
1. Omówienie
Cloud Dataproc to zarządzana usługa Spark i Hadoop, która umożliwia korzystanie z narzędzi typu open source do przetwarzania wsadowego, zapytań, strumieniowania i systemów uczących się. Automatyzacja Cloud Dataproc pomaga szybko tworzyć klastry, łatwo nimi zarządzać i oszczędzać pieniądze dzięki wyłączaniu klastrów, które nie są potrzebne. Mając mniej czasu i pieniędzy na administrację, możesz skupić się na swoich zadaniach i swoich danych.
Ten samouczek pochodzi ze strony https://cloud.google.com/dataproc/overview
Czego się nauczysz
- Jak utworzyć zarządzany klaster Cloud Dataproc (z wstępnie zainstalowanym Apache Spark).
- Jak przesłać zadanie Spark
- Jak zmienić rozmiar klastra
- Łączenie się przez SSH z węzłem głównym klastra Dataproc
- Jak za pomocą gcloud badać klastry, zadania i reguły zapory sieciowej
- Jak wyłączyć klaster
Czego potrzebujesz
Jak wykorzystasz ten samouczek?
Jak oceniasz swoje wrażenia z korzystania z usług Google Cloud Platform?
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub wykorzystaj już istniejący. Jeśli nie masz jeszcze konta Gmail lub G Suite, musisz je utworzyć.



Zapamiętaj identyfikator projektu, unikalną nazwę we wszystkich projektach Google Cloud (powyższa nazwa jest już zajęta i nie będzie Ci odpowiadać). W dalszej części tego ćwiczenia w Codelabs będzie ona określana jako PROJECT_ID.
- Następnie musisz włączyć płatności w Cloud Console, aby korzystać z zasobów Google Cloud.
Ukończenie tego ćwiczenia z programowania nie powinno kosztować zbyt wiele. Postępuj zgodnie z instrukcjami podanymi w sekcji „Czyszczenie” W tym samouczku znajdziesz wskazówki, jak wyłączyć zasoby, aby uniknąć naliczania opłat. Nowi użytkownicy Google Cloud mogą skorzystać z programu bezpłatnego okresu próbnego o wartości 300 USD.
3. Włączanie interfejsów Cloud Dataproc API i Google Compute Engine API
Kliknij ikonę menu w lewym górnym rogu ekranu.

Z menu wybierz Menedżer API.

Kliknij Włącz interfejsy API i usługi.

Wyszukaj „Compute Engine” w polu wyszukiwania. Kliknij „Google Compute Engine API”. na wyświetlonej liście wyników.

Na stronie Google Compute Engine kliknij Włącz.

Po włączeniu kliknij strzałkę w lewo, aby wrócić.
Teraz wyszukaj „Google Cloud Dataproc API”. i ją włączyć.

4. Uruchamianie Cloud Shell
Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i uwierzytelnianie. Oznacza to, że do tego ćwiczenia z programowania wystarczy przeglądarka (tak, działa ona na Chromebooku).
- Aby aktywować Cloud Shell z poziomu konsoli Cloud, kliknij Aktywuj Cloud Shell
(udostępnienie środowiska i połączenie z nim powinno zająć tylko chwilę).
Po nawiązaniu połączenia z Cloud Shell powinno pojawić się potwierdzenie, że użytkownik jest już uwierzytelniony, a projekt jest już ustawiony na PROJECT_ID.
gcloud auth list
Dane wyjściowe polecenia
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Dane wyjściowe polecenia
[core] project = <PROJECT_ID>
Jeśli z jakiegoś powodu projekt nie jest skonfigurowany, uruchom po prostu to polecenie:
gcloud config set project <PROJECT_ID>
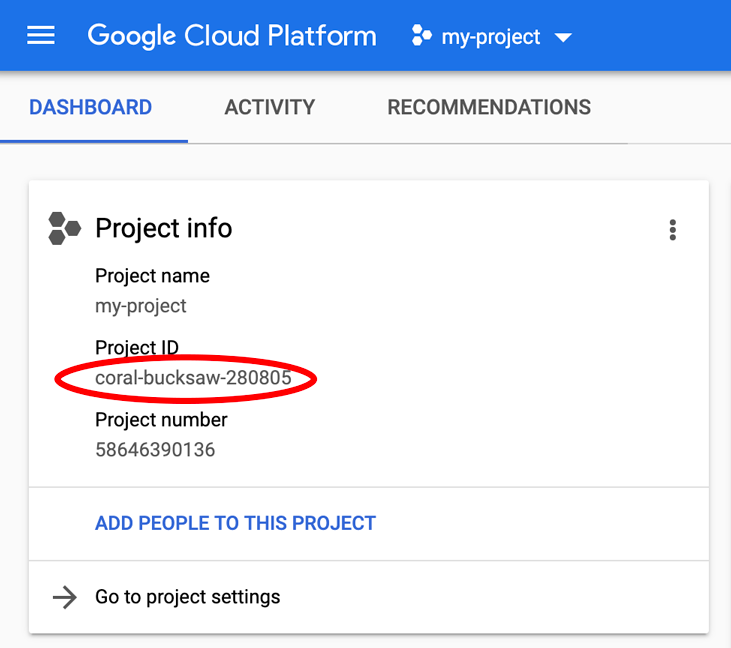
Szukasz urządzenia PROJECT_ID? Sprawdź identyfikator użyty w krokach konfiguracji lub wyszukaj go w panelu Cloud Console:
Cloud Shell ustawia też domyślnie niektóre zmienne środowiskowe, które mogą być przydatne podczas uruchamiania kolejnych poleceń.
echo $GOOGLE_CLOUD_PROJECT
Dane wyjściowe polecenia
<PROJECT_ID>
- Na koniec ustaw domyślną strefę i konfigurację projektu.
gcloud config set compute/zone us-central1-f
Możesz wybrać różne strefy. Więcej informacji znajdziesz w artykule Regiony i Strefy.
5. Utwórz klaster Cloud Dataproc
Po uruchomieniu Cloud Shell możesz użyć wiersza poleceń, aby wywołać polecenie gcloud z pakietu SDK Cloud lub inne narzędzia dostępne w instancji maszyny wirtualnej.
Wybierz nazwę klastra, której chcesz użyć w tym module:
$ CLUSTERNAME=${USER}-dplab
Zacznijmy od utworzenia nowego klastra:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
W tym samouczku powinny wystarczyć domyślne ustawienia klastra, które obejmują 2 węzły robocze. Powyższe polecenie zawiera opcję --zone określającą strefę geograficzną, w której zostanie utworzony klaster, oraz 2 opcje zaawansowane (--scopes i --tags), które zostały opisane poniżej podczas korzystania z włączonych funkcji. Informacje o dostosowywaniu ustawień klastra za pomocą flag wiersza poleceń znajdziesz w poleceniu pakietu SDK Cloud gcloud dataproc clusters create.
6. Przesyłanie zadania Spark do klastra
Zadanie możesz przesłać za pomocą żądania do interfejsu Cloud Dataproc API jobs.submit, narzędzia wiersza poleceń gcloud lub konsoli Google Cloud Platform. Możesz też połączyć się z instancją maszyny w klastrze przez SSH, a następnie uruchomić zadanie z instancji.
Prześlijmy zadanie za pomocą narzędzia gcloud z wiersza poleceń Cloud Shell:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
Po uruchomieniu zadania w oknie Cloud Shell wyświetlą się dane wyjściowe.
Aby przerwać wyjście, naciśnij Ctrl+C. Spowoduje to zatrzymanie polecenia gcloud, ale zadanie będzie nadal uruchomione w klastrze Dataproc.
7. Wyświetlanie listy zadań i ponowne łączenie
Drukuj listę zadań:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
Ostatnio przesłane zadanie znajduje się na początku listy. Skopiuj identyfikator zadania i wklej go w miejscu „jobId” w tym poleceniu. To polecenie połączy się ponownie z określonym zadaniem i wyświetli dane wyjściowe:
$ gcloud dataproc jobs wait jobId
Po zakończeniu zadania dane wyjściowe będą zawierać przybliżoną wartość liczby π.

8. Zmień rozmiar klastra
W przypadku większych obliczeń możesz dodać do klastra więcej węzłów, aby przyspieszyć jego działanie. Dataproc pozwala na dodawanie i usuwanie węzłów z klastra w dowolnym momencie.
Sprawdź konfigurację klastra:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Powiększ klaster, dodając kilka węzłów z możliwością wywłaszczania:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Ponownie sprawdź klaster:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Zwróć uwagę, że oprócz workerConfig z pierwotnego opisu klastra istnieje teraz również zasób secondaryWorkerConfig, który zawiera 2 obiekty instanceNames dla instancji roboczych z możliwością wywłaszczania. Podczas uruchamiania nowych węzłów Dataproc wyświetla stan klastra jako gotowy.
Ponieważ rozpoczęto pracę z 2 węzłami, a teraz masz 4, Twoje zadania Spark powinny uruchamiać się około 2 razy szybciej.
9. Łączenie się z klastrem przez SSH
Połącz się z węzłem głównym przez SSH, którego nazwa instancji to zawsze nazwa klastra z dołączonym adresem -m:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Gdy po raz pierwszy uruchomisz polecenie ssh w Cloud Shell, spowoduje to wygenerowanie kluczy SSH do Twojego konta w tym miejscu. Możesz wybrać hasło lub na razie użyć pustego hasła i zmienić je później za pomocą ssh-keygen.
Sprawdź nazwę hosta instancji:
$ hostname
Podczas tworzenia klastra określono --scopes=cloud-platform, dlatego możesz uruchamiać w nim polecenia gcloud. Wyświetl listę klastrów w projekcie:
$ gcloud dataproc clusters list
Gdy skończysz, wyloguj się z połączenia SSH:
$ logout
10. Sprawdzanie tagów
Podczas tworzenia klastra dołączono opcję --tags umożliwiającą dodanie tagu do każdego węzła w klastrze. Tagi są używane do dołączania reguł zapory sieciowej do każdego węzła. W tym ćwiczeniu z programowania nie utworzono żadnych pasujących reguł zapory sieciowej, ale nadal możesz sprawdzić tagi w węźle i reguły zapory sieciowej w sieci.
Wydrukuj opis węzła nadrzędnego:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Poszukaj kodu tags: na końcu danych wyjściowych i sprawdź, czy zawiera on ciąg codelab.
Wydrukuj reguły zapory sieciowej:
$ gcloud compute firewall-rules list
Zwróć uwagę na kolumny SRC_TAGS i TARGET_TAGS. Dołączając tag do reguły zapory sieciowej, możesz określić, że będzie on używany we wszystkich węzłach, które go używają.
11. Wyłącz klaster
Klaster możesz wyłączyć przy użyciu żądania Cloud Dataproc API clusters.delete, pliku wykonywalnego gcloud dataproc clusters delete lub konsoli Google Cloud Platform w wierszu poleceń.
Wyłączmy klaster za pomocą wiersza poleceń Cloud Shell:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Gratulacje!
Wiesz już, jak utworzyć klaster Dataproc, przesłać zadanie Spark, zmienić rozmiar klastra, zalogować się przy użyciu SSH do logowania się do węzła głównego, użyć gcloud do badania klastrów, zadań i reguł zapory sieciowej, a także wyłączyć klaster za pomocą gcloud.
Więcej informacji
- Dokumentacja Dataproc: https://cloud.google.com/dataproc/overview
- Wprowadzenie do Dataproc za pomocą konsoli (w języku angielskim)
Licencja
Te materiały są na licencji Creative Commons Uznanie autorstwa 3.0 i Apache 2.0.