
1. Descripción general

¿Qué es Document AI?
Document AI es una plataforma que te permite extraer estadísticas de tus documentos. En esencia, ofrece una lista creciente de procesadores de documentos (también llamados analizadores o divisores, según su funcionalidad).
Existen dos maneras de administrar los procesadores de Document AI:
- de forma manual, desde la consola web
- de manera programática, con la API de Document AI.
A continuación, se muestra una captura de pantalla de ejemplo que muestra tu lista de procesadores, tanto desde la consola web como desde el código de Python:
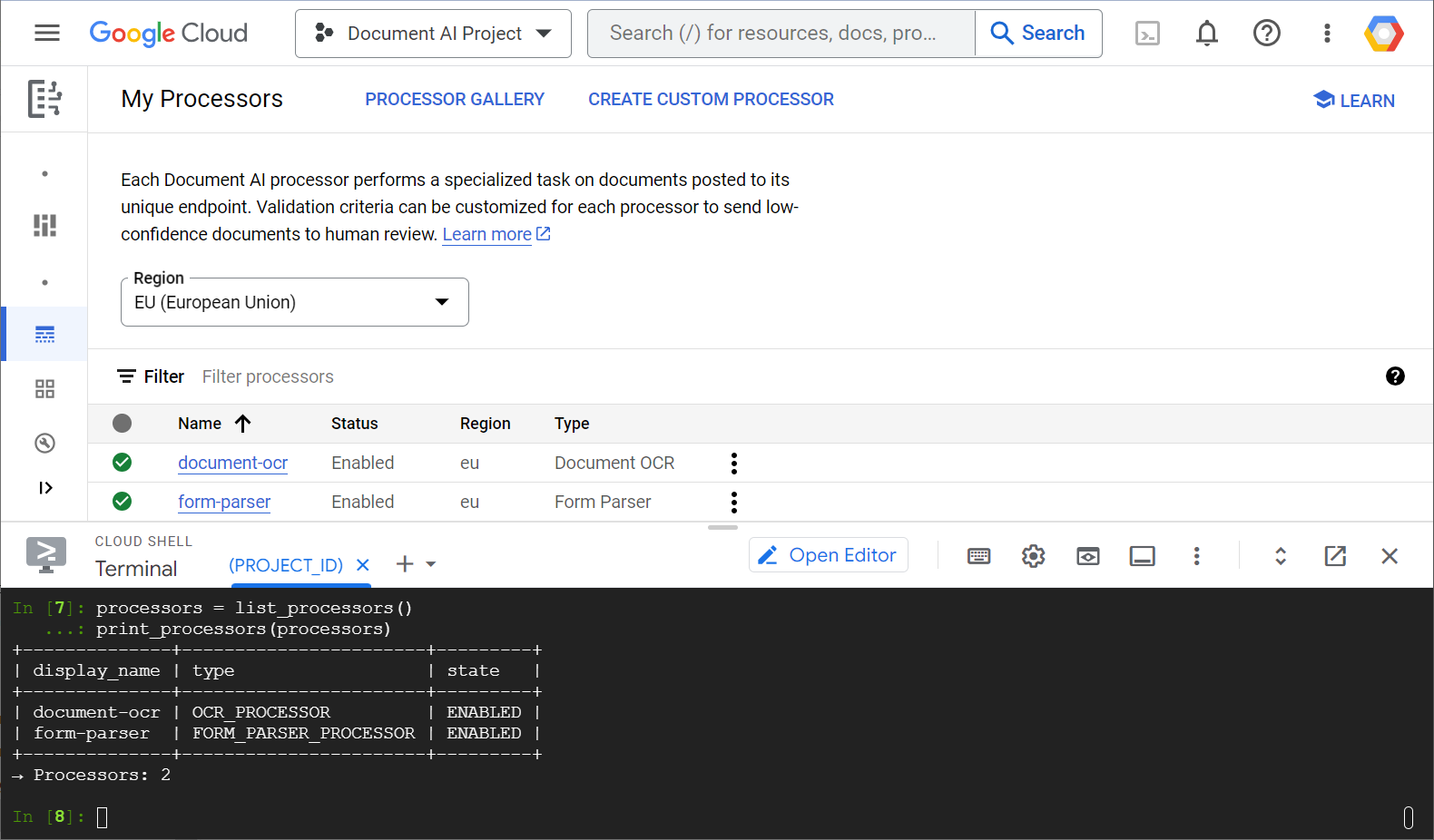
En este lab, te enfocarás en administrar procesadores de Document AI de forma programática con la biblioteca cliente de Python.
Qué verás
- Cómo configurar tu entorno
- Cómo recuperar tipos de procesadores
- Cómo crear procesadores
- Cómo enumerar los procesadores de proyectos
- Cómo usar procesadores
- Cómo habilitar o inhabilitar procesadores
- Cómo administrar las versiones de los procesadores
- Cómo borrar procesadores
Requisitos
Encuesta
¿Cómo usarás este instructivo?
¿Cómo calificarías tu experiencia en Python?
¿Cómo calificarías tu experiencia con los servicios de Google Cloud?
2. Configuración y requisitos
Configuración del entorno de autoaprendizaje
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.


- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien Google Cloud se puede operar de manera remota desde tu laptop, en este lab usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Activar Cloud Shell
- En la consola de Cloud, haz clic en Activar Cloud Shell
 .
.

Si es la primera vez que inicias Cloud Shell, aparecerá una pantalla intermedia en la que se describe qué es. Si aparece una pantalla intermedia, haz clic en Continuar.
El aprovisionamiento y la conexión a Cloud Shell solo tomará unos minutos.

Esta máquina virtual está cargada con todas las herramientas de desarrollo necesarias. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Gran parte de tu trabajo en este codelab, si no todo, se puede hacer con un navegador.
Una vez que te conectes a Cloud Shell, deberías ver que se te autenticó y que el proyecto se configuró con tu ID de proyecto.
- En Cloud Shell, ejecuta el siguiente comando para confirmar que tienes la autenticación:
gcloud auth list
Resultado del comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto:
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
De lo contrario, puedes configurarlo con el siguiente comando:
gcloud config set project <PROJECT_ID>
Resultado del comando
Updated property [core/project].
3. Configuración del entorno
Antes de comenzar a usar Document AI, ejecuta el siguiente comando en Cloud Shell para habilitar la API de Document AI:
gcloud services enable documentai.googleapis.com
Debería ver algo como esto:
Operation "operations/..." finished successfully.
Ahora puedes usar Document AI.
Navega a tu directorio principal:
cd ~
Crea un entorno virtual de Python para aislar las dependencias:
virtualenv venv-docai
Activa el entorno virtual:
source venv-docai/bin/activate
Instala IPython, la biblioteca cliente de Document AI y python-tabulate (que usarás para imprimir de forma más atractiva los resultados de la solicitud):
pip install ipython google-cloud-documentai tabulate
Debería ver algo como esto:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Ya está todo listo para usar la biblioteca cliente de Document AI.
Configura las siguientes variables de entorno:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
A partir de ahora, todos los pasos se deben completar en la misma sesión.
Asegúrate de que tus variables de entorno estén definidas correctamente:
echo $PROJECT_ID
echo $API_LOCATION
En los próximos pasos, usarás un intérprete de Python interactivo llamado IPython, que acabas de instalar. Para iniciar una sesión, ejecuta ipython en Cloud Shell:
ipython
Debería ver algo como esto:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Copia el siguiente código en tu sesión de IPython:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Ya puedes realizar tu primera solicitud y recuperar los tipos de procesadores.
4. Cómo recuperar tipos de procesadores
Antes de crear un procesador en el siguiente paso, recupera los tipos de procesadores disponibles. Puedes recuperar esta lista con fetch_processor_types.
Agrega las siguientes funciones a tu sesión de IPython:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Enumera los tipos de procesadores:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Deberías obtener algo como lo siguiente:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Ahora tienes toda la información necesaria para crear procesadores en el siguiente paso.
5. Cómo crear procesadores
Para crear un procesador, llama a create_processor con un nombre visible y un tipo de procesador.
Agrega la siguiente función:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Crea los procesadores de prueba:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Deberías obtener lo siguiente:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
¡Creaste procesadores nuevos!
A continuación, consulta cómo hacer una lista de los procesadores.
6. Cómo enumerar los procesadores de proyectos
list_processors muestra la lista de todos los procesadores que pertenecen a tu proyecto.
Agrega las siguientes funciones:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Llama a las funciones:
processors = list_processors()
print_processors(processors)
Deberías obtener lo siguiente:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Para recuperar un procesador por su nombre visible, agrega la siguiente función:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Sigue estos pasos para probar la función:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Debería ver algo como esto:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Ahora sabes cómo enumerar los procesadores de tu proyecto y recuperarlos por sus nombres visibles. A continuación, descubre cómo usar un procesador.
7. Cómo usar procesadores
Los documentos se pueden procesar de dos maneras:
- De manera síncrona: Llama a
process_documentpara analizar un solo documento y usar los resultados directamente. - De manera asíncrona: Llama a
batch_process_documentspara iniciar un procesamiento por lotes en varios documentos o documentos grandes.
Tu documento de prueba ( PDF) es un cuestionario escaneado completado con respuestas escritas a mano. Descarga el archivo en tu directorio de trabajo, directamente desde tu sesión de IPython:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Revisa el contenido de tu directorio de trabajo:
!ls
Debes contar con lo siguiente:
... form.pdf ... venv-docai ...
Puedes usar el método síncrono process_document para analizar un archivo local. Agrega la siguiente función:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Como tu documento es un cuestionario, elige el analizador de formularios. Además de extraer el texto (impreso y escrito a mano), que hacen todos los procesadores, este procesador general detecta campos de formulario.
Analiza el documento:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Todos los procesadores ejecutan un primer pase de reconocimiento óptico de caracteres (OCR) en el documento. Revisa el texto detectado por el pase de OCR:
document.text.split("\n")
Deberías ver un resultado similar al siguiente:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Agrega las siguientes funciones para imprimir los campos de formulario detectados:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
También agrega estas funciones de utilidad:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Imprime los campos de formulario detectados:
print_form_fields(document)
Deberías obtener una copia impresa como la siguiente:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Revisa los nombres y valores de los campos que se detectaron ( PDF). Esta es la mitad superior del cuestionario:

Analizaste un formulario que contiene texto impreso y escrito a mano. También detectaste sus campos con alta confianza. El resultado es que tus píxeles se transformaron en datos estructurados.
8. Habilita y habilita procesadores
Con disable_processor y enable_processor, puedes controlar si se puede usar un procesador.
Agrega las siguientes funciones:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Inhabilita el procesador de analizador de formularios y verifica el estado de tus procesadores:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Deberías obtener lo siguiente:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Vuelve a habilitar el procesador de analizador de formularios:
enable_processor(processor)
print_processors()
Deberías obtener lo siguiente:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
A continuación, descubre cómo administrar las versiones de procesadores.
9. Administrar las versiones de los procesadores
Los procesadores pueden estar disponibles en varias versiones. Descubre cómo usar los métodos list_processor_versions y set_default_processor_version.
Agrega las siguientes funciones:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Crea una lista de las versiones disponibles para el procesador de OCR:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Obtendrás las versiones del procesador:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Ahora, agrega una función para cambiar la versión predeterminada del procesador:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Cambia a la versión más reciente del procesador:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Obtienes la configuración de la versión nueva:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Y, a continuación, el método de administración de procesadores definitivo (eliminación).
10. Cómo borrar procesadores
Por último, consulta cómo usar el método delete_processor.
Agrega la siguiente función:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Borra los procesadores de prueba:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Deberías obtener lo siguiente:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
¡Cubrimos todos los métodos de administración de procesadores! Ya casi terminas…
11. ¡Felicitaciones!
Aprendiste a administrar procesadores de Document AI con Python.
Limpia
Para limpiar tu entorno de desarrollo, haz lo siguiente desde Cloud Shell:
- Si aún estás en tu sesión de IPython, vuelve a la shell:
exit - Deja de usar el entorno virtual de Python:
deactivate - Borra la carpeta de tu entorno virtual:
cd ~ ; rm -rf ./venv-docai
Para borrar tu proyecto de Google Cloud, haz lo siguiente en Cloud Shell:
- Recupera el ID de tu proyecto actual:
PROJECT_ID=$(gcloud config get-value core/project) - Asegúrate de que este sea el proyecto que quieres borrar:
echo $PROJECT_ID - Borra el proyecto:
gcloud projects delete $PROJECT_ID
Más información
- Prueba Document AI en tu navegador: https://cloud.google.com/document-ai/docs/drag-and-drop
- Detalles del procesador de Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python en Google Cloud: https://cloud.google.com/python
- Bibliotecas cliente de Cloud para Python: https://github.com/googleapis/google-cloud-python
Licencia
Este trabajo cuenta con una licencia Atribución 2.0 Genérica de Creative Commons.