
1. ภาพรวม
ใน Code Lab นี้ คุณจะได้เรียนรู้วิธีทำให้แอป LangChain ที่ใช้ Gemini ใช้งานได้ เพื่อให้คุณถามคำถามผ่านบันทึกประจำรุ่นของ Cloud Run ได้
ต่อไปนี้คือตัวอย่างการทำงานของแอป หากคุณถามคำถามว่า "ฉันจะต่อเชื่อมที่เก็บข้อมูล Cloud Storage เป็นวอลุ่มใน Cloud Run ได้ไหม" แอปจะตอบกลับว่า "ได้ ตั้งแต่วันที่ 19 มกราคม 2024" หรือข้อความที่คล้ายกัน
หากต้องการแสดงคำตอบที่อิงตามข้อมูลจริง แอปจะดึงข้อมูลบันทึกประจำรุ่นของ Cloud Run ที่คล้ายกับคำถามก่อน จากนั้นจึงแสดงทั้งคำถามและบันทึกประจำรุ่นให้ Gemini (เป็นรูปแบบที่มักเรียกว่า RAG) แผนภาพแสดงสถาปัตยกรรมของแอปมีดังนี้
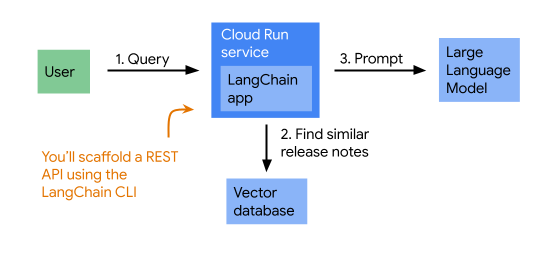
2. การตั้งค่าและข้อกำหนด
ก่อนอื่น ให้ตรวจสอบว่าตั้งค่าสภาพแวดล้อมการพัฒนาอย่างถูกต้อง
- คุณจะต้องมีโปรเจ็กต์ Google Cloud เพื่อทำให้ทรัพยากรที่จำเป็นสำหรับแอปใช้งานได้
- หากต้องการทำให้แอปใช้งานได้ คุณจะต้องติดตั้ง gcloud บนเครื่องภายในเครื่อง ตรวจสอบสิทธิ์แล้ว และกำหนดค่าให้ใช้โปรเจ็กต์
gcloud auth logingcloud config set project
- หากต้องการเรียกใช้แอปพลิเคชันในเครื่อง ซึ่งเราขอแนะนำ คุณต้องตรวจสอบว่าได้ตั้งค่าข้อมูลเข้าสู่ระบบเริ่มต้นของแอปพลิเคชันอย่างถูกต้อง รวมถึงการตั้งค่าโปรเจ็กต์โควต้า
gcloud auth application-default logingcloud auth application-default set-quota-project
- นอกจากนี้ คุณยังต้องติดตั้งซอฟต์แวร์ต่อไปนี้ด้วย
- Python (ต้องใช้เวอร์ชัน 3.11 ขึ้นไป)
- LangChain CLI
- บทกวี สำหรับการจัดการการอ้างอิง
- pipx เพื่อติดตั้งและเรียกใช้ LangChain CLI และบทกวีในสภาพแวดล้อมเสมือนจริงที่แยกไว้
ต่อไปนี้เป็นบล็อกที่จะช่วยคุณเริ่มต้นการติดตั้งเครื่องมือที่จําเป็นสําหรับการแนะนำแบบทีละขั้นตอนนี้
Cloud Workstations
คุณใช้ Cloud Workstation ใน Google Cloud แทนเครื่องคอมพิวเตอร์ของคุณได้ โปรดทราบว่าตั้งแต่เดือนเมษายน 2024 เป็นต้นไป ไฟล์ดังกล่าวเรียกใช้ Python เวอร์ชันที่ต่ำกว่า 3.11 ดังนั้นคุณอาจต้องอัปเกรด Python ก่อนเริ่มต้นใช้งาน
เปิดใช้ Cloud API
ก่อนอื่นให้เรียกใช้คำสั่งต่อไปนี้เพื่อตรวจสอบว่าคุณได้กำหนดค่าโปรเจ็กต์ Google Cloud ที่ถูกต้องเพื่อใช้
gcloud config list project
หากโปรเจ็กต์ที่ถูกต้องไม่แสดงขึ้น คุณสามารถตั้งค่าด้วยคำสั่งนี้
gcloud config set project <PROJECT_ID>
จากนั้นเปิดใช้ API ต่อไปนี้
gcloud services enable \ bigquery.googleapis.com \ sqladmin.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com \ secretmanager.googleapis.com
เลือกภูมิภาค
Google Cloud มีให้บริการในหลายแห่งทั่วโลก และคุณต้องเลือก 1 แห่งเพื่อทำให้ทรัพยากรที่จะใช้สำหรับห้องทดลองนี้ ตั้งค่าภูมิภาคเป็นตัวแปรสภาพแวดล้อมใน Shell (คำสั่งหลังจากนี้จะใช้ตัวแปรนี้) ดังนี้
export REGION=us-central1
3. สร้างอินสแตนซ์ฐานข้อมูลเวกเตอร์
ส่วนสำคัญของแอปนี้คือการเรียกข้อมูลบันทึกประจำรุ่นที่เกี่ยวข้องกับคำถามของผู้ใช้ ตัวอย่างที่ชัดเจนมากขึ้นคือ หากคุณถามคำถามเกี่ยวกับ Cloud Storage คุณจะต้องเพิ่มหมายเหตุประจำรุ่นต่อไปนี้ลงในพรอมต์
คุณสามารถใช้การฝังข้อความและฐานข้อมูลเวกเตอร์เพื่อค้นหาหมายเหตุประจำรุ่นที่คล้ายกันตามความหมาย
ผมจะสาธิตวิธีใช้ PostgreSQL บน Cloud SQL เป็นฐานข้อมูลเวกเตอร์ การสร้างอินสแตนซ์ Cloud SQL ใหม่จะใช้เวลาสักครู่ เรามาเริ่มกันเลย
gcloud sql instances create sql-instance \ --database-version POSTGRES_14 \ --tier db-f1-micro \ --region $REGION
คุณสามารถเรียกใช้คําสั่งนี้และดําเนินการต่อในขั้นตอนถัดไป ต่อไปคุณจะต้องสร้างฐานข้อมูลและเพิ่มผู้ใช้ แต่เรามาไม่เสียเวลาดูภาพสปินเนอร์กัน
PostgreSQL เป็นเซิร์ฟเวอร์ฐานข้อมูลเชิงสัมพันธ์ และอินสแตนซ์ใหม่ทุกรายการของ Cloud SQL มีส่วนขยาย pgvector ติดตั้งอยู่โดยค่าเริ่มต้น ซึ่งหมายความว่าคุณสามารถใช้ส่วนขยายนี้เป็นฐานข้อมูลเวกเตอร์ได้เช่นกัน
4. Scaffold แอป LangChain
หากต้องการดำเนินการต่อ คุณจะต้องติดตั้ง LangChain CLI และบทกวีเพื่อจัดการทรัพยากร Dependency วิธีติดตั้งโดยใช้ pipx มีดังนี้
pipx install langchain-cli poetry
สร้างสคีมาแอป LangChain ด้วยคำสั่งต่อไปนี้ เมื่อระบบถาม ให้ตั้งชื่อโฟลเดอร์ run-rag และข้ามการติดตั้งแพ็กเกจโดยกด Enter
langchain app new
เปลี่ยนเป็นไดเรกทอรี run-rag และติดตั้งการอ้างอิง
poetry install
คุณเพิ่งสร้างแอป LangServe ซึ่งจะรวม FastAPI ไว้ในเชน LangChain เครื่องมือนี้มาพร้อมกับพื้นที่ทดสอบในตัวที่ช่วยให้ส่งพรอมต์และตรวจสอบผลลัพธ์ รวมถึงขั้นตอนกลางทั้งหมดได้ง่าย เราขอแนะนำให้คุณเปิดโฟลเดอร์ run-rag ในเครื่องมือแก้ไขและค้นหาสิ่งที่อยู่ในนั้น
5. สร้างงานการจัดทำดัชนี
ก่อนเริ่มสร้างเว็บแอป ให้ตรวจสอบว่ามีการจัดทำดัชนีบันทึกประจำรุ่นของ Cloud Run ในฐานข้อมูล Cloud SQL แล้ว ในส่วนนี้ คุณจะได้สร้างงานการจัดทําดัชนีที่ทําสิ่งต่อไปนี้
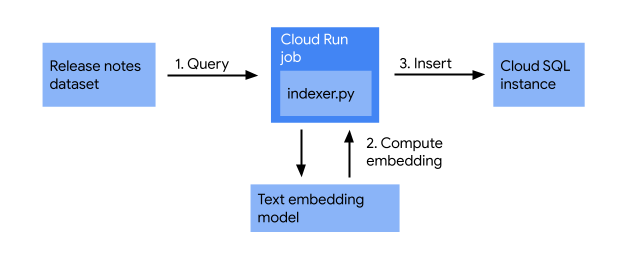
งานการจัดทำดัชนีจะบันทึกบันทึกประจำรุ่น แปลงให้เป็นเวกเตอร์โดยใช้โมเดลการฝังข้อความ และจัดเก็บไว้ในฐานข้อมูลเวกเตอร์ วิธีนี้ช่วยให้ค้นหาหมายเหตุเกี่ยวกับรุ่นที่คล้ายกันได้อย่างมีประสิทธิภาพตามความหมายเชิงอรรถศาสตร์
ในโฟลเดอร์ run-rag/app ให้สร้างไฟล์ indexer.py ที่มีเนื้อหาต่อไปนี้
import os
from google.cloud.sql.connector import Connector
import pg8000
from langchain_community.vectorstores.pgvector import PGVector
from langchain_google_vertexai import VertexAIEmbeddings
from google.cloud import bigquery
# Retrieve all Cloud Run release notes from BigQuery
client = bigquery.Client()
query = """
SELECT
CONCAT(FORMAT_DATE("%B %d, %Y", published_at), ": ", description) AS release_note
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE product_name= "Cloud Run"
ORDER BY published_at DESC
"""
rows = client.query(query)
print(f"Number of release notes retrieved: {rows.result().total_rows}")
# Set up a PGVector instance
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
store = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
),
pre_delete_collection=True
)
# Save all release notes into the Cloud SQL database
texts = list(row["release_note"] for row in rows)
ids = store.add_texts(texts)
print(f"Done saving: {len(ids)} release notes")
เพิ่มทรัพยากร Dependency ที่จำเป็น
poetry add \ "cloud-sql-python-connector[pg8000]" \ langchain-google-vertexai==1.0.5 \ langchain-community==0.2.5 \ pgvector
สร้างฐานข้อมูลและผู้ใช้
สร้างฐานข้อมูล release-notes บนอินสแตนซ์ Cloud SQL sql-instance:
gcloud sql databases create release-notes --instance sql-instance
สร้างผู้ใช้ฐานข้อมูลที่ชื่อ app โดยทำดังนี้
gcloud sql users create app --instance sql-instance --password "myprecious"
ติดตั้งใช้งานและเรียกใช้งานการจัดทําดัชนี
ทำให้งานใช้งานได้และเรียกใช้งานได้ทันที:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run jobs deploy indexer \ --source . \ --command python \ --args app/indexer.py \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --execute-now
ออกคำสั่งมาก มาดูกันว่าจะเกิดอะไรขึ้น
คำสั่งแรกจะดึงข้อมูลชื่อการเชื่อมต่อ (รหัสเฉพาะที่จัดรูปแบบเป็น project:region:instance) และตั้งเป็นตัวแปรสภาพแวดล้อม DB_INSTANCE_NAME
คำสั่งที่ 2 จะทําให้ใช้งานงาน Cloud Run ได้ สิ่งที่รายงานเข้ามามีดังนี้
--source .: ระบุว่าซอร์สโค้ดสำหรับงานอยู่ในไดเรกทอรีที่ใช้งานอยู่ปัจจุบัน (ไดเรกทอรีที่คุณเรียกใช้คำสั่ง)--command python: ตั้งค่าคำสั่งให้ดำเนินการภายในคอนเทนเนอร์ ในกรณีนี้ คำสั่งดังกล่าวจะใช้ในการเรียกใช้ Python--args app/indexer.py: ระบุอาร์กิวเมนต์ของคำสั่ง Python ซึ่งจะเรียกใช้สคริปต์_indexer.py ในไดเรกทอรีแอป--set-env-vars: ตั้งค่าตัวแปรสภาพแวดล้อมที่สคริปต์ Python เข้าถึงได้ระหว่างการดำเนินการ--region=$REGION: ระบุภูมิภาคที่ควรทำให้งานใช้งานได้--execute-now: บอกให้ Cloud Run เริ่มงานทันทีหลังจากที่ทำให้ใช้งานได้แล้ว
หากต้องการตรวจสอบว่างานเสร็จสมบูรณ์แล้ว ให้ทำดังนี้
- อ่านบันทึกการดำเนินการงานผ่านเว็บคอนโซล ระบบควรแสดงข้อความว่า "บันทึกบันทึกประจำรุ่น xxx รายการเสร็จแล้ว" (โดยที่ xxx คือจำนวนบันทึกประจำรุ่นที่บันทึกไว้)
- นอกจากนี้ คุณยังไปยังอินสแตนซ์ Cloud SQL ในเว็บคอนโซล และใช้ Cloud SQL Studio เพื่อค้นหาจํานวนระเบียนในตาราง
langchain_pg_embeddingได้ด้วย
6. เขียนเว็บแอปพลิเคชัน
เปิดไฟล์ app/server.py ในตัวแก้ไข คุณจะเห็นบรรทัดที่มีข้อความต่อไปนี้
# Edit this to add the chain you want to add
แทนที่ความคิดเห็นนั้นด้วยข้อมูลโค้ดต่อไปนี้
# (1) Initialize VectorStore
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
vectorstore = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
)
)
# (2) Build retriever
def concatenate_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
notes_retriever = vectorstore.as_retriever() | concatenate_docs
# (3) Create prompt template
prompt_template = PromptTemplate.from_template(
"""You are a Cloud Run expert answering questions.
Use the retrieved release notes to answer questions
Give a concise answer, and if you are unsure of the answer, just say so.
Release notes: {notes}
Here is your question: {query}
Your answer: """)
# (4) Initialize LLM
llm = VertexAI(
model_name="gemini-1.0-pro-001",
temperature=0.2,
max_output_tokens=100,
top_k=40,
top_p=0.95
)
# (5) Chain everything together
chain = (
RunnableParallel({
"notes": notes_retriever,
"query": RunnablePassthrough()
})
| prompt_template
| llm
| StrOutputParser()
)
นอกจากนี้ คุณยังต้องเพิ่มการนําเข้าต่อไปนี้ด้วย
import pg8000
import os
from google.cloud.sql.connector import Connector
from langchain_google_vertexai import VertexAI
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores.pgvector import PGVector
สุดท้าย ให้เปลี่ยนบรรทัดที่ระบุว่า "NotImplemented" เป็น
# add_routes(app, NotImplemented)
add_routes(app, chain)
7. ทำให้เว็บแอปพลิเคชันใช้งานได้ใน Cloud Run
จากไดเรกทอรี run-rag ให้ใช้คำสั่งต่อไปนี้เพื่อทำให้แอปใช้งานได้ใน Cloud Run
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run deploy run-rag \ --source . \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --allow-unauthenticated
คำสั่งนี้จะทําสิ่งต่อไปนี้
- อัปโหลดซอร์สโค้ดไปยัง Cloud Build
- เรียกใช้บิลด์ Docker
- พุชอิมเมจคอนเทนเนอร์ที่ได้ไปยัง Artifact Registry
- สร้างบริการ Cloud Run โดยใช้อิมเมจคอนเทนเนอร์
เมื่อคำสั่งเสร็จสมบูรณ์ ระบบจะแสดง URL ของ HTTPS ในโดเมน run.app นี่คือ URL สาธารณะของบริการ Cloud Run ใหม่ของคุณ
8. สำรวจ Playgroud
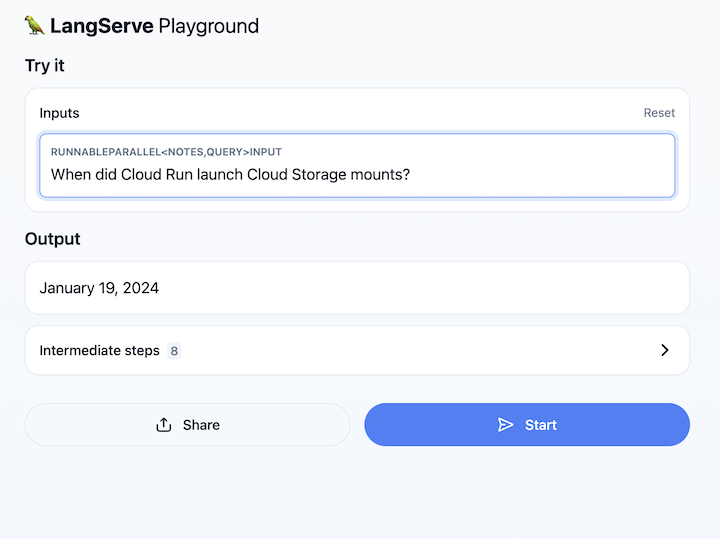
เปิด URL ของบริการ Cloud Run แล้วไปที่ /playground ซึ่งจะแสดงช่องข้อความ ใช้เพื่อถามคำถามในบันทึกประจำรุ่น Cloud Run ดังตัวอย่างต่อไปนี้
9. ขอแสดงความยินดี
คุณสร้างและทำให้แอป LangChain ใช้งานได้บน Cloud Run เรียบร้อยแล้ว เยี่ยมมาก!
แนวคิดหลักมีดังนี้
- การใช้เฟรมเวิร์ก LangChain เพื่อสร้างแอปพลิเคชัน Retrieval Augmented Generation (RAG)
- การใช้ PostgreSQL บน Cloud SQL เป็นฐานข้อมูลเวกเตอร์ที่มี pgvector ซึ่งติดตั้งบน Cloud SQL ตามค่าเริ่มต้น
- เรียกใช้งานการจัดทําดัชนีที่ทํางานนานขึ้นเป็นงาน Cloud Run และเว็บแอปพลิเคชันเป็นบริการ Cloud Run
- รวมเชน LangChain ในแอปพลิเคชัน FastAPI ด้วย LangServe ซึ่งเป็นอินเทอร์เฟซที่สะดวกสบายในการโต้ตอบกับแอป RAG
ล้างข้อมูล
โปรดดำเนินการดังนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud Platform สำหรับทรัพยากรที่ใช้ในบทแนะนำนี้
- ใน Cloud Console ให้ไปที่หน้าจัดการทรัพยากร
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ แล้วคลิก "ลบ"
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิก "ปิด" เพื่อลบโปรเจ็กต์
หากต้องการเก็บโปรเจ็กต์ไว้ โปรดลบทรัพยากรต่อไปนี้
- อินสแตนซ์ Cloud SQL
- บริการ Cloud Run
- งาน Cloud Run