
1. 概要
BigQuery は、Google が提供するペタバイト規模の低料金フルマネージド分析データ ウェアハウスです。BigQuery は NoOps です。インフラストラクチャの管理もデータベース管理者も不要です。そのため、ユーザーは有用な情報を得るためのデータ分析に専念できます。また、使い慣れた SQL を使用し、従量課金制モデルも活用できます。
この Codelab では、Google Cloud BigQuery クライアント ライブラリを使用して、Node.js で BigQuery の一般公開データセットに対してクエリを実行します。
学習内容
- Cloud Shell を使用する方法
- BigQuery API を有効にする方法
- API リクエストを認証する方法
- Node.js 用 BigQuery クライアント ライブラリをインストールする方法
- シェイクスピア作品をクエリする方法
- GitHub データセットに対してクエリを実行する方法
- キャッシュを調整して統計情報を表示する方法
必要なもの
アンケート
このチュートリアルをどのように使用されますか?
Node.js の使用経験をどのように評価されますか。
Google Cloud Platform サービスのご利用経験についてどのように評価されますか?
<ph type="x-smartling-placeholder">2. 設定と要件
セルフペース型の環境設定
- Cloud Console にログインし、新しいプロジェクトを作成するか、既存のプロジェクトを再利用します(Gmail アカウントまたは G Suite アカウントをお持ちでない場合は、アカウントを作成する必要があります)。


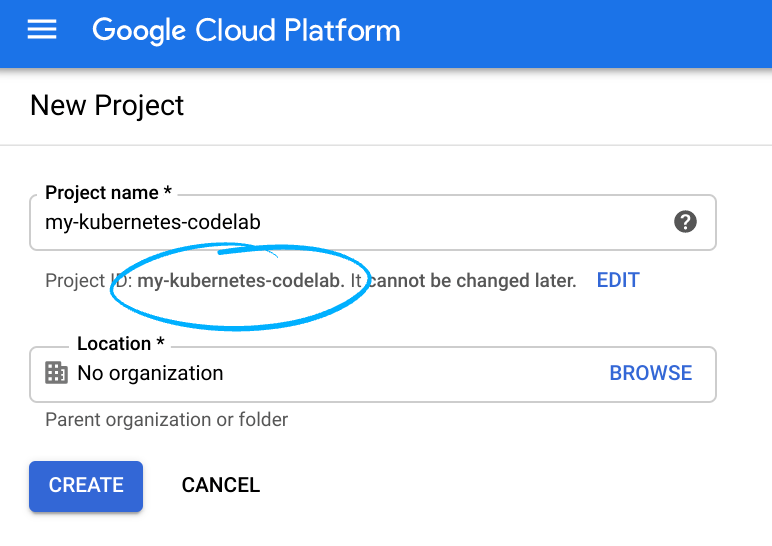
プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
- 次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
このコードラボを実行しても、費用はほとんどかからないはずです。このチュートリアル以外で請求が発生しないように、リソースのシャットダウン方法を説明する「クリーンアップ」セクションの手順に従うようにしてください。Google Cloud の新規ユーザーは $300 の無料トライアル プログラムをご利用いただけます。
Cloud Shell の起動
Cloud SDK コマンドライン ツールはノートパソコンからリモートで操作できますが、この Codelab では、クラウド上で動作するコマンドライン環境である Google Cloud Shell を使用します。
Cloud Shell をアクティブにする
- Cloud Console で、[Cloud Shell をアクティブにする]
をクリックします。

Cloud Shell を初めて起動する場合は、その内容を説明する中間画面(スクロールしなければ見えない範囲)が表示されます。その場合は、[続行] をクリックします(今後表示されなくなります)。この中間画面は次のようになります。

Cloud Shell のプロビジョニングと接続に少し時間がかかる程度です。

この仮想マシンには、必要な開発ツールがすべて含まれています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。このコードラボでの作業のほとんどは、ブラウザまたは Chromebook から実行できます。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自のプロジェクト ID が設定されていることがわかります。
- Cloud Shell で次のコマンドを実行して、認証されたことを確認します。
gcloud auth list
コマンド出力
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
上記のようになっていない場合は、次のコマンドで設定できます。
gcloud config set project <PROJECT_ID>
コマンド出力
Updated property [core/project].
3. BigQuery API を有効にする
BigQuery API は、すべての Google Cloud プロジェクトでデフォルトで有効にする必要があります。これに該当するかどうかを確認するには、Cloud Shell で次のコマンドを実行します。
gcloud services list
次のように BigQuery が表示されます。
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
BigQuery API が有効になっていない場合は、Cloud Shell で次のコマンドを使用して有効にできます。
gcloud services enable bigquery-json.googleapis.com
4. API リクエストを認証する
BigQuery API にリクエストを送信するには、サービス アカウントを使用する必要があります。サービス アカウントはプロジェクトに属し、Google BigQuery Node.js クライアント ライブラリで BigQuery API リクエストを行うために使用されます。ほかのユーザー アカウントと同じように、サービス アカウントはメールアドレスで表されます。このセクションでは、Cloud SDK を使用してサービス アカウントを作成し、サービス アカウントとして認証するために必要な認証情報を作成します。
まず、この Codelab 全体を通して使用する PROJECT_ID を使って環境変数を設定します。
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
次に、次のコマンドを使用して、BigQuery API にアクセスするための新しいサービス アカウントを作成します。
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
次に、Node.js コードが新しいサービス アカウントとしてログインするために使用する認証情報を作成します。これらの認証情報を作成し、JSON ファイル「~/key.json」として保存します。次のコマンドを使用します。
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
最後に、GOOGLE_APPLICATION_CREDENTIALS 環境変数を設定します。この変数は、次のステップで説明する BigQuery API C# ライブラリで使用され、認証情報を検索します。環境変数には、作成した認証情報 JSON ファイルのフルパスを設定する必要があります。次のコマンドを使用して環境変数を設定します。
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
詳細については、BigQuery API の認証をご覧ください。
5. アクセス制御の設定
BigQuery は Identity and Access Management(IAM)を使用してリソースへのアクセスを管理します。BigQuery にはいくつかの事前定義ロール(user、dataOwner、dataViewer など)があり、前のステップで作成したサービス アカウントに割り当てることができます。アクセス制御の詳細については、BigQuery のドキュメントをご覧ください。
一般公開データセットに対してクエリを実行する前に、サービス アカウントに少なくとも bigquery.user ロールがあることを確認する必要があります。Cloud Shell で次のコマンドを実行して、サービス アカウントに bigquery.user ロールを割り当てます。
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
次のコマンドを実行して、サービス アカウントにユーザーロールが割り当てられていることを確認できます。
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Node.js 用の BigQuery クライアント ライブラリをインストールする
まず、BigQueryDemo フォルダを作成してそのフォルダに移動します。
mkdir BigQueryDemo
cd BigQueryDemo
次に、BigQuery クライアント ライブラリのサンプルの実行に使用する Node.js プロジェクトを作成します。
npm init -y
作成された Node.js プロジェクトが表示されます。
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
BigQuery クライアント ライブラリをインストールします。
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
これで、BigQuery Node.js クライアント ライブラリを使用する準備が整いました。
7. シェイクスピアの作品をクエリする
一般公開データセットとは、BigQuery に保存され、一般に公開されるデータセットのことです。クエリに使用できる一般公開データセットは他にも多数あり、一部は Google でもホストされていますが、多くはサードパーティによってホストされています。詳しくは、公開データセットのページをご覧ください。
BigQuery では、一般公開データセットに加えて、クエリに使用できるサンプル テーブルが限られています。これらのテーブルは bigquery-public-data:samples dataset に含まれています。そのうちの 1 つは shakespeare. です。シェイクスピア作品の単語インデックスが含まれ、各コーパスで各単語が出現する回数を指定します。
このステップでは、shakespeare テーブルに対してクエリを実行します。
まず、Cloud Shell の右上からコードエディタを開きます。

BigQueryDemo フォルダ内に queryShakespeare.js ファイルを作成します。
touch queryShakespeare.js
queryShakespeare.js ファイルに移動し、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
1 ~ 2 分ほどかけてコードを学習し、テーブルがどのようにクエリされるかを確認してください。
Cloud Shell に戻り、アプリを実行します。
node queryShakespeare.js
単語とその出現箇所のリストが表示されます。
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. GitHub データセットに対してクエリを実行する
BigQuery に慣れるため、GitHub の一般公開データセットに対してクエリを発行します。最も一般的なコミット メッセージは GitHub で確認できます。また、BigQuery のウェブ UI を使用して、アドホック クエリをプレビューして実行します。
データを表示するには、BigQuery ウェブ UI で GitHub データセットを開きます。
[プレビュー] タブをクリックすると、データがどのように表示されるかを簡単に確認できます。

BigQueryDemo フォルダ内に queryGitHub.js ファイルを作成します。
touch queryGitHub.js
queryGitHub.js ファイルに移動し、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
1 ~ 2 分かけてコードを学習し、最も一般的な commit メッセージがテーブルに対してどのようにクエリされるかを確認してください。
Cloud Shell に戻り、アプリを実行します。
node queryGitHub.js
commit メッセージとその発生回数のリストが表示されます。
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. キャッシュと統計情報
クエリを実行すると、BigQuery は結果をキャッシュに保存します。その結果、後続の同一のクエリにかかる時間は大幅に短縮されます。クエリ オプションを使用してキャッシュを無効にできます。また、BigQuery では、作成時間、終了時間、処理された合計バイト数など、クエリに関する統計情報も記録されます。
このステップでは、キャッシュを無効にして、クエリに関するいくつかの統計情報を表示します。
BigQueryDemo フォルダ内の queryShakespeare.js ファイルに移動し、コードを次のように置き換えます。
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
コードについて、いくつか注意点があります。まず、options オブジェクト内で UseQueryCache を false に設定することで、キャッシュを無効にします。次に、ジョブ オブジェクトからクエリに関する統計情報にアクセスしました。
Cloud Shell に戻り、アプリを実行します。
node queryShakespeare.js
commit メッセージとその発生回数のリストが表示されます。さらに、クエリに関するいくつかの統計情報も表示されます。
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. BigQuery へのデータの読み込み
独自のデータに対してクエリを実行する場合は、まずデータを BigQuery に読み込む必要があります。BigQuery では、Google Cloud Storage、その他の Google サービス、ローカルの読み取り可能なソースなど、さまざまなソースからのデータの読み込みがサポートされています。データをストリーミングすることもできます。詳細については、BigQuery へのデータの読み込みをご覧ください。
このステップでは、Google Cloud Storage に保存されている JSON ファイルを BigQuery テーブルに読み込みます。JSON ファイルは gs://cloud-samples-data/bigquery/us-states/us-states.json にあります。
JSON ファイルの内容については、gsutil コマンドライン ツールを使用して Cloud Shell でダウンロードできます。
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
米国の州のリストが含まれており、各州が別々の行に記述された JSON オブジェクトであることがわかります。
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
この JSON ファイルを BigQuery に読み込むには、BigQueryDemo フォルダ内に createDataset.js ファイルと loadBigQueryJSON.js ファイルを作成します。
touch createDataset.js
touch loadBigQueryJSON.js
Google Cloud Storage Node.js クライアント ライブラリをインストールします。
npm install --save @google-cloud/storage
createDataset.js ファイルに移動し、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
次に、loadBigQueryJSON.js ファイルに移動して、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
1 ~ 2 分ほどかけて、このコードが JSON ファイルを読み込み、データセットにテーブル(スキーマ付き)を作成する仕組みを確認しましょう。
Cloud Shell に戻り、アプリを実行します。
node createDataset.js
node loadBigQueryJSON.js
BigQuery にデータセットとテーブルが作成されます。
Table my_states_table created.
Job [JOB ID] completed.
データセットが作成されたことを確認するには、BigQuery ウェブ UI に移動します。新しいデータセットとテーブルが表示されます。テーブルの [プレビュー] タブに切り替えると、実際のデータを確認できます。

11. 完了
ここでは、Node.js を使用して BigQuery を使用する方法を学びました。
クリーンアップ
このクイックスタートで使用するリソースに対して Google Cloud Platform アカウントに課金されないようにするには:
- Cloud Platform コンソールに移動します。
- シャットダウンするプロジェクトを選択し、[削除] をクリックしますプロジェクトの削除がスケジュールされます。
詳細
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Google Cloud Platform での Node.js: https://cloud.google.com/nodejs/
- Google BigQuery Node.js クライアント ライブラリ: https://github.com/googleapis/nodejs-bigquery
ライセンス
この作業はクリエイティブ・コモンズの表示 2.0 汎用ライセンスにより使用許諾されています。