
1. 소개

사기 행위에는 연결된 법인의 숨겨진 네트워크가 포함되는 경우가 많습니다. 예를 들어 동일한 이메일 주소, 전화번호 또는 실제 주소를 공유하는 여러 계정이 있습니다. 기존 관계형 데이터베이스는 이러한 복잡한 멀티 홉 관계를 효율적으로 쿼리하는 데 어려움을 겪을 수 있습니다.
BigQuery 그래프를 사용하면 그래프 데이터베이스를 사용하여 이러한 네트워크를 대규모로 분석할 수 있습니다. 기존 BigQuery 테이블 위에 속성 그래프를 정의하고 그래프 쿼리 언어 (GQL)를 사용하여 데이터에서 패턴을 찾을 수 있습니다.
사기 감지를 위한 그래프 네트워크의 일반적인 적용 사례는 사기 네트워크와 연결된 배송 주소가 있는 주문을 중지하거나
이 Codelab에서는 BigQuery 그래프를 사용하여 사기 감지 솔루션을 빌드합니다. Cloud Storage에서 데이터를 로드하고, 속성 그래프를 만들고, 그래프 쿼리를 사용하여 의심스러운 연결을 식별합니다.
학습할 내용
- BigQuery 데이터 세트를 만들고 데이터를 로드하는 방법
- DDL을 사용하여 속성 그래프를 정의하는 방법
- GQL을 사용하여 그래프를 쿼리하는 방법
- 그래프 분석을 사용하여 사기를 감지하는 방법
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트.
- BigQuery 노트북 환경 (BigQuery Studio 또는 Colab Enterprise)
비용
이 실습에서는 비용이 청구될 수 있는 Google Cloud 리소스를 사용합니다. 완료 후 리소스를 삭제하면 예상 비용은 5달러 미만입니다.
2. 시작하기 전에
Google Cloud 프로젝트 선택 또는 만들기
- Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Google Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
환경 선택
이 실습을 실행하려면 노트북 환경이 필요합니다. BigQuery Studio 또는 Colab Enterprise를 사용할 수 있습니다.
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
- Python 노트북을 사용하여 그래프 쿼리를 실행합니다.
Cloud Shell 시작
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- 인증을 확인합니다.
gcloud auth list
- 프로젝트를 확인합니다.
gcloud config get project
- 필요한 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API 사용 설정
다음 명령어를 실행하여 필요한 BigQuery API를 사용 설정합니다.
gcloud services enable bigquery.googleapis.com
3. 데이터 로드
이 단계에서는 BigQuery 데이터 세트를 만들고 Cloud Storage에서 샘플 데이터를 로드합니다.
샘플 데이터는 시뮬레이션된 소매 환경을 나타내는 여러 CSV 파일로 구성됩니다.
customers.csv: 고객 계정 정보입니다.emails.csv: 이메일 주소입니다.phones.csv: 전화번호입니다.addresses.csv: 실제 주소입니다.customer_emails.csv,customer_phones.csv,customer_addresses.csv: 테이블 연결orders.csv: 사기 플래그를 포함한 주문 내역입니다.
데이터세트 만들기
테이블을 저장할 fraud_demo이라는 데이터 세트를 만듭니다.
- 이 Codelab에서는 SQL 명령어를 실행합니다. BigQuery Studio > SQL 편집기에서 이러한 명령어를 실행하거나 Cloud Shell에서
bq query명령어를 사용할 수 있습니다. 여러 줄로 된 생성 문을 더 효과적으로 사용하려면 BigQuery SQL 편집기를 사용하는 것이 좋습니다.
여러 줄로 된 생성 문을 더 효과적으로 사용하려면 BigQuery SQL 편집기를 사용하는 것이 좋습니다.
CREATE SCHEMA IF NOT EXISTS `fraud_demo` OPTIONS(location="US");
표 로드
다음 SQL 문을 실행하여 Cloud Storage에서 데이터 세트로 데이터를 로드합니다.
LOAD DATA OVERWRITE `fraud_demo.customers`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customers.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.orders`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/orders.csv'],
skip_leading_rows = 1
);
4. 속성 그래프 만들기
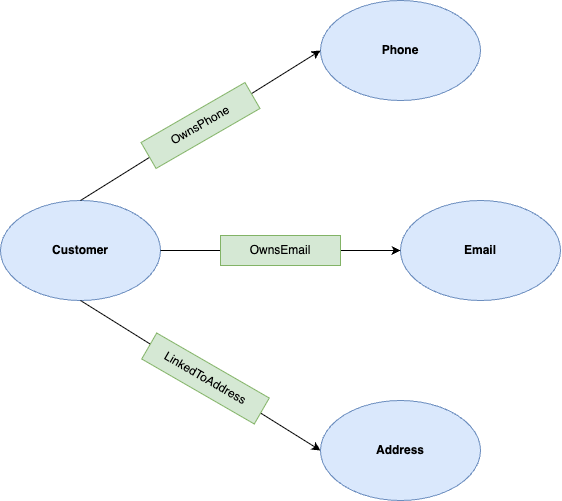
이제 데이터가 로드되었으므로 속성 그래프를 정의할 수 있습니다. 속성 그래프는 노드 (항목)와 모서리 (관계)로 구성됩니다.
이 실습에서 노드는 다음과 같습니다.
- 고객: 계정 소유자를 나타냅니다.
- 전화: 전화번호를 나타냅니다.
- 이메일: 이메일 주소를 나타냅니다.
- 주소: 실제 주소를 나타냅니다.
가장자리는 다음과 같습니다.
- OwnsPhone: 고객을 전화번호에 연결합니다.
- OwnsEmail: 고객을 이메일에 연결합니다.
- LinkedToAddress: 고객을 주소에 연결합니다.
그래프 만들기
다음 DDL 문을 실행하여 fraud_demo 데이터 세트에 FraudDemo이라는 그래프를 만듭니다.
CREATE OR REPLACE PROPERTY GRAPH fraud_demo.FraudDemo
NODE TABLES(
fraud_demo.customers
KEY(account_id)
LABEL Customer PROPERTIES(
account_id,
name),
fraud_demo.emails
KEY(email)
LABEL Email PROPERTIES(
email,
email_type),
fraud_demo.phones
KEY(phone_number)
LABEL Phone PROPERTIES(
phone_number,
phone_type),
fraud_demo.addresses
KEY(address)
LABEL Address PROPERTIES(
address,
address_type)
)
EDGE TABLES(
fraud_demo.customer_emails
KEY(account_id, email)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(email) REFERENCES emails(email)
LABEL OwnsEmail PROPERTIES(
account_id,
email,
last_updated_ts),
fraud_demo.customer_phones
KEY(account_id, phone_number)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(phone_number) REFERENCES phones(phone_number)
LABEL OwnsPhone PROPERTIES(
account_id,
phone_number,
last_updated_ts),
fraud_demo.customer_addresses
KEY(account_id, address)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(address) REFERENCES addresses(address)
LABEL LinkedToAddress PROPERTIES(
account_id,
address,
last_updated_ts)
);
5. 네트워크 분석 (2홉)
BigQuery Studio에서 새 노트북을 엽니다.

이 Codelab의 시각화 및 추천 부분에서는 BigQuery Studio의 Google Colab 노트북을 사용합니다. 이렇게 하면 그래프 결과를 쉽게 시각화할 수 있습니다.
BigQuery 그래프 노트북은 IPython 매직으로 구현됩니다. TO_JSON 함수와 함께 %%bigquery 매직 명령어를 추가하면 다음 섹션에 표시된 대로 결과를 시각화할 수 있습니다. 이 단계에서는 그래프 쿼리를 실행하여 계정 간의 간단한 연결을 찾습니다. 시작 노드에서 2홉을 이동하여 관련 노드를 찾으므로 '2홉' 쿼리입니다 (예: 고객 -> 이메일 -> 고객).
니콜 웨이드의 계정부터 조사하겠습니다. 2홉을 통해 그녀와 관련된 계정을 찾고 싶습니다.
2홉 쿼리 실행
노트북에서 다음 쿼리를 실행합니다.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p=(a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){2}
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Verify the final node in the hop array is a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(1)]))
RETURN TO_JSON(p) AS paths
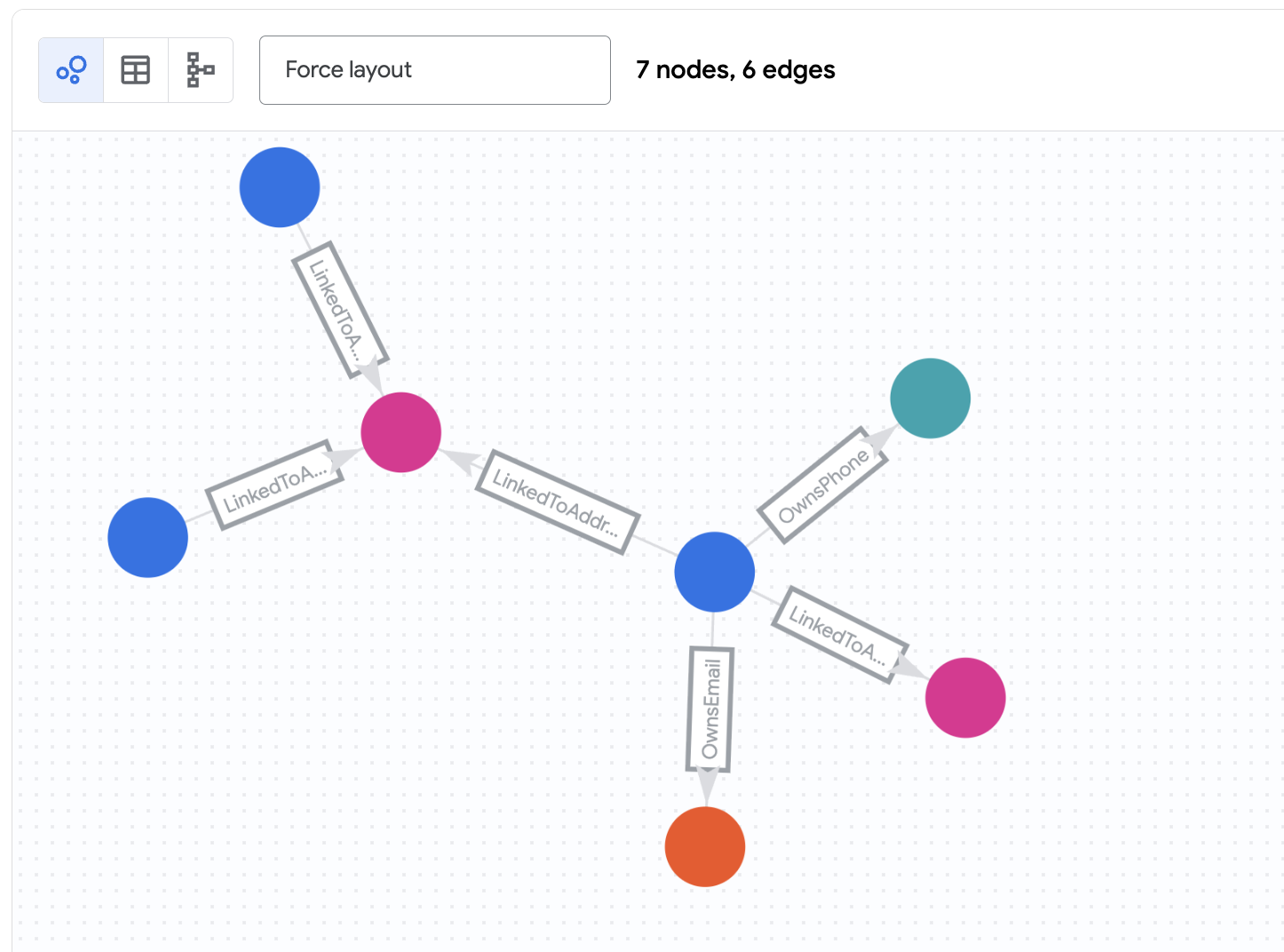
결과 이해하기
이 쿼리는 다음과 같은 작업을 합니다.
account_id'd2f1f992-d116-41b3-955b-6c76a3352657' (니콜 웨이드)로Customer노드에서 시작합니다.OwnsEmail,OwnsPhone또는LinkedToAddress가장자리를 따라 연결 노드 (Phone,Email또는Address)로 이동합니다.- 연결 노드에서 다른
Customer노드로 에지를 따라 돌아갑니다. - 타임스탬프 (
last_updated_ts)를 기반으로 가장자리를 필터링하여 특정 시점의 네트워크 상태를 확인합니다.
Zachary Cordova와 Brenda Brown이 동일한 주소를 통해 Nicole에 연결되어 있는 것을 확인할 수 있습니다.
6. 네트워크 분석 (4홉)
이 단계에서는 더 복잡한 관계를 찾기 위해 쿼리를 확장합니다. 4홉 연결을 찾습니다. 이를 통해 여러 중간 법인 (예: 고객 A -> 이메일 -> 고객 B -> 전화 -> 고객 C)을 통해 연결된 계정을 찾을 수 있습니다.
시간이 지남에 따라 이 네트워크가 어떻게 변화하는지도 관찰합니다.
'이전' 상태
먼저 2025년 7월 30일에 존재했던 네트워크를 살펴보겠습니다.
다음 쿼리를 실행합니다.
%%bigquery --graph
%%bigquery --graph
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
GRAPH fraud_demo.FraudDemo
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count

'After' 상태
이제 2주 후 네트워크가 어떻게 표시되는지 살펴보겠습니다. 동일한 쿼리를 실행하되 날짜 제한은 적용하지 않습니다.
다음 쿼리를 실행합니다.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count

결과 이해하기
날짜 필터를 삭제하면 전체 데이터 세트에 대해 쿼리하게 됩니다. 네트워크가 크게 성장한 것을 확인할 수 있습니다. 니콜 웨이드는 이제 훨씬 더 큰, 긴밀하게 연결된 그룹에 속해 있습니다. 연결된 네트워크의 이러한 급격한 확장은 시간이 지남에 따라 리소스를 공유하는 사기 조직과 같은 사기 행위가 발생할 수 있음을 나타내는 강력한 지표입니다.
7. 사기 보고서 생성
이 단계에서는 그래프 분석과 기존 비즈니스 데이터 (주문)를 결합하여 포괄적인 사기 보고서를 생성합니다. 위험한 계정과 잠재적인 사기 주문을 식별합니다.
이 쿼리는 더 복잡합니다. GRAPH_TABLE를 사용하여 표준 SQL 내에서 그래프 쿼리를 실행하고 이전 단계에서 관찰한 '이전' 상태와 '이후' 상태 간의 네트워크 크기 변화 (diff)를 계산합니다.
사기 보고서 쿼리 실행
노트북에서 다음 쿼리를 실행합니다.
%%bigquery --graph
WITH num_orders AS (
SELECT account_id, COUNT(1) AS num_order
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
GROUP BY account_id
),
orders AS (
SELECT account_id, order_id, fraud, order_total
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
),
-- Use Quantified Path Patterns to find connections up to 4 hops away
latest_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
MATCH (a:Customer)-[:OwnsEmail|OwnsPhone|LinkedToAddress]-{4}(connected:Customer)
RETURN a.account_id AS account_id, connected.account_id AS connected_id
)
GROUP BY account_id
),
prev_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
-- Apply the timestamp filter to EVERY edge in the 4-hop chain
MATCH (a:Customer)
(-[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']-(n)){4}
WHERE 'Customer' IN UNNEST(LABELS(n[OFFSET(3)]))
RETURN a.account_id AS account_id, n[OFFSET(3)].account_id AS connected_id
)
GROUP BY account_id
),
edge_changes AS (
SELECT account_id, MAX(last_updated_ts) AS max_last_updated_ts
FROM fraud_demo.customer_addresses
GROUP BY account_id
)
SELECT
la.account_id,
o.order_id,
la.size AS latest_size,
COALESCE(pa.size, 0) AS previous_size,
la.size - COALESCE(pa.size, 0) AS diff,
nos.num_order,
o.fraud AS reported_as_fraud,
o.order_total,
CASE
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NULL THEN "CUSTOMER AT RISK"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND o.fraud THEN "CONFIRMED FRAUD ORDER"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND NOT o.fraud THEN "POTENTIAL FRAUD ORDER"
ELSE ""
END AS notes
FROM latest_connect la
LEFT JOIN prev_connect pa ON la.account_id = pa.account_id
LEFT JOIN num_orders nos ON la.account_id = nos.account_id
LEFT JOIN orders o ON la.account_id = o.account_id
INNER JOIN edge_changes ec ON la.account_id = ec.account_id
WHERE nos.num_order > 1 OR (la.size - COALESCE(pa.size, 0)) > 10
ORDER BY diff DESC
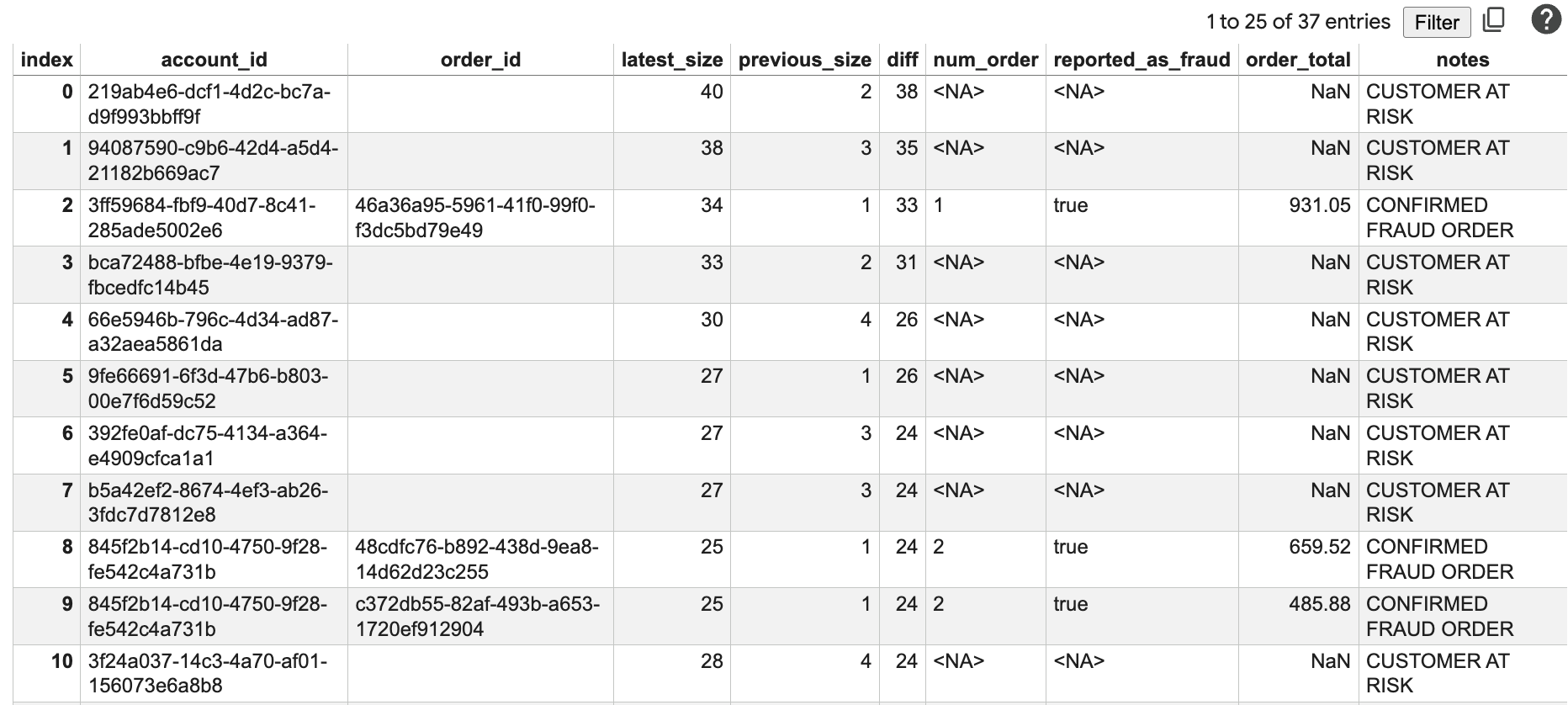
결과 이해하기
이 보고서에는 다음이 표시됩니다.
account_id: 분석 중인 계정의 ID입니다.order_id: 최근 주문 ID입니다.latest_size: 현재 연결된 네트워크의 크기입니다.previous_size: 2주 전 네트워크의 크기입니다.diff: 네트워크 크기의 증가입니다.num_order: 최근 주문 수입니다.reported_as_fraud: 주문이 사기로 신고되었는지 여부입니다.order_total: 주문의 총 금액입니다.notes: 네트워크 성장 및 주문 내역을 기반으로 계산된 위험 상태입니다.
diff 값이 크고 주문 총액이 높은 계정이 표시되며, 이러한 계정은 추가 조사의 주요 대상입니다. '위험 고객' 및 '사기 가능 주문' 메모는 이러한 계정의 우선순위를 지정하는 데 도움이 됩니다.
8. 대규모 감지
이 마지막 분석 단계에서는 더 큰 규모로 네트워크를 시각화합니다. 단일 계정으로 시작하는 대신 의심스러운 계정 집합 간의 연결을 쿼리합니다.
이를 통해 여러 독립적인 조사가 실제로 동일한 대규모 사기 조직의 일부인지 확인할 수 있습니다.
확장된 쿼리 실행
노트북에서 다음 쿼리를 실행합니다.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}
(reachable_a:Customer)
-- these IDs are from the previous results
WHERE a.account_id in ( "845f2b14-cd10-4750-9f28-fe542c4a731b"
, "3ff59684-fbf9-40d7-8c41-285ade5002e6"
, "8887c17b-e6fb-4b3b-8c62-cb721aafd028"
, "03e777e5-6fb4-445d-b48c-cf42b7620874"
, "81629832-eb1d-4a0e-86da-81a198604898"
, "845f2b14-cd10-4750-9f28-fe542c4a731b",
"89e9a8fe-ffc4-44eb-8693-a711a3534849"
)
LIMIT 400
RETURN TO_JSON(p) as paths
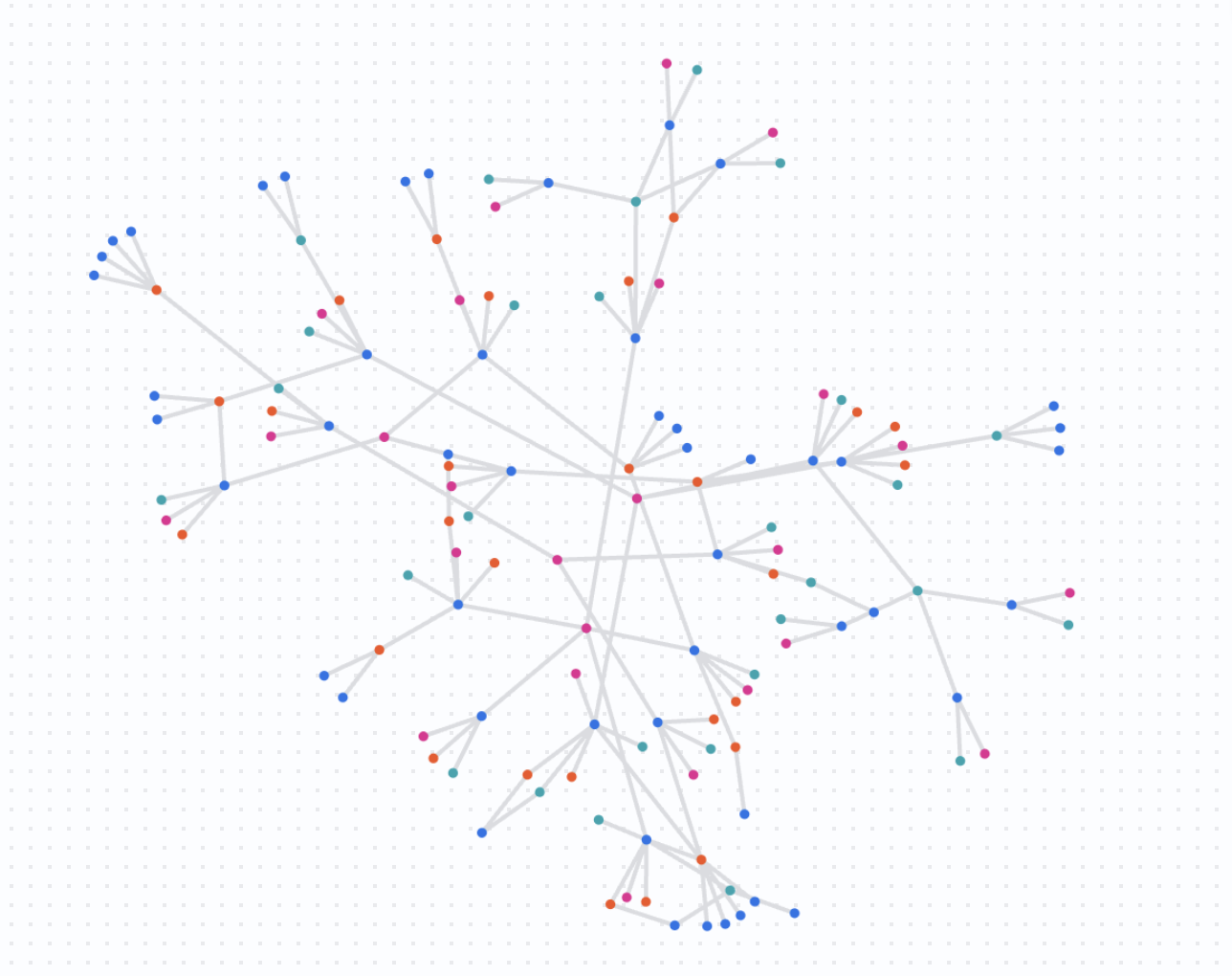
결과 이해하기
이 쿼리는 지정된 의심스러운 계정이 중복되고 리소스를 공유하는 방식을 보여주는 복잡한 그래프를 반환합니다. 이제 대규모 사기 감지를 통해 조정된 대응이 필요할 수 있는 활동 클러스터를 식별할 수 있습니다.
9. 삭제
이 Codelab에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 데이터 세트와 속성 그래프를 삭제해야 합니다.
다음 SQL 문을 실행하여 환경을 정리합니다.
DROP PROPERTY GRAPH IF EXISTS fraud_demo.FraudDemo;
DROP SCHEMA IF EXISTS fraud_demo CASCADE;
10. 축하합니다
축하합니다. BigQuery 그래프를 사용하여 사기 감지 솔루션을 빌드했습니다.
지금까지 학습한 내용은 다음과 같습니다.
- Cloud Storage에서 BigQuery로 데이터를 로드합니다.
- DDL을 사용하여 속성 그래프를 정의합니다.
- GQL을 사용하여 그래프를 쿼리하여 간단한 관계와 복잡한 관계를 찾습니다.
- 그래프 분석과 비즈니스 데이터를 결합하여 위험을 식별합니다.
- 규모에 따라 네트워크를 시각화합니다.
기타 자료