
Bu codelab hakkında
1. Genel Bakış

Document AI nedir?
Document AI, belgelerinizden analiz almanızı sağlayan bir platformdur. Temel olarak, büyüyen bir belge işlemci listesi (işlevlerine bağlı olarak ayrıştırıcı veya ayırıcı olarak da adlandırılır) sunar.
Document AI işleyicilerini iki şekilde yönetebilirsiniz:
- web konsolundan manuel olarak;
- Document AI API'yi kullanarak programlı olarak
Hem web konsolundan hem de Python kodundan işlemci listenizi gösteren örnek bir ekran görüntüsünü aşağıda bulabilirsiniz:
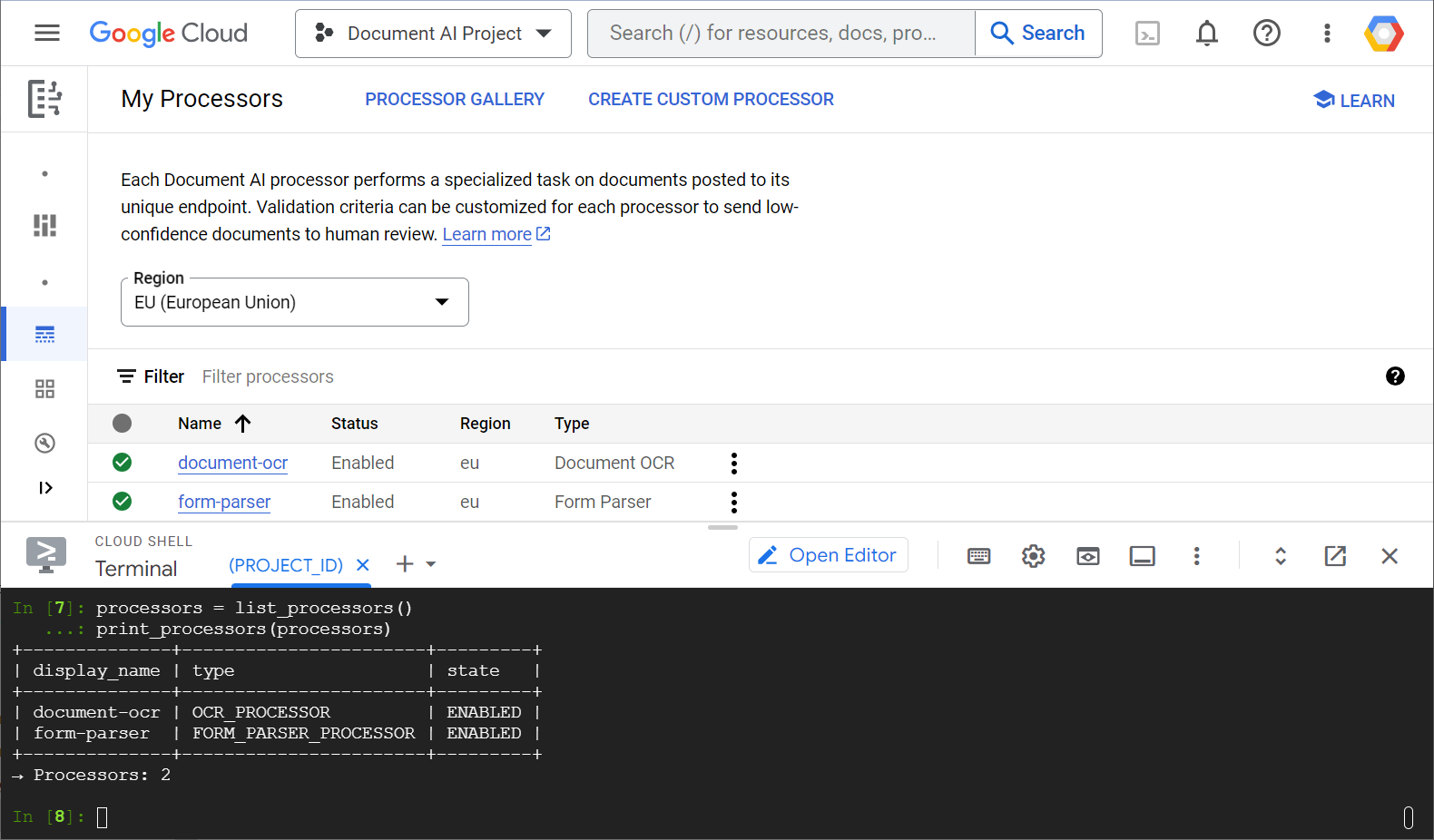
Bu laboratuvarda, Document AI işleyicilerini Python istemci kitaplığıyla programatik olarak yönetmeye odaklanacaksınız.
Göreceğiniz içerikler
- Ortamınızı ayarlama
- İşlemci türlerini getirme
- İşleyici oluşturma
- Proje işleyicileri listeleyebilirsiniz.
- İşlemcileri kullanma
- İşlemcileri etkinleştirme/devre dışı bırakma
- İşlemci sürümlerini yönetme
- İşlemcileri silme
Gerekenler
Anket
Bu eğitimi nasıl kullanacaksınız?
Python ile ilgili deneyiminizi nasıl değerlendirirsiniz?
Google Cloud hizmetleriyle ilgili deneyiminizi nasıl değerlendirirsiniz?
2. Kurulum ve şartlar
Kendine ait tempoda ortam oluşturma
- Google Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. Gmail veya Google Workspace hesabınız yoksa hesap oluşturmanız gerekir.

- Proje adı, bu projenin katılımcılarının görünen adıdır. Google API'leri tarafından kullanılmayan bir karakter dizesidir. Dilediğiniz zaman güncelleyebilirsiniz.
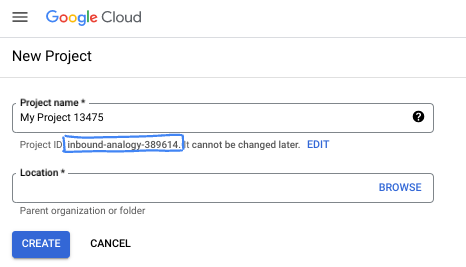
- Proje kimliği, tüm Google Cloud projelerinde benzersizdir ve değiştirilemez (ayarlandıktan sonra değiştirilemez). Cloud Console, benzersiz bir dize otomatik olarak oluşturur. Bu dizenin ne olduğu genellikle önemli değildir. Çoğu kod laboratuvarında proje kimliğinize (genellikle
PROJECT_IDolarak tanımlanır) referans vermeniz gerekir. Oluşturulan kimliği beğenmezseniz rastgele başka bir kimlik oluşturabilirsiniz. Alternatif olarak, kendi anahtarınızı deneyerek kullanılabilir olup olmadığını görebilirsiniz. Bu adımdan sonra değiştirilemez ve proje boyunca geçerli kalır. - Bazı API'lerin kullandığı üçüncü bir değer (Proje Numarası) olduğunu belirtmek isteriz. Bu üç değer hakkında daha fazla bilgiyi dokümanlar bölümünde bulabilirsiniz.
- Ardından, Cloud kaynaklarını/API'lerini kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir. Bu codelab'i çalıştırmak çok pahalı değildir. Bu eğitimden sonra faturalandırılmamak için kaynakları kapatmak istiyorsanız oluşturduğunuz kaynakları veya projeyi silebilirsiniz. Yeni Google Cloud kullanıcıları 300 ABD doları değerinde ücretsiz deneme programına uygundur.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Bu laboratuvarda ise bulutta çalışan bir komut satırı ortamı olan Cloud Shell'i kullanıyorsunuz.
Cloud Shell'i etkinleştirme
- Cloud Console'da Cloud Shell'i etkinleştir 'i
 tıklayın.
tıklayın.

Cloud Shell'i ilk kez başlatıyorsanız Cloud Shell'in ne olduğunu açıklayan bir ara ekran gösterilir. Ara ekran gösterildiyse Devam'ı tıklayın.
Cloud Shell'e bağlanmak ve ortam oluşturmak yalnızca birkaç dakikanızı alır.

Bu sanal makinede, ihtiyaç duyulan tüm geliştirme araçları yüklüdür. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud'da çalışır. Bu sayede ağ performansını ve kimlik doğrulamayı büyük ölçüde iyileştirir. Bu kod laboratuvarındaki çalışmanızın tamamı olmasa da büyük bir kısmı tarayıcıda yapılabilir.
Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını görürsünüz.
- Kimliğinizi doğrulamak için Cloud Shell'de aşağıdaki komutu çalıştırın:
gcloud auth list
Komut çıkışı
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın:
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Aksi takdirde aşağıdaki komutla ayarlayabilirsiniz:
gcloud config set project <PROJECT_ID>
Komut çıkışı
Updated property [core/project].
3. Ortam kurulumu
Document AI'ı kullanmaya başlamadan önce Document AI API'yi etkinleştirmek için Cloud Shell'de aşağıdaki komutu çalıştırın:
gcloud services enable documentai.googleapis.com
Aşağıdakine benzer bir tablo görürsünüz:
Operation "operations/..." finished successfully.
Artık Document AI'ı kullanabilirsiniz.
Ana dizininize gidin:
cd ~
Bağımlılıkları izole etmek için bir Python sanal ortamı oluşturun:
virtualenv venv-docai
Sanal ortamı etkinleştirin:
source venv-docai/bin/activate
IPython, Document AI istemci kitaplığı ve python-tabulate'ı (istem sonuçlarını güzel bir şekilde yazdırmak için kullanacağınız) yükleyin:
pip install ipython google-cloud-documentai tabulate
Aşağıdakine benzer bir tablo görürsünüz:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Artık Document AI istemci kitaplığını kullanmaya hazırsınız.
Aşağıdaki ortam değişkenlerini ayarlayın:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
Bundan sonra tüm adımlar aynı oturumda tamamlanmalıdır.
Ortam değişkenlerinizin doğru şekilde tanımlandığından emin olun:
echo $PROJECT_ID
echo $API_LOCATION
Sonraki adımlarda, az önce yüklediğiniz IPython adlı etkileşimli bir Python yorumlayıcısı kullanacaksınız. Cloud Shell'de ipython komutunu çalıştırarak oturum başlatın:
ipython
Aşağıdakine benzer bir tablo görürsünüz:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Aşağıdaki kodu IPython oturumunuza kopyalayın:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
İlk isteğinizi gönderip işlemci türlerini getirmeye hazırsınız.
4. İşlemci türleri getiriliyor
Sonraki adımda bir işlemci oluşturmadan önce mevcut işlemci türlerini getirin. Bu listeyi fetch_processor_types ile alabilirsiniz.
IPython oturumunuza aşağıdaki işlevleri ekleyin:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
İşlemci türlerini listeleyin:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Aşağıdakine benzer bir sonuç alırsınız:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Artık bir sonraki adımda işleyici oluşturmak için gereken tüm bilgilere sahipsiniz.
5. İşleyici oluşturma
İşlemci oluşturmak için görünen ad ve işlemci türü ile create_processor işlevini çağırın.
Aşağıdaki işlevi ekleyin:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Test işleyicilerini oluşturun:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Aşağıdakileri göreceksiniz:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Yeni işlemciler oluşturdunuz.
Ardından, işlemcilerin nasıl listeleneceğini öğrenin.
6. Proje işleyicilerini listeleme
list_processors, projenize ait tüm işleyicilerin listesini döndürür.
Aşağıdaki işlevleri ekleyin:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
İşlevleri çağırın:
processors = list_processors()
print_processors(processors)
Aşağıdakileri göreceksiniz:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Bir işlemciyi görünen adına göre almak için aşağıdaki işlevi ekleyin:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
İşlevi test edin:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Aşağıdakine benzer bir tablo görürsünüz:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Artık proje işleyicilerinizi nasıl listeleyip görünen adlarına göre nasıl alacağınızı biliyorsunuz. Ardından, işlemciyi nasıl kullanacağınızı öğrenin.
7. İşleyicileri kullanma
Dokümanlar iki şekilde işlenebilir:
- Senkron: Tek bir dokümanı analiz etmek ve sonuçları doğrudan kullanmak için
process_documentişlevini çağırın. - Eşzamansız: Birden fazla veya büyük boyutlu dokümanda toplu işlem başlatmak için
batch_process_documentsişlevini çağırın.
Test dokümanınız ( PDF), el yazısıyla yanıtlanmış bir tarama anketidir. Dosyayı doğrudan IPython oturumunuzdan çalışma dizininize indirin:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Çalışma dizininizin içeriğini kontrol edin:
!ls
Aşağıdakilere sahip olmanız gerekir:
... form.pdf ... venv-docai ...
Yerel bir dosyayı analiz etmek için senkronize process_document yöntemini kullanabilirsiniz. Aşağıdaki işlevi ekleyin:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Belgeniz bir anket olduğundan form ayrıştırıcıyı seçin. Bu genel işlemci, tüm işlemcilerin yaptığı metin (basılı ve el yazısı) ayıklama işlemine ek olarak form alanlarını da algılar.
Belgeyi analiz edin:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Tüm işlemciler, belgede ilk olarak Optik Karakter Tanıma (OCR) işlemi gerçekleştirir. OCR geçişi tarafından algılanan metni inceleyin:
document.text.split("\n")
Aşağıdakine benzer bir şey görürsünüz:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Algılanan form alanlarını yazdırmak için aşağıdaki işlevleri ekleyin:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Ayrıca aşağıdaki yardımcı program işlevlerini de ekleyin:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Algılanan form alanlarını yazdırın:
print_form_fields(document)
Aşağıdaki gibi bir çıktı alırsınız:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Tespit edilen alan adlarını ve değerlerini inceleyin ( PDF). Anketin üst yarısını aşağıda bulabilirsiniz:

Hem basılı hem de el yazısı metin içeren bir formu analiz ettiniz. Ayrıca, alanlarını yüksek güvenle tespit ettiniz. Sonuç olarak, pikselleriniz yapılandırılmış verilere dönüştürülmüştür.
8. İşlemcileri etkinleştirme ve devre dışı bırakma
disable_processor ve enable_processor ile bir işlemcinin kullanılıp kullanılamayacağını kontrol edebilirsiniz.
Aşağıdaki işlevleri ekleyin:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Form ayrıştırıcıyı devre dışı bırakın ve işlemcilerinizin durumunu kontrol edin:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Aşağıdakileri göreceksiniz:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Form ayrıştırıcıyı yeniden etkinleştirin:
enable_processor(processor)
print_processors()
Aşağıdakileri göreceksiniz:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Ardından, işlemci sürümlerini nasıl yöneteceğinizi öğrenin.
9. İşlemci sürümlerini yönetme
İşlemciler birden fazla sürümde bulunabilir. list_processor_versions ve set_default_processor_version yöntemlerinin nasıl kullanılacağına göz atın.
Aşağıdaki işlevleri ekleyin:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
OCR işlemcisi için kullanılabilen sürümleri listeleyin:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Aşağıdaki işlemci sürümlerini alırsınız:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Ardından, varsayılan işlemci sürümünü değiştirmek için bir işlev ekleyin:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
En yeni işlemci sürümüne geçin:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Yeni sürüm yapılandırmasını alırsınız:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Son olarak, en iyi işlemci yönetimi yöntemi olan silme işlemini ele alalım.
10. İşlemcileri silme
Son olarak, delete_processor yönteminin nasıl kullanılacağına göz atın.
Aşağıdaki işlevi ekleyin:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Test işlemcilerinizi silin:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Aşağıdakileri göreceksiniz:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Tüm işlemci yönetimi yöntemlerini tamamladınız. Neredeyse bitti...
11. Tebrikler!
Python'u kullanarak Document AI işleyicilerini nasıl yöneteceğinizi öğrendiniz.
Temizleme
Geliştirme ortamınızı temizlemek için Cloud Shell'de:
- IPython oturumunuzdaysanız kabuğa geri dönün:
exit - Python sanal ortamını kullanmayı bırakın:
deactivate - Sanal ortam klasörünüzü silin:
cd ~ ; rm -rf ./venv-docai
Google Cloud projenizi silmek için Cloud Shell'de:
- Geçerli proje kimliğinizi alın:
PROJECT_ID=$(gcloud config get-value core/project) - Silmek istediğiniz projenin bu olduğundan emin olun:
echo $PROJECT_ID - Projeyi silme:
gcloud projects delete $PROJECT_ID
Daha fazla bilgi
- Tarayıcınızda Document AI'ı deneyin: https://cloud.google.com/document-ai/docs/drag-and-drop
- Document AI işleyici ayrıntıları: https://cloud.google.com/document-ai/docs/processors-list
- Google Cloud'da Python: https://cloud.google.com/python
- Python için Cloud İstemci Kitaplıkları: https://github.com/googleapis/google-cloud-python
Lisans
Bu çalışma, Creative Commons Attribution 2.0 Genel Amaçlı Lisans ile lisans altına alınmıştır.