
Bu codelab hakkında
1. Giriş
İş akışları, veri analizinde yaygın bir kullanım alanıdır. Anlamlı bilgileri bulmak için verilerin alınmasını, dönüştürülmesini ve analiz edilmesini içerir. Google Cloud Platform'da iş akışlarını düzenlemeye yönelik araç, popüler açık kaynak iş akışı aracı Apache Airflow'un barındırılan bir sürümü olan Cloud Composer'dır. Bu laboratuvarda, Cloud Dataproc kümesi oluşturan, Cloud Dataproc ve Apache Hadoop kullanarak bu kümeyi analiz eden, ardından Cloud Dataproc kümesini silen basit bir iş akışı oluşturmak için Cloud Composer'ı kullanacaksınız.
Cloud Composer nedir?
Cloud Composer, bulutlara ve şirket içi veri merkezlerine yayılan ardışık düzenler yazmanız, planlamanız ve imzalamanız için size destek veren, tümüyle yönetilen bir iş akışı düzenleme hizmetidir. Popüler Apache Airflow açık kaynak projesi temel alınarak geliştirilen ve Python programlama diliyle çalıştırılan Cloud Composer, bağımlılık olmadan ve kolayca kullanılır.
Kullanıcılar, yerel bir Apache Airflow örneği yerine Cloud Composer'ı kullanarak kurulum veya yönetim ek yükü olmadan Airflow'un en iyi özelliklerinden yararlanabilir.
Apache Airflow nedir?
Apache Airflow, iş akışlarını programatik olarak yazmak, planlamak ve izlemek için kullanılan açık kaynak bir araçtır. Airflow ile ilgili unutulmaması gereken birkaç temel terim vardır. Laboratuvar boyunca bunları göreceksiniz:
- DAG - bir DAG (Yönlü Döngüsel Grafik), planlamak ve çalıştırmak istediğiniz düzenlenmiş görevlerden oluşan bir koleksiyondur. İş akışları olarak da adlandırılan DAG'ler, standart Python dosyalarında tanımlanır.
- Operatör - operatör, iş akışındaki tek bir görevi açıklar
Cloud Dataproc nedir?
Cloud Dataproc, Google Cloud Platform'un tümüyle yönetilen Apache Spark ve Apache Hadoop hizmetidir. Cloud Dataproc, diğer GCP hizmetleriyle kolayca entegre olarak size veri işleme, analiz ve makine öğrenimi için güçlü, eksiksiz bir platform sunar.
Yapacaklarınız
Bu codelab'de, Cloud Composer'da aşağıdaki görevleri tamamlayan bir Apache Airflow iş akışının nasıl oluşturulacağı ve çalıştırılacağı gösterilmiştir:
- Cloud Dataproc kümesi oluşturur
- Kümede Apache Hadoop kelime sayısı işi çalıştırır ve sonuçlarını Cloud Storage'a gönderir
- Kümeyi siler
Neler öğreneceksiniz?
- Cloud Composer'da Apache Airflow iş akışı oluşturma ve çalıştırma
- Bir veri kümesi üzerinde analiz çalıştırmak için Cloud Composer ve Cloud Dataproc'u kullanma
- Google Cloud Platform Console, Google Cloud SDK ve Airflow web arayüzü üzerinden Cloud Composer ortamınıza erişme
Gerekenler
- GCP hesabı
- Temel KSA bilgisi
- Python ile ilgili temel bilgiler
2. GCP'yi Ayarlama
Projeyi oluşturma
Bir Google Cloud Platform projesi seçin veya oluşturun.
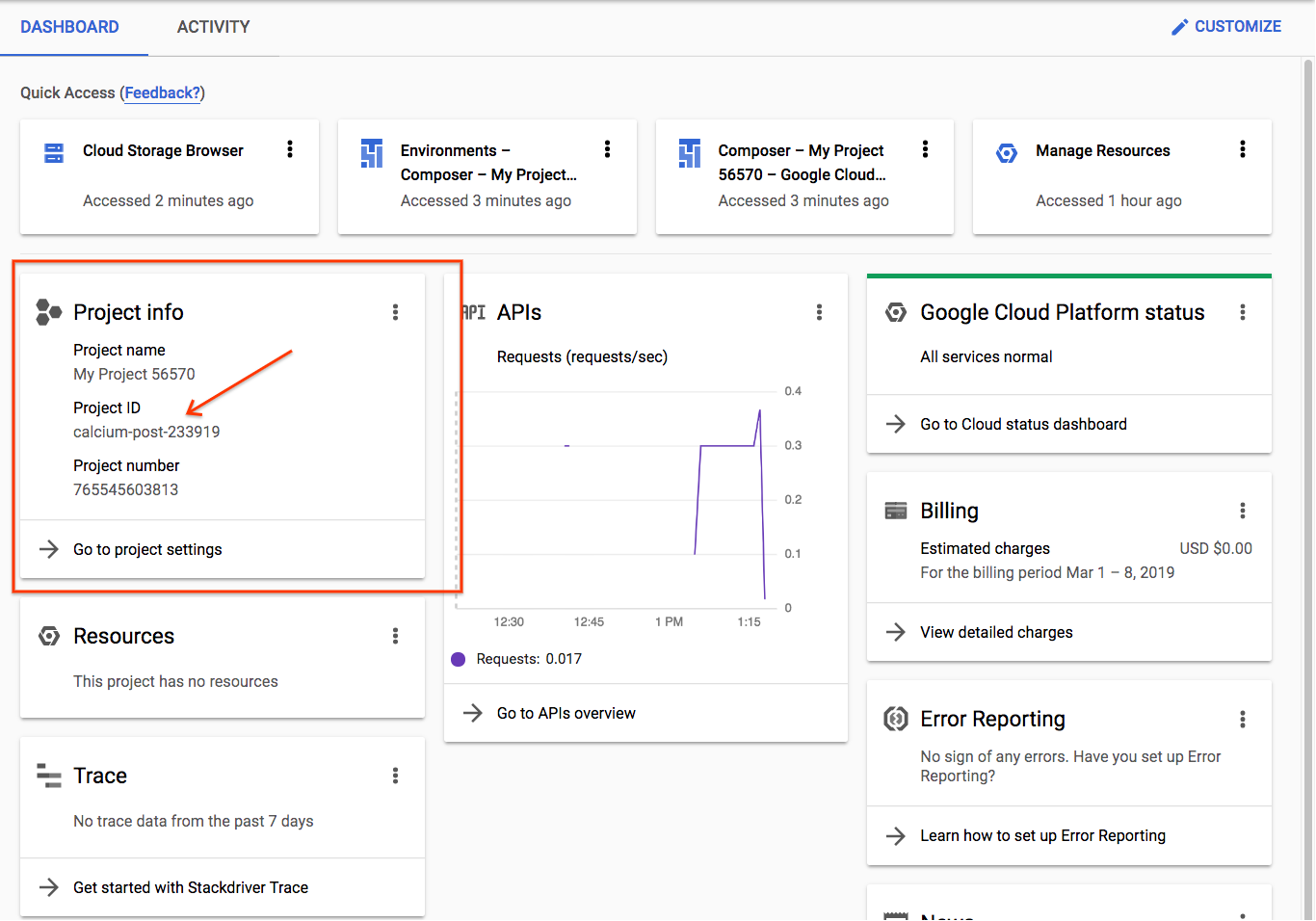
Sonraki adımlarda kullanacağınız proje kimliğinizi not edin.
Yeni bir proje oluşturuyorsanız proje kimliği, oluşturma sayfasındaki Proje Adı'nın hemen altında yer alır |
|
Daha önce proje oluşturduysanız kimliği Proje Bilgileri kartındaki konsol ana sayfasında bulabilirsiniz |
|

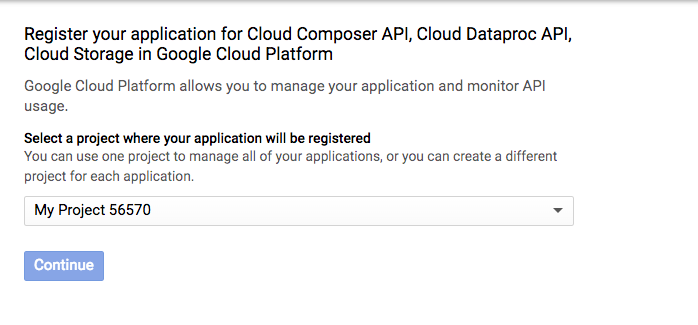
API'leri etkinleştirme
Cloud Composer, Cloud Dataproc ve Cloud Storage API'lerini etkinleştirin. Bunlar etkinleştirildikten sonra "Kimlik Bilgilerine Git" düğmesini yoksayabilirsiniz. ve eğiticinin sonraki adımına geçin. |
|

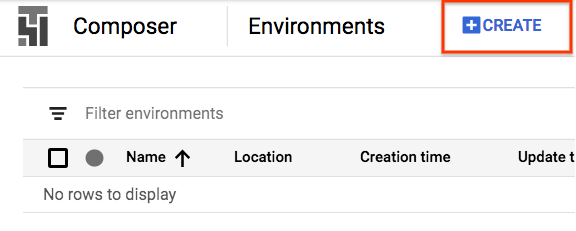
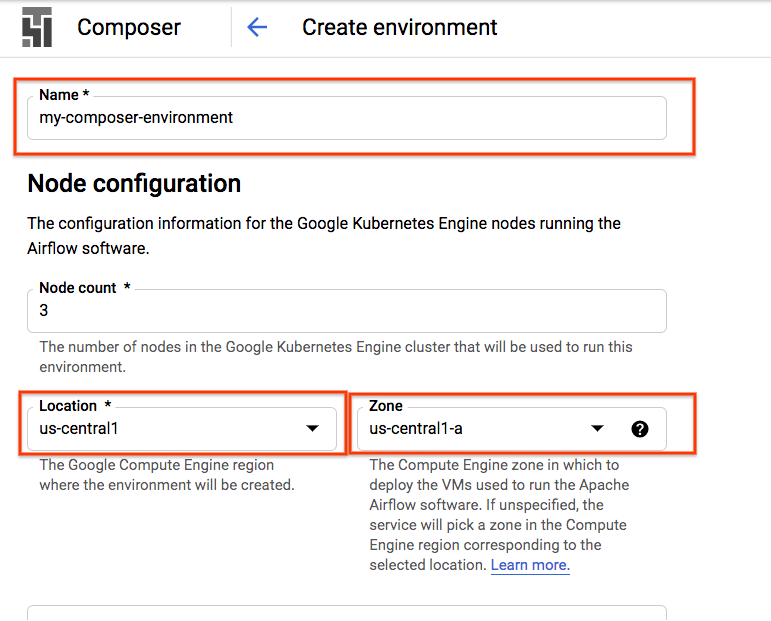
Composer Ortamı Oluşturma
Aşağıdaki yapılandırmaya sahip bir Cloud Composer ortamı oluşturun:
Diğer tüm yapılandırmalar varsayılan değerlerinde kalabilir. "Oluştur"u tıklayın. dokunun. |
|
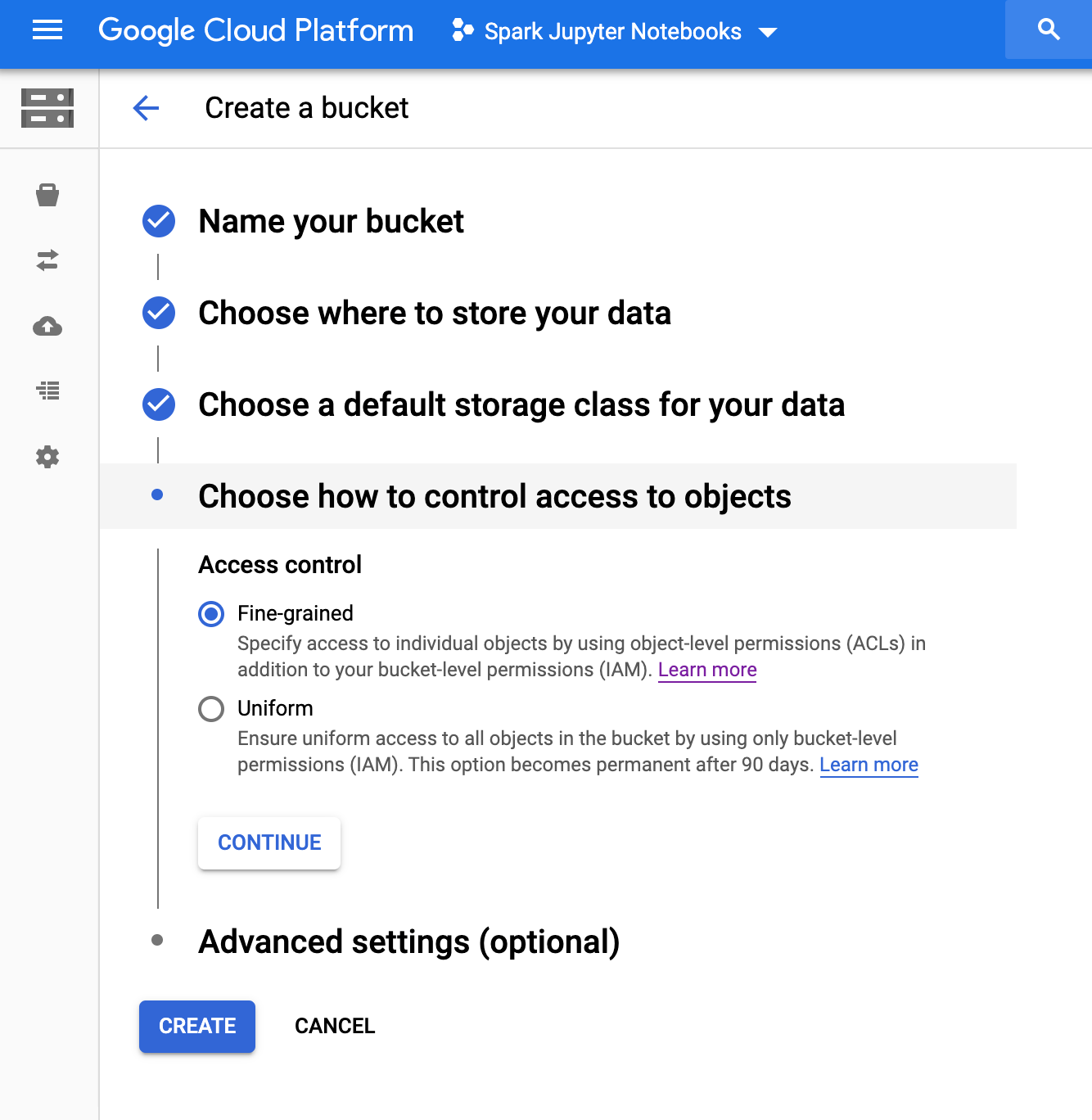
Cloud Storage Paketi oluşturma
Projenizde aşağıdaki yapılandırmaya sahip bir Cloud Storage paketi oluşturun:
"Oluştur"a basın. hazır olduğunuzda |
|
3. Apache Airflow'u Ayarlama
Composer Ortamı Bilgilerini Görüntüleme
GCP Console'da Ortamlar sayfasını açın.
Ayrıntılarını görmek için ortamın adını tıklayın.
Ortam ayrıntıları sayfasında Airflow web arayüzü URL'si, Google Kubernetes Engine küme kimliği, Cloud Storage paketinin adı ve /dags klasörünün yolu gibi bilgiler bulunur.
Airflow'da DAG (Yönlü Döngüsel Grafik), planlamak ve çalıştırmak istediğiniz düzenlenmiş görevlerden oluşan bir koleksiyondur. İş akışları olarak da adlandırılan DAG'ler, standart Python dosyalarında tanımlanır. Cloud Composer yalnızca /dags klasöründeki DAG'leri planlar. /dags klasörü, ortamınızı oluşturduğunuzda Cloud Composer'ın otomatik olarak oluşturduğu Cloud Storage paketinde yer alır.
Apache Airflow Ortamı Değişkenlerini Ayarlama
Apache Airflow değişkenleri, ortam değişkenlerinden farklı olan Airflow'a özgü bir kavramdır. Bu adımda şu üç Airflow değişkenini ayarlayacaksınız: gcp_project, gcs_bucket ve gce_zone.
Değişkenleri Ayarlamak için gcloud Kullanımı
İlk olarak Google Cloud SDK'nın sizin için kolayca yüklenmiş olduğu Cloud Shell'inizi açın.
COMPOSER_INSTANCE ortam değişkenini Composer ortamınızın adına ayarlayın
COMPOSER_INSTANCE=my-composer-environment
gcloud komut satırı aracını kullanarak Airflow değişkenlerini ayarlamak için variables alt komutuyla gcloud composer environments run komutunu kullanın. Bu gcloud composer komutu, Airflow CLI alt komutunu variables yürütür. Alt komut, bağımsız değişkenleri gcloud komut satırı aracına iletir.
Değişkenleri projenizle ilgili olanlarla değiştirerek bu komutu üç kez çalıştıracaksınız.
Aşağıdaki komutta <proje-kimliğiniz> kısmını değiştirerek gcp_project özelliğini ayarlayın. not aldığınız proje kimliği ile değiştirin.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
Çıkışınız şuna benzer:
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
Aşağıdaki komutu kullanarak gcs_bucket değerini ayarlayın ve <your-bucket-name> yerine 2. adımda not ettiğiniz paket kimliğini girin. Önerimizi uyguladıysanız paketinizin adı proje kimliğinizle aynı olur. Çıkışınız önceki komuta benzer olur.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
Aşağıdaki komutu kullanarak gce_zone öğesini ayarlayın. Çıkışınız önceki komutlara benzer olacaktır.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(İsteğe bağlı) Bir değişkeni görüntülemek için gcloud kullanma
Bir değişkenin değerini görmek için Airflow CLI alt komutunu variables get bağımsız değişkeniyle çalıştırın veya Airflow kullanıcı arayüzünü kullanın.
Örneğin:
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
Bu işlemi, az önce ayarladığınız şu üç değişkenden herhangi biriyle yapabilirsiniz: gcp_project, gcs_bucket ve gce_zone.
4. Örnek İş Akışı
Şimdi, 5. adımda kullanacağımız DAG'nin koduna bakalım. Henüz dosya indirme konusunda endişelenmeyin. Buradan talimatları takip edebilirsiniz.
Burada açılacak çok şey var. Şimdi biraz açalım.
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
Birkaç Airflow içe aktarma işlemiyle başlıyoruz:
airflow.models- Airflow veritabanında verilere erişmemizi ve bu verileri oluşturmamızı sağlar.airflow.contrib.operators- Topluluktaki operatörlerin yaşadığı yer. Bu durumda, Cloud Dataproc API'ye erişmek içindataproc_operatorgerekir.airflow.utils.trigger_rule: Operatörlerimize tetikleyici kuralları eklemek için kullanılır. Tetikleme kuralları, bir operatörün üst öğelerinin durumuna göre yürütülüp yürütülmeyeceğini ayrıntılı bir şekilde kontrol etmenize olanak tanır.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
Bu, çıkış dosyamızın konumunu belirtir. Buradaki önemli satır, Airflow veritabanından gcs_bucket değişken değerini alacak models.Variable.get('gcs_bucket').
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR- Cloud Dataproc kümesinde çalıştıracağımız .jar dosyasının konumu. GCP'de sizin için barındırılmaktadır.input_file- Hadoop işimizin sonunda hesaplanacağı verileri içeren dosyanın konumu. Verileri birlikte 5. Adım'da söz konusu konuma yükleyeceğiz.wordcount_args- Jar dosyasına ileteceğimiz bağımsız değişkenler.
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
Bu bize bir önceki günün gece yarısını temsil eden bir tarih ve saat nesnesi sağlar. Örneğin, bu işlem 4 Mart saat 11:00'de yürütülürse tarih ve saat nesnesi 3 Mart'ta saat 00:00'ı temsil eder. Bu, Airflow'un planlamayı nasıl ele aldığıyla ilgilidir. Bu konu hakkında daha fazla bilgiye buradan ulaşabilirsiniz.
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
Yeni bir DAG oluşturulduğunda sözlük biçimindeki default_dag_args değişkeni sağlanmalıdır:
'email_on_failure'- Bir görev başarısız olduğunda e-posta uyarılarının gönderilip gönderilmeyeceğini belirtir'email_on_retry'- Bir görev yeniden denendiğinde e-posta uyarılarının gönderilip gönderilmeyeceğini belirtir'retries': DAG hatası durumunda Airflow'un kaç yeniden deneme denemesi gerektiğini belirtir'retry_delay': Airflow'un yeniden denemeden önce ne kadar beklemesi gerektiğini belirtir'project_id'- DAG'ye, onu hangi GCP Proje Kimliği ile ilişkilendireceğini söyler. Daha sonra Dataproc Operatörü ile bu kimliğin ilişkilendirilmesi gerekir
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
with models.DAG kullanılması, komut dosyasına, altındaki her şeyi aynı DAG'ye eklemesini belirtir. Ayrıca, aşağıda belirtilen üç bağımsız değişkenin geçirildiğini görüyoruz:
- Bunların ilki olan dize, oluşturduğumuz DAG'ye verilecek addır. Bu örnekte
composer_hadoop_tutorialkullanıyoruz. schedule_interval- Burada bir güne ayarladığımızdatetime.timedeltanesnesi. Bu durumda, bu DAG,'default_dag_args'içinde daha önce ayarlanan'start_date'sonrasında günde bir kez yürütülmeye çalışacaktır.default_args- Daha önce oluşturduğumuz ve DAG'nin varsayılan bağımsız değişkenlerini içeren sözlük
Dataproc Kümesi oluşturma
Şimdi, Cloud Dataproc kümesi oluşturan bir dataproc_operator.DataprocClusterCreateOperator oluşturacağız.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
Bu operatör içinde, biri hariç tümü bu operatöre özel birkaç bağımsız değişken görürüz:
task_id: Bu, BashOperator'da olduğu gibi operatöre atadığımız addır ve Airflow kullanıcı arayüzünden görüntülenebilir.cluster_name: Cloud Dataproc kümesine atadığımız ad. Burada, videoyucomposer-hadoop-tutorial-cluster-{{ ds_nodash }}olarak adlandırdık (isteğe bağlı ek bilgiler için bilgi kutusuna bakın).num_workers- Cloud Dataproc kümesine atadığımız çalışan sayısızone: Airflow veritabanına kaydedildiği şekliyle kümenin kullanılmasını istediğimiz coğrafi bölge. Bu, 3. adımda belirlediğimiz'gce_zone'değişkenini okuyacaktırmaster_machine_type- Cloud Dataproc ana sistemine ayırmak istediğimiz makine türüworker_machine_type- Cloud Dataproc çalışanına ayırmak istediğimiz makine türü
Apache Hadoop İşi Gönderme
dataproc_operator.DataProcHadoopOperator, Cloud Dataproc kümesine iş göndermemize olanak tanır.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
Birkaç parametre sağlarız:
task_id- DAG'nin bu bölümüne atadığımız admain_jar- Kümede çalıştırmak istediğimiz .jar dosyasının konumucluster_name- İşin çalıştırılacağı kümenin adı. Bu adın önceki operatörde bulduğumuz adla aynı olduğunu fark edeceksinizarguments- .jar dosyasını komut satırından yürütürken olduğu gibi, jar dosyasına geçirilen bağımsız değişkenler
Kümeyi Silme
Oluşturacağımız son operatör dataproc_operator.DataprocClusterDeleteOperator olacak.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
Adından da anlaşılacağı gibi bu operatör, belirli bir Cloud Dataproc kümesini siler. Burada üç bağımsız değişken görüyoruz:
task_id: Bu, BashOperator'da olduğu gibi operatöre atadığımız addır ve Airflow kullanıcı arayüzünden görüntülenebilir.cluster_name: Cloud Dataproc kümesine atadığımız ad. Burada, dosyayıcomposer-hadoop-tutorial-cluster-{{ ds_nodash }}olarak adlandırdık (isteğe bağlı ek bilgiler için "Dataproc Kümesi Oluşturma" başlığındaki bilgi kutusunu inceleyin.)trigger_rule- Bu adımın başındaki içe aktarma işlemleri sırasında Tetikleyici Kurallarından kısaca bahsettik ancak burada bir kural uyguluyoruz. Varsayılan olarak, bir Airflow operatörü tüm yukarı akış operatörleri başarıyla tamamlanmadığı sürece yürütülmez.ALL_DONEtetikleyici kuralı, başarılı olup olmadıklarına bakılmaksızın yalnızca tüm yukarı akış operatörlerinin tamamlamalarını gerektirir. Bu, Hadoop işi başarısız olsa bile kümeyi ortadan kaldırmak istediğimiz anlamına gelir.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Son olarak, bu operatörlerin belirli bir sırada yürütülmesini istiyoruz. Bunu, Python bit kaydırma operatörlerini kullanarak gösterebiliriz. Bu durumda, her zaman ilk olarak create_dataproc_cluster, ardından run_dataproc_hadoop ve son olarak delete_dataproc_cluster yürütülür.
Hepsini bir araya getirdiğimizde kod şu şekilde görünür:
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. Airflow Dosyalarını Cloud Storage'a Yükleme
DAG'yi /dags Klasörüne Kopyalayın
- İlk olarak Google Cloud SDK'nın sizin için kolayca yüklenmiş olduğu Cloud Shell'inizi açın.
- Python örnek deposunu klonlama ve oluşturucu/iş akışı dizinine değiştirme
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- DAG'ler klasörünüzün adını bir ortam değişkeni olarak ayarlamak için aşağıdaki komutu çalıştırın
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- Eğitim kodunu /dags klasörünüzün oluşturulduğu yere kopyalamak için aşağıdaki
gsutilkomutunu çalıştırın
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
Çıkışınız aşağıdaki gibi görünür:
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. Airflow kullanıcı arayüzünü kullanma
GCP konsolunu kullanarak Airflow web arayüzüne erişmek için:
|
|
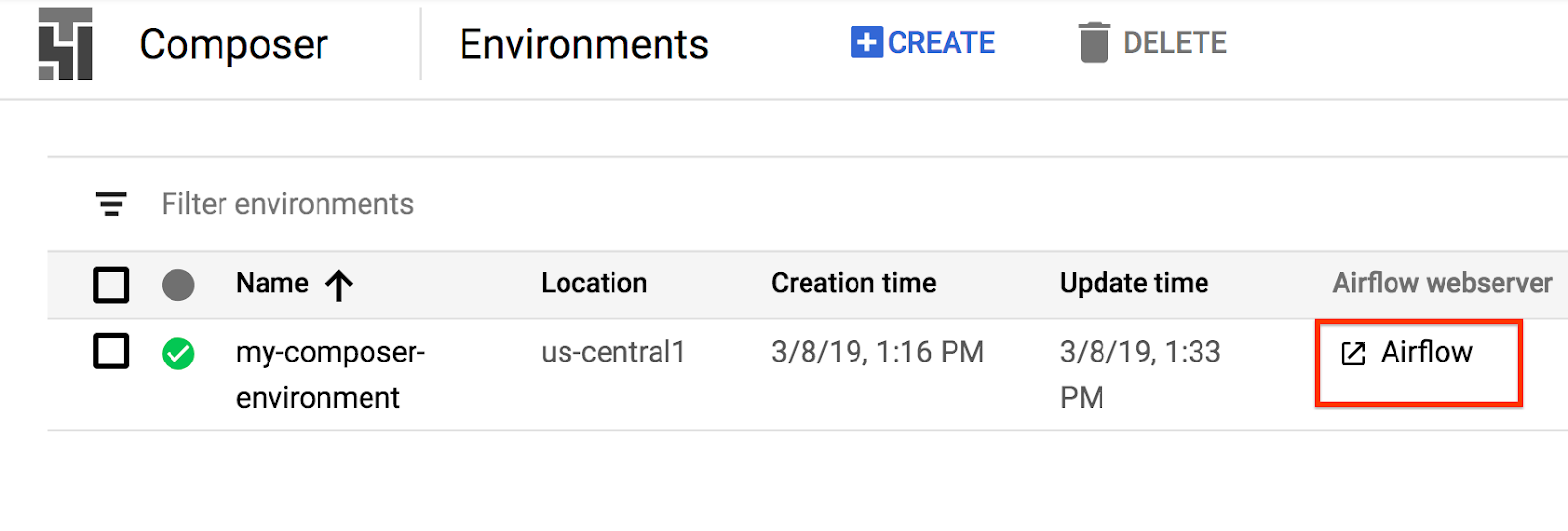
Airflow kullanıcı arayüzü hakkında bilgi edinmek için Web arayüzüne erişme bölümüne bakın.
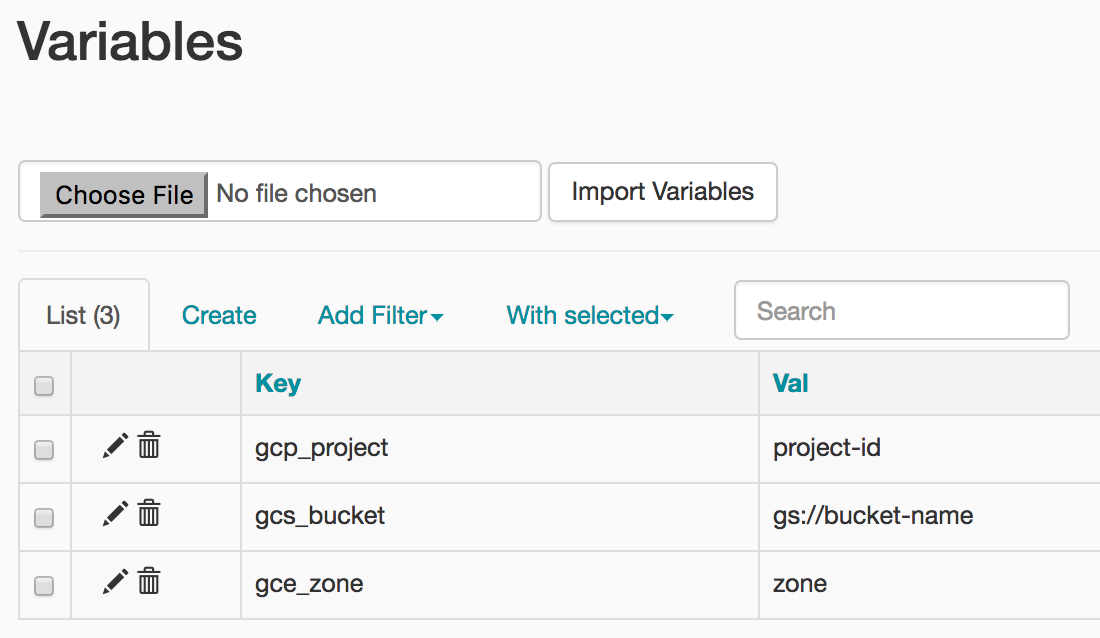
Değişkenleri Görüntüleyin
Daha önce ayarladığınız değişkenler ortamınızda kalır. Yönetici > Değişkenler'i tıklayın.
DAG Çalıştırmalarını Keşfetme
DAG dosyanızı Cloud Storage'daki dags klasörüne yüklediğinizde Cloud Composer dosyayı ayrıştırır. Hata bulunmazsa iş akışının adı DAG girişinde görünür ve iş akışı hemen çalışmak üzere sıraya alınır. DAG'lerinize bakmak için sayfanın üst kısmındaki DAG'ler seçeneğini tıklayın.
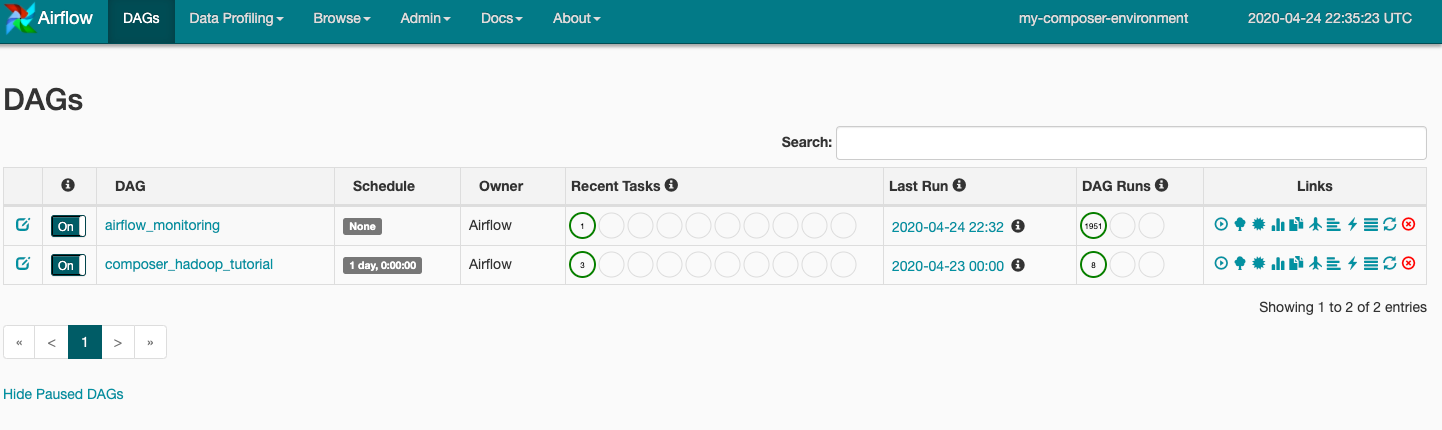
DAG ayrıntıları sayfasını açmak için composer_hadoop_tutorial simgesini tıklayın. Bu sayfada iş akışı görevlerinin ve bağımlılıklarının grafik bir sunumu bulunmaktadır.
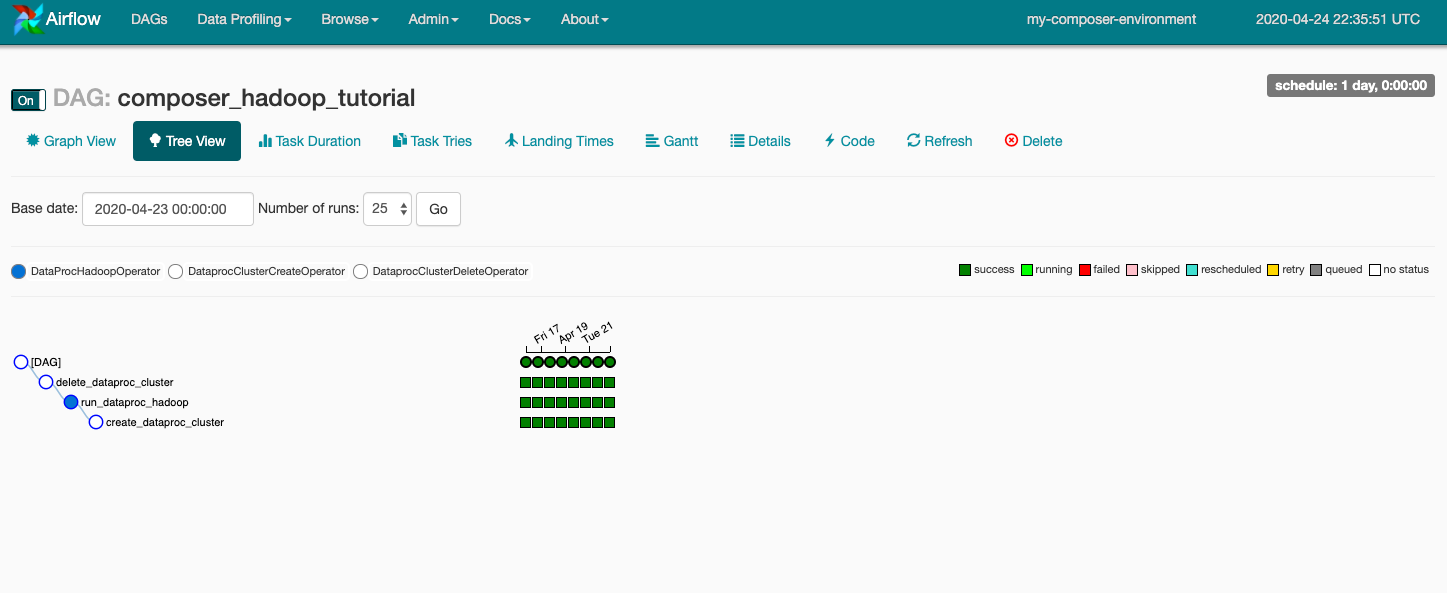
Şimdi, araç çubuğunda Grafik Görünümü'nü tıklayın ve ardından her görevin durumunu görmek için fareyle grafiğin üzerine gelin. Her görevin çevresindeki kenarlığın da durumu gösterdiğini unutmayın (yeşil kenarlık = çalışıyor; kırmızı = başarısız vb.).
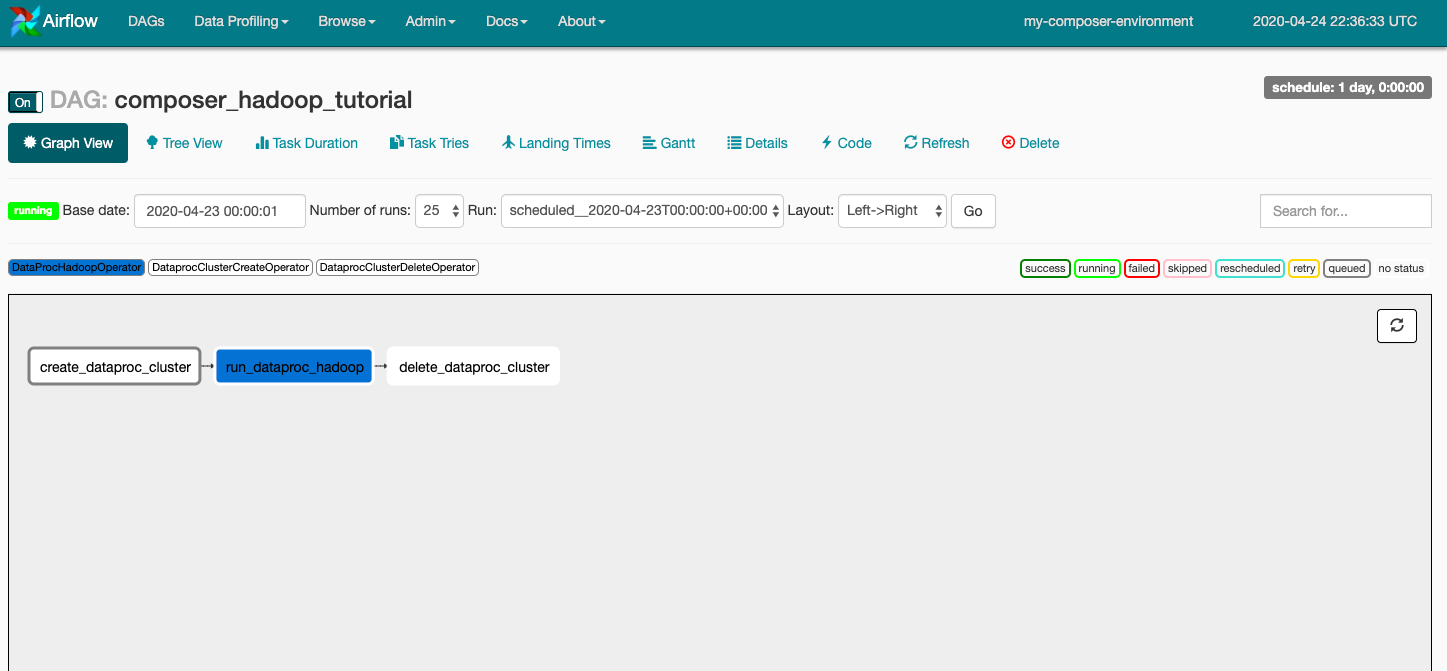
İş akışını Grafik Görünümü'nden tekrar çalıştırmak için:
- Airflow Kullanıcı Arayüzü Grafiği Görünümü'nde
create_dataproc_clustergrafiğini tıklayın. - Üç görevi sıfırlamak için Temizle'yi, ardından işlemi onaylamak için Tamam'ı tıklayın.
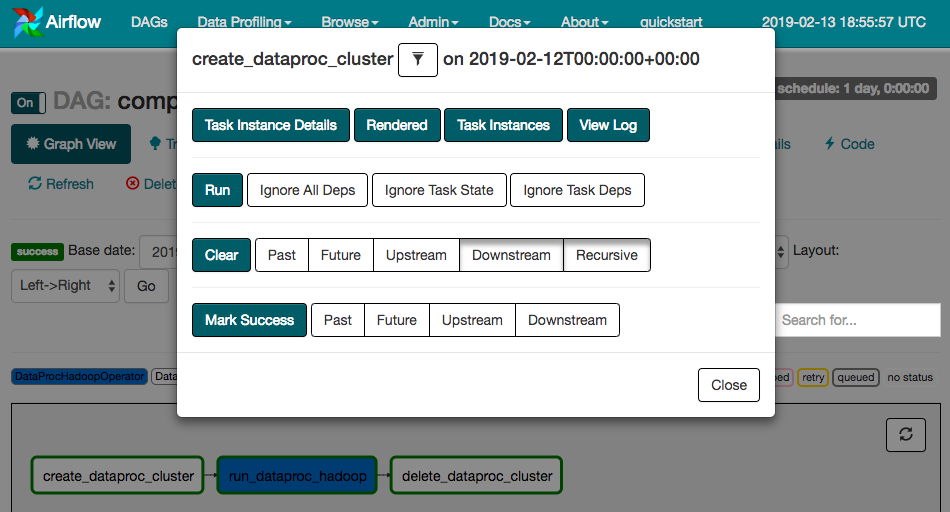
Aşağıdaki GCP Console sayfalarına giderek composer-hadoop-tutorial iş akışının durumunu ve sonuçlarını da kontrol edebilirsiniz:
- Kümenin oluşturulmasını ve silinmesini izlemek için Cloud Dataproc Kümeleri. İş akışı tarafından oluşturulan kümenin geçici olduğunu unutmayın: Yalnızca iş akışı süresince mevcuttur ve son iş akışı görevinin bir parçası olarak silinir.
- Apache Hadoop kelime sayısı işini görüntülemek veya izlemek için Cloud Dataproc İşleri. İş günlüğü çıkışını görmek için İş Kimliği'ni tıklayın.
- Bu codelab için oluşturduğunuz Cloud Storage paketinde bulunan
wordcountklasöründeki kelime sayısının sonuçlarını görmek için Cloud Storage Tarayıcısı'nı tıklayın.
7. Temizleme
Bu codelab'de kullanılan kaynaklar için GCP hesabınızın ücretlendirilmesini önlemek amacıyla:
- (İsteğe bağlı) Verilerinizi kaydetmek istiyorsanız Cloud Composer ortamına ait Cloud Storage paketinden ve bu codelab için oluşturduğunuz depolama paketinden verileri indirin.
- Bu codelab için oluşturduğunuz Cloud Storage paketini silin.
- Ortam için Cloud Storage paketini silin.
- Cloud Composer ortamını silin. Ortamınızı sildiğinizde ortama ait depolama paketinin silinmeyeceğini unutmayın.
İsterseniz projeyi silebilirsiniz:
- GCP Console'da Projeler sayfasına gidin.
- Proje listesinde, silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- Kutuya proje kimliğini yazın ve ardından projeyi silmek için Kapat'ı tıklayın.