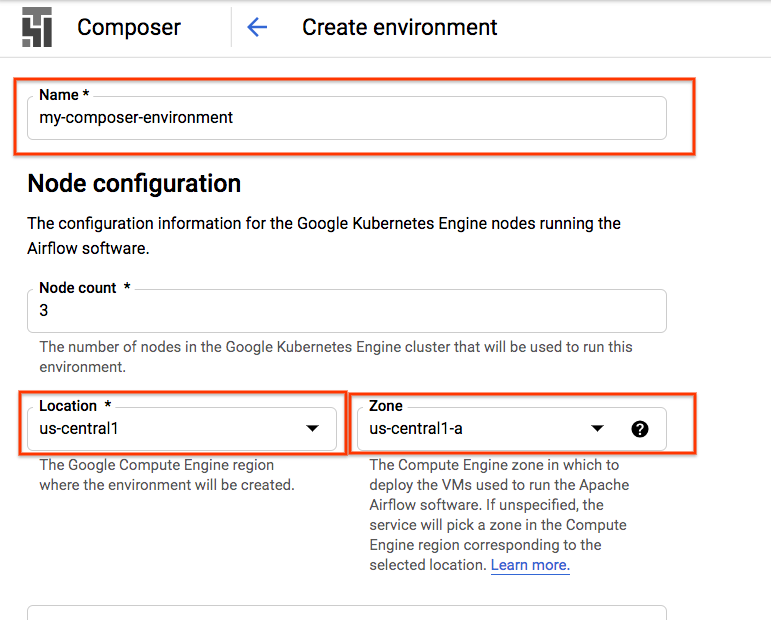
Composer 環境を作成する
次の構成で Cloud Composer 環境を作成します。
その他の構成はすべてデフォルトのままにできます。[作成] をクリックします] をクリックします。 |
|

Cloud Storage バケットを作成する
プロジェクトで、Cloud Storage バケットを作成して次の構成にします。
[作成] をクリックします。準備ができたら |
|

3. Apache Airflow の設定
Composer 環境情報の表示
GCP Console で、[環境] ページを開きます。
環境の名前をクリックして、詳細を表示します。
[環境の詳細] ページには、Airflow ウェブ インターフェースの URL、Google Kubernetes Engine クラスタ ID、Cloud Storage バケットの名前、/dags フォルダのパスなどの情報が表示されます。
Airflow における DAG(有向非巡回グラフ)とは、スケジュールを設定して実行する、整理されたタスクの集まりです。DAG はワークフローとも呼ばれ、標準の Python ファイルで定義されます。Cloud Composer では、/dags フォルダ内の DAG のみがスケジュール設定されます。/dags フォルダは、環境の作成時に Cloud Composer によって自動的に作成される Cloud Storage バケット内にあります。
Apache Airflow の環境変数の設定
Apache Airflow 変数は Airflow 固有のコンセプトであり、環境変数とは異なります。このステップでは、gcp_project、gcs_bucket、gce_zone の 3 つの Airflow 変数を設定します。
gcloud を使用した変数の設定
まず、Cloud SDK がインストールされている Cloud Shell を開きます。
環境変数 COMPOSER_INSTANCE を Composer 環境の名前に設定する
COMPOSER_INSTANCE=my-composer-environment
gcloud コマンドライン ツールを使用して Airflow 変数を設定するには、variables サブコマンドで gcloud composer environments run コマンドを使用します。この gcloud composer コマンドは、Airflow CLI サブコマンド variables を実行します。サブコマンドは、引数を gcloud コマンドライン ツールに渡します。
このコマンドを 3 回実行し、変数をプロジェクトに関連する変数に置き換えます。
次のコマンドを使用して gcp_project を設定します。<your-project-id> は、プロジェクト ID に置き換えます。
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
出力は次のようになります。
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
次のコマンドを使用して gcs_bucket を設定します。<your-bucket-name> は、ステップ 2 でメモしたバケット ID に置き換えます。Google の推奨事項に従っている場合、バケット名はプロジェクト ID と同じになります。出力は前のコマンドのようになります。
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
次のコマンドを使用して gce_zone を設定します。出力は前のコマンドと同様です。
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(省略可)gcloud を使用して変数を表示
変数の値を表示するには、Airflow CLI サブコマンド variables に get 引数を指定して実行するか、Airflow UI を使用します。
例:
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
これは、先ほど設定した 3 つの変数(gcp_project、gcs_bucket、gce_zone)のいずれかで行うことができます。
4. サンプル ワークフロー
ステップ 5 で使用する DAG のコードを見てみましょう。まだファイルのダウンロードについて気にせずに、ここでやり遂げてください。
取り上げるべきことがたくさんあるため、少し詳しく見ていきましょう。
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
まず、Airflow のインポートをいくつか紹介します。
airflow.models- Airflow データベースにアクセスしてデータを作成できます。airflow.contrib.operators- コミュニティのオペレーターが住んでいる場所。この例では、Cloud Dataproc API にアクセスするためにdataproc_operatorが必要です。airflow.utils.trigger_rule- 演算子にトリガールールを追加します。トリガールールを使用すると、演算子を親のステータスに関連して実行するかどうかをきめ細かく制御できます。
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
出力ファイルの場所を指定します。ここでの注目すべき行は、Airflow データベースから gcs_bucket 変数値を取得する models.Variable.get('gcs_bucket') です。
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR- 最終的に Cloud Dataproc クラスタで実行する .jar ファイルの場所。これは GCP ですでにホストされています。input_file- Hadoop ジョブが最終的に計算するデータを含むファイルの場所。ステップ 5 で、データをこの場所にアップロードします。wordcount_args- jar ファイルに渡す引数。
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
これにより、前日の午前 0 時を表す datetime オブジェクトがこれに相当します。たとえば、これが 3 月 4 日の 11:00 で実行される場合、datetime オブジェクトは 3 月 3 日の 00:00 を表します。これは、Airflow がスケジューリングを処理する方法に関係します。詳しくは、こちらをご覧ください。
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
新しい DAG が作成されるたびに、辞書形式の default_dag_args 変数を指定する必要があります。
'email_on_failure'- タスクが失敗したときにメール通知アラートを送信するかどうかを指定します。'email_on_retry'- タスクが再試行されたときにメール通知アラートを送信するかどうかを指定します。'retries'- DAG が失敗した場合に Airflow が行う再試行回数を示します。'retry_delay'- 再試行を試行する前に Airflow が待機する時間を示します。'project_id'- 関連付ける GCP プロジェクト ID を DAG に伝えます。この ID は後で Dataproc オペレーターで必要になります。
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
with models.DAG を使用すると、その下にあるすべてを同じ DAG 内に含めるようにスクリプトに指示します。また、3 つの引数が渡されていることがわかります。
- 1 つ目の文字列は、作成する DAG に付ける名前です。この例では
composer_hadoop_tutorialを使用します。 schedule_interval-datetime.timedeltaオブジェクト。ここでは 1 日に設定されています。つまり、この DAG は、'default_dag_args'で設定された'start_date'の後に 1 日 1 回実行が試行されます。default_args- DAG のデフォルト引数を含む、前に作成した辞書
Dataproc クラスタを作成する
次に、Cloud Dataproc クラスタを作成する dataproc_operator.DataprocClusterCreateOperator を作成します。
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
この演算子にはいくつかの引数がありますが、最初の引数以外の引数はすべてこの演算子に固有のものです。
task_id- BashOperator と同様に、これはオペレーターに割り当てる名前で、Airflow UI から表示できます。cluster_name- Cloud Dataproc クラスタに割り当てた名前。ここでは、composer-hadoop-tutorial-cluster-{{ ds_nodash }}という名前を付けます(オプションの追加情報については、情報ボックスをご覧ください)。num_workers- Cloud Dataproc クラスタに割り当てるワーカーの数zone- クラスタを配置する地理的リージョン(Airflow データベース内に保存されます)。これにより、ステップ 3 で設定した'gce_zone'変数が読み取られます。master_machine_type- Cloud Dataproc マスターに割り当てるマシンのタイプworker_machine_type- Cloud Dataproc ワーカーに割り当てるマシンのタイプ
Apache Hadoop ジョブを送信する
dataproc_operator.DataProcHadoopOperator を使用すると、Cloud Dataproc クラスタにジョブを送信できます。
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
いくつかのパラメータが用意されています。
task_id- DAG のこの部分に割り当てる名前main_jar- クラスタに対して実行する .jar ファイルの場所cluster_name- ジョブを実行するクラスタの名前。これは前の演算子で見つかったものと同じです。arguments- コマンドラインから .jar ファイルを実行する場合と同様に、jar ファイルに渡される引数
クラスタを削除する
最後に作成する演算子は dataproc_operator.DataprocClusterDeleteOperator です。
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
名前のとおり、このオペレーターは特定の Cloud Dataproc クラスタを削除します。ここでは 3 つの引数があります。
task_id- BashOperator と同様に、これはオペレーターに割り当てる名前で、Airflow UI から表示できます。cluster_name- Cloud Dataproc クラスタに割り当てた名前。ここでは、composer-hadoop-tutorial-cluster-{{ ds_nodash }}という名前を付けます(オプションの追加情報については、「Dataproc クラスタを作成する」の後に情報ボックスをご覧ください)。trigger_rule- この手順の冒頭で、インポート時にトリガールールについて簡単に触れましたが、ここでは実際のルールを見てみましょう。デフォルトでは、Airflow オペレーターは、上流の演算子がすべて正常に完了しない限り実行されません。ALL_DONEトリガールールでは、成功したかどうかにかかわらず、上流の演算子がすべて完了していることのみが必要です。つまり、Hadoop ジョブが失敗しても、クラスタを破棄する必要があるということです。
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
最後に、これらの演算子を特定の順序で実行したいので、Python のビットシフト演算子を使用してこれを指定できます。この場合、常に create_dataproc_cluster が最初に実行され、その後に run_dataproc_hadoop が実行され、最後に delete_dataproc_cluster が実行されます。
まとめると、コードは次のようになります。
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. Airflow ファイルを Cloud Storage にアップロードする
DAG を /dags フォルダにコピーする
- まず、Cloud SDK がインストールされている Cloud Shell を開きます。
- Python サンプル リポジトリのクローンを作成し、composer/workflows ディレクトリに移動します。
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- 次のコマンドを実行して、DAG フォルダの名前を環境変数に設定します。
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- 次の
gsutilコマンドを実行して、/dags フォルダの作成場所にチュートリアル コードをコピーします
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
出力は次のようになります。
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. Airflow UI を使用する
GCP コンソールを使用して Airflow ウェブ インターフェースにアクセスするには:
|
|

Airflow UI について詳しくは、ウェブ インターフェースへのアクセスをご覧ください。
変数を表示する
先ほど設定した変数は、環境内に保持されています。変数を表示するには、[管理] >Variables] を選択します。
![[List] タブが選択され、キー gcp_project、value: project-id、gcs_bucket、value: gs://bucket-name、key: gce_zone、value: zone を含むテーブルが表示されています。](https://codelabs.developers.google.cn/static/codelabs/intro-cloud-composer/img/a423b1b2d5765962.png?authuser=6&hl=ja "Airflow UI の [Variables] ページ")
DAG の実行状況を確認する
DAG ファイルを Cloud Storage の dags フォルダにアップロードすると、Cloud Composer によってファイルが解析されます。エラーが検出されなかった場合、そのワークフローの名前が DAG のリストに表示され、すぐに実行されるようキューに登録されます。DAG を表示するには、ページの上部にある [DAG] をクリックします。
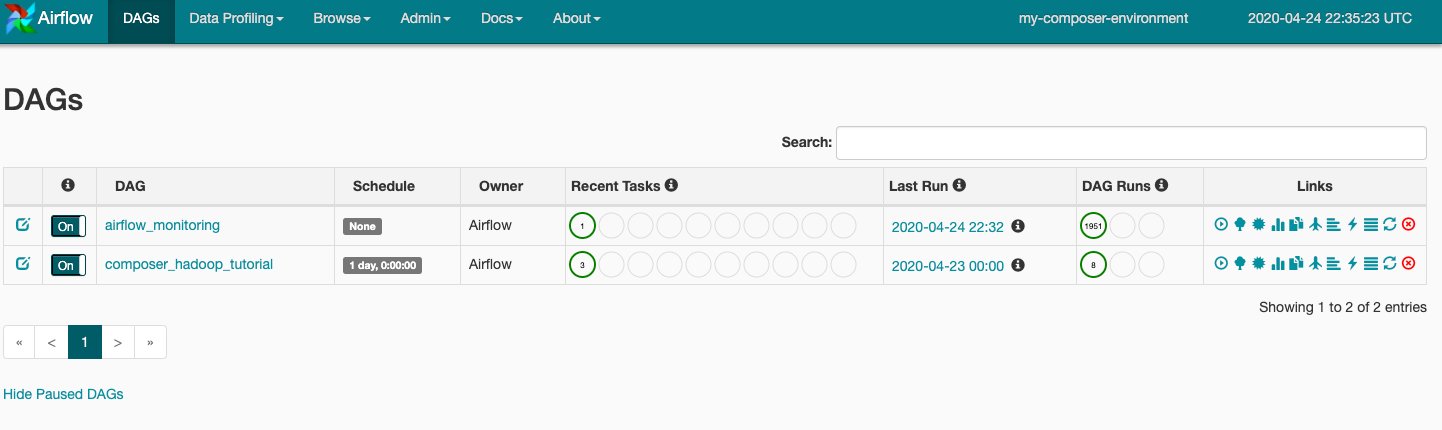
composer_hadoop_tutorial をクリックして DAG の詳細ページを開きます。このページでは、ワークフローのタスクと依存関係が図で示されます。
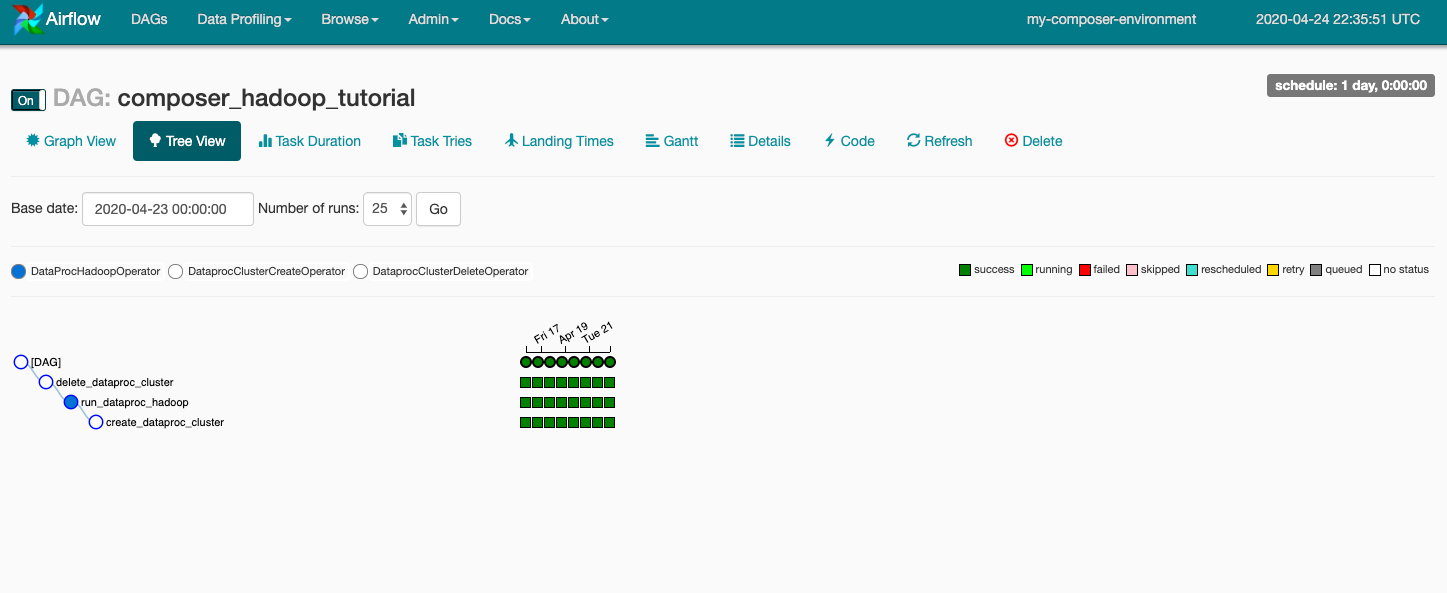
ツールバーで [Graph View] をクリックし、各タスクのグラフィックにカーソルを合わせてステータスを表示します。各タスクを囲む線の色もステータスを表しています(緑は実行中、赤は失敗など)。

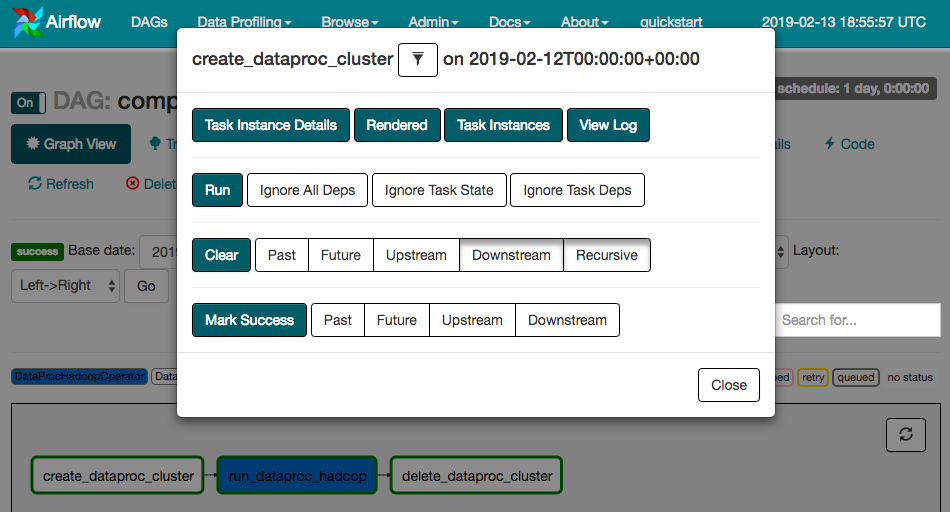
グラフビューからワークフローをもう一度実行するには、次の手順を行います。
- Airflow UI のグラフビューで、
create_dataproc_clusterグラフィックをクリックします。 - [Clear] をクリックして 3 つのタスクをリセットし、[OK] をクリックして確定します。
次の GCP コンソールのページに移動して、composer-hadoop-tutorial ワークフローのステータスと結果を確認することもできます。
- Cloud Dataproc クラスタ: クラスタの作成と削除をモニタリングします。ワークフローによって作成されたクラスタはエフェメラルであることに注意してください。クラスタはワークフローの期間中にのみ存在し、最後のワークフロー タスクの一部として削除されます。
- Cloud Dataproc ジョブ: Apache Hadoop ワードカウント ジョブを表示またはモニタリングします。ジョブ ID をクリックすると、ジョブのログ出力を確認できます。
- Cloud Storage ブラウザ: この Codelab 用に作成した Cloud Storage バケットの
wordcountフォルダにあるワードカウントの結果を確認します。
7. クリーンアップ
この Codelab で使用したリソースについて、GCP アカウントに課金されないようにする手順は次のとおりです。
- (省略可)データを保存するには、Cloud Composer 環境の Cloud Storage バケットと、この Codelab 用に作成したストレージ バケットからデータをダウンロードします。
- この Codelab で作成した Cloud Storage バケットを削除します。
- 環境の Cloud Storage バケットを削除します。
- Cloud Composer 環境を削除します。環境を削除しても、その環境のストレージ バケットは削除されません。
必要に応じて、プロジェクトを削除することもできます。
- GCP コンソールで [プロジェクト] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ボックスにプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。