
Como executar um job de contagem de palavras do Hadoop em um cluster do Dataproc
Sobre este codelab
1. Introdução
Os fluxos de trabalho são um caso de uso comum em análise de dados. Eles envolvem ingestão, transformação e análise de dados para encontrar informações significativas neles. A ferramenta do Google Cloud Platform para orquestrar fluxos de trabalho é o Cloud Composer, que é uma versão hospedada da famosa ferramenta de fluxo de trabalho de código aberto Apache Airflow. Neste laboratório, você vai usar o Cloud Composer para criar um fluxo de trabalho simples que cria um cluster do Cloud Dataproc, analisa esse cluster com o Cloud Dataproc e o Apache Hadoop e depois exclui esse cluster.
O que é o Cloud Composer?
O Google Cloud Composer é um serviço totalmente gerenciado de orquestração de fluxos de trabalho que permite criar, agendar e monitorar canais que abrangem nuvens e data centers no local. Criado no conhecido projeto de código aberto Apache Airflow (em inglês) e operado com a linguagem de programação Python, o Cloud Composer é fácil de usar e deixa você livre da dependência tecnológica.
Ao usar o Cloud Composer em vez de uma instância local do Apache Airflow, os usuários se beneficiam do melhor do Airflow sem sobrecarga de instalação ou gerenciamento.
O que é Apache Airflow?
O Apache Airflow é uma ferramenta de código aberto usada para criar, programar e monitorar fluxos de trabalho programaticamente. Você vai ver alguns termos importantes relacionados ao Airflow que serão usados ao longo do laboratório:
- O DAG (gráfico acíclico dirigido) é uma coleção de tarefas organizadas que você quer programar e executar. Os DAGs, também chamados de fluxos de trabalho, são definidos em arquivos Python padrão
- Operador: um operador descreve uma única tarefa em um fluxo de trabalho.
O que é o Cloud Dataproc?
O Cloud Dataproc é o serviço Apache Spark e Apache Hadoop totalmente gerenciado do Google Cloud Platform. O Cloud Dataproc se integra facilmente a outros serviços do GCP, oferecendo uma plataforma completa e potente de processamento de dados, análise e machine learning.
Atividades do laboratório
Neste codelab, mostramos como criar e executar um fluxo de trabalho do Apache Airflow no Cloud Composer que realiza as seguintes tarefas:
- Cria um cluster do Cloud Dataproc
- Executa um job de contagem de palavras do Apache Hadoop no cluster e envia os resultados para o Cloud Storage
- Exclui o cluster
O que você vai aprender
- Como criar e executar um fluxo de trabalho do Apache Airflow no Cloud Composer
- Como usar o Cloud Composer e o Cloud Dataproc para executar uma análise em um conjunto de dados
- Como acessar o ambiente do Cloud Composer por meio do Console do Google Cloud Platform, do SDK do Cloud e da interface da Web do Airflow
O que é necessário
- Conta do GCP
- Conhecimentos básicos sobre CLI
- compreensão básica do Python
2. Como configurar o GCP
Criar o projeto
Selecione ou crie um projeto do Google Cloud Platform.
Anote o ID do projeto, porque ele será usado nas próximas etapas.
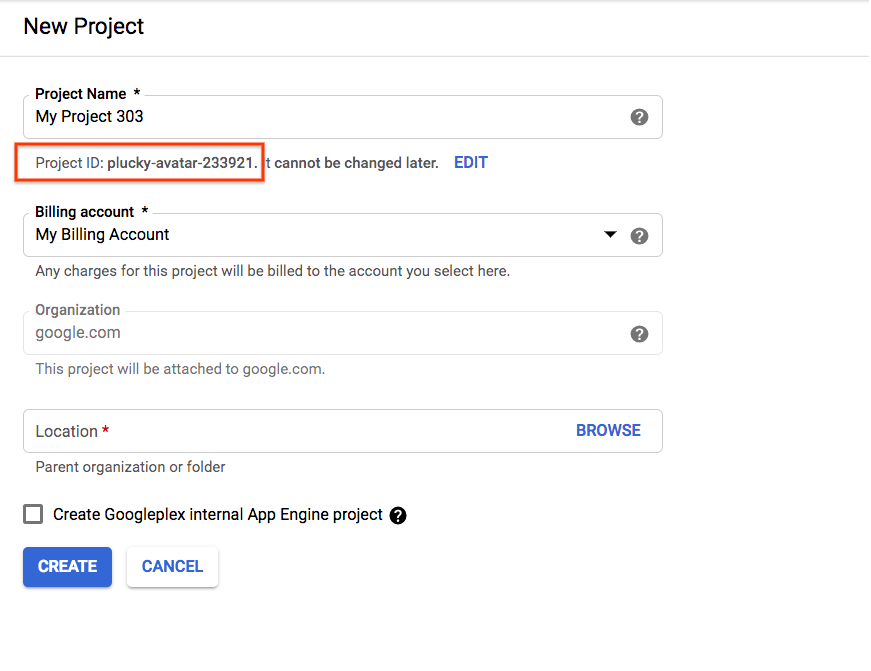
Se você estiver criando um novo projeto, o ID dele pode ser encontrado logo abaixo do nome do projeto na página de criação. |
|
Se você já criou um projeto, é possível encontrar o ID na página inicial do console no card "Informações do projeto" |
|

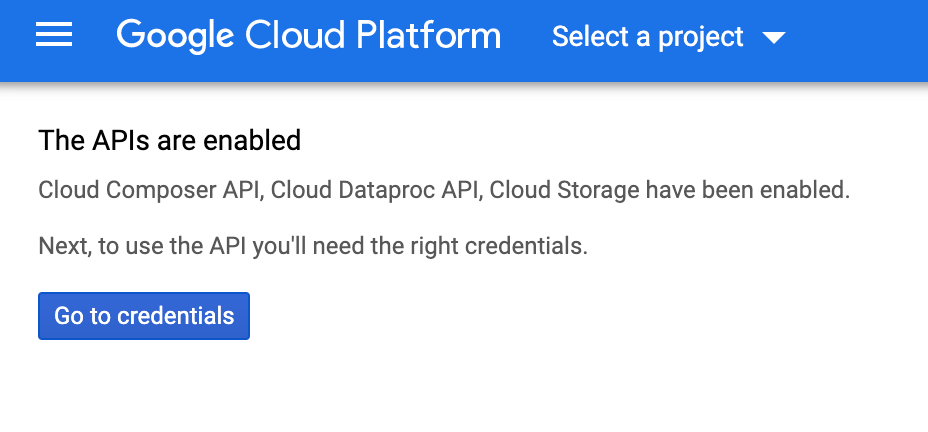
Ativar as APIs
Ative as APIs Cloud Composer, Cloud Dataproc e Cloud Storage.Depois de fazer isso, ignore o botão "Acessar credenciais" e prossiga para a próxima etapa do tutorial. |
|

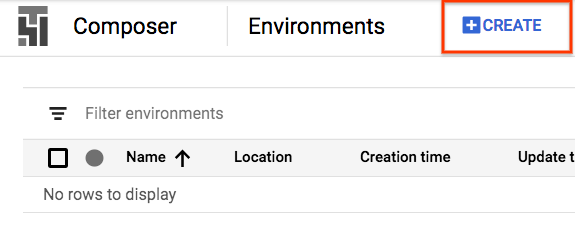
Criar ambiente do Composer
Crie um ambiente do Cloud Composer com a seguinte configuração:
Todas as outras configurações podem permanecer nos valores padrão. Clique em "Criar". na parte de baixo. |
|

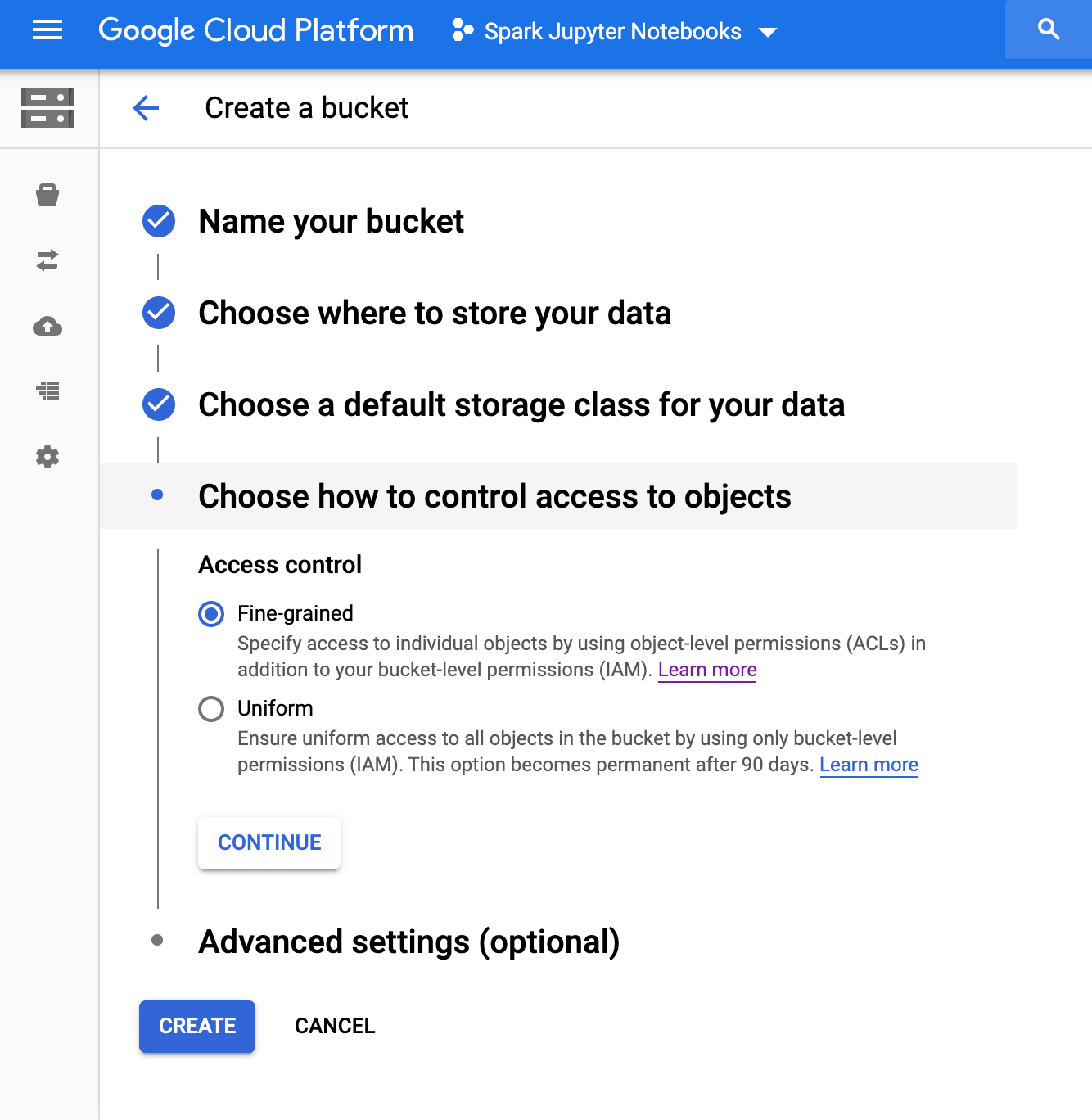
Crie o bucket do Cloud Storage
No seu projeto, crie um bucket do Cloud Storage com a seguinte configuração:
Pressione "Criar" quando estiver tudo pronto |
|
3. Como configurar o Apache Airflow
Como visualizar informações de ambiente do Composer
No Console do GCP, abra a página Ambientes
Clique no nome do ambiente para conferir os detalhes.
A página Detalhes do ambiente mostra o URL da interface da Web do Airflow, o ID do cluster do Google Kubernetes Engine, o nome do bucket do Cloud Storage e o caminho da pasta /dags.
No Airflow, um gráfico acíclico dirigido DAG é uma coleção de tarefas organizadas que você quer programar e executar. Os DAGs, também chamados de fluxos de trabalho, são definidos em arquivos Python padrão. O Cloud Composer só programa os DAGs que estão na pasta /dags. A pasta /dags está no bucket do Cloud Storage que o Cloud Composer cria automaticamente quando você cria o ambiente.
Como definir variáveis de ambiente do Apache Airflow
As variáveis do Apache Airflow são um conceito específico da plataforma e diferente das variáveis de ambiente. Nesta etapa, você vai definir as três variáveis do Airflow a seguir: gcp_project, gcs_bucket e gce_zone.
Como usar gcloud para definir variáveis
Primeiro, abra o Cloud Shell, que tem o SDK Cloud instalado de forma prática.
Defina a variável de ambiente COMPOSER_INSTANCE como o nome do ambiente do Composer
COMPOSER_INSTANCE=my-composer-environment
Para definir variáveis do Airflow usando a ferramenta de linha de comando gcloud, use o comando gcloud composer environments run com o subcomando variables. O comando gcloud composer executa o subcomando variables da CLI do Airflow. O subcomando transmite os argumentos para a ferramenta de linha de comando gcloud.
Você executará esse comando três vezes, substituindo as variáveis pelas que forem relevantes para o projeto.
Defina gcp_project usando o comando a seguir, substituindo <your-project-id> pelo ID do projeto que você anotou na Etapa 2.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
A saída será mais ou menos assim
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
Defina gcs_bucket usando o comando a seguir, substituindo <your-bucket-name> pelo ID do bucket que você anotou na Etapa 2. Se você seguiu nossa recomendação, o nome do bucket é o mesmo do ID do projeto. A resposta será semelhante ao comando anterior.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
Defina gce_zone usando o comando a seguir. A resposta será semelhante aos comandos anteriores.
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(Opcional) Como usar gcloud para ver uma variável
Para ver o valor de uma variável, execute o subcomando variables da CLI do Airflow com o argumento get ou use a interface do Airflow.
Exemplo:
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
É possível fazer isso com qualquer uma das três variáveis que você acabou de definir: gcp_project, gcs_bucket e gce_zone.
4. Fluxo de trabalho de amostra
Vejamos o código do DAG que usaremos na etapa 5. Não se preocupe com o download de arquivos ainda, apenas acompanhe aqui.
Há muito a ser desvendado aqui, então vamos analisar um pouco mais.
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
Vamos começar com algumas importações do Airflow:
airflow.models: permite acessar e criar dados no banco de dados do Airflow.airflow.contrib.operators: onde os operadores da comunidade moram. Nesse caso, precisamos dodataproc_operatorpara acessar a API Cloud Dataproc.airflow.utils.trigger_rule: para adicionar regras de acionadores aos operadores. As regras de gatilho permitem um controle refinado sobre a execução de um operador de acordo com o status dos pais.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
Isso especifica a localização do nosso arquivo de saída. A linha models.Variable.get('gcs_bucket'), que extrai o valor da variável gcs_bucket do banco de dados do Airflow,
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR: localização do arquivo .jar que será executado no cluster do Cloud Dataproc. Ele já está hospedado no GCP para você.input_file: localização do arquivo que contém os dados em que nosso job do Hadoop calculará. Faremos upload dos dados para esse local juntos na Etapa 5.wordcount_args: argumentos que serão transmitidos no arquivo jar.
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
Isso nos dará um objeto datetime equivalente que representa a meia-noite do dia anterior. Por exemplo, se isso for executado às 11:00 de 4 de março, o objeto datetime representará 00:00 em 3 de março. Isso tem a ver com a forma como o Airflow lida com a programação. Veja mais informações neste link.
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
A variável default_dag_args na forma de um dicionário precisa ser fornecida sempre que um novo DAG é criado:
'email_on_failure': indica se alertas por e-mail precisam ser enviados quando uma tarefa falha.'email_on_retry': indica se alertas por e-mail precisam ser enviados quando uma nova tentativa de tarefa é repetida'retries': indica quantas tentativas de repetição o Airflow deve fazer em caso de falha do DAG.'retry_delay': indica quanto tempo o Airflow deve aguardar antes de tentar uma nova tentativa.'project_id': informa ao DAG o código do projeto do GCP para associá-lo, que será necessário posteriormente com o operador do Dataproc
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
O uso de with models.DAG instrui o script a incluir tudo que está abaixo dele no mesmo DAG. Também podemos ver três argumentos transmitidos:
- O primeiro, uma string, é o nome dado ao DAG que estamos criando. Neste caso, estamos usando
composer_hadoop_tutorial. schedule_interval: um objetodatetime.timedelta, que aqui é definido como um dia. Isso significa que este DAG tentará ser executado uma vez por dia após o'start_date'definido anteriormente em'default_dag_args'.default_args: o dicionário que criamos anteriormente contendo os argumentos padrão do DAG
crie um cluster do Dataproc
Em seguida, criaremos um dataproc_operator.DataprocClusterCreateOperator que cria um cluster do Cloud Dataproc.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
Nesse operador, vemos alguns argumentos, todos com exceção do primeiro, que são específicos dele:
task_id: assim como no BashOperator, esse é o nome que atribuímos ao operador e que pode ser visualizado na interface do Airflow.cluster_name: o nome que atribuímos ao cluster do Cloud Dataproc. Aqui, o nomeamoscomposer-hadoop-tutorial-cluster-{{ ds_nodash }}(consulte a caixa de informações para informações adicionais opcionais).num_workers: o número de workers que alocamos para o cluster do Cloud Dataproc.zone: a região geográfica em que queremos que o cluster fique, conforme salvo no banco de dados do Airflow. Isso lerá a variável'gce_zone'definida na Etapa 3.master_machine_type: o tipo de máquina que queremos alocar para o mestre do Cloud Dataprocworker_machine_type: o tipo de máquina que queremos alocar para o worker do Cloud Dataproc
Envie um job do Apache Hadoop
O dataproc_operator.DataProcHadoopOperator nos permite enviar um job para um cluster do Cloud Dataproc.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
Oferecemos vários parâmetros:
task_id: nome que atribuímos a essa parte do DAGmain_jar: localização do arquivo .jar que queremos executar no clustercluster_name: nome do cluster em que o job será executado, que é idêntico ao que encontramos no operador anteriorarguments: argumentos que são passados para o arquivo jar, como você faria se estivesse executando o arquivo .jar na linha de comando.
Exclua o cluster
O último operador que vamos criar é o dataproc_operator.DataprocClusterDeleteOperator.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
Como o nome sugere, esse operador exclui um determinado cluster do Cloud Dataproc. Há três argumentos aqui:
task_id: assim como no BashOperator, esse é o nome que atribuímos ao operador e que pode ser visualizado na interface do Airflow.cluster_name: o nome que atribuímos ao cluster do Cloud Dataproc. Aqui, o nomeamoscomposer-hadoop-tutorial-cluster-{{ ds_nodash }}. Confira mais informações opcionais na caixa de informações depois de "Criar um cluster do Dataproc".trigger_rule: mencionamos brevemente as regras de acionamento durante as importações no início desta etapa, mas aqui temos uma em ação. Por padrão, um operador do Airflow não é executado a menos que todos os operadores upstream tenham sido concluídos com sucesso. A regra de acionadorALL_DONEexige apenas que todos os operadores upstream tenham sido concluídos, independentemente de terem sido bem-sucedidos ou não. Aqui, isso significa que, mesmo que o job do Hadoop falhe, ainda queremos destruir o cluster.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Por fim, queremos que esses operadores sejam executados em uma ordem específica, e podemos denotar isso usando operadores bitshift do Python. Nesse caso, create_dataproc_cluster sempre será executado primeiro, seguido por run_dataproc_hadoop e, por fim, delete_dataproc_cluster.
Juntando tudo, o código vai ficar assim:
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. fazer upload de arquivos do Airflow para o Cloud Storage
Copie o DAG para a pasta /dags
- Primeiro, abra o Cloud Shell, que tem o SDK Cloud instalado de forma prática.
- Clonar o repositório de exemplos em Python e mudar para o diretório composer/workflows
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- Execute o seguinte comando para definir o nome da sua pasta de DAGs como uma variável de ambiente
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- Execute o comando
gsutila seguir para copiar o código do tutorial para o local em que a pasta /dags é criada
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
A resposta será semelhante a esta:
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. Como usar a IU do Airflow
Para acessar a interface da Web do Airflow pelo Console do GCP, siga estas etapas:
|
|

Para saber mais sobre a IU do Airflow, consulte Como acessar a interface da Web.
Conferir variáveis
As variáveis já definidas são mantidas no seu ambiente. Para conferir as variáveis, selecione Administrador > Variáveis da barra de menus da interface do Airflow.
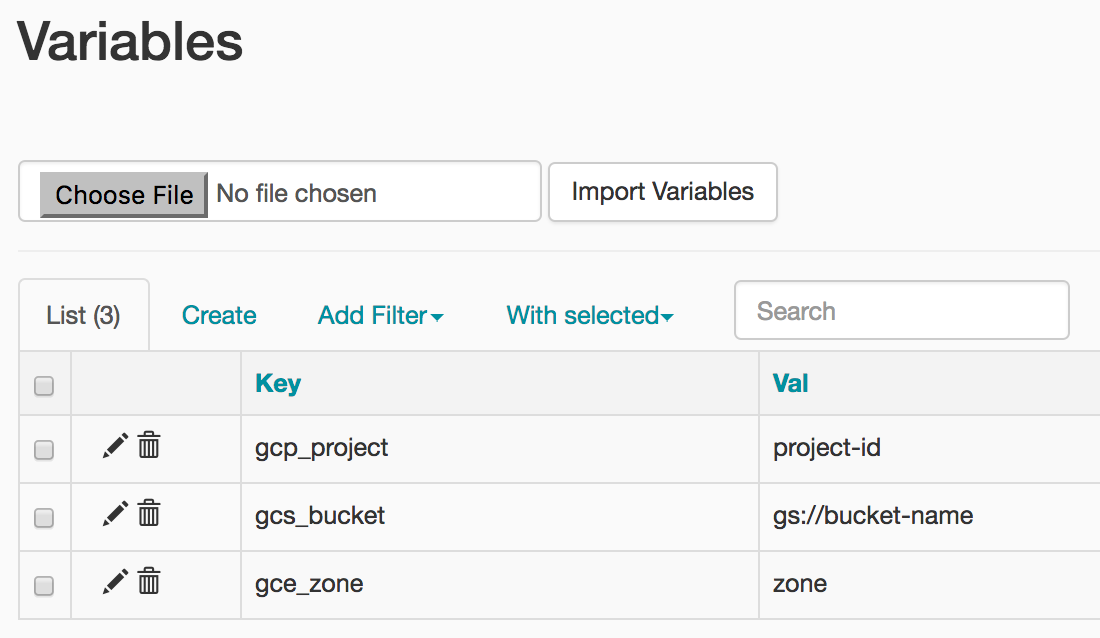
Como analisar as execuções de DAG
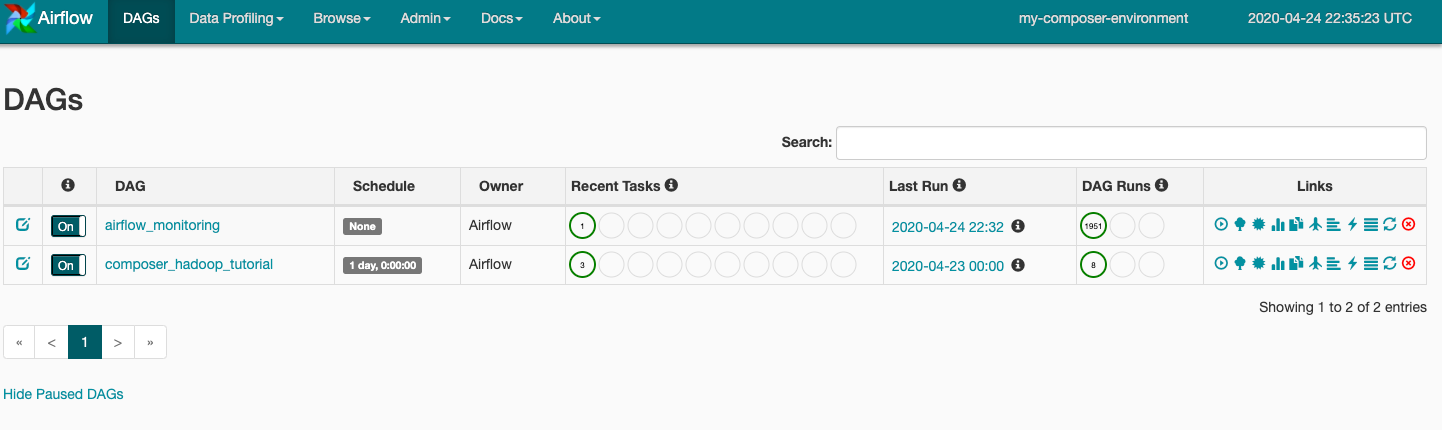
Quando você faz upload do arquivo DAG para a pasta dags no Cloud Storage, o Cloud Composer analisa o arquivo. Se nenhum erro for encontrado, o nome do fluxo de trabalho será exibido na lista de DAGs e entrará na fila para ser executado imediatamente. Clique em DAGs na parte de cima da página para conferir os DAGs.
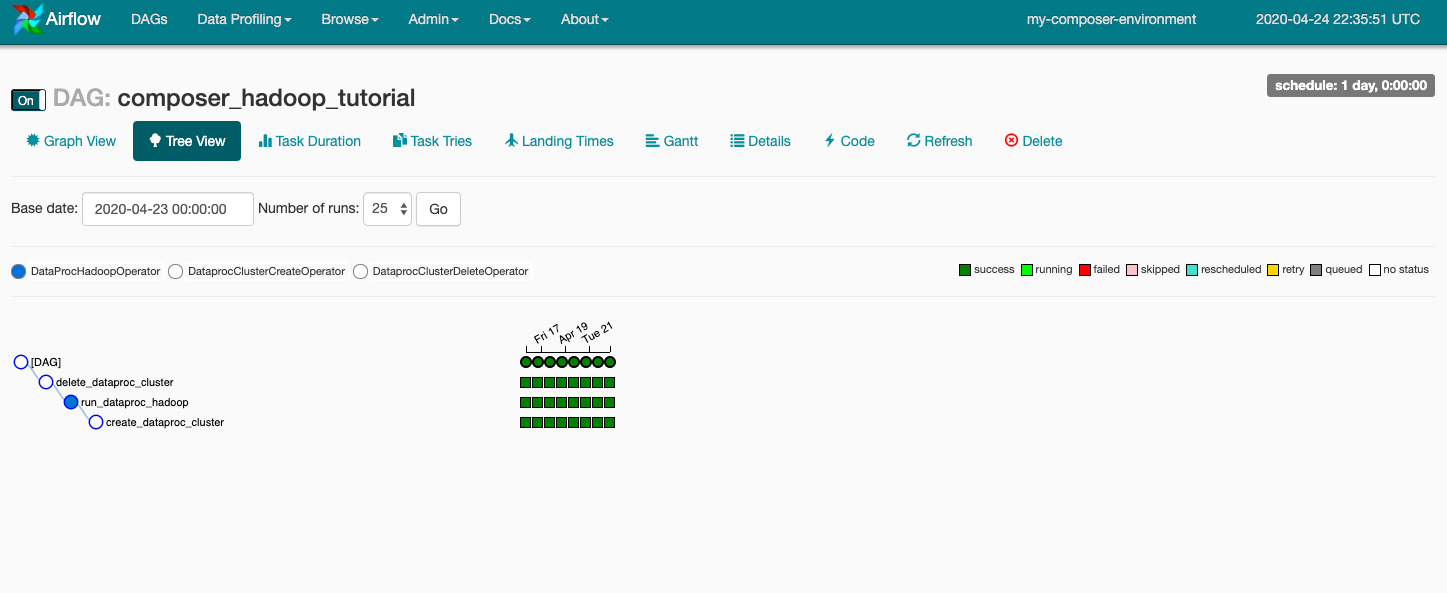
Clique em composer_hadoop_tutorial para abrir a página de detalhes do DAG. Nela, você encontra uma representação gráfica das tarefas e das dependências do fluxo de trabalho.
Na barra de ferramentas, clique em Exibição de gráfico e passe o cursor sobre o gráfico de cada tarefa para ver o status de cada uma. A borda das tarefas também indica o status: verde = em execução, vermelha = falha etc.
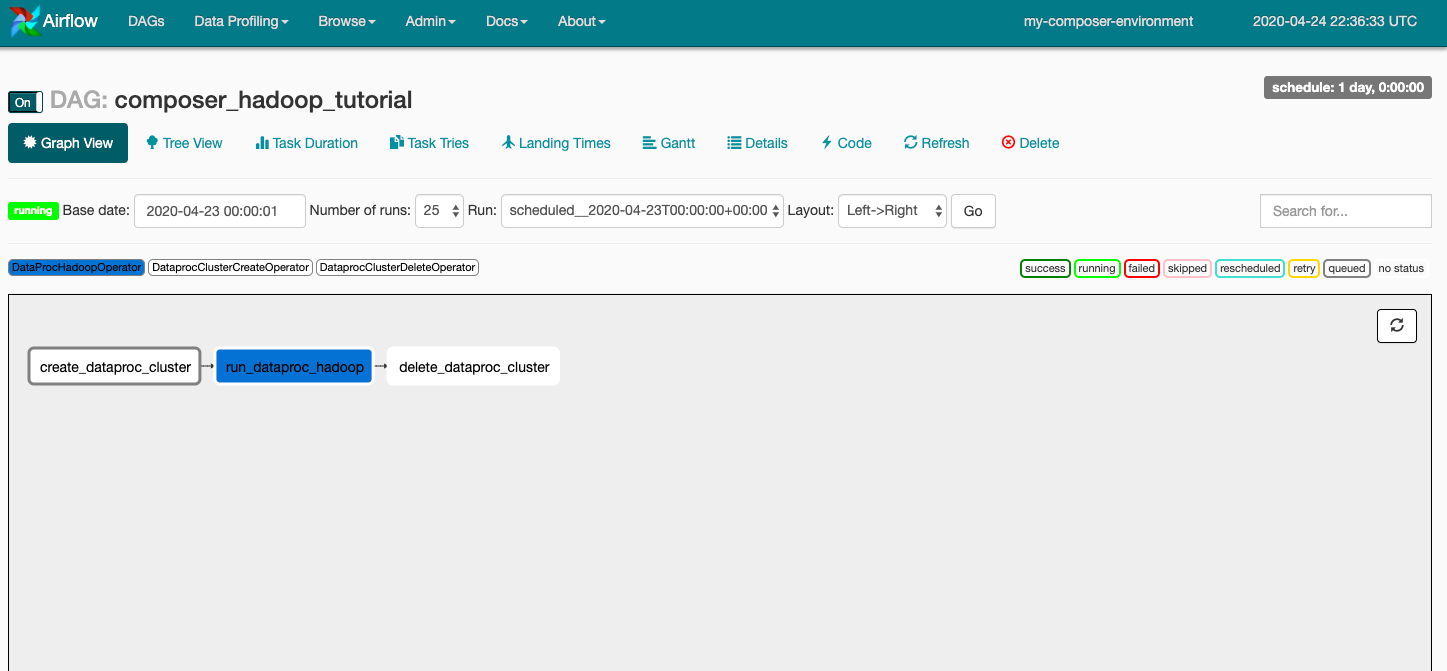
Para executar o fluxo de trabalho novamente a partir da Visualização de gráfico:
- Na visualização de gráfico da IU do Airflow, clique no gráfico
create_dataproc_cluster. - Clique em Clear para redefinir as três tarefas e em OK para confirmar.
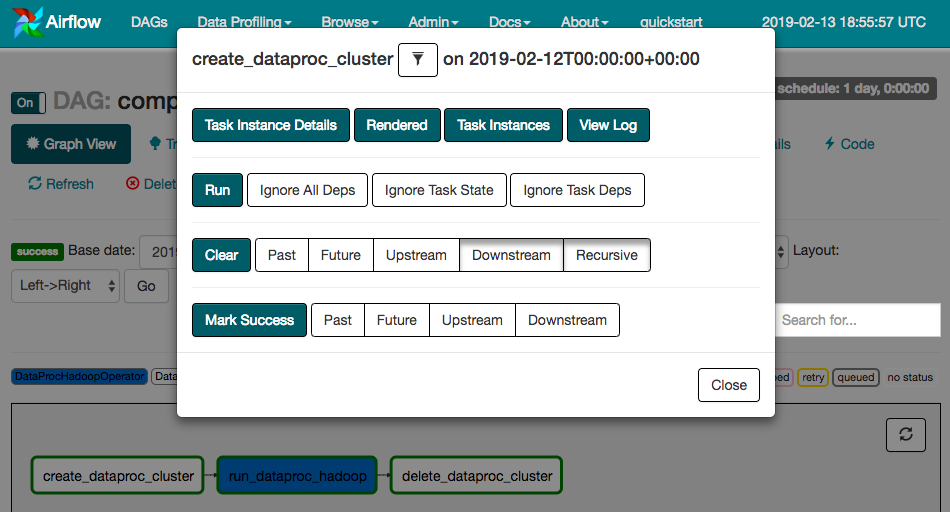
Também é possível verificar o status e os resultados do fluxo de trabalho composer-hadoop-tutorial nas seguintes páginas do Console do GCP:
- Clusters do Cloud Dataproc para monitorar a criação e a exclusão de clusters. Observe que o cluster criado pelo fluxo de trabalho é efêmero: ele existe apenas durante o fluxo de trabalho e é excluído como parte da última tarefa dele.
- Jobs do Cloud Dataproc para visualizar ou monitorar o job de contagem de palavras do Apache Hadoop. Clique no ID do job para ver a saída do registro dele.
- Navegador do Cloud Storage para conferir os resultados da contagem de palavras na pasta
wordcountdo bucket do Cloud Storage que você criou para este codelab.
7. Limpeza
Para evitar cobranças dos recursos usados neste codelab na conta do GCP, siga estas etapas:
- (Opcional) Para salvar seus dados, faça o download dos dados do bucket do Cloud Storage para o ambiente do Cloud Composer e o bucket de armazenamento que você criou para este codelab.
- Exclua o bucket do Cloud Storage que você criou para este codelab.
- Exclua o bucket do Cloud Storage do ambiente.
- Exclua o ambiente do Cloud Composer. A exclusão do ambiente não remove o bucket de armazenamento dele.
Também é possível excluir o projeto:
- No Console do GCP, acesse a página Projetos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa, digite o ID do projeto e clique em Encerrar para excluí-lo.