
1. Einführung
Übersicht
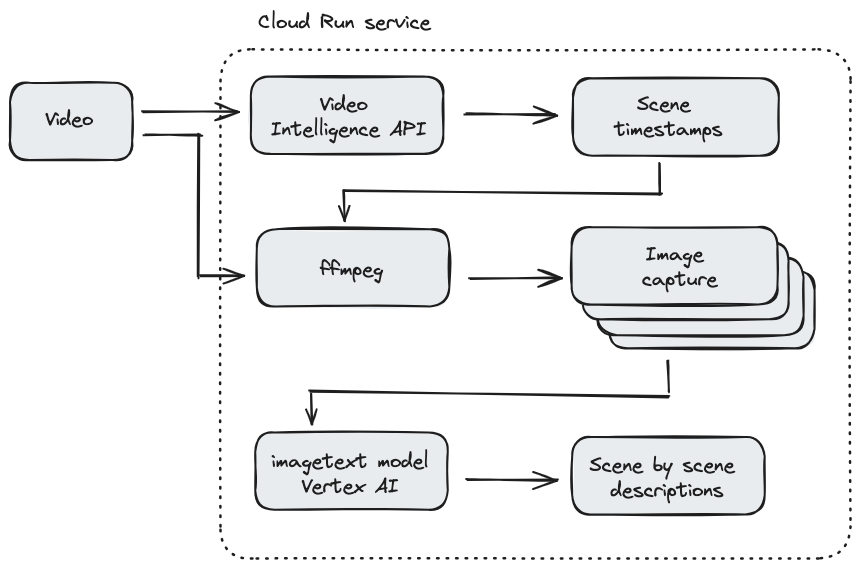
In diesem Codelab erstellen Sie einen in Node.js geschriebenen Cloud Run-Dienst, der eine visuelle Beschreibung jeder Szene in einem Video bietet. Zuerst verwendet Ihr Dienst die Video Intelligence API, um die Zeitstempel zu erkennen, wenn sich eine Szene ändert. Als Nächstes verwendet Ihr Dienst ein Drittanbieter-Binärprogramm namens ffmpeg, um für jeden Szenenwechselzeitstempel einen Screenshot zu erstellen. Schließlich werden visuelle Untertitel in Vertex AI verwendet, um eine visuelle Beschreibung der Screenshots bereitzustellen.
In diesem Codelab wird außerdem gezeigt, wie Sie ffmpeg in Ihrem Cloud Run-Dienst verwenden, um Bilder aus einem Video mit einem bestimmten Zeitstempel zu erfassen. Da ffmpeg unabhängig installiert werden muss, erfahren Sie in diesem Codelab, wie Sie ein Dockerfile erstellen, um ffmpeg als Teil Ihres Cloud Run-Dienstes zu installieren.
Hier sehen Sie ein Beispiel dafür, wie der Cloud Run-Dienst funktioniert:
Aufgaben in diesem Lab
- Container-Image mit einem Dockerfile erstellen und ein Drittanbieter-Binärprogramm installieren
- Anleitung zum Prinzip der geringsten Berechtigung durch Erstellen eines Dienstkontos für den Cloud Run-Dienst, um andere Google Cloud-Dienste aufzurufen
- Video Intelligence-Clientbibliothek aus einem Cloud Run-Dienst verwenden
- Google APIs aufrufen, um die visuelle Beschreibung jeder Szene aus Vertex AI zu erhalten
2. Einrichtung und Anforderungen
Voraussetzungen
- Sie sind in der Cloud Console angemeldet.
- Sie haben zuvor einen Cloud Run-Dienst bereitgestellt. Weitere Informationen finden Sie beispielsweise in der Kurzanleitung: Webdienst aus dem Quellcode bereitstellen.
Cloud Shell aktivieren
- Klicken Sie in der Cloud Console auf Cloud Shell aktivieren
 .
.

Wenn Sie Cloud Shell zum ersten Mal starten, wird ein Zwischenbildschirm mit einer Beschreibung der Funktion angezeigt. Wenn ein Zwischenbildschirm angezeigt wird, klicken Sie auf Weiter.

Die Bereitstellung und Verbindung mit Cloud Shell dauert nur einen Moment.

Diese virtuelle Maschine verfügt über alle erforderlichen Entwicklertools. Es bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und wird in Google Cloud ausgeführt. Dadurch werden die Netzwerkleistung und die Authentifizierung erheblich verbessert. Viele, wenn nicht sogar alle Arbeiten in diesem Codelab können mit einem Browser erledigt werden.
Sobald Sie mit Cloud Shell verbunden sind, sollten Sie sehen, dass Sie authentifiziert sind und das Projekt auf Ihre Projekt-ID eingestellt ist.
- Führen Sie in Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Sie authentifiziert sind:
gcloud auth list
Befehlsausgabe
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Führen Sie in Cloud Shell den folgenden Befehl aus, um zu prüfen, ob der gcloud-Befehl Ihr Projekt kennt:
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Ist dies nicht der Fall, können Sie die Einstellung mit diesem Befehl vornehmen:
gcloud config set project <PROJECT_ID>
Befehlsausgabe
Updated property [core/project].
3. APIs aktivieren und Umgebungsvariablen festlegen
Bevor Sie dieses Codelab verwenden können, müssen Sie mehrere APIs aktivieren. Für dieses Codelab müssen die folgenden APIs verwendet werden. Sie können diese APIs aktivieren, indem Sie den folgenden Befehl ausführen:
gcloud services enable run.googleapis.com \
storage.googleapis.com \
cloudbuild.googleapis.com \
videointelligence.googleapis.com \
aiplatform.googleapis.com
Dann können Sie Umgebungsvariablen festlegen, die in diesem Codelab verwendet werden.
REGION=<YOUR-REGION> PROJECT_ID=<YOUR-PROJECT-ID> PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)') SERVICE_NAME=video-describer export BUCKET_ID=$PROJECT_ID-video-describer
4. Cloud Storage-Bucket erstellen
Erstellen Sie einen Cloud Storage-Bucket, in den Sie mit dem folgenden Befehl Videos zur Verarbeitung durch den Cloud Run-Dienst hochladen können:
gsutil mb -l us-central1 gs://$BUCKET_ID/
[Optional] Sie können dieses Beispielvideo verwenden, indem Sie es lokal herunterladen.
gsutil cp gs://cloud-samples-data/video/visionapi.mp4 testvideo.mp4
Laden Sie nun die Videodatei in Ihren Storage-Bucket hoch.
FILENAME=<YOUR-VIDEO-FILENAME> gsutil cp $FILENAME gs://$BUCKET_ID
5. Node.js-Anwendung erstellen
Erstellen Sie zunächst ein Verzeichnis für den Quellcode und speichern Sie das Verzeichnis mit cd.
mkdir video-describer && cd $_
Erstellen Sie dann eine package.json-Datei mit folgendem Inhalt:
{
"name": "video-describer",
"version": "1.0.0",
"private": true,
"description": "describes the image in every scene for a given video",
"main": "index.js",
"author": "Google LLC",
"license": "Apache-2.0",
"scripts": {
"start": "node index.js"
},
"dependencies": {
"@google-cloud/storage": "^7.7.0",
"@google-cloud/video-intelligence": "^5.0.1",
"axios": "^1.6.2",
"express": "^4.18.2",
"fluent-ffmpeg": "^2.1.2",
"google-auth-library": "^9.4.1"
}
}
Diese Anwendung besteht aus mehreren Quelldateien, um die Lesbarkeit zu verbessern. Erstellen Sie zuerst eine index.js-Quelldatei mit dem unten stehenden Inhalt. Diese Datei enthält den Einstiegspunkt für den Dienst und die Hauptlogik für die Anwendung.
const { captureImages } = require('./imageCapture.js');
const { detectSceneChanges } = require('./sceneDetector.js');
const transcribeScene = require('./imageDescriber.js');
const { Storage } = require('@google-cloud/storage');
const fs = require('fs').promises;
const path = require('path');
const express = require('express');
const app = express();
const bucketName = process.env.BUCKET_ID;
const port = parseInt(process.env.PORT) || 8080;
app.listen(port, () => {
console.log(`video describer service ready: listening on port ${port}`);
});
// entry point for the service
app.get('/', async (req, res) => {
try {
// download the requested video from Cloud Storage
let videoFilename = req.query.filename;
console.log("processing file: " + videoFilename);
// download the file to locally to the Cloud Run instance
let localFilename = await downloadVideoFile(videoFilename);
// detect all the scenes in the video & save timestamps to an array
let timestamps = await detectSceneChanges(localFilename);
console.log("Detected scene changes at the following timestamps: ", timestamps);
// create an image of each scene change
// and save to a local directory called "output"
await captureImages(localFilename, timestamps);
// get an access token for the Service Account to call the Google APIs
let accessToken = await transcribeScene.getAccessToken();
console.log("got an access token");
let imageBaseName = path.parse(localFilename).name;
// the data structure for storing the scene description and timestamp
// e.g. an array of json objects {timestamp: 1, description: "..."}, etc.
let scenes = []
// for each timestamp, send the image to Vertex AI
console.log("getting Vertex AI description all the timestamps");
scenes = await Promise.all(
timestamps.map(async (timestamp) => {
let filepath = path.join("./output", imageBaseName + "-" + timestamp + ".png");
// get the base64 encoded image
const encodedFile = await fs.readFile(filepath, 'base64');
// send each screenshot to Vertex AI for description
let description = await transcribeScene.transcribeScene(accessToken, encodedFile)
return { timestamp: timestamp, description: description };
}));
console.log("finished collecting all the scenes");
//console.log(scenes);
return res.json(scenes);
} catch (error) {
//return an error
console.log("received error: ", error);
return res.status(500).json("an internal error occurred");
}
});
async function downloadVideoFile(videoFilename) {
// Creates a client
const storage = new Storage();
// keep same name locally
let localFilename = videoFilename;
const options = {
destination: localFilename
};
// Download the file
await storage.bucket(bucketName).file(videoFilename).download(options);
console.log(
`gs://${bucketName}/${videoFilename} downloaded locally to ${localFilename}.`
);
return localFilename;
}
Erstellen Sie als Nächstes eine viewDetector.js-Datei mit dem folgenden Inhalt. Für diese Datei wird die Video Intelligence API verwendet, um zu erkennen, wenn sich Szenen im Video ändern.
const fs = require('fs');
const util = require('util');
const readFile = util.promisify(fs.readFile);
const ffmpeg = require('fluent-ffmpeg');
const Video = require('@google-cloud/video-intelligence');
const client = new Video.VideoIntelligenceServiceClient();
module.exports = {
detectSceneChanges: async function (downloadedFile) {
// Reads a local video file and converts it to base64
const file = await readFile(downloadedFile);
const inputContent = file.toString('base64');
// setup request for shot change detection
const videoContext = {
speechTranscriptionConfig: {
languageCode: 'en-US',
enableAutomaticPunctuation: true,
},
};
const request = {
inputContent: inputContent,
features: ['SHOT_CHANGE_DETECTION'],
};
// Detects camera shot changes
const [operation] = await client.annotateVideo(request);
console.log('Shot (scene) detection in progress...');
const [operationResult] = await operation.promise();
// Gets shot changes
const shotChanges = operationResult.annotationResults[0].shotAnnotations;
console.log("Shot (scene) changes detected: " + shotChanges.length);
// data structure to be returned
let sceneChanges = [];
// for the initial scene
sceneChanges.push(1);
// if only one scene, keep at 1 second
if (shotChanges.length === 1) {
return sceneChanges;
}
// get length of video
const videoLength = await getVideoLength(downloadedFile);
shotChanges.forEach((shot, shotIndex) => {
if (shot.endTimeOffset === undefined) {
shot.endTimeOffset = {};
}
if (shot.endTimeOffset.seconds === undefined) {
shot.endTimeOffset.seconds = 0;
}
if (shot.endTimeOffset.nanos === undefined) {
shot.endTimeOffset.nanos = 0;
}
// convert to a number
let currentTimestampSecond = Number(shot.endTimeOffset.seconds);
let sceneChangeTime = 0;
// double-check no scenes were detected within the last second
if (currentTimestampSecond + 1 > videoLength) {
sceneChangeTime = currentTimestampSecond;
} else {
// otherwise, for simplicity, just round up to the next second
sceneChangeTime = currentTimestampSecond + 1;
}
sceneChanges.push(sceneChangeTime);
});
return sceneChanges;
}
}
async function getVideoLength(localFile) {
let getLength = util.promisify(ffmpeg.ffprobe);
let length = await getLength(localFile);
console.log("video length: ", length.format.duration);
return length.format.duration;
}
Erstellen Sie nun eine Datei namens imageCapture.js mit folgendem Inhalt. Diese Datei verwendet das Knotenpaket fluent-ffmpeg, um ffmpeg-Befehle in einer Knotenanwendung auszuführen.
const ffmpeg = require('fluent-ffmpeg');
const path = require('path');
const util = require('util');
module.exports = {
captureImages: async function (localFile, scenes) {
let imageBaseName = path.parse(localFile).name;
try {
for (scene of scenes) {
console.log("creating screenshot for scene: ", + scene);
await createScreenshot(localFile, imageBaseName, scene);
}
} catch (error) {
console.log("error gathering screenshots: ", error);
}
console.log("finished gathering the screenshots");
}
}
async function createScreenshot(localFile, imageBaseName, scene) {
return new Promise((resolve, reject) => {
ffmpeg(localFile)
.screenshots({
timestamps: [scene],
filename: `${imageBaseName}-${scene}.png`,
folder: 'output',
size: '320x240'
}).on("error", () => {
console.log("Failed to create scene for timestamp: " + scene);
return reject('Failed to create scene for timestamp: ' + scene);
})
.on("end", () => {
return resolve();
});
})
}
Erstellen Sie abschließend eine Datei namens „imagedescriber.js“ mit folgendem Inhalt. Diese Datei verwendet Vertex AI, um eine visuelle Beschreibung jedes Szenenbilds zu erhalten.
const axios = require("axios");
const { GoogleAuth } = require('google-auth-library');
const auth = new GoogleAuth({
scopes: 'https://www.googleapis.com/auth/cloud-platform'
});
module.exports = {
getAccessToken: async function () {
return await auth.getAccessToken();
},
transcribeScene: async function(token, encodedFile) {
let projectId = await auth.getProjectId();
let config = {
headers: {
'Authorization': 'Bearer ' + token,
'Content-Type': 'application/json; charset=utf-8'
}
}
const json = {
"instances": [
{
"image": {
"bytesBase64Encoded": encodedFile
}
}
],
"parameters": {
"sampleCount": 1,
"language": "en"
}
}
let response = await axios.post('https://us-central1-aiplatform.googleapis.com/v1/projects/' + projectId + '/locations/us-central1/publishers/google/models/imagetext:predict', json, config);
return response.data.predictions[0];
}
}
Dockerfile und .dockerignore-Datei erstellen
Da dieser Dienst ffmpeg verwendet, müssen Sie ein Dockerfile erstellen, das ffmpeg installiert.
Erstellen Sie eine Datei mit dem Namen Dockerfile, die folgenden Inhalt enthält:
# Copyright 2020 Google, LLC. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Use the official lightweight Node.js image. # https://hub.docker.com/_/node FROM node:20.10.0-slim # Create and change to the app directory. WORKDIR /usr/src/app RUN apt-get update && apt-get install -y ffmpeg # Copy application dependency manifests to the container image. # A wildcard is used to ensure both package.json AND package-lock.json are copied. # Copying this separately prevents re-running npm install on every code change. COPY package*.json ./ # Install dependencies. # If you add a package-lock.json speed your build by switching to 'npm ci'. # RUN npm ci --only=production RUN npm install --production # Copy local code to the container image. COPY . . # Run the web service on container startup. CMD [ "npm", "start" ]
Außerdem erstellen Sie eine Datei mit dem Namen „.dockerignore“, um die Containerisierung bestimmter Dateien zu ignorieren.
Dockerfile .dockerignore node_modules npm-debug.log
6. Dienstkonto erstellen
Sie erstellen ein Dienstkonto für den Cloud Run-Dienst, um auf Cloud Storage, Vertex AI und die Video Intelligence API zuzugreifen.
SERVICE_ACCOUNT="cloud-run-video-description" SERVICE_ACCOUNT_ADDRESS=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Cloud Run Video Scene Image Describer service account" # to view & download storage bucket objects gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_ADDRESS \ --role=roles/storage.objectViewer # to call the Vertex AI imagetext model gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_ADDRESS \ --role=roles/aiplatform.user
7. Cloud Run-Dienst bereitstellen
Jetzt können Sie eine quellbasierte Bereitstellung verwenden, um Ihren Cloud Run-Dienst automatisch in Container zu verlagern.
Hinweis: Die Standardverarbeitungszeit für einen Cloud Run-Dienst beträgt 60 Sekunden. In diesem Codelab wird ein Zeitlimit von 5 Minuten verwendet, da das vorgeschlagene Testvideo 2 Minuten lang ist. Wenn Sie ein Video mit einer längeren Dauer verwenden, müssen Sie möglicherweise die Uhrzeit ändern.
gcloud run deploy $SERVICE_NAME \ --region=$REGION \ --set-env-vars BUCKET_ID=$BUCKET_ID \ --no-allow-unauthenticated \ --service-account $SERVICE_ACCOUNT_ADDRESS \ --timeout=5m \ --source=.
Speichern Sie nach der Bereitstellung die Dienst-URL in einer Umgebungsvariablen.
SERVICE_URL=$(gcloud run services describe $SERVICE_NAME --platform managed --region $REGION --format 'value(status.url)')
8. Cloud Run-Dienst aufrufen
Jetzt können Sie Ihren Dienst aufrufen, indem Sie den Namen des Videos angeben, das Sie in Cloud Storage hochgeladen haben.
curl -X GET -H "Authorization: Bearer $(gcloud auth print-identity-token)" ${SERVICE_URL}?filename=${FILENAME}
Die Ergebnisse sollten in etwa so aussehen:
[{"timestamp":1,"description":"an aerial view of a city with a bridge in the background"},{"timestamp":7,"description":"a man in a blue shirt sits in front of shelves of donuts"},{"timestamp":11,"description":"a black and white photo of people working in a bakery"},{"timestamp":12,"description":"a black and white photo of a man and woman working in a bakery"}]
9. Glückwunsch!
Herzlichen Glückwunsch zum Abschluss des Codelabs!
Wir empfehlen Ihnen, die Dokumentation zur Video Intelligence API, zu Cloud Run und zur visuellen Untertitelung mit Vertex AI zu lesen.
Behandelte Themen
- Container-Image mit einem Dockerfile erstellen und ein Drittanbieter-Binärprogramm installieren
- Anleitung zum Prinzip der geringsten Berechtigung durch Erstellen eines Dienstkontos für den Cloud Run-Dienst, um andere Google Cloud-Dienste aufzurufen
- Video Intelligence-Clientbibliothek aus einem Cloud Run-Dienst verwenden
- Google APIs aufrufen, um die visuelle Beschreibung jeder Szene aus Vertex AI zu erhalten
10. Bereinigen
Um versehentliche Gebühren zu vermeiden, z. B. wenn dieser Cloud Run-Dienst versehentlich häufiger aufgerufen wird als Ihre monatliche Zuweisung von Cloud Run-Aufrufen in der kostenlosen Stufe, können Sie entweder den Cloud Run-Dienst oder das in Schritt 2 erstellte Projekt löschen.
Wenn Sie den Cloud Run-Dienst löschen möchten, rufen Sie die Cloud Run-Cloud Console unter https://console.cloud.google.com/run/ auf und löschen Sie die Funktion video-describer (oder $SERVICE_NAME, falls Sie einen anderen Namen verwendet haben).
Wenn Sie das gesamte Projekt löschen möchten, rufen Sie https://console.cloud.google.com/cloud-resource-manager auf, wählen Sie das in Schritt 2 erstellte Projekt aus und klicken Sie auf „Löschen“. Wenn Sie das Projekt löschen, müssen Sie die Projekte in Ihrem Cloud SDK ändern. Sie können die Liste aller verfügbaren Projekte mit dem Befehl gcloud projects list aufrufen.