
1. מבוא
תהליכי עבודה הם תרחיש לדוגמה נפוץ בניתוח נתונים – הם כוללים הטמעה, טרנספורמציה וניתוח של נתונים כדי למצוא בהם מידע חשוב. ב-Google Cloud Platform, הכלי לתזמור תהליכי עבודה הוא Cloud Composer, שהיא גרסה מתארחת של הכלי הפופולרי לתזמור תהליכי עבודה בקוד פתוח Apache Airflow. בשיעור ה-Lab הזה תשתמשו ב-Cloud Composer כדי ליצור תהליך עבודה פשוט של יצירת אשכול של Cloud Dataproc, תנתח אותו באמצעות Cloud Dataproc ו-Apache Hadoop ולאחר מכן תמחק את האשכול Cloud Dataproc.
מה זה Cloud Composer?
Cloud Composer הוא שירות מנוהל לתזמור תהליכי עבודה שמאפשר ליצור צינורות עיבוד נתונים, לתזמן אותם ולעקוב אחריהם משם. Cloud Composer, שמובנה על ידי פרויקט הקוד הפתוח Apache Airflow הפופולרי ומופעל באמצעות שפת התכנות Python, זמין ללא נעילה וקל לשימוש.
באמצעות Cloud Composer במקום במופע מקומי של Apache Airflow, המשתמשים יכולים ליהנות מהמיטב של Airflow ללא תקורת התקנה או ניהול.
מה זה Apache Airflow?
Apache Airflow הוא כלי בקוד פתוח המשמש באופן פרוגרמטי ליצירה, לתזמון ולמעקב של תהליכי עבודה. יש כמה מונחים עיקריים שכדאי לזכור בקשר ל-Airflow שיוצגו במהלך שיעור ה-Lab:
- DAG - DAG (Directed Acyclic Graph) הוא אוסף של משימות מאורגנות שברצונך לתזמן ולהפעיל. DAG, שנקרא גם תהליכי עבודה, מוגדר בקובצי Python סטנדרטיים
- אופרטור – אופרטור מתאר משימה יחידה בתהליך העבודה
מה זה Cloud Dataproc?
Cloud Dataproc הוא השירות המנוהל המלא של Google Cloud Platform ל-Apache Spark ול-Apache Hadoop . Cloud Dataproc משתלב בקלות עם שירותי GCP אחרים, ומספק פלטפורמה חזקה ומלאה לעיבוד נתונים, לניתוח נתונים וללמידת מכונה.
מה תעשו
ב-Codelab הזה מוסבר איך ליצור ולהריץ תהליך עבודה של Apache Airflow ב-Cloud Composer, שמבצע את המשימות הבאות:
- יצירת אשכול של Cloud Dataproc
- מריצה משימה של ספירת מילים של Apache Hadoop באשכול ומפיקה את התוצאות שלה ל-Cloud Storage
- מחיקת האשכול
מה תלמדו
- איך ליצור ולהפעיל תהליך עבודה של Apache Airflow ב-Cloud Composer
- איך משתמשים ב-Cloud Composer וב-Cloud Dataproc כדי להריץ ניתוח נתונים על מערך נתונים
- איך ניגשים לסביבת Cloud Composer דרך ממשק Google Cloud Platform Console, Cloud SDK ו-Airflow
מה צריך להכין
- חשבון GCP
- ידע בסיסי ב-CLI
- הבנה בסיסית של Python
2. הגדרת GCP
יצירת הפרויקט
בוחרים או יוצרים פרויקט ב-Google Cloud Platform.
מומלץ לרשום את מזהה הפרויקט, שבו תשתמשו בשלבים הבאים.
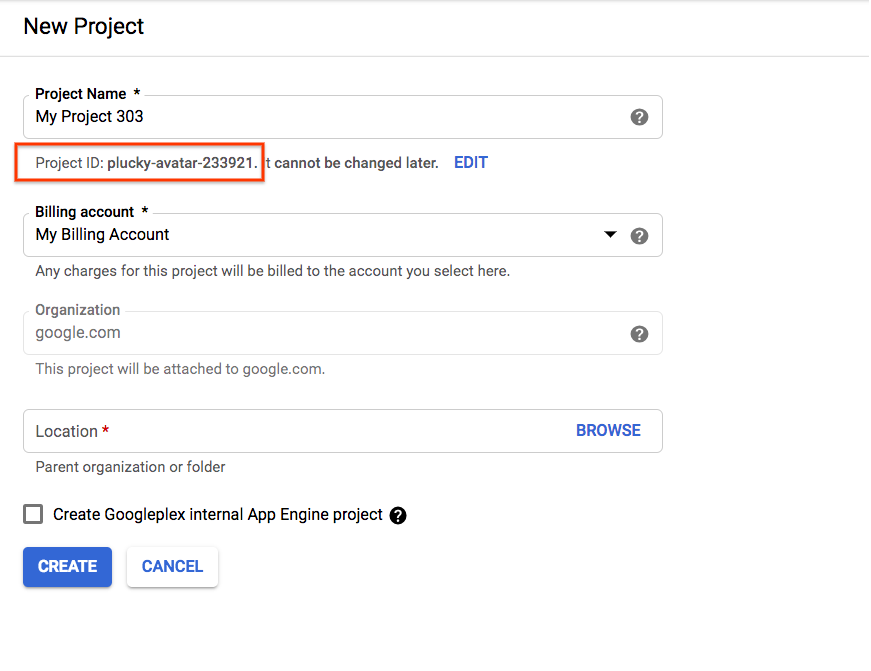
אם יוצרים פרויקט חדש, מזהה הפרויקט מופיע ממש מתחת לשם הפרויקט בדף היצירה. |
|
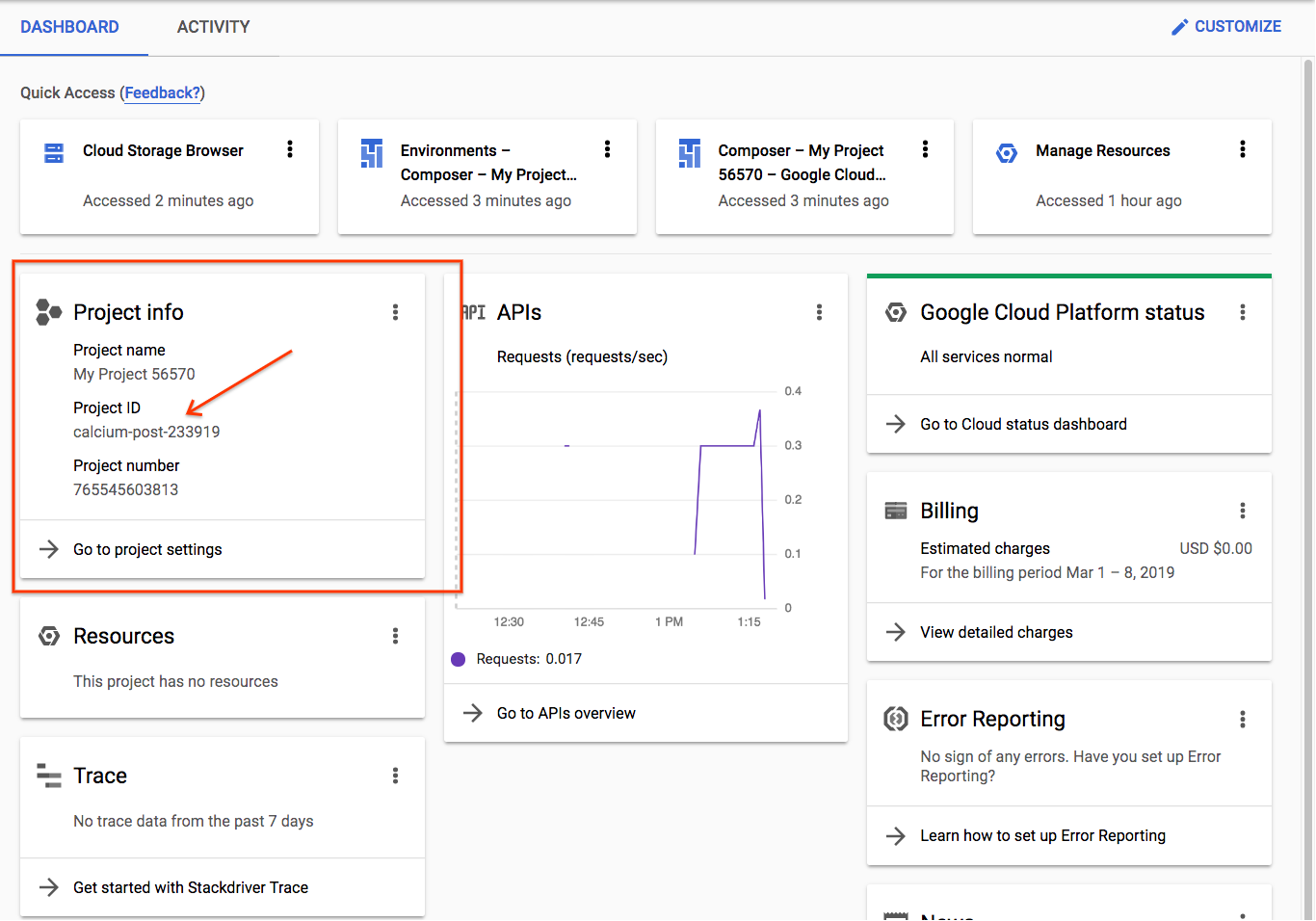
אם כבר יצרתם פרויקט, תוכלו למצוא את המזהה בדף הבית של המסוף בכרטיס 'פרטי הפרויקט' |
|
הפעלת ממשקי ה-API
מפעילים את ממשקי ה-API של Cloud Composer, Cloud Dataproc ו-Cloud Storage. אחרי שהם יופעלו, אפשר להתעלם מהלחצן עם הכיתוב 'Go to Credentials (מעבר לפרטי כניסה)'. ולהמשיך לשלב הבא במדריך. |
|

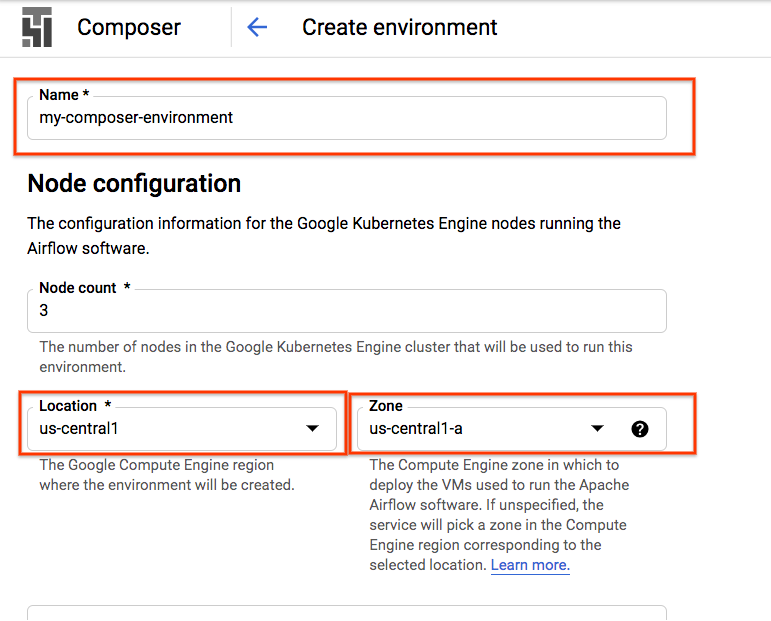
יצירת סביבת Composer
יוצרים סביבה של Cloud Composer עם ההגדרות הבאות:
כל שאר ההגדרות יישארו כברירת המחדל. לוחצים על 'יצירה' שלמטה. |
|

יצירת קטגוריה של Cloud Storage
בפרויקט שלכם, יוצרים קטגוריה של Cloud Storage עם ההגדרות הבאות:
לוחצים על 'יצירה' כשיתאים לך |
|

3. הגדרת Apache Airflow
הצגת פרטי סביבת Composer
במסוף GCP, פותחים את הדף Environments (סביבות).
לוחצים על שם הסביבה כדי לראות את הפרטים שלה.
הדף Environment details כולל מידע כמו כתובת ה-URL של ממשק האינטרנט של Airflow, מזהה האשכול של Google Kubernetes Engine, שם הקטגוריה של Cloud Storage והנתיב של התיקייה /dags.
ב-Airflow, DAG (Directed Acyclic Graph) הוא אוסף של משימות מאורגנות שאתם רוצים לתזמן ולהפעיל. DAG, שנקרא גם תהליכי עבודה, מוגדר בקובצי Python סטנדרטיים. Cloud Composer מתזמן את ה-DAG רק בתיקייה /dags. התיקייה /dags נמצאת בקטגוריה של Cloud Storage ש-Cloud Composer יוצר באופן אוטומטי כשיוצרים את הסביבה.
הגדרת משתני סביבת Apache Airflow
משתני Apache Airflow הם קונספט ספציפי ל-Airflow ששונה ממשתני סביבה. בשלב הזה מגדירים את שלושת משתני Airflow הבאים: gcp_project, gcs_bucket ו-gce_zone.
שימוש בפונקציה gcloud להגדרת משתנים
קודם כול פותחים את Cloud Shell, שכוללת את Cloud SDK שמותקן בשבילכם.
מגדירים את משתנה הסביבה COMPOSER_INSTANCE לשם של סביבת Composer
COMPOSER_INSTANCE=my-composer-environment
כדי להגדיר משתני Airflow באמצעות כלי שורת הפקודה של Google Cloud, משתמשים בפקודה gcloud composer environments run עם פקודת המשנה variables. פקודת gcloud composer הזו מפעילה את פקודת המשנה של ה-CLI של Airflow variables. פקודת המשנה מעבירה את הארגומנטים לכלי שורת הפקודה gcloud.
אתם מריצים את הפקודה הזו שלוש פעמים, ומחליפים את המשתנים במשתנים הרלוונטיים לפרויקט שלכם.
מגדירים את gcp_project באמצעות הפקודה הבאה, שמחליפים את <your-project-id> עם מזהה הפרויקט שרשמתם בשלב 2.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
הפלט שלכם ייראה בערך כך
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
מגדירים את gcs_bucket באמצעות הפקודה הבאה, ומחליפים את <your-bucket-name> במזהה הקטגוריה שציינתם בשלב 2. אם פעלתם בהתאם להמלצה שלנו, שם הקטגוריה שלכם יהיה זהה למזהה הפרויקט שלכם. הפלט שלכם יהיה דומה לפקודה הקודמת.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
מגדירים את gce_zone באמצעות הפקודה הבאה. הפלט שלכם יהיה דומה לפקודות הקודמות.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(אופציונלי) שימוש בפונקציה gcloud כדי לצפות במשתנה
כדי לראות את הערך של משתנה, מריצים את פקודת המשנה של Airflow CLI variables עם הארגומנט get או משתמשים בממשק המשתמש של Airflow.
לדוגמה:
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
תוכלו לעשות זאת באמצעות כל אחד משלושת המשתנים שהגדרתם: gcp_project, gcs_bucket ו-gce_zone.
4. תהליך עבודה לדוגמה
בואו נסתכל על הקוד של ה-DAG שבו נשתמש בשלב 5. לא צריך לדאוג לגבי הורדת הקבצים, פשוט צריך לעקוב כאן.
יש כאן הרבה מה לדאוג, אז נסביר קצת.
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
אנחנו מתחילים עם חלק מייבוא Airflow:
airflow.models– מאפשרת לנו לגשת לנתונים וליצור נתונים במסד הנתונים של Airflow.airflow.contrib.operators– המקום שבו גרים המפעילים של הקהילה. במקרה הזה, אנחנו צריכים את ה-dataproc_operatorכדי לקבל גישה ל-Cloud Dataproc API.airflow.utils.trigger_rule– להוספת כללי הפעלה לאופרטורים שלנו. כללי הטריגר מאפשרים שליטה פרטנית אם האופרטור צריך לפעול ביחס לסטטוס של ההורה שלו.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
מציין את המיקום של קובץ הפלט. השורה הבולטת כאן היא models.Variable.get('gcs_bucket'), שתאחזר את ערך המשתנה gcs_bucket ממסד הנתונים של Airflow.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR– מיקום קובץ ה- .jar שבסופו של דבר נריץ על האשכול Cloud Dataproc. הוא כבר מתארח ב-GCP בשבילך.input_file– מיקום הקובץ שמכיל את הנתונים שעליהם תחושב בסופו של דבר משימת Hadoop. נעלה את הנתונים למיקום הזה ביחד בשלב 5.wordcount_args- ארגומנטים שנעביר לקובץ ה-jar.
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
הפעולה הזו תספק לנו אובייקט עם תאריך ושעה מקבילים שמייצג את חצות ביום הקודם. לדוגמה, אם היא מבוצעת בשעה 11:00 ב-4 במרץ, האובייקט timestamp ייצג את השעה 00:00 ב-3 במרץ. הבעיה הזו קשורה לאופן שבו Airflow מטפל בתזמון. מידע נוסף זמין כאן.
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
בכל פעם שיוצרים DAG חדש, יש לספק את המשתנה default_dag_args בצורת מילון:
'email_on_failure'– מציין אם צריך לשלוח התראות באימייל כשמשימה נכשלה'email_on_retry'– מציין אם צריך לשלוח התראות באימייל כשמתבצע ניסיון חוזר של משימה'retries'– ציון מספר הניסיונות של הניסיונות החוזרים על ידי Airflow לבצע במקרה של כשל DAG'retry_delay'– מציינת כמה זמן Airflow צריך להמתין לפני ניסיון חוזר'project_id'– מציין ל-DAG לאיזה מזהה פרויקט של GCP לשייך אותו, שיהיה צורך בו מאוחר יותר עם מפעיל Dataproc
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
השימוש ב-with models.DAG מורה לסקריפט לכלול את כל מה שמתחתיו בתוך אותו DAG. אנחנו גם רואים שלושה ארגומנטים שהועברו:
- המחרוזת הראשונה היא השם לתת ל-DAG שאנחנו יוצרים. במקרה הזה, נשתמש ב-
composer_hadoop_tutorial. schedule_interval– אובייקטdatetime.timedelta, שכאן הגדרנו ליום אחד. פירוש הדבר הוא שה-DAG הזה ינסה לפעול פעם אחת ביום אחרי ה-'start_date'שהוגדר קודם לכן ב-'default_dag_args'default_args- המילון שיצרנו קודם שמכיל את ארגומנטים ברירת המחדל של ה-DAG
יצירת אשכול Dataproc
בשלב הבא ניצור dataproc_operator.DataprocClusterCreateOperator שיוצר אשכול של Cloud Dataproc.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
בתוך האופרטור הזה מופיעים כמה ארגומנטים, שכולם ספציפיים לאופרטור הזה:
task_id– בדיוק כמו ב-BashOperator, זה השם שאנחנו מקצים לאופרטור, וניתן לראות אותו בממשק המשתמש של Airflow.cluster_name– השם שאנחנו מקצים לאשכול Cloud Dataproc. כאן שינינו את השםcomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(מידע אופציונלי נוסף בתיבת המידע)num_workers– מספר העובדים שאנחנו מקצים לאשכול Cloud Dataproczone– האזור הגיאוגרפי שבו רוצים שהאשכול ימוקם, כפי שהוא שמור במסד הנתונים של Airflow. הפעולה הזו תקרא את המשתנה'gce_zone'שהגדרנו בשלב 3master_machine_type– סוג המכונה שאנחנו רוצים להקצות למאסטר של Cloud Dataprocworker_machine_type– סוג המכונה שאנחנו רוצים להקצות ל-Cloud Dataproc
שליחת משימת Apache Hadoop
השדה dataproc_operator.DataProcHadoopOperator מאפשר לנו לשלוח משימה לאשכול של Cloud Dataproc.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
אנחנו מספקים כמה פרמטרים:
task_id- השם שאנחנו מקצים לחלק הזה ב-DAGmain_jar– המיקום של קובץ ה- .jar שאנחנו רוצים להריץ מול האשכולcluster_name– שם האשכול שעליו רוצים להריץ את המשימה, שתבחינו בו זהה לשם שמצאנו באופרטור הקודםarguments- ארגומנטים שמועברים לקובץ ה-jar, בדיוק כמו שמריצים את קובץ ה- .jar משורת הפקודה
מחיקת האשכול
האופרטור האחרון שניצור הוא dataproc_operator.DataprocClusterDeleteOperator.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
כפי שהשם מרמז, האופרטור הזה ימחק אשכול נתון של Cloud Dataproc. כאן אפשר לראות שלושה ארגומנטים:
task_id– בדיוק כמו ב-BashOperator, זה השם שאנחנו מקצים לאופרטור, וניתן לראות אותו בממשק המשתמש של Airflow.cluster_name– השם שאנחנו מקצים לאשכול Cloud Dataproc. כאן ניתן לו את השםcomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(למידע נוסף, ניתן לעיין בתיבת המידע אחרי 'יצירת אשכול Dataproc'trigger_rule– הזכרנו את כללי הטריגר בקצרה במהלך הייבוא בתחילת השלב הזה, אבל עכשיו יש לנו מודל כזה. כברירת מחדל, מפעיל Airflow לא מבצע את הפעולה אלא אם כל האופרטורים שלו ב-upstream השלימו את התהליך. כלל הטריגרALL_DONEרק מחייב שכל האופרטורים ב-upstream ישלימו את התהליך, גם אם הם לא הצליחו. כלומר, גם אם משימת Hadoop נכשלה, עדיין אנחנו רוצים לנתק את האשכול.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
לסיום, אנחנו רוצים שהאופרטורים האלה יופעלו בסדר מסוים, ונוכל לציין זאת באמצעות שימוש באופרטורים של העברת סיביות (bitshift) ב-Python. במקרה הזה, הפקודה create_dataproc_cluster תמיד תבוצע קודם, אחריה run_dataproc_hadoop ולבסוף delete_dataproc_cluster.
הקוד נראה כך:
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. העלאת קובצי Airflow ל-Cloud Storage
העתקת ה-DAG לתיקיית /dags
- קודם כול פותחים את Cloud Shell, שכוללת את Cloud SDK שמותקן בשבילכם.
- שכפול המאגר של דוגמאות python ושינוי לספריית המלחין/workflows
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- מריצים את הפקודה הבאה כדי להגדיר את השם של תיקיית ה-DAG למשתנה סביבה
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- מריצים את הפקודה הבאה של
gsutilכדי להעתיק את הקוד של המדריך למקום שבו נוצרת התיקייה /dags
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
הפלט שלכם ייראה בערך כך:
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. שימוש בממשק המשתמש של Airflow
כדי לגשת לממשק האינטרנט של Airflow באמצעות מסוף GCP:
|
|

מידע נוסף על ממשק המשתמש של Airflow זמין במאמר גישה לממשק האינטרנט.
הצגת המשתנים
המשתנים שהגדרתם קודם נשארים בסביבה שלכם. כדי להציג את המשתנים, בוחרים באפשרות אדמין > משתנים מסרגל התפריטים בממשק המשתמש של Airflow.

התנסות בהפעלות DAG
כשמעלים את קובץ ה-DAG לתיקייה dags ב-Cloud Storage, Cloud Composer מנתח את הקובץ. אם לא יימצאו שגיאות, השם של תהליך העבודה יופיע ברשימת ה-DAG ותהליך העבודה יועבר לתור מיד. כדי לראות את ה-DAG, לוחצים על DAG בראש הדף.
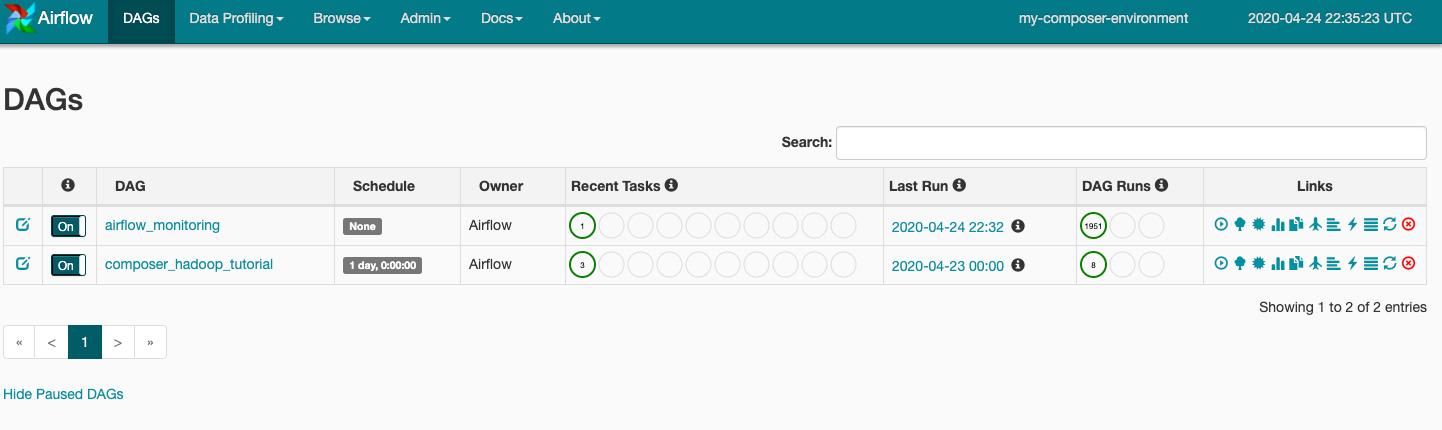
לוחצים על composer_hadoop_tutorial כדי לפתוח את דף פרטי ה-DAG. הדף הזה כולל ייצוג גרפי של משימות של תהליך עבודה ויחסי תלות.
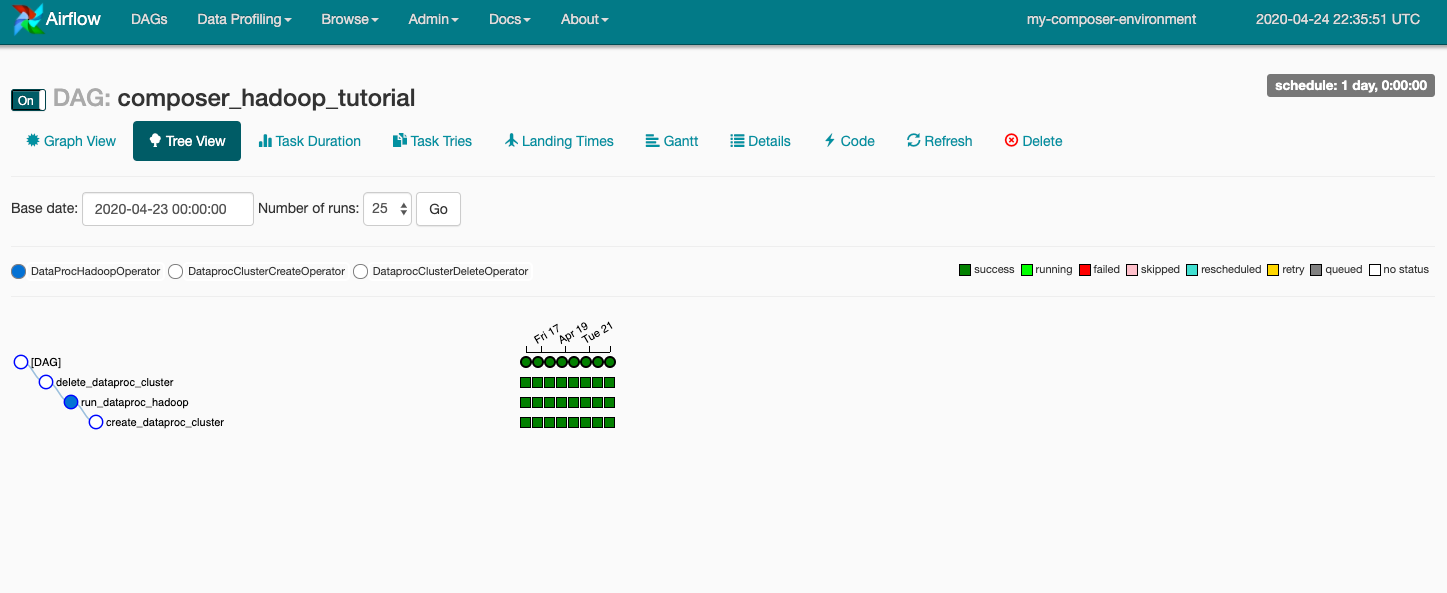
עכשיו, בסרגל הכלים לוחצים על תצוגת תרשים ומעבירים את העכבר מעל הגרפיקה של כל משימה כדי לראות את הסטטוס שלה. לתשומת ליבכם: הגבול מסביב לכל משימה מציין גם את הסטטוס (גבול ירוק = פועל, אדום = נכשל וכו').

כדי להפעיל שוב את תהליך העבודה מתצוגת התרשים:
- בתצוגת התרשים של ממשק המשתמש של Airflow, לוחצים על הגרפיקה
create_dataproc_cluster. - לוחצים על ניקוי כדי לאפס את שלוש המשימות ואז לוחצים על אישור כדי לאשר.

אפשר גם לבדוק את הסטטוס והתוצאות של תהליך העבודה ב-composer-hadoop-tutorial באמצעות הדפים הבאים במסוף GCP:
- Cloud Dataproc Clusters למעקב אחרי היצירה והמחיקה של אשכולות. שימו לב שהאשכול שנוצר על ידי תהליך העבודה הוא זמני: הוא קיים רק במהלך תהליך העבודה ונמחק כחלק מהמשימה האחרונה של תהליך העבודה.
- משימות Cloud Dataproc כדי להציג או לעקוב אחר משימת ספירת המילים של Apache Hadoop. לוחצים על מזהה המשימה כדי לראות את הפלט של יומן המשימות.
- דפדפן Cloud Storage כדי לראות את התוצאות של ספירת המילים בתיקייה
wordcountבקטגוריה של Cloud Storage שיצרתם עבור ה-Codelab הזה.
7. הסרת המשאבים
כדי להימנע מצבירת חיובים בחשבון GCP עבור המשאבים שבהם נעשה שימוש ב-Codelab הזה:
- (אופציונלי) כדי לשמור את הנתונים, מורידים את הנתונים מהקטגוריה של Cloud Storage לסביבת Cloud Composer ואת קטגוריית האחסון שיצרתם בשביל ה-Codelab הזה.
- מוחקים את הקטגוריה של Cloud Storage שיצרתם בשביל ה-Codelab הזה.
- מחיקת הקטגוריה של Cloud Storage של הסביבה.
- מחיקה של סביבת Cloud Composer. שימו לב שמחיקת הסביבה לא מוחקת את קטגוריית האחסון של הסביבה.
אפשר גם למחוק את הפרויקט:
- במסוף GCP, עוברים לדף Projects.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על מחיקה.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבה ולוחצים על Shut down.