
1. Omówienie

Co to jest Document AI?
Document AI to platforma, która pozwala wydobywać informacje z dokumentów. W podstawie oferuje ona stale rosnącą listę procesorów dokumentów (zwanych też parsownikami lub rozdzielnikami w zależności od ich funkcji).
Możesz zarządzać procesorami Document AI na 2 sposoby:
- ręcznie z poziomu konsoli internetowej;
- programowo za pomocą interfejsu Document AI API.
Oto przykładowy zrzut ekranu z listą procesorów z konsoli internetowej i kodu Pythona:
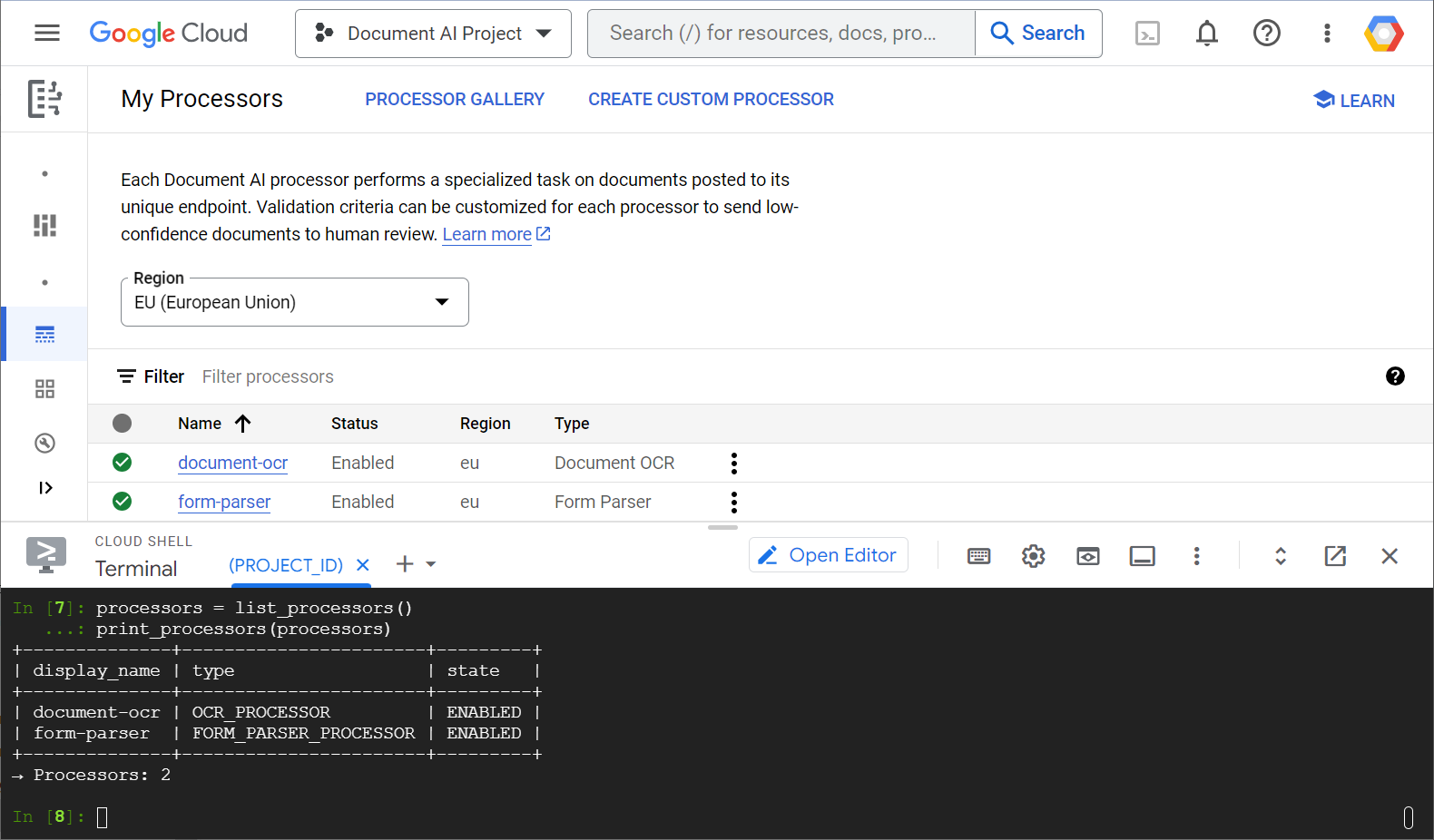
W tym module skoncentrujesz się na zarządzaniu procesorami Document AI za pomocą biblioteki klienta w Pythonie.
Co zobaczysz
- Konfigurowanie środowiska
- Pobieranie typów procesorów
- Jak tworzyć procesory
- Jak wyświetlić listę procesorów projektu
- Jak korzystać z procesorów
- Jak włączyć lub wyłączyć procesory
- Zarządzanie wersjami procesora
- Jak usuwać procesory
Czego potrzebujesz
Ankieta
Jak będziesz korzystać z tego samouczka?
Jak oceniasz swoje doświadczenie z Pythonem?
Jak oceniasz korzystanie z usług Google Cloud?
2. Konfiguracja i wymagania
Konfiguracja środowiska w samodzielnym tempie
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.


- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, którego nie używają interfejsy API Google. Zawsze możesz go zaktualizować.
- Identyfikator projektu jest niepowtarzalny we wszystkich projektach Google Cloud i nie można go zmienić (po ustawieniu). Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie ma znaczenia, jaki to ciąg. W większości laboratoriów z kodem musisz podać identyfikator projektu (zwykle oznaczony jako
PROJECT_ID). Jeśli nie podoba Ci się wygenerowany identyfikator, możesz wygenerować inny losowy. Możesz też spróbować użyć własnego adresu e-mail, aby sprawdzić, czy jest on dostępny. Po wykonaniu tego kroku nie można go zmienić. Pozostanie on na stałe w ramach projektu. - Informacyjnie: istnieje jeszcze 3 wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o wszystkich 3 wartościach znajdziesz w dokumentacji.
- Następnie, aby korzystać z zasobów i interfejsów API w chmurze, musisz włączyć rozliczenia w konsoli Cloud. Przejście przez ten samouczek nie będzie kosztowne, a być może nawet bezpłatne. Aby wyłączyć zasoby i uniknąć obciążenia opłatami po zakończeniu samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Google Cloud można obsługiwać zdalnie z laptopa, ale w tym laboratorium będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Aktywowanie Cloud Shell
- W konsoli Google Cloud kliknij Aktywuj Cloud Shell
 .
.

Jeśli uruchamiasz Cloud Shell po raz pierwszy, zobaczysz ekran pośredni, na którym opisano, czym jest to środowisko. Jeśli taki ekran się wyświetlił, kliknij Dalej.

Uproszczenie i połączenie z Cloud Shell powinno zająć tylko kilka chwil.

Ta maszyna wirtualna zawiera wszystkie niezbędne narzędzia programistyczne. Zawiera stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie poprawia wydajność sieci i uwierzytelnianie. Większość, jeśli nie wszystkie, zadań w tym ćwiczeniu można wykonać w przeglądarce.
Po połączeniu z Cloud Shell powinieneś zobaczyć, że jesteś uwierzytelniony i że projekt ma ustawiony identyfikator Twojego projektu.
- Aby potwierdzić uwierzytelnianie, uruchom w Cloud Shell to polecenie:
gcloud auth list
Wynik polecenia
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Aby sprawdzić, czy polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
Wynik polecenia
[core] project = <PROJECT_ID>
Jeśli nie, możesz ustawić je za pomocą tego polecenia:
gcloud config set project <PROJECT_ID>
Wynik polecenia
Updated property [core/project].
3. Konfiguracja środowiska
Zanim zaczniesz korzystać z Document AI, uruchom w Cloud Shell to polecenie, aby włączyć interfejs Document AI API:
gcloud services enable documentai.googleapis.com
Powinien pojawić się ekran podobny do tego:
Operation "operations/..." finished successfully.
Możesz teraz korzystać z Document AI.
Przejdź do katalogu domowego:
cd ~
Utwórz środowisko wirtualne Pythona, aby oddzielić zależności:
virtualenv venv-docai
Aktywuj środowisko wirtualne:
source venv-docai/bin/activate
Zainstaluj IPython, bibliotekę klienta Document AI i python-tabulate (której użyjesz do ładnego wydrukowania wyników zapytania):
pip install ipython google-cloud-documentai tabulate
Powinien pojawić się ekran podobny do tego:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Możesz już korzystać z biblioteki klienta Document AI.
Ustaw te zmienne środowiskowe:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
Od tej pory wszystkie kroki należy wykonać w ramach tej samej sesji.
Upewnij się, że zmienne środowiskowe są prawidłowo zdefiniowane:
echo $PROJECT_ID
echo $API_LOCATION
W kolejnych krokach użyjesz interaktywnego interpretera Pythona o nazwie IPython, który właśnie zainstalowałeś. Rozpocznij sesję, uruchamiając ipython w Cloud Shell:
ipython
Powinien pojawić się ekran podobny do tego:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Skopiuj ten kod do sesji IPython:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Możesz teraz wysłać pierwsze żądanie i pobrać typy procesorów.
4. Pobieranie typów procesorów
Zanim w następnym kroku utworzysz procesor, pobierz dostępne typy procesorów. Możesz pobrać tę listę za pomocą fetch_processor_types.
Dodaj do sesji IPython te funkcje:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Wymień typy procesorów:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Powinieneś zobaczyć coś takiego:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Masz już wszystkie informacje potrzebne do utworzenia w następnym kroku procesorów.
5. Tworzenie procesorów
Aby utworzyć procesor, wywołaj funkcję create_processor, podając nazwę wyświetlaną i typ procesora.
Dodaj tę funkcję:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Utwórz procesory testowe:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Powinny pojawić się te informacje:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Utworzono nowych procesorów.
Następnie dowiedz się, jak wyświetlić listę procesorów.
6. Wyświetlanie procesorów projektu
list_processors zwraca listę wszystkich procesorów należących do projektu.
Dodaj te funkcje:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Wywoływanie funkcji:
processors = list_processors()
print_processors(processors)
Powinny pojawić się te informacje:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Aby pobrać procesor według jego nazwy wyświetlanej, dodaj tę funkcję:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Testowanie funkcji:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Powinien pojawić się ekran podobny do tego:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Teraz już wiesz, jak wyświetlić przetwarzanie projektów i pobrać je według ich nazw wyświetlanych. Następnie dowiedz się, jak korzystać z procesora.
7. Korzystanie z procesorów
Dokumenty można przetwarzać na 2 sposoby:
- Synchronicznie: wywołanie funkcji
process_documentpowoduje analizę pojedynczego dokumentu i bezpośrednie korzystanie z wyników. - Asynchronicznie: wywołanie funkcji
batch_process_documentsuruchamia grupowe przetwarzanie wielu lub dużych dokumentów.
Dokument testowy ( w formacie PDF) to zeskanowany kwestionariusz z odręcznymi odpowiedziami. Pobierz go do katalogu roboczego bezpośrednio z sesji IPython:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Sprawdź zawartość katalogu roboczego:
!ls
Musisz mieć:
... form.pdf ... venv-docai ...
Do analizy pliku lokalnego możesz użyć synchronicznej metody process_document. Dodaj tę funkcję:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Ponieważ Twój dokument jest kwestionariuszem, wybierz parser formularzy. Oprócz wyodrębniania tekstu (drukowanego i ręcznego), co robią wszystkie procesory, ten procesor ogólny wykrywa pola formularza.
Przeanalizuj dokument:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Wszystkie procesory przeprowadzają na dokumencie pierwszy odczyt optycznego rozpoznawania znaków (OCR). Sprawdź tekst wykryty przez funkcję OCR:
document.text.split("\n")
Powinna pojawić się strona podobna do tej:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Dodaj te funkcje, aby wydrukować wykryte pola formularza:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Dodaj też te funkcje pomocnicze:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Wydrukuj wykryte pola formularza:
print_form_fields(document)
Wydruk powinien wyglądać tak:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Sprawdź nazwy i wartości pól, które zostały wykryte ( PDF). Oto pierwsza połowa kwestionariusza:

Przeanalizowano formularz, który zawiera tekst drukowany i odręczny. Wykryto też pola z wysokim poziomem ufności. W rezultacie Twoje piksele zostały przekształcone w uporządkowane dane.
8. Włączanie i wyłączanie procesorów
Za pomocą ustawień disable_processor i enable_processor możesz określić, czy procesor może być używany.
Dodaj te funkcje:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Wyłącz procesor parsowania formularzy i sprawdź stan procesorów:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Powinny pojawić się te informacje:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Aby ponownie włączyć procesor parsera formularzy:
enable_processor(processor)
print_processors()
Powinny pojawić się te informacje:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Następnie dowiedz się, jak zarządzać wersjami procesora.
9. Zarządzanie wersjami procesora
Procesory mogą być dostępne w kilku wersjach. Dowiedz się, jak używać metod list_processor_versions i set_default_processor_version.
Dodaj te funkcje:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Lista dostępnych wersji procesora OCR:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Masz dostęp do tych wersji procesora:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Teraz dodaj funkcję, aby zmienić domyślną wersję procesora:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Przełącz się na najnowszą wersję procesora:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Otrzymasz konfigurację nowej wersji:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Następnie możesz użyć ostatecznej metody zarządzania procesorem (usunięcie).
10. Usuwanie procesorów
Na koniec dowiedz się, jak korzystać z metody delete_processor.
Dodaj tę funkcję:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Usuń procesory testowe:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Powinny pojawić się te informacje:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Znasz wszystkie metody zarządzania procesorami. To już prawie wszystko.
11. Gratulacje!
Wiesz już, jak zarządzać procesorami Document AI za pomocą Pythona.
Czyszczenie danych
Aby wyczyścić środowisko programistyczne w Cloud Shell:
- Jeśli nadal jesteś w sesji IPython, wróć do powłoki:
exit - Zatrzymaj korzystanie ze środowiska wirtualnego Pythona:
deactivate - Usuwanie folderu środowiska wirtualnego:
cd ~ ; rm -rf ./venv-docai
Aby usunąć projekt Google Cloud, w Cloud Shell:
- Pobierz identyfikator bieżącego projektu:
PROJECT_ID=$(gcloud config get-value core/project) - Sprawdź, czy to jest projekt, który chcesz usunąć:
echo $PROJECT_ID - Usuń projekt:
gcloud projects delete $PROJECT_ID
Więcej informacji
- Wypróbuj Document AI w przeglądarce: https://cloud.google.com/document-ai/docs/drag-and-drop
- Szczegóły procesora Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python w Google Cloud: https://cloud.google.com/python
- Biblioteki klienta usługi w chmurze dla Pythona: https://github.com/googleapis/google-cloud-python
Licencja
To zadanie jest licencjonowane na podstawie ogólnej licencji Creative Commons Attribution 2.0.